 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Heterogeneous federated collaborative filtering using FAIR: Federated Averaging in Random Subspaces
Nov 03, 2023
Recommendation systems (RS) for items (e.g., movies, books) and ads are widely used to tailor content to users on various internet platforms. Traditionally, recommendation models are trained on a central server. However, due to rising concerns for data privacy and regulations like the GDPR, federated learning is an increasingly popular paradigm in which data never leaves the client device. Applying federated learning to recommendation models is non-trivial due to large embedding tables, which often exceed the memory constraints of most user devices. To include data from all devices in federated learning, we must enable collective training of embedding tables on devices with heterogeneous memory capacities. Current solutions to heterogeneous federated learning can only accommodate a small range of capacities and thus limit the number of devices that can participate in training. We present Federated Averaging in Random subspaces (FAIR), which allows arbitrary compression of embedding tables based on device capacity and ensures the participation of all devices in training. FAIR uses what we call consistent and collapsible subspaces defined by hashing-based random projections to jointly train large embedding tables while using varying amounts of compression on user devices. We evaluate FAIR on Neural Collaborative Filtering tasks with multiple datasets and verify that FAIR can gather and share information from a wide range of devices with varying capacities, allowing for seamless collaboration. We prove the convergence of FAIR in the homogeneous setting with non-i.i.d data distribution. Our code is open source at {https://github.com/apd10/FLCF}
FETV: A Benchmark for Fine-Grained Evaluation of Open-Domain Text-to-Video Generation
Nov 03, 2023
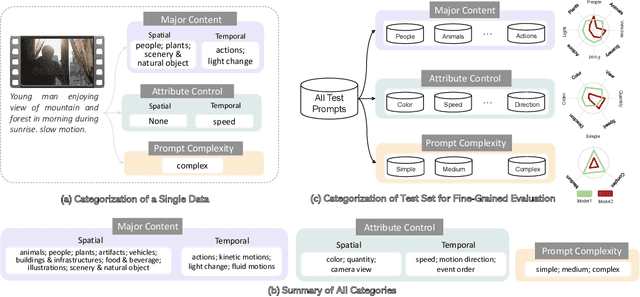


Recently, open-domain text-to-video (T2V) generation models have made remarkable progress. However, the promising results are mainly shown by the qualitative cases of generated videos, while the quantitative evaluation of T2V models still faces two critical problems. Firstly, existing studies lack fine-grained evaluation of T2V models on different categories of text prompts. Although some benchmarks have categorized the prompts, their categorization either only focuses on a single aspect or fails to consider the temporal information in video generation. Secondly, it is unclear whether the automatic evaluation metrics are consistent with human standards. To address these problems, we propose FETV, a benchmark for Fine-grained Evaluation of Text-to-Video generation. FETV is multi-aspect, categorizing the prompts based on three orthogonal aspects: the major content, the attributes to control and the prompt complexity. FETV is also temporal-aware, which introduces several temporal categories tailored for video generation. Based on FETV, we conduct comprehensive manual evaluations of four representative T2V models, revealing their pros and cons on different categories of prompts from different aspects. We also extend FETV as a testbed to evaluate the reliability of automatic T2V metrics. The multi-aspect categorization of FETV enables fine-grained analysis of the metrics' reliability in different scenarios. We find that existing automatic metrics (e.g., CLIPScore and FVD) correlate poorly with human evaluation. To address this problem, we explore several solutions to improve CLIPScore and FVD, and develop two automatic metrics that exhibit significant higher correlation with humans than existing metrics. Benchmark page: https://github.com/llyx97/FETV.
3-Dimensional residual neural architecture search for ultrasonic defect detection
Nov 03, 2023This study presents a deep learning methodology using 3-dimensional (3D) convolutional neural networks to detect defects in carbon fiber reinforced polymer composites through volumetric ultrasonic testing data. Acquiring large amounts of ultrasonic training data experimentally is expensive and time-consuming. To address this issue, a synthetic data generation method was extended to incorporate volumetric data. By preserving the complete volumetric data, complex preprocessing is reduced, and the model can utilize spatial and temporal information that is lost during imaging. This enables the model to utilise important features that might be overlooked otherwise. The performance of three architectures were compared. The first two architectures were hand-designed to address the high aspect ratios between the spatial and temporal dimensions. The first architecture reduced dimensionality in the time domain and used cubed kernels for feature extraction. The second architecture used cuboidal kernels to account for the large aspect ratios. The evaluation included comparing the use of max pooling and convolutional layers for dimensionality reduction, with the fully convolutional layers consistently outperforming the models using max pooling. The third architecture was generated through neural architecture search from a modified 3D Residual Neural Network (ResNet) search space. Additionally, domain-specific augmentation methods were incorporated during training, resulting in significant improvements in model performance for all architectures. The mean accuracy improvements ranged from 8.2% to 22.4%. The best performing models achieved mean accuracies of 91.8%, 92.2%, and 100% for the reduction, constant, and discovered architectures, respectively. Whilst maintaining a model size smaller than most 2-dimensional (2D) ResNets.
Kernel-based Joint Multiple Graph Learning and Clustering of Graph Signals
Oct 29, 2023Within the context of Graph Signal Processing (GSP), Graph Learning (GL) is concerned with the inference of a graph's topology from nodal observations, i.e., graph signals. However, data is often in mixed form, relating to different underlying structures. This heterogeneity necessitates the joint clustering and learning of multiple graphs. In many real-life applications, there are available node-side covariates (i.e., kernels) that imperatively should be incorporated, which has not been addressed by the rare graph signal clustering approaches. To this end and inspired by the rich K-means framework, we propose a novel kernel-based algorithm to incorporate this node-side information as we jointly partition the signals and learn a graph for each cluster. Numerical experiments demonstrate its effectiveness over the state-of-the-art.
Learning Realistic Traffic Agents in Closed-loop
Nov 02, 2023Realistic traffic simulation is crucial for developing self-driving software in a safe and scalable manner prior to real-world deployment. Typically, imitation learning (IL) is used to learn human-like traffic agents directly from real-world observations collected offline, but without explicit specification of traffic rules, agents trained from IL alone frequently display unrealistic infractions like collisions and driving off the road. This problem is exacerbated in out-of-distribution and long-tail scenarios. On the other hand, reinforcement learning (RL) can train traffic agents to avoid infractions, but using RL alone results in unhuman-like driving behaviors. We propose Reinforcing Traffic Rules (RTR), a holistic closed-loop learning objective to match expert demonstrations under a traffic compliance constraint, which naturally gives rise to a joint IL + RL approach, obtaining the best of both worlds. Our method learns in closed-loop simulations of both nominal scenarios from real-world datasets as well as procedurally generated long-tail scenarios. Our experiments show that RTR learns more realistic and generalizable traffic simulation policies, achieving significantly better tradeoffs between human-like driving and traffic compliance in both nominal and long-tail scenarios. Moreover, when used as a data generation tool for training prediction models, our learned traffic policy leads to considerably improved downstream prediction metrics compared to baseline traffic agents. For more information, visit the project website: https://waabi.ai/rtr
Adapting Fake News Detection to the Era of Large Language Models
Nov 02, 2023In the age of large language models (LLMs) and the widespread adoption of AI-driven content creation, the landscape of information dissemination has witnessed a paradigm shift. With the proliferation of both human-written and machine-generated real and fake news, robustly and effectively discerning the veracity of news articles has become an intricate challenge. While substantial research has been dedicated to fake news detection, this either assumes that all news articles are human-written or abruptly assumes that all machine-generated news are fake. Thus, a significant gap exists in understanding the interplay between machine-(paraphrased) real news, machine-generated fake news, human-written fake news, and human-written real news. In this paper, we study this gap by conducting a comprehensive evaluation of fake news detectors trained in various scenarios. Our primary objectives revolve around the following pivotal question: How to adapt fake news detectors to the era of LLMs? Our experiments reveal an interesting pattern that detectors trained exclusively on human-written articles can indeed perform well at detecting machine-generated fake news, but not vice versa. Moreover, due to the bias of detectors against machine-generated texts \cite{su2023fake}, they should be trained on datasets with a lower machine-generated news ratio than the test set. Building on our findings, we provide a practical strategy for the development of robust fake news detectors.
CenterRadarNet: Joint 3D Object Detection and Tracking Framework using 4D FMCW Radar
Nov 02, 2023Robust perception is a vital component for ensuring safe autonomous and assisted driving. Automotive radar (77 to 81 GHz), which offers weather-resilient sensing, provides a complementary capability to the vision- or LiDAR-based autonomous driving systems. Raw radio-frequency (RF) radar tensors contain rich spatiotemporal semantics besides 3D location information. The majority of previous methods take in 3D (Doppler-range-azimuth) RF radar tensors, allowing prediction of an object's location, heading angle, and size in bird's-eye-view (BEV). However, they lack the ability to at the same time infer objects' size, orientation, and identity in the 3D space. To overcome this limitation, we propose an efficient joint architecture called CenterRadarNet, designed to facilitate high-resolution representation learning from 4D (Doppler-range-azimuth-elevation) radar data for 3D object detection and re-identification (re-ID) tasks. As a single-stage 3D object detector, CenterRadarNet directly infers the BEV object distribution confidence maps, corresponding 3D bounding box attributes, and appearance embedding for each pixel. Moreover, we build an online tracker utilizing the learned appearance embedding for re-ID. CenterRadarNet achieves the state-of-the-art result on the K-Radar 3D object detection benchmark. In addition, we present the first 3D object-tracking result using radar on the K-Radar dataset V2. In diverse driving scenarios, CenterRadarNet shows consistent, robust performance, emphasizing its wide applicability.
Federated Learning on Edge Sensing Devices: A Review
Nov 02, 2023The ability to monitor ambient characteristics, interact with them, and derive information about the surroundings has been made possible by the rapid proliferation of edge sensing devices like IoT, mobile, and wearable devices and their measuring capabilities with integrated sensors. Even though these devices are small and have less capacity for data storage and processing, they produce vast amounts of data. Some example application areas where sensor data is collected and processed include healthcare, environmental (including air quality and pollution levels), automotive, industrial, aerospace, and agricultural applications. These enormous volumes of sensing data collected from the edge devices are analyzed using a variety of Machine Learning (ML) and Deep Learning (DL) approaches. However, analyzing them on the cloud or a server presents challenges related to privacy, hardware, and connectivity limitations. Federated Learning (FL) is emerging as a solution to these problems while preserving privacy by jointly training a model without sharing raw data. In this paper, we review the FL strategies from the perspective of edge sensing devices to get over the limitations of conventional machine learning techniques. We focus on the key FL principles, software frameworks, and testbeds. We also explore the current sensor technologies, properties of the sensing devices and sensing applications where FL is utilized. We conclude with a discussion on open issues and future research directions on FL for further studies
Key Frame Mechanism For Efficient Conformer Based End-to-end Speech Recognition
Oct 28, 2023Recently, Conformer as a backbone network for end-to-end automatic speech recognition achieved state-of-the-art performance. The Conformer block leverages a self-attention mechanism to capture global information, along with a convolutional neural network to capture local information, resulting in improved performance. However, the Conformer-based model encounters an issue with the self-attention mechanism, as computational complexity grows quadratically with the length of the input sequence. Inspired by previous Connectionist Temporal Classification (CTC) guided blank skipping during decoding, we introduce intermediate CTC outputs as guidance into the downsampling procedure of the Conformer encoder. We define the frame with non-blank output as key frame. Specifically, we introduce the key frame-based self-attention (KFSA) mechanism, a novel method to reduce the computation of the self-attention mechanism using key frames. The structure of our proposed approach comprises two encoders. Following the initial encoder, we introduce an intermediate CTC loss function to compute the label frame, enabling us to extract the key frames and blank frames for KFSA. Furthermore, we introduce the key frame-based downsampling (KFDS) mechanism to operate on high-dimensional acoustic features directly and drop the frames corresponding to blank labels, which results in new acoustic feature sequences as input to the second encoder. By using the proposed method, which achieves comparable or higher performance than vanilla Conformer and other similar work such as Efficient Conformer. Meantime, our proposed method can discard more than 60\% useless frames during model training and inference, which will accelerate the inference speed significantly. This work code is available in {https://github.com/scufan1990/Key-Frame-Mechanism-For-Efficient-Conformer}
ViCLEVR: A Visual Reasoning Dataset and Hybrid Multimodal Fusion Model for Visual Question Answering in Vietnamese
Oct 27, 2023In recent years, Visual Question Answering (VQA) has gained significant attention for its diverse applications, including intelligent car assistance, aiding visually impaired individuals, and document image information retrieval using natural language queries. VQA requires effective integration of information from questions and images to generate accurate answers. Neural models for VQA have made remarkable progress on large-scale datasets, with a primary focus on resource-rich languages like English. To address this, we introduce the ViCLEVR dataset, a pioneering collection for evaluating various visual reasoning capabilities in Vietnamese while mitigating biases. The dataset comprises over 26,000 images and 30,000 question-answer pairs (QAs), each question annotated to specify the type of reasoning involved. Leveraging this dataset, we conduct a comprehensive analysis of contemporary visual reasoning systems, offering valuable insights into their strengths and limitations. Furthermore, we present PhoVIT, a comprehensive multimodal fusion that identifies objects in images based on questions. The architecture effectively employs transformers to enable simultaneous reasoning over textual and visual data, merging both modalities at an early model stage. The experimental findings demonstrate that our proposed model achieves state-of-the-art performance across four evaluation metrics. The accompanying code and dataset have been made publicly accessible at \url{https://github.com/kvt0012/ViCLEVR}. This provision seeks to stimulate advancements within the research community, fostering the development of more multimodal fusion algorithms, specifically tailored to address the nuances of low-resource languages, exemplified by Vietnamese.