 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MARformer: An Efficient Metal Artifact Reduction Transformer for Dental CBCT Images
Nov 16, 2023
Cone Beam Computed Tomography (CBCT) plays a key role in dental diagnosis and surgery. However, the metal teeth implants could bring annoying metal artifacts during the CBCT imaging process, interfering diagnosis and downstream processing such as tooth segmentation. In this paper, we develop an efficient Transformer to perform metal artifacts reduction (MAR) from dental CBCT images. The proposed MAR Transformer (MARformer) reduces computation complexity in the multihead self-attention by a new Dimension-Reduced Self-Attention (DRSA) module, based on that the CBCT images have globally similar structure. A Patch-wise Perceptive Feed Forward Network (P2FFN) is also proposed to perceive local image information for fine-grained restoration. Experimental results on CBCT images with synthetic and real-world metal artifacts show that our MARformer is efficient and outperforms previous MAR methods and two restoration Transformers.
Federated Knowledge Graph Completion via Latent Embedding Sharing and Tensor Factorization
Nov 17, 2023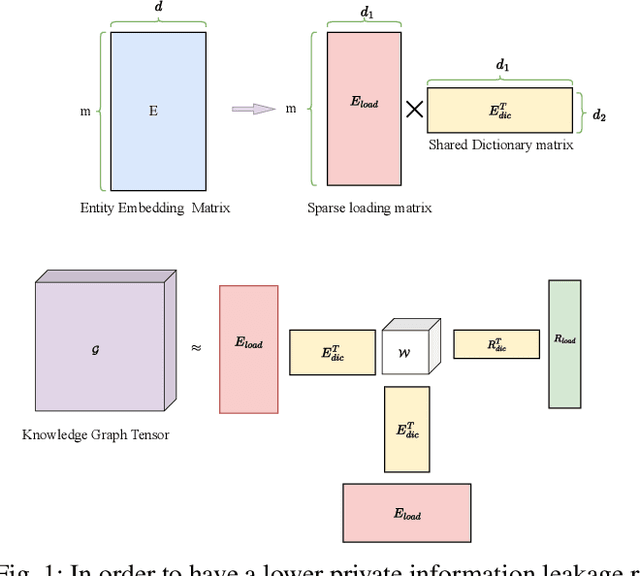
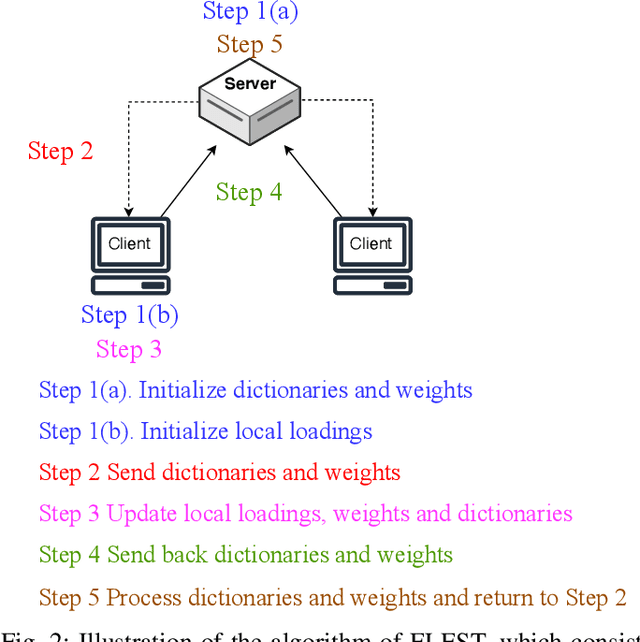
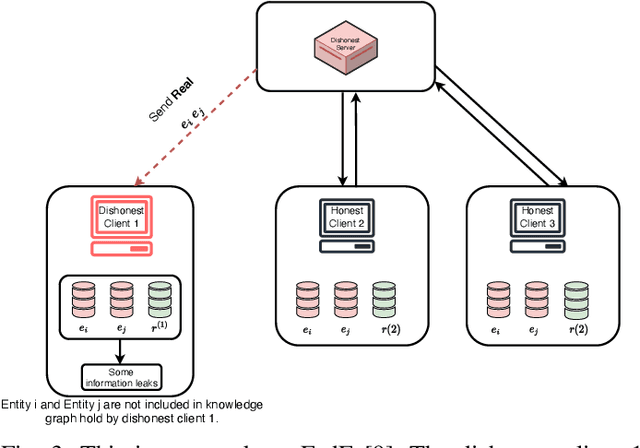

Knowledge graphs (KGs), which consist of triples, are inherently incomplete and always require completion procedure to predict missing triples. In real-world scenarios, KGs are distributed across clients, complicating completion tasks due to privacy restrictions. Many frameworks have been proposed to address the issue of federated knowledge graph completion. However, the existing frameworks, including FedE, FedR, and FEKG, have certain limitations. = FedE poses a risk of information leakage, FedR's optimization efficacy diminishes when there is minimal overlap among relations, and FKGE suffers from computational costs and mode collapse issues. To address these issues, we propose a novel method, i.e., Federated Latent Embedding Sharing Tensor factorization (FLEST), which is a novel approach using federated tensor factorization for KG completion. FLEST decompose the embedding matrix and enables sharing of latent dictionary embeddings to lower privacy risks. Empirical results demonstrate FLEST's effectiveness and efficiency, offering a balanced solution between performance and privacy. FLEST expands the application of federated tensor factorization in KG completion tasks.
Supervised structure learning
Nov 17, 2023This paper concerns structure learning or discovery of discrete generative models. It focuses on Bayesian model selection and the assimilation of training data or content, with a special emphasis on the order in which data are ingested. A key move - in the ensuing schemes - is to place priors on the selection of models, based upon expected free energy. In this setting, expected free energy reduces to a constrained mutual information, where the constraints inherit from priors over outcomes (i.e., preferred outcomes). The resulting scheme is first used to perform image classification on the MNIST dataset to illustrate the basic idea, and then tested on a more challenging problem of discovering models with dynamics, using a simple sprite-based visual disentanglement paradigm and the Tower of Hanoi (cf., blocks world) problem. In these examples, generative models are constructed autodidactically to recover (i.e., disentangle) the factorial structure of latent states - and their characteristic paths or dynamics.
A Comparative Analysis of Retrievability and PageRank Measures
Nov 17, 2023The accessibility of documents within a collection holds a pivotal role in Information Retrieval, signifying the ease of locating specific content in a collection of documents. This accessibility can be achieved via two distinct avenues. The first is through some retrieval model using a keyword or other feature-based search, and the other is where a document can be navigated using links associated with them, if available. Metrics such as PageRank, Hub, and Authority illuminate the pathways through which documents can be discovered within the network of content while the concept of Retrievability is used to quantify the ease with which a document can be found by a retrieval model. In this paper, we compare these two perspectives, PageRank and retrievability, as they quantify the importance and discoverability of content in a corpus. Through empirical experimentation on benchmark datasets, we demonstrate a subtle similarity between retrievability and PageRank particularly distinguishable for larger datasets.
CSAM: A 2.5D Cross-Slice Attention Module for Anisotropic Volumetric Medical Image Segmentation
Nov 08, 2023A large portion of volumetric medical data, especially magnetic resonance imaging (MRI) data, is anisotropic, as the through-plane resolution is typically much lower than the in-plane resolution. Both 3D and purely 2D deep learning-based segmentation methods are deficient in dealing with such volumetric data since the performance of 3D methods suffers when confronting anisotropic data, and 2D methods disregard crucial volumetric information. Insufficient work has been done on 2.5D methods, in which 2D convolution is mainly used in concert with volumetric information. These models focus on learning the relationship across slices, but typically have many parameters to train. We offer a Cross-Slice Attention Module (CSAM) with minimal trainable parameters, which captures information across all the slices in the volume by applying semantic, positional, and slice attention on deep feature maps at different scales. Our extensive experiments using different network architectures and tasks demonstrate the usefulness and generalizability of CSAM. Associated code is available at https://github.com/aL3x-O-o-Hung/CSAM.
Data-driven project planning: An integrated network learning and constraint relaxation approach in favor of scheduling
Nov 20, 2023Our focus is on projects, i.e., business processes, which are emerging as the economic drivers of our times. Differently from day-to-day operational processes that do not require detailed planning, a project requires planning and resource-constrained scheduling for coordinating resources across sub- or related projects and organizations. A planner in charge of project planning has to select a set of activities to perform, determine their precedence constraints, and schedule them according to temporal project constraints. We suggest a data-driven project planning approach for classes of projects such as infrastructure building and information systems development projects. A project network is first learned from historical records. The discovered network relaxes temporal constraints embedded in individual projects, thus uncovering where planning and scheduling flexibility can be exploited for greater benefit. Then, the network, which contains multiple project plan variations, from which one has to be selected, is enriched by identifying decision rules and frequent paths. The planner can rely on the project network for: 1) decoding a project variation such that it forms a new project plan, and 2) applying resource-constrained project scheduling procedures to determine the project's schedule and resource allocation. Using two real-world project datasets, we show that the suggested approach may provide the planner with significant flexibility (up to a 26% reduction of the critical path of a real project) to adjust the project plan and schedule. We believe that the proposed approach can play an important part in supporting decision making towards automated data-driven project planning.
Visual Commonsense based Heterogeneous Graph Contrastive Learning
Nov 11, 2023How to select relevant key objects and reason about the complex relationships cross vision and linguistic domain are two key issues in many multi-modality applications such as visual question answering (VQA). In this work, we incorporate the visual commonsense information and propose a heterogeneous graph contrastive learning method to better finish the visual reasoning task. Our method is designed as a plug-and-play way, so that it can be quickly and easily combined with a wide range of representative methods. Specifically, our model contains two key components: the Commonsense-based Contrastive Learning and the Graph Relation Network. Using contrastive learning, we guide the model concentrate more on discriminative objects and relevant visual commonsense attributes. Besides, thanks to the introduction of the Graph Relation Network, the model reasons about the correlations between homogeneous edges and the similarities between heterogeneous edges, which makes information transmission more effective. Extensive experiments on four benchmarks show that our method greatly improves seven representative VQA models, demonstrating its effectiveness and generalizability.
Aligning the Capabilities of Large Language Models with the Context of Information Retrieval via Contrastive Feedback
Sep 29, 2023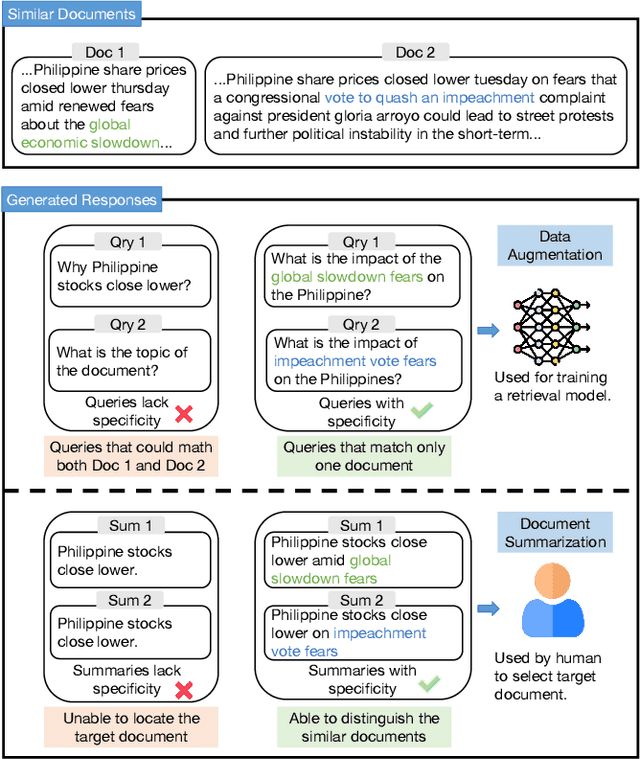
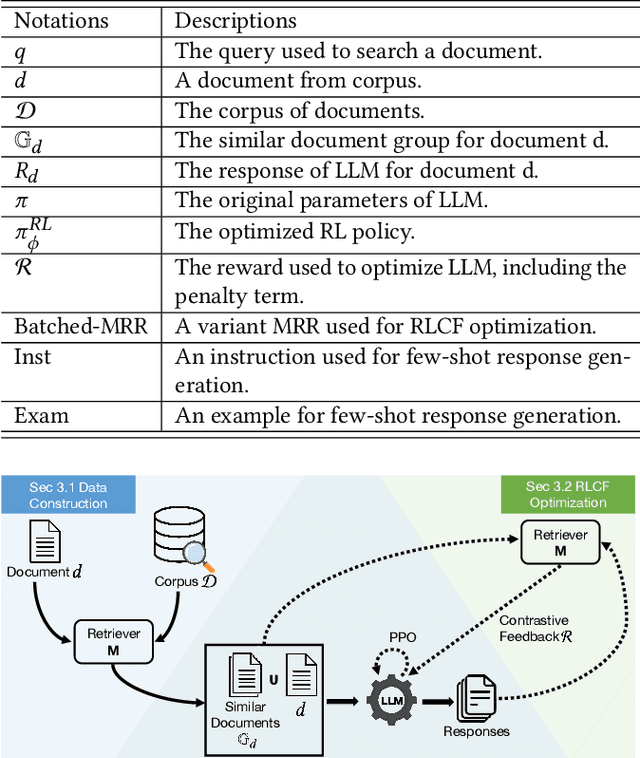
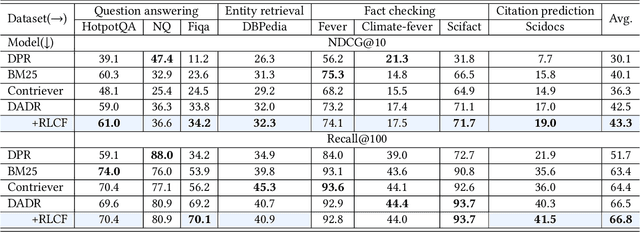
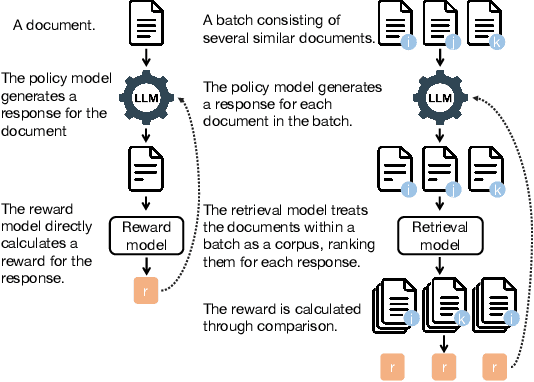
Information Retrieval (IR), the process of finding information to satisfy user's information needs, plays an essential role in modern people's lives. Recently, large language models (LLMs) have demonstrated remarkable capabilities across various tasks, some of which are important for IR. Nonetheless, LLMs frequently confront the issue of generating responses that lack specificity. This has limited the overall effectiveness of LLMs for IR in many cases. To address these issues, we present an unsupervised alignment framework called Reinforcement Learning from Contrastive Feedback (RLCF), which empowers LLMs to generate both high-quality and context-specific responses that suit the needs of IR tasks. Specifically, we construct contrastive feedback by comparing each document with its similar documents, and then propose a reward function named Batched-MRR to teach LLMs to generate responses that captures the fine-grained information that distinguish documents from their similar ones. To demonstrate the effectiveness of RLCF, we conducted experiments in two typical applications of LLMs in IR, i.e., data augmentation and summarization. The experimental results show that RLCF can effectively improve the performance of LLMs in IR context.
Practical Estimation of Ensemble Accuracy
Nov 18, 2023Ensemble learning combines several individual models to obtain better generalization performance. In this work we present a practical method for estimating the joint power of several classifiers which differs from existing approaches by {\em not relying on labels}, hence enabling the work in unsupervised setting of huge datasets. It differs from existing methods which define a "diversity measure". The heart of the method is a combinatorial bound on the number of mistakes the ensemble is likely to make. The bound can be efficiently approximated in time linear in the number of samples. Thus allowing an efficient search for a combination of classifiers that are likely to produce higher joint accuracy. Moreover, having the bound applicable to unlabeled data makes it both accurate and practical in modern setting of unsupervised learning. We demonstrate the method on popular large-scale face recognition datasets which provide a useful playground for fine-grain classification tasks using noisy data over many classes. The proposed framework fits neatly in trending practices of unsupervised learning. It is a measure of the inherent independence of a set of classifiers not relying on extra information such as another classifier or labeled data.
Beyond Images: An Integrative Multi-modal Approach to Chest X-Ray Report Generation
Nov 18, 2023Image-to-text radiology report generation aims to automatically produce radiology reports that describe the findings in medical images. Most existing methods focus solely on the image data, disregarding the other patient information accessible to radiologists. In this paper, we present a novel multi-modal deep neural network framework for generating chest X-rays reports by integrating structured patient data, such as vital signs and symptoms, alongside unstructured clinical notes.We introduce a conditioned cross-multi-head attention module to fuse these heterogeneous data modalities, bridging the semantic gap between visual and textual data. Experiments demonstrate substantial improvements from using additional modalities compared to relying on images alone. Notably, our model achieves the highest reported performance on the ROUGE-L metric compared to relevant state-of-the-art models in the literature. Furthermore, we employed both human evaluation and clinical semantic similarity measurement alongside word-overlap metrics to improve the depth of quantitative analysis. A human evaluation, conducted by a board-certified radiologist, confirms the model's accuracy in identifying high-level findings, however, it also highlights that more improvement is needed to capture nuanced details and clinical context.