 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnravelling the Mechanisms of Manipulating Numbers in Language Models
Oct 30, 2025



Recent work has shown that different large language models (LLMs) converge to similar and accurate input embedding representations for numbers. These findings conflict with the documented propensity of LLMs to produce erroneous outputs when dealing with numeric information. In this work, we aim to explain this conflict by exploring how language models manipulate numbers and quantify the lower bounds of accuracy of these mechanisms. We find that despite surfacing errors, different language models learn interchangeable representations of numbers that are systematic, highly accurate and universal across their hidden states and the types of input contexts. This allows us to create universal probes for each LLM and to trace information -- including the causes of output errors -- to specific layers. Our results lay a fundamental understanding of how pre-trained LLMs manipulate numbers and outline the potential of more accurate probing techniques in addressed refinements of LLMs' architectures.
Confabulations from ACL Publications (CAP): A Dataset for Scientific Hallucination Detection
Oct 25, 2025


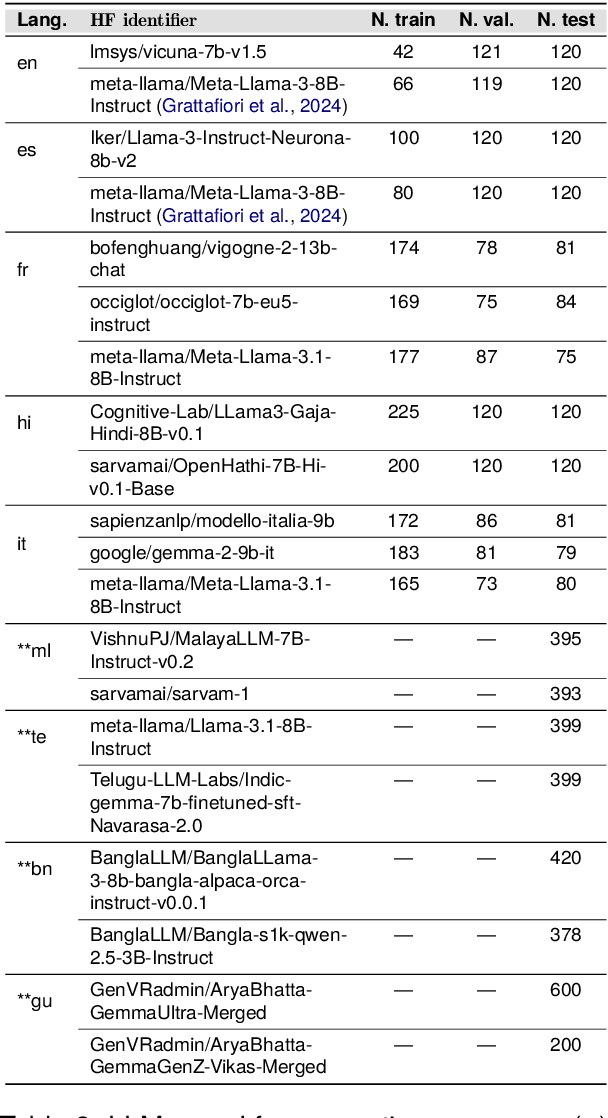
We introduce the CAP (Confabulations from ACL Publications) dataset, a multilingual resource for studying hallucinations in large language models (LLMs) within scientific text generation. CAP focuses on the scientific domain, where hallucinations can distort factual knowledge, as they frequently do. In this domain, however, the presence of specialized terminology, statistical reasoning, and context-dependent interpretations further exacerbates these distortions, particularly given LLMs' lack of true comprehension, limited contextual understanding, and bias toward surface-level generalization. CAP operates in a cross-lingual setting covering five high-resource languages (English, French, Hindi, Italian, and Spanish) and four low-resource languages (Bengali, Gujarati, Malayalam, and Telugu). The dataset comprises 900 curated scientific questions and over 7000 LLM-generated answers from 16 publicly available models, provided as question-answer pairs along with token sequences and corresponding logits. Each instance is annotated with a binary label indicating the presence of a scientific hallucination, denoted as a factuality error, and a fluency label, capturing issues in the linguistic quality or naturalness of the text. CAP is publicly released to facilitate advanced research on hallucination detection, multilingual evaluation of LLMs, and the development of more reliable scientific NLP systems.
ImmunoFOMO: Are Language Models missing what oncologists see?
Jun 13, 2025Language models (LMs) capabilities have grown with a fast pace over the past decade leading researchers in various disciplines, such as biomedical research, to increasingly explore the utility of LMs in their day-to-day applications. Domain specific language models have already been in use for biomedical natural language processing (NLP) applications. Recently however, the interest has grown towards medical language models and their understanding capabilities. In this paper, we investigate the medical conceptual grounding of various language models against expert clinicians for identification of hallmarks of immunotherapy in breast cancer abstracts. Our results show that pre-trained language models have potential to outperform large language models in identifying very specific (low-level) concepts.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
Your Model is Overconfident, and Other Lies We Tell Ourselves
Mar 03, 2025The difficulty intrinsic to a given example, rooted in its inherent ambiguity, is a key yet often overlooked factor in evaluating neural NLP models. We investigate the interplay and divergence among various metrics for assessing intrinsic difficulty, including annotator dissensus, training dynamics, and model confidence. Through a comprehensive analysis using 29 models on three datasets, we reveal that while correlations exist among these metrics, their relationships are neither linear nor monotonic. By disentangling these dimensions of uncertainty, we aim to refine our understanding of data complexity and its implications for evaluating and improving NLP models.
Rate-Informed Discovery via Bayesian Adaptive Multifidelity Sampling
Nov 26, 2024



Ensuring the safety of autonomous vehicles (AVs) requires both accurate estimation of their performance and efficient discovery of potential failure cases. This paper introduces Bayesian adaptive multifidelity sampling (BAMS), which leverages the power of adaptive Bayesian sampling to achieve efficient discovery while simultaneously estimating the rate of adverse events. BAMS prioritizes exploration of regions with potentially low performance, leading to the identification of novel and critical scenarios that traditional methods might miss. Using real-world AV data we demonstrate that BAMS discovers 10 times as many issues as Monte Carlo (MC) and importance sampling (IS) baselines, while at the same time generating rate estimates with variances 15 and 6 times narrower than MC and IS baselines respectively.
BERT-Based Approach for Automating Course Articulation Matrix Construction with Explainable AI
Nov 21, 2024



Course Outcome (CO) and Program Outcome (PO)/Program-Specific Outcome (PSO) alignment is a crucial task for ensuring curriculum coherence and assessing educational effectiveness. The construction of a Course Articulation Matrix (CAM), which quantifies the relationship between COs and POs/PSOs, typically involves assigning numerical values (0, 1, 2, 3) to represent the degree of alignment. In this study, We experiment with four models from the BERT family: BERT Base, DistilBERT, ALBERT, and RoBERTa, and use multiclass classification to assess the alignment between CO and PO/PSO pairs. We first evaluate traditional machine learning classifiers, such as Decision Tree, Random Forest, and XGBoost, and then apply transfer learning to evaluate the performance of the pretrained BERT models. To enhance model interpretability, we apply Explainable AI technique, specifically Local Interpretable Model-agnostic Explanations (LIME), to provide transparency into the decision-making process. Our system achieves accuracy, precision, recall, and F1-score values of 98.66%, 98.67%, 98.66%, and 98.66%, respectively. This work demonstrates the potential of utilizing transfer learning with BERT-based models for the automated generation of CAMs, offering high performance and interpretability in educational outcome assessment.
Retrieve, Generate, Evaluate: A Case Study for Medical Paraphrases Generation with Small Language Models
Jul 23, 2024Recent surge in the accessibility of large language models (LLMs) to the general population can lead to untrackable use of such models for medical-related recommendations. Language generation via LLMs models has two key problems: firstly, they are prone to hallucination and therefore, for any medical purpose they require scientific and factual grounding; secondly, LLMs pose tremendous challenge to computational resources due to their gigantic model size. In this work, we introduce pRAGe, a pipeline for Retrieval Augmented Generation and evaluation of medical paraphrases generation using Small Language Models (SLM). We study the effectiveness of SLMs and the impact of external knowledge base for medical paraphrase generation in French.
Domain-specific or Uncertainty-aware models: Does it really make a difference for biomedical text classification?
Jul 17, 2024



The success of pretrained language models (PLMs) across a spate of use-cases has led to significant investment from the NLP community towards building domain-specific foundational models. On the other hand, in mission critical settings such as biomedical applications, other aspects also factor in-chief of which is a model's ability to produce reasonable estimates of its own uncertainty. In the present study, we discuss these two desiderata through the lens of how they shape the entropy of a model's output probability distribution. We find that domain specificity and uncertainty awareness can often be successfully combined, but the exact task at hand weighs in much more strongly.
Exploring the Nexus Between Retrievability and Query Generation Strategies
Apr 15, 2024Quantifying bias in retrieval functions through document retrievability scores is vital for assessing recall-oriented retrieval systems. However, many studies investigating retrieval model bias lack validation of their query generation methods as accurate representations of retrievability for real users and their queries. This limitation results from the absence of established criteria for query generation in retrievability assessments. Typically, researchers resort to using frequent collocations from document corpora when no query log is available. In this study, we address the issue of reproducibility and seek to validate query generation methods by comparing retrievability scores generated from artificially generated queries to those derived from query logs. Our findings demonstrate a minimal or negligible correlation between retrievability scores from artificial queries and those from query logs. This suggests that artificially generated queries may not accurately reflect retrievability scores as derived from query logs. We further explore alternative query generation techniques, uncovering a variation that exhibits the highest correlation. This alternative approach holds promise for improving reproducibility when query logs are unavailable.