 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-View Person Matching and 3D Pose Estimation with Arbitrary Uncalibrated Camera Networks
Dec 04, 2023
Cross-view person matching and 3D human pose estimation in multi-camera networks are particularly difficult when the cameras are extrinsically uncalibrated. Existing efforts generally require large amounts of 3D data for training neural networks or known camera poses for geometric constraints to solve the problem. However, camera poses and 3D data annotation are usually expensive and not always available. We present a method, PME, that solves the two tasks without requiring either information. Our idea is to address cross-view person matching as a clustering problem using each person as a cluster center, then obtain correspondences from person matches, and estimate 3D human poses through multi-view triangulation and bundle adjustment. We solve the clustering problem by introducing a "size constraint" using the number of cameras and a "source constraint" using the fact that two people from the same camera view should not match, to narrow the solution space to a small feasible region. The 2D human poses used in clustering are obtained through a pre-trained 2D pose detector, so our method does not require expensive 3D training data for each new scene. We extensively evaluate our method on three open datasets and two indoor and outdoor datasets collected using arbitrarily set cameras. Our method outperforms other methods by a large margin on cross-view person matching, reaches SOTA performance on 3D human pose estimation without using either camera poses or 3D training data, and shows good generalization ability across five datasets of various environment settings.
MIR2: Towards Provably Robust Multi-Agent Reinforcement Learning by Mutual Information Regularization
Oct 15, 2023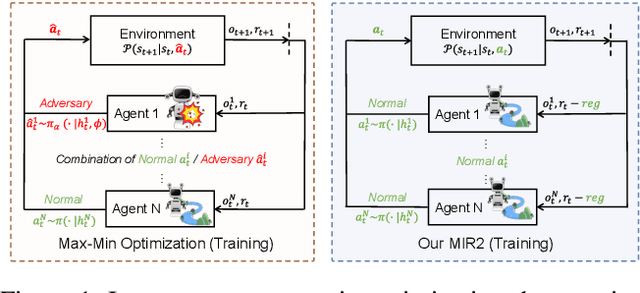

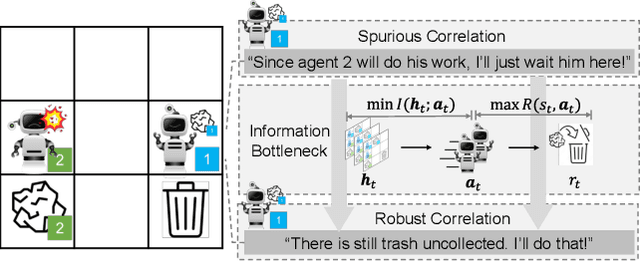
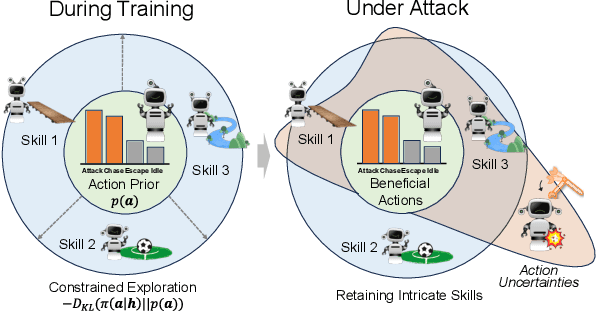
Robust multi-agent reinforcement learning (MARL) necessitates resilience to uncertain or worst-case actions by unknown allies. Existing max-min optimization techniques in robust MARL seek to enhance resilience by training agents against worst-case adversaries, but this becomes intractable as the number of agents grows, leading to exponentially increasing worst-case scenarios. Attempts to simplify this complexity often yield overly pessimistic policies, inadequate robustness across scenarios and high computational demands. Unlike these approaches, humans naturally learn adaptive and resilient behaviors without the necessity of preparing for every conceivable worst-case scenario. Motivated by this, we propose MIR2, which trains policy in routine scenarios and minimize Mutual Information as Robust Regularization. Theoretically, we frame robustness as an inference problem and prove that minimizing mutual information between histories and actions implicitly maximizes a lower bound on robustness under certain assumptions. Further analysis reveals that our proposed approach prevents agents from overreacting to others through an information bottleneck and aligns the policy with a robust action prior. Empirically, our MIR2 displays even greater resilience against worst-case adversaries than max-min optimization in StarCraft II, Multi-agent Mujoco and rendezvous. Our superiority is consistent when deployed in challenging real-world robot swarm control scenario. See code and demo videos in Supplementary Materials.
Sparse Beats Dense: Rethinking Supervision in Radar-Camera Depth Completion
Dec 01, 2023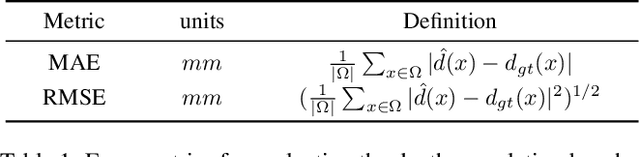

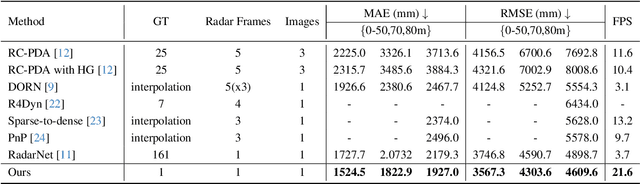
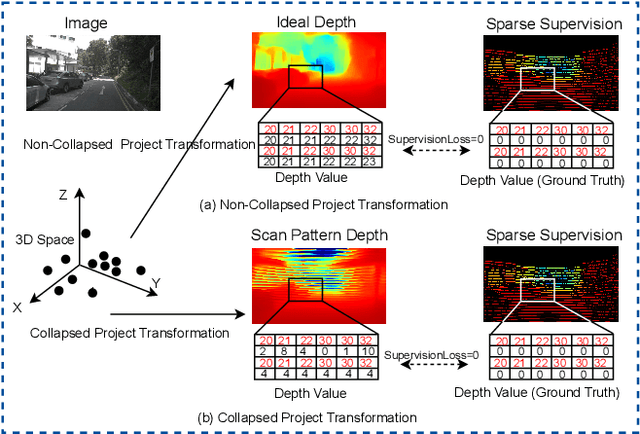
It is widely believed that the dense supervision is better than the sparse supervision in the field of depth completion, but the underlying reasons for this are rarely discussed. In this paper, we find that the challenge of using sparse supervision for training Radar-Camera depth prediction models is the Projection Transformation Collapse (PTC). The PTC implies that sparse supervision leads the model to learn unexpected collapsed projection transformations between Image/Radar/LiDAR spaces. Building on this insight, we propose a novel ``Disruption-Compensation" framework to handle the PTC, thereby relighting the use of sparse supervision in depth completion tasks. The disruption part deliberately discards position correspondences among Image/Radar/LiDAR, while the compensation part leverages 3D spatial and 2D semantic information to compensate for the discarded beneficial position correspondence. Extensive experimental results demonstrate that our framework (sparse supervision) outperforms the state-of-the-art (dense supervision) with 11.6$\%$ improvement in mean absolute error and $1.6 \times$ speedup. The code is available at ...
RadioGalaxyNET: Dataset and Novel Computer Vision Algorithms for the Detection of Extended Radio Galaxies and Infrared Hosts
Dec 01, 2023Creating radio galaxy catalogues from next-generation deep surveys requires automated identification of associated components of extended sources and their corresponding infrared hosts. In this paper, we introduce RadioGalaxyNET, a multimodal dataset, and a suite of novel computer vision algorithms designed to automate the detection and localization of multi-component extended radio galaxies and their corresponding infrared hosts. The dataset comprises 4,155 instances of galaxies in 2,800 images with both radio and infrared channels. Each instance provides information about the extended radio galaxy class, its corresponding bounding box encompassing all components, the pixel-level segmentation mask, and the keypoint position of its corresponding infrared host galaxy. RadioGalaxyNET is the first dataset to include images from the highly sensitive Australian Square Kilometre Array Pathfinder (ASKAP) radio telescope, corresponding infrared images, and instance-level annotations for galaxy detection. We benchmark several object detection algorithms on the dataset and propose a novel multimodal approach to simultaneously detect radio galaxies and the positions of infrared hosts.
Mutual Information-Based Integrated Sensing and Communications: A WMMSE Framework
Oct 19, 2023In this letter, a weighted minimum mean square error (WMMSE) empowered integrated sensing and communication (ISAC) system is investigated. One transmitting base station and one receiving wireless access point are considered to serve multiple users a sensing target. Based on the theory of mutual-information (MI), communication MI and sensing MI rate are utilized as the performance metrics under the presence of clutters. In particular, we propose an novel MI-based WMMSE-ISAC method by developing a unique transceiver design mechanism to maximize the weighted sensing and communication sum-rate of this system. Such a maximization process is achieved by utilizing the classical method -- WMMSE, aiming to better manage the effect of sensing clutters and the interference among users. Numerical results show the effectiveness of our proposed method, and the performance trade-off between sensing and communication is also validated.
Word for Person: Zero-shot Composed Person Retrieval
Nov 25, 2023Searching for specific person has great security value and social benefits, and it often involves a combination of visual and textual information. Conventional person retrieval methods, whether image-based or text-based, usually fall short in effectively harnessing both types of information, leading to the loss of accuracy. In this paper, a whole new task called Composed Person Retrieval (CPR) is proposed to jointly utilize both image and text information for target person retrieval. However, the supervised CPR must depend on very costly manual annotation dataset, while there are currently no available resources. To mitigate this issue, we firstly introduce the Zero-shot Composed Person Retrieval (ZS-CPR), which leverages existing domain-related data to resolve the CPR problem without reliance on expensive annotations. Secondly, to learn ZS-CPR model, we propose a two-stage learning framework, Word4Per, where a lightweight Textual Inversion Network (TINet) and a text-based person retrieval model based on fine-tuned Contrastive Language-Image Pre-training (CLIP) network are learned without utilizing any CPR data. Thirdly, a finely annotated Image-Text Composed Person Retrieval dataset (ITCPR) is built as the benchmark to assess the performance of the proposed Word4Per framework. Extensive experiments under both Rank-1 and mAP demonstrate the effectiveness of Word4Per for the ZS-CPR task, surpassing the comparative methods by over 10%. The code and ITCPR dataset will be publicly available at https://github.com/Delong-liu-bupt/Word4Per.
SAGE: Bridging Semantic and Actionable Parts for GEneralizable Articulated-Object Manipulation under Language Instructions
Dec 03, 2023Generalizable manipulation of articulated objects remains a challenging problem in many real-world scenarios, given the diverse object structures, functionalities, and goals. In these tasks, both semantic interpretations and physical plausibilities are crucial for a policy to succeed. To address this problem, we propose SAGE, a novel framework that bridges the understanding of semantic and actionable parts of articulated objects to achieve generalizable manipulation under language instructions. Given a manipulation goal specified by natural language, an instruction interpreter with Large Language Models (LLMs) first translates them into programmatic actions on the object's semantic parts. This process also involves a scene context parser for understanding the visual inputs, which is designed to generate scene descriptions with both rich information and accurate interaction-related facts by joining the forces of generalist Visual-Language Models (VLMs) and domain-specialist part perception models. To further convert the action programs into executable policies, a part grounding module then maps the object semantic parts suggested by the instruction interpreter into so-called Generalizable Actionable Parts (GAParts). Finally, an interactive feedback module is incorporated to respond to failures, which greatly increases the robustness of the overall framework. Experiments both in simulation environments and on real robots show that our framework can handle a large variety of articulated objects with diverse language-instructed goals. We also provide a new benchmark for language-guided articulated-object manipulation in realistic scenarios.
Anomaly Detection Under Uncertainty Using Distributionally Robust Optimization Approach
Dec 03, 2023Anomaly detection is defined as the problem of finding data points that do not follow the patterns of the majority. Among the various proposed methods for solving this problem, classification-based methods, including one-class Support Vector Machines (SVM) are considered effective and state-of-the-art. The one-class SVM method aims to find a decision boundary to distinguish between normal data points and anomalies using only the normal data. On the other hand, most real-world problems involve some degree of uncertainty, where the true probability distribution of each data point is unknown, and estimating it is often difficult and costly. Assuming partial distribution information such as the first and second-order moments is known, a distributionally robust chance-constrained model is proposed in which the probability of misclassification is low. By utilizing a mapping function to a higher dimensional space, the proposed model will be capable of classifying origin-inseparable datasets. Also, by adopting the kernel idea, the need for explicitly knowing the mapping is eliminated, computations can be performed in the input space, and computational complexity is reduced. Computational results validate the robustness of the proposed model under different probability distributions and also the superiority of the proposed model compared to the standard one-class SVM in terms of various evaluation metrics.
Too Much Information: Keeping Training Simple for BabyLMs
Nov 03, 2023This paper details the work of the University of Groningen for the BabyLM Challenge. We follow the idea that, like babies, language models should be introduced to simpler concepts first and build off of that knowledge to understand more complex concepts. We examine this strategy of simple-then-complex through a variety of lenses, namely context size, vocabulary, and overall linguistic complexity of the data. We find that only one, context size, is truly beneficial to training a language model. However this simple change to context size gives us improvements of 2 points on average on (Super)GLUE tasks, 1 point on MSGS tasks, and 12\% on average on BLiMP tasks. Our context-limited model outperforms the baseline that was trained on 10$\times$ the amount of data.
De-identification of clinical free text using natural language processing: A systematic review of current approaches
Nov 28, 2023Background: Electronic health records (EHRs) are a valuable resource for data-driven medical research. However, the presence of protected health information (PHI) makes EHRs unsuitable to be shared for research purposes. De-identification, i.e. the process of removing PHI is a critical step in making EHR data accessible. Natural language processing has repeatedly demonstrated its feasibility in automating the de-identification process. Objectives: Our study aims to provide systematic evidence on how the de-identification of clinical free text has evolved in the last thirteen years, and to report on the performances and limitations of the current state-of-the-art systems. In addition, we aim to identify challenges and potential research opportunities in this field. Methods: A systematic search in PubMed, Web of Science and the DBLP was conducted for studies published between January 2010 and February 2023. Titles and abstracts were examined to identify the relevant studies. Selected studies were then analysed in-depth, and information was collected on de-identification methodologies, data sources, and measured performance. Results: A total of 2125 publications were identified for the title and abstract screening. 69 studies were found to be relevant. Machine learning (37 studies) and hybrid (26 studies) approaches are predominant, while six studies relied only on rules. Majority of the approaches were trained and evaluated on public corpora. The 2014 i2b2/UTHealth corpus is the most frequently used (36 studies), followed by the 2006 i2b2 (18 studies) and 2016 CEGS N-GRID (10 studies) corpora.