 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Merging to Maintain Language-Only Performance in Developmentally Plausible Multimodal Models
Oct 02, 2025



State-of-the-art vision-and-language models consist of many parameters and learn from enormous datasets, surpassing the amounts of linguistic data that children are exposed to as they acquire a language. This paper presents our approach to the multimodal track of the BabyLM challenge addressing this discrepancy. We develop language-only and multimodal models in low-resource settings using developmentally plausible datasets, with our multimodal models outperforming previous BabyLM baselines. One finding in the multimodal language model literature is that these models tend to underperform in \textit{language-only} tasks. Therefore, we focus on maintaining language-only abilities in multimodal models. To this end, we experiment with \textit{model merging}, where we fuse the parameters of multimodal models with those of language-only models using weighted linear interpolation. Our results corroborate the findings that multimodal models underperform in language-only benchmarks that focus on grammar, and model merging with text-only models can help alleviate this problem to some extent, while maintaining multimodal performance.
Are BabyLMs Second Language Learners?
Oct 28, 2024



This paper describes a linguistically-motivated approach to the 2024 edition of the BabyLM Challenge (Warstadt et al. 2023). Rather than pursuing a first language learning (L1) paradigm, we approach the challenge from a second language (L2) learning perspective. In L2 learning, there is a stronger focus on learning explicit linguistic information, such as grammatical notions, definitions of words or different ways of expressing a meaning. This makes L2 learning potentially more efficient and concise. We approximate this using data from Wiktionary, grammar examples either generated by an LLM or sourced from grammar books, and paraphrase data. We find that explicit information about word meaning (in our case, Wiktionary) does not boost model performance, while grammatical information can give a small improvement. The most impactful data ingredient is sentence paraphrases, with our two best models being trained on 1) a mix of paraphrase data and data from the BabyLM pretraining dataset, and 2) exclusively paraphrase data.
Individuation in Neural Models with and without Visual Grounding
Sep 27, 2024We show differences between a language-and-vision model CLIP and two text-only models - FastText and SBERT - when it comes to the encoding of individuation information. We study latent representations that CLIP provides for substrates, granular aggregates, and various numbers of objects. We demonstrate that CLIP embeddings capture quantitative differences in individuation better than models trained on text-only data. Moreover, the individuation hierarchy we deduce from the CLIP embeddings agrees with the hierarchies proposed in linguistics and cognitive science.
Black Big Boxes: Do Language Models Hide a Theory of Adjective Order?
Jul 02, 2024



In English and other languages, multiple adjectives in a complex noun phrase show intricate ordering patterns that have been a target of much linguistic theory. These patterns offer an opportunity to assess the ability of language models (LMs) to learn subtle rules of language involving factors that cross the traditional divisions of syntax, semantics, and pragmatics. We review existing hypotheses designed to explain Adjective Order Preferences (AOPs) in humans and develop a setup to study AOPs in LMs: we present a reusable corpus of adjective pairs and define AOP measures for LMs. With these tools, we study a series of LMs across intermediate checkpoints during training. We find that all models' predictions are much closer to human AOPs than predictions generated by factors identified in theoretical linguistics. At the same time, we demonstrate that the observed AOPs in LMs are strongly correlated with the frequency of the adjective pairs in the training data and report limited generalization to unseen combinations. This highlights the difficulty in establishing the link between LM performance and linguistic theory. We therefore conclude with a road map for future studies our results set the stage for, and a discussion of key questions about the nature of knowledge in LMs and their ability to generalize beyond the training sets.
Too Much Information: Keeping Training Simple for BabyLMs
Nov 03, 2023



This paper details the work of the University of Groningen for the BabyLM Challenge. We follow the idea that, like babies, language models should be introduced to simpler concepts first and build off of that knowledge to understand more complex concepts. We examine this strategy of simple-then-complex through a variety of lenses, namely context size, vocabulary, and overall linguistic complexity of the data. We find that only one, context size, is truly beneficial to training a language model. However this simple change to context size gives us improvements of 2 points on average on (Super)GLUE tasks, 1 point on MSGS tasks, and 12\% on average on BLiMP tasks. Our context-limited model outperforms the baseline that was trained on 10$\times$ the amount of data.
Leverage Points in Modality Shifts: Comparing Language-only and Multimodal Word Representations
Jun 04, 2023Multimodal embeddings aim to enrich the semantic information in neural representations of language compared to text-only models. While different embeddings exhibit different applicability and performance on downstream tasks, little is known about the systematic representation differences attributed to the visual modality. Our paper compares word embeddings from three vision-and-language models (CLIP, OpenCLIP and Multilingual CLIP) and three text-only models, with static (FastText) as well as contextual representations (multilingual BERT; XLM-RoBERTa). This is the first large-scale study of the effect of visual grounding on language representations, including 46 semantic parameters. We identify meaning properties and relations that characterize words whose embeddings are most affected by the inclusion of visual modality in the training data; that is, points where visual grounding turns out most important. We find that the effect of visual modality correlates most with denotational semantic properties related to concreteness, but is also detected for several specific semantic classes, as well as for valence, a sentiment-related connotational property of linguistic expressions.
Old BERT, New Tricks: Artificial Language Learning for Pre-Trained Language Models
Sep 13, 2021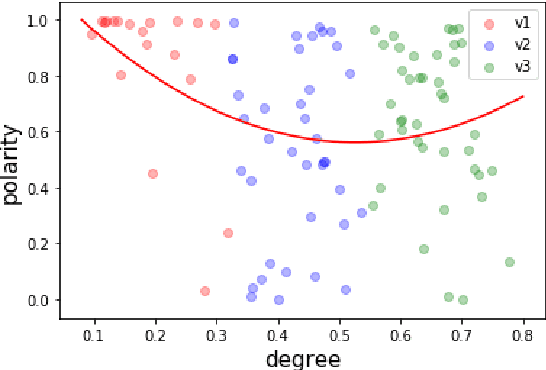
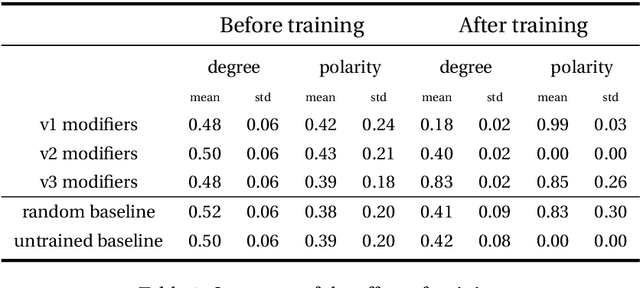
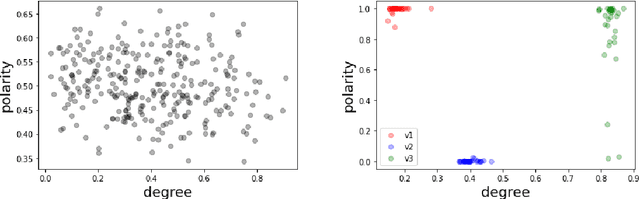
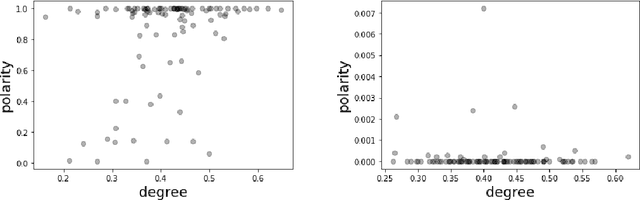
We extend the artificial language learning experimental paradigm from psycholinguistics and apply it to pre-trained language models -- specifically, BERT (Devlin et al., 2019). We treat the model as a subject in an artificial language learning experimental setting: in order to learn the relation between two linguistic properties A and B, we introduce a set of new, non-existent, linguistic items, give the model information about their variation along property A, then measure to what extent the model learns property B for these items as a result of training. We show this method at work for degree modifiers (expressions like "slightly", "very", "rather", "extremely") and test the hypothesis that the degree expressed by modifiers (low, medium or high degree) is related to their sensitivity to sentence polarity (whether they show preference for affirmative or negative sentences or neither). Our experimental results are compatible with existing linguistic observations that relate degree semantics to polarity-sensitivity, including the main one: low degree semantics leads to positive polarity sensitivity (that is, to preference towards affirmative contexts). The method can be used in linguistics to elaborate on hypotheses and interpret experimental results, as well as for more insightful evaluation of linguistic representations in language models.
Transformers in the loop: Polarity in neural models of language
Sep 08, 2021
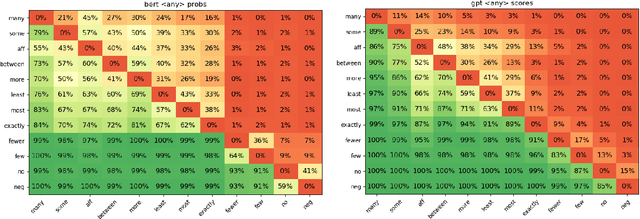
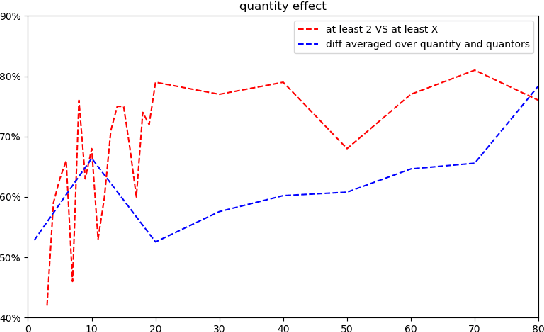
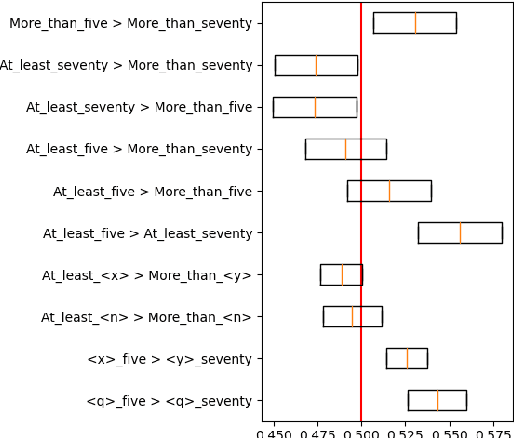
Representation of linguistic phenomena in computational language models is typically assessed against the predictions of existing linguistic theories of these phenomena. Using the notion of polarity as a case study, we show that this is not always the most adequate set-up. We probe polarity via so-called 'negative polarity items' (in particular, English 'any') in two pre-trained Transformer-based models (BERT and GPT-2). We show that -- at least for polarity -- metrics derived from language models are more consistent with data from psycholinguistic experiments than linguistic theory predictions. Establishing this allows us to more adequately evaluate the performance of language models and also to use language models to discover new insights into natural language grammar beyond existing linguistic theories. Overall, our results encourage a closer tie between experiments with human subjects and with language models. We propose methods to enable this closer tie, with language models as part of experimental pipeline, and show this pipeline at work.