 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Value-Based Reinforcement Learning for Digital Twins in Cloud Computing
Nov 27, 2023
The setup considered in the paper consists of sensors in a Networked Control System that are used to build a digital twin (DT) model of the system dynamics. The focus is on control, scheduling, and resource allocation for sensory observation to ensure timely delivery to the DT model deployed in the cloud. Low latency and communication timeliness are instrumental in ensuring that the DT model can accurately estimate and predict system states. However, acquiring data for efficient state estimation and control computing poses a non-trivial problem given the limited network resources, partial state vector information, and measurement errors encountered at distributed sensors. We propose the REinforcement learning and Variational Extended Kalman filter with Robust Belief (REVERB), which leverages a reinforcement learning solution combined with a Value of Information-based algorithm for performing optimal control and selecting the most informative sensors to satisfy the prediction accuracy of DT. Numerical results demonstrate that the DT platform can offer satisfactory performance while reducing the communication overhead up to five times.
MARIS: Referring Image Segmentation via Mutual-Aware Attention Features
Nov 27, 2023
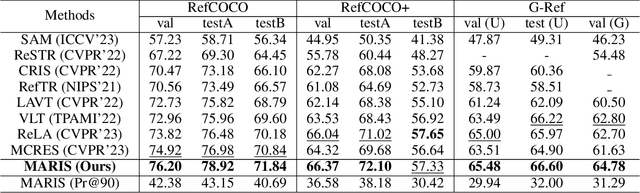

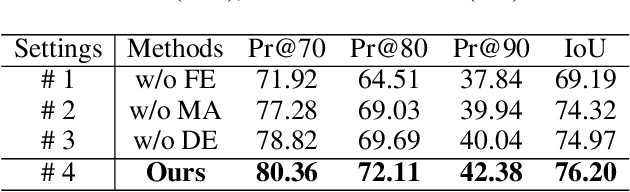
Referring image segmentation (RIS) aims to segment a particular region based on a language expression prompt. Existing methods incorporate linguistic features into visual features and obtain multi-modal features for mask decoding. However, these methods may segment the visually salient entity instead of the correct referring region, as the multi-modal features are dominated by the abundant visual context. In this paper, we propose MARIS, a referring image segmentation method that leverages the Segment Anything Model (SAM) and introduces a mutual-aware attention mechanism to enhance the cross-modal fusion via two parallel branches. Specifically, our mutual-aware attention mechanism consists of Vision-Guided Attention and Language-Guided Attention, which bidirectionally model the relationship between visual and linguistic features. Correspondingly, we design a Mask Decoder to enable explicit linguistic guidance for more consistent segmentation with the language expression. To this end, a multi-modal query token is proposed to integrate linguistic information and interact with visual information simultaneously. Extensive experiments on three benchmark datasets show that our method outperforms the state-of-the-art RIS methods. Our code will be publicly available.
Towards Vision Enhancing LLMs: Empowering Multimodal Knowledge Storage and Sharing in LLMs
Nov 27, 2023Recent advancements in multimodal large language models (MLLMs) have achieved significant multimodal generation capabilities, akin to GPT-4. These models predominantly map visual information into language representation space, leveraging the vast knowledge and powerful text generation abilities of LLMs to produce multimodal instruction-following responses. We could term this method as LLMs for Vision because of its employing LLMs for visual-language understanding, yet observe that these MLLMs neglect the potential of harnessing visual knowledge to enhance overall capabilities of LLMs, which could be regraded as Vision Enhancing LLMs. In this paper, we propose an approach called MKS2, aimed at enhancing LLMs through empowering Multimodal Knowledge Storage and Sharing in LLMs. Specifically, we introduce the Modular Visual Memory, a component integrated into the internal blocks of LLMs, designed to store open-world visual information efficiently. Additionally, we present a soft Mixtures-of-Multimodal Experts architecture in LLMs to invoke multimodal knowledge collaboration during generation. Our comprehensive experiments demonstrate that MKS2 substantially augments the reasoning capabilities of LLMs in contexts necessitating physical or commonsense knowledge. It also delivers competitive results on multimodal benchmarks.
Learning-based Scheduling for Information Accuracy and Freshness in Wireless Networks
Oct 24, 2023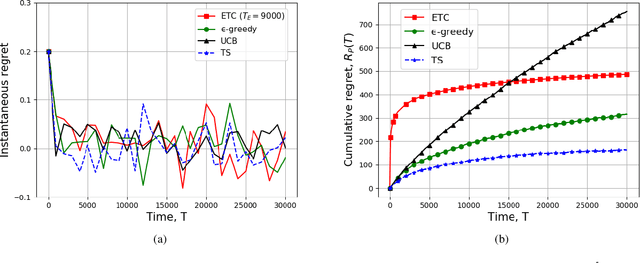
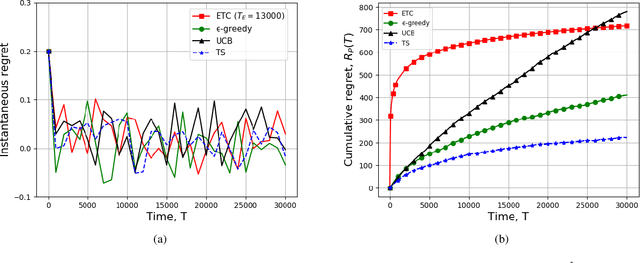
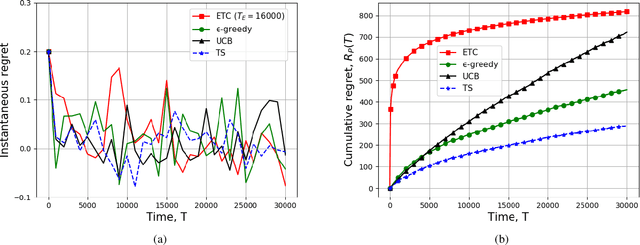
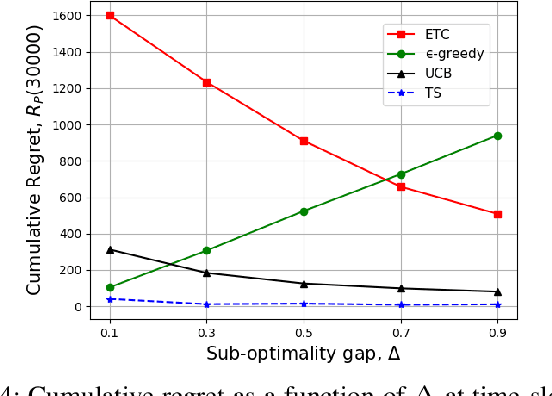
We consider a system of multiple sources, a single communication channel, and a single monitoring station. Each source measures a time-varying quantity with varying levels of accuracy and one of them sends its update to the monitoring station via the channel. The probability of success of each attempted communication is a function of the source scheduled for transmitting its update. Both the probability of correct measurement and the probability of successful transmission of all the sources are unknown to the scheduler. The metric of interest is the reward received by the system which depends on the accuracy of the last update received by the destination and the Age-of-Information (AoI) of the system. We model our scheduling problem as a variant of the multi-arm bandit problem with sources as different arms. We compare the performance of all $4$ standard bandit policies, namely, ETC, $\epsilon$-greedy, UCB, and TS suitably adjusted to our system model via simulations. In addition, we provide analytical guarantees of $2$ of these policies, ETC, and $\epsilon$-greedy. Finally, we characterize the lower bound on the cumulative regret achievable by any policy.
Highly Detailed and Temporal Consistent Video Stylization via Synchronized Multi-Frame Diffusion
Nov 24, 2023Text-guided video-to-video stylization transforms the visual appearance of a source video to a different appearance guided on textual prompts. Existing text-guided image diffusion models can be extended for stylized video synthesis. However, they struggle to generate videos with both highly detailed appearance and temporal consistency. In this paper, we propose a synchronized multi-frame diffusion framework to maintain both the visual details and the temporal consistency. Frames are denoised in a synchronous fashion, and more importantly, information of different frames is shared since the beginning of the denoising process. Such information sharing ensures that a consensus, in terms of the overall structure and color distribution, among frames can be reached in the early stage of the denoising process before it is too late. The optical flow from the original video serves as the connection, and hence the venue for information sharing, among frames. We demonstrate the effectiveness of our method in generating high-quality and diverse results in extensive experiments. Our method shows superior qualitative and quantitative results compared to state-of-the-art video editing methods.
Video Summarization: Towards Entity-Aware Captions
Dec 01, 2023Existing popular video captioning benchmarks and models deal with generic captions devoid of specific person, place or organization named entities. In contrast, news videos present a challenging setting where the caption requires such named entities for meaningful summarization. As such, we propose the task of summarizing news video directly to entity-aware captions. We also release a large-scale dataset, VIEWS (VIdeo NEWS), to support research on this task. Further, we propose a method that augments visual information from videos with context retrieved from external world knowledge to generate entity-aware captions. We demonstrate the effectiveness of our approach on three video captioning models. We also show that our approach generalizes to existing news image captions dataset. With all the extensive experiments and insights, we believe we establish a solid basis for future research on this challenging task.
Augmented Kinesthetic Teaching: Enhancing Task Execution Efficiency through Intuitive Human Instructions
Dec 01, 2023In this paper, we present a complete and efficient implementation of a knowledge-sharing augmented kinesthetic teaching approach for efficient task execution in robotics. Our augmented kinesthetic teaching method integrates intuitive human feedback, including verbal, gesture, gaze, and physical guidance, to facilitate the extraction of multiple layers of task information including control type, attention direction, input and output type, action state change trigger, etc., enhancing the adaptability and autonomy of robots during task execution. We propose an efficient Programming by Demonstration (PbD) framework for users with limited technical experience to teach the robot in an intuitive manner. The proposed framework provides an interface for such users to teach customized tasks using high-level commands, with the goal of achieving a smoother teaching experience and task execution. This is demonstrated with the sample task of pouring water.
Multiview Transformer: Rethinking Spatial Information in Hyperspectral Image Classification
Oct 11, 2023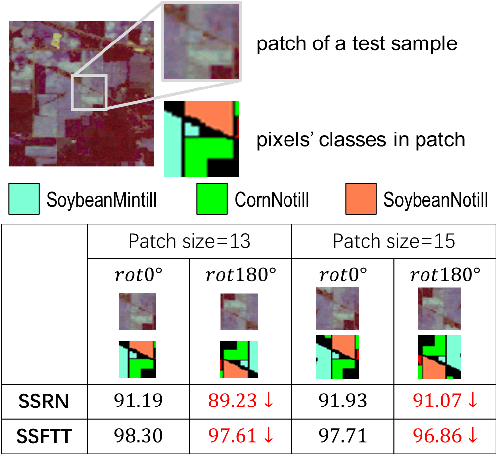
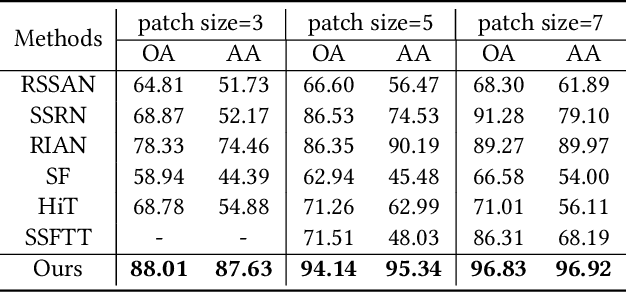

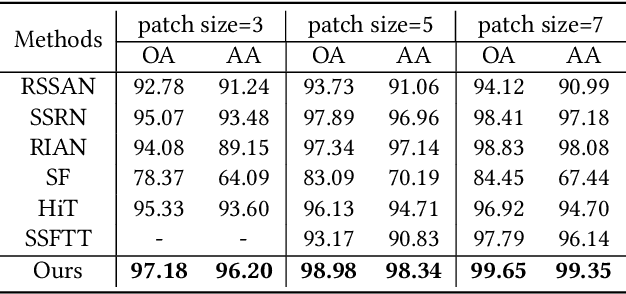
Identifying the land cover category for each pixel in a hyperspectral image (HSI) relies on spectral and spatial information. An HSI cuboid with a specific patch size is utilized to extract spatial-spectral feature representation for the central pixel. In this article, we investigate that scene-specific but not essential correlations may be recorded in an HSI cuboid. This additional information improves the model performance on existing HSI datasets and makes it hard to properly evaluate the ability of a model. We refer to this problem as the spatial overfitting issue and utilize strict experimental settings to avoid it. We further propose a multiview transformer for HSI classification, which consists of multiview principal component analysis (MPCA), spectral encoder-decoder (SED), and spatial-pooling tokenization transformer (SPTT). MPCA performs dimension reduction on an HSI via constructing spectral multiview observations and applying PCA on each view data to extract low-dimensional view representation. The combination of view representations, named multiview representation, is the dimension reduction output of the MPCA. To aggregate the multiview information, a fully-convolutional SED with a U-shape in spectral dimension is introduced to extract a multiview feature map. SPTT transforms the multiview features into tokens using the spatial-pooling tokenization strategy and learns robust and discriminative spatial-spectral features for land cover identification. Classification is conducted with a linear classifier. Experiments on three HSI datasets with rigid settings demonstrate the superiority of the proposed multiview transformer over the state-of-the-art methods.
Learning Multi-graph Structure for Temporal Knowledge Graph Reasoning
Dec 04, 2023Temporal Knowledge Graph (TKG) reasoning that forecasts future events based on historical snapshots distributed over timestamps is denoted as extrapolation and has gained significant attention. Owing to its extreme versatility and variation in spatial and temporal correlations, TKG reasoning presents a challenging task, demanding efficient capture of concurrent structures and evolutional interactions among facts. While existing methods have made strides in this direction, they still fall short of harnessing the diverse forms of intrinsic expressive semantics of TKGs, which encompass entity correlations across multiple timestamps and periodicity of temporal information. This limitation constrains their ability to thoroughly reflect historical dependencies and future trends. In response to these drawbacks, this paper proposes an innovative reasoning approach that focuses on Learning Multi-graph Structure (LMS). Concretely, it comprises three distinct modules concentrating on multiple aspects of graph structure knowledge within TKGs, including concurrent and evolutional patterns along timestamps, query-specific correlations across timestamps, and semantic dependencies of timestamps, which capture TKG features from various perspectives. Besides, LMS incorporates an adaptive gate for merging entity representations both along and across timestamps effectively. Moreover, it integrates timestamp semantics into graph attention calculations and time-aware decoders, in order to impose temporal constraints on events and narrow down prediction scopes with historical statistics. Extensive experimental results on five event-based benchmark datasets demonstrate that LMS outperforms state-of-the-art extrapolation models, indicating the superiority of modeling a multi-graph perspective for TKG reasoning.
Improving embedding of graphs with missing data by soft manifolds
Nov 29, 2023Embedding graphs in continous spaces is a key factor in designing and developing algorithms for automatic information extraction to be applied in diverse tasks (e.g., learning, inferring, predicting). The reliability of graph embeddings directly depends on how much the geometry of the continuous space matches the graph structure. Manifolds are mathematical structure that can enable to incorporate in their topological spaces the graph characteristics, and in particular nodes distances. State-of-the-art of manifold-based graph embedding algorithms take advantage of the assumption that the projection on a tangential space of each point in the manifold (corresponding to a node in the graph) would locally resemble a Euclidean space. Although this condition helps in achieving efficient analytical solutions to the embedding problem, it does not represent an adequate set-up to work with modern real life graphs, that are characterized by weighted connections across nodes often computed over sparse datasets with missing records. In this work, we introduce a new class of manifold, named soft manifold, that can solve this situation. In particular, soft manifolds are mathematical structures with spherical symmetry where the tangent spaces to each point are hypocycloids whose shape is defined according to the velocity of information propagation across the data points. Using soft manifolds for graph embedding, we can provide continuous spaces to pursue any task in data analysis over complex datasets. Experimental results on reconstruction tasks on synthetic and real datasets show how the proposed approach enable more accurate and reliable characterization of graphs in continuous spaces with respect to the state-of-the-art.