 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Massive Wireless Energy Transfer without Channel State Information via Imperfect Intelligent Reflecting Surfaces
Nov 15, 2023
Intelligent Reflecting Surface (IRS) utilizes low-cost, passive reflecting elements to enhance the passive beam gain, improve Wireless Energy Transfer (WET) efficiency, and enable its deployment for numerous Internet of Things (IoT) devices. However, the increasing number of IRS elements presents considerable channel estimation challenges. This is due to the lack of active Radio Frequency (RF) chains in an IRS, while pilot overhead becomes intolerable. To address this issue, we propose a Channel State Information (CSI)-free scheme that maximizes received energy in a specific direction and covers the entire space through phased beam rotation. Furthermore, we take into account the impact of an imperfect IRS and meticulously design the active precoder and IRS reflecting phase shift to mitigate its effects. Our proposed technique does not alter the existing IRS hardware architecture, allowing for easy implementation in the current system, and enabling access or removal of any Energy Receivers (ERs) without additional cost. Numerical results illustrate the efficacy of our CSI-free scheme in facilitating large-scale IRS without compromising performance due to excessive pilot overhead. Furthermore, our scheme outperforms the CSI-based counterpart in scenarios involving large-scale ERs, making it a promising solution in the era of IoT.
Mitigating Perspective Distortion-induced Shape Ambiguity in Image Crops
Dec 11, 2023Objects undergo varying amounts of perspective distortion as they move across a camera's field of view. Models for predicting 3D from a single image often work with crops around the object of interest and ignore the location of the object in the camera's field of view. We note that ignoring this location information further exaggerates the inherent ambiguity in making 3D inferences from 2D images and can prevent models from even fitting to the training data. To mitigate this ambiguity, we propose Intrinsics-Aware Positional Encoding (KPE), which incorporates information about the location of crops in the image and camera intrinsics. Experiments on three popular 3D-from-a-single-image benchmarks: depth prediction on NYU, 3D object detection on KITTI & nuScenes, and predicting 3D shapes of articulated objects on ARCTIC, show the benefits of KPE.
Expression Syntax Information Bottleneck for Math Word Problems
Oct 24, 2023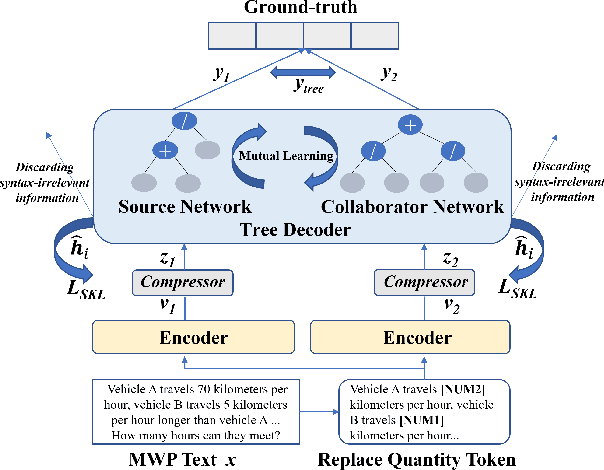
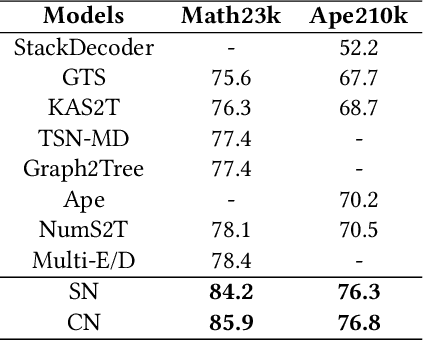
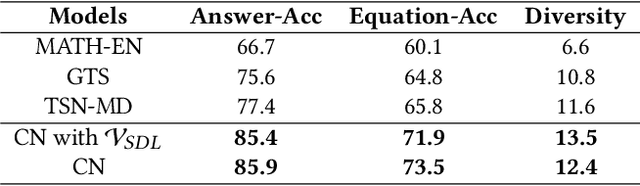
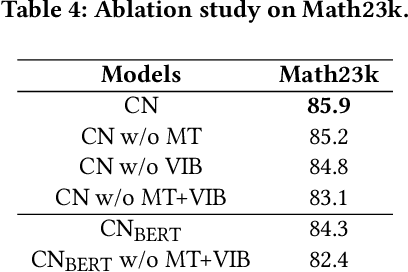
Math Word Problems (MWP) aims to automatically solve mathematical questions given in texts. Previous studies tend to design complex models to capture additional information in the original text so as to enable the model to gain more comprehensive features. In this paper, we turn our attention in the opposite direction, and work on how to discard redundant features containing spurious correlations for MWP. To this end, we design an Expression Syntax Information Bottleneck method for MWP (called ESIB) based on variational information bottleneck, which extracts essential features of expression syntax tree while filtering latent-specific redundancy containing syntax-irrelevant features. The key idea of ESIB is to encourage multiple models to predict the same expression syntax tree for different problem representations of the same problem by mutual learning so as to capture consistent information of expression syntax tree and discard latent-specific redundancy. To improve the generalization ability of the model and generate more diverse expressions, we design a self-distillation loss to encourage the model to rely more on the expression syntax information in the latent space. Experimental results on two large-scale benchmarks show that our model not only achieves state-of-the-art results but also generates more diverse solutions. The code is available.
Text-Guided Face Recognition using Multi-Granularity Cross-Modal Contrastive Learning
Dec 14, 2023State-of-the-art face recognition (FR) models often experience a significant performance drop when dealing with facial images in surveillance scenarios where images are in low quality and often corrupted with noise. Leveraging facial characteristics, such as freckles, scars, gender, and ethnicity, becomes highly beneficial in improving FR performance in such scenarios. In this paper, we introduce text-guided face recognition (TGFR) to analyze the impact of integrating facial attributes in the form of natural language descriptions. We hypothesize that adding semantic information into the loop can significantly improve the image understanding capability of an FR algorithm compared to other soft biometrics. However, learning a discriminative joint embedding within the multimodal space poses a considerable challenge due to the semantic gap in the unaligned image-text representations, along with the complexities arising from ambiguous and incoherent textual descriptions of the face. To address these challenges, we introduce a face-caption alignment module (FCAM), which incorporates cross-modal contrastive losses across multiple granularities to maximize the mutual information between local and global features of the face-caption pair. Within FCAM, we refine both facial and textual features for learning aligned and discriminative features. We also design a face-caption fusion module (FCFM) that applies fine-grained interactions and coarse-grained associations among cross-modal features. Through extensive experiments conducted on three face-caption datasets, proposed TGFR demonstrates remarkable improvements, particularly on low-quality images, over existing FR models and outperforms other related methods and benchmarks.
Annotation-Free Automatic Music Transcription with Scalable Synthetic Data and Adversarial Domain Confusion
Dec 16, 2023Automatic Music Transcription (AMT) is a crucial technology in music information processing. Despite recent improvements in performance through machine learning approaches, existing methods often achieve high accuracy in domains with abundant annotation data, primarily due to the difficulty of creating annotation data. A practical transcription model requires an architecture that does not require an annotation data. In this paper, we propose an annotation-free transcription model achieved through the utilization of scalable synthetic audio for pre-training and adversarial domain confusion using unannotated real audio. Through evaluation experiments, we confirm that our proposed method can achieve higher accuracy under annotation-free conditions compared to when learning with mixture of annotated real audio data. Additionally, through ablation studies, we gain insights into the scalability of this approach and the challenges that lie ahead in the field of AMT research.
When Graph Data Meets Multimodal: A New Paradigm for Graph Understanding and Reasoning
Dec 16, 2023Graph data is ubiquitous in the physical world, and it has always been a challenge to efficiently model graph structures using a unified paradigm for the understanding and reasoning on various graphs. Moreover, in the era of large language models, integrating complex graph information into text sequences has become exceptionally difficult, which hinders the ability to interact with graph data through natural language instructions.The paper presents a new paradigm for understanding and reasoning about graph data by integrating image encoding and multimodal technologies. This approach enables the comprehension of graph data through an instruction-response format, utilizing GPT-4V's advanced capabilities. The study evaluates this paradigm on various graph types, highlighting the model's strengths and weaknesses, particularly in Chinese OCR performance and complex reasoning tasks. The findings suggest new direction for enhancing graph data processing and natural language interaction.
SCEdit: Efficient and Controllable Image Diffusion Generation via Skip Connection Editing
Dec 18, 2023Image diffusion models have been utilized in various tasks, such as text-to-image generation and controllable image synthesis. Recent research has introduced tuning methods that make subtle adjustments to the original models, yielding promising results in specific adaptations of foundational generative diffusion models. Rather than modifying the main backbone of the diffusion model, we delve into the role of skip connection in U-Net and reveal that hierarchical features aggregating long-distance information across encoder and decoder make a significant impact on the content and quality of image generation. Based on the observation, we propose an efficient generative tuning framework, dubbed SCEdit, which integrates and edits Skip Connection using a lightweight tuning module named SC-Tuner. Furthermore, the proposed framework allows for straightforward extension to controllable image synthesis by injecting different conditions with Controllable SC-Tuner, simplifying and unifying the network design for multi-condition inputs. Our SCEdit substantially reduces training parameters, memory usage, and computational expense due to its lightweight tuners, with backward propagation only passing to the decoder blocks. Extensive experiments conducted on text-to-image generation and controllable image synthesis tasks demonstrate the superiority of our method in terms of efficiency and performance. Project page: \url{https://scedit.github.io/}
Perceptual Musical Features for Interpretable Audio Tagging
Dec 18, 2023In the age of music streaming platforms, the task of automatically tagging music audio has garnered significant attention, driving researchers to devise methods aimed at enhancing performance metrics on standard datasets. Most recent approaches rely on deep neural networks, which, despite their impressive performance, possess opacity, making it challenging to elucidate their output for a given input. While the issue of interpretability has been emphasized in other fields like medicine, it has not received attention in music-related tasks. In this study, we explored the relevance of interpretability in the context of automatic music tagging. We constructed a workflow that incorporates three different information extraction techniques: a) leveraging symbolic knowledge, b) utilizing auxiliary deep neural networks, and c) employing signal processing to extract perceptual features from audio files. These features were subsequently used to train an interpretable machine-learning model for tag prediction. We conducted experiments on two datasets, namely the MTG-Jamendo dataset and the GTZAN dataset. Our method surpassed the performance of baseline models in both tasks and, in certain instances, demonstrated competitiveness with the current state-of-the-art. We conclude that there are use cases where the deterioration in performance is outweighed by the value of interpretability.
User-centric Flexible Resource Management Framework for LEO Satellites with Fully Regenerative Payload
Dec 18, 2023The regenerative capabilities of next-generation satellite systems offer a novel approach to design low earth orbit (LEO) satellite communication systems, enabling full flexibility in bandwidth and spot beam management, power control, and onboard data processing. These advancements allow the implementation of intelligent spatial multiplexing techniques, addressing the ever-increasing demand for future broadband data traffic. Existing satellite resource management solutions, however, do not fully exploit these capabilities. To address this issue, a novel framework called flexible resource management algorithm for LEO satellites (FLARE-LEO) is proposed to jointly design bandwidth, power, and spot beam coverage optimized for the geographic distribution of users. It incorporates multi-spot beam multicasting, spatial multiplexing, caching, and handover (HO). In particular, the spot beam coverage is optimized by using the unsupervised K-means algorithm applied to the realistic geographical user demands, followed by a proposed successive convex approximation (SCA)-based iterative algorithm for optimizing the radio resources. Furthermore, we propose two joint transmission architectures during the HO period, which jointly estimate the downlink channel state information (CSI) using deep learning and optimize the transmit power of the LEOs involved in the HO process to improve the overall system throughput. Simulations demonstrate superior performance in terms of delivery time reduction of the proposed algorithm over the existing solutions.
An Extended Variational Mode Decomposition Algorithm Developed Speech Emotion Recognition Performance
Dec 18, 2023Emotion recognition (ER) from speech signals is a robust approach since it cannot be imitated like facial expression or text based sentiment analysis. Valuable information underlying the emotions are significant for human-computer interactions enabling intelligent machines to interact with sensitivity in the real world. Previous ER studies through speech signal processing have focused exclusively on associations between different signal mode decomposition methods and hidden informative features. However, improper decomposition parameter selections lead to informative signal component losses due to mode duplicating and mixing. In contrast, the current study proposes VGG-optiVMD, an empowered variational mode decomposition algorithm, to distinguish meaningful speech features and automatically select the number of decomposed modes and optimum balancing parameter for the data fidelity constraint by assessing their effects on the VGG16 flattening output layer. Various feature vectors were employed to train the VGG16 network on different databases and assess VGG-optiVMD reproducibility and reliability. One, two, and three-dimensional feature vectors were constructed by concatenating Mel-frequency cepstral coefficients, Chromagram, Mel spectrograms, Tonnetz diagrams, and spectral centroids. Results confirmed a synergistic relationship between the fine-tuning of the signal sample rate and decomposition parameters with classification accuracy, achieving state-of-the-art 96.09% accuracy in predicting seven emotions on the Berlin EMO-DB database.
* 12 pages