 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Difference of Probability and Information Entropy for Skills Classification and Prediction in Student Learning
Dec 10, 2023
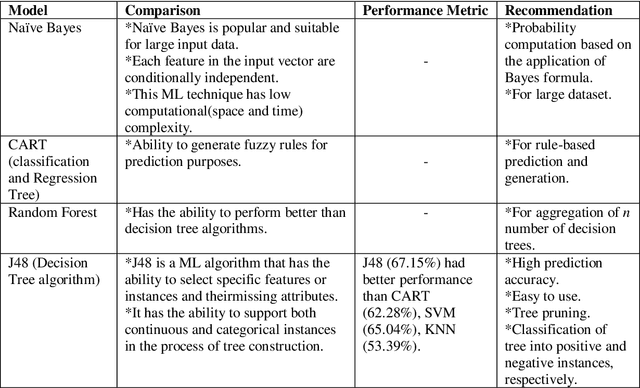
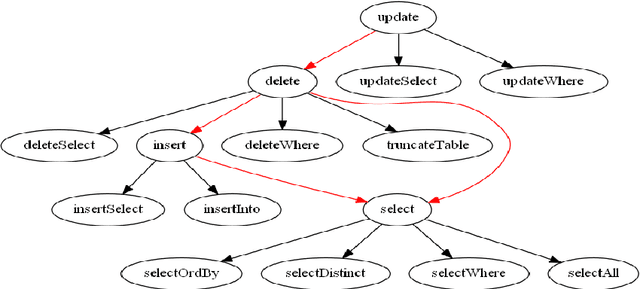
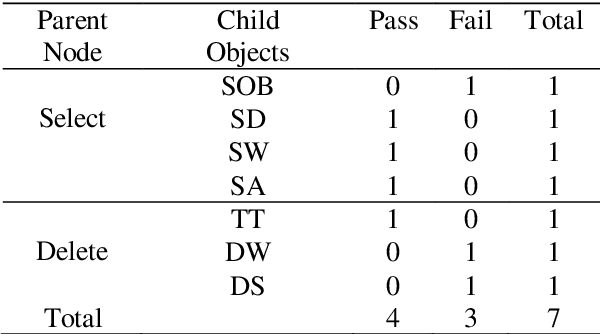
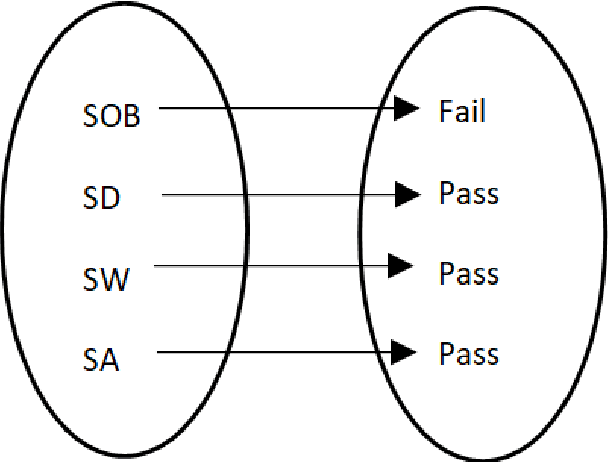
The probability of an event is in the range of [0, 1]. In a sample space S, the value of probability determines whether an outcome is true or false. The probability of an event Pr(A) that will never occur = 0. The probability of the event Pr(B) that will certainly occur = 1. This makes both events A and B thus a certainty. Furthermore, the sum of probabilities Pr(E1) + Pr(E2) + ... + Pr(En) of a finite set of events in a given sample space S = 1. Conversely, the difference of the sum of two probabilities that will certainly occur is 0. Firstly, this paper discusses Bayes' theorem, then complement of probability and the difference of probability for occurrences of learning-events, before applying these in the prediction of learning objects in student learning. Given the sum total of 1; to make recommendation for student learning, this paper submits that the difference of argMaxPr(S) and probability of student-performance quantifies the weight of learning objects for students. Using a dataset of skill-set, the computational procedure demonstrates: i) the probability of skill-set events that has occurred that would lead to higher level learning; ii) the probability of the events that has not occurred that requires subject-matter relearning; iii) accuracy of decision tree in the prediction of student performance into class labels; and iv) information entropy about skill-set data and its implication on student cognitive performance and recommendation of learning [1].
Generative AI-driven Semantic Communication Networks: Architecture, Technologies and Applications
Dec 30, 2023Generative artificial intelligence (GAI) has emerged as a rapidly burgeoning field demonstrating significant potential in creating diverse contents intelligently and automatically. To support such artificial intelligence-generated content (AIGC) services, future communication systems should fulfill much more stringent requirements (including data rate, throughput, latency, etc.) with limited yet precious spectrum resources. To tackle this challenge, semantic communication (SemCom), dramatically reducing resource consumption via extracting and transmitting semantics, has been deemed as a revolutionary communication scheme. The advanced GAI algorithms facilitate SemCom on sophisticated intelligence for model training, knowledge base construction and channel adaption. Furthermore, GAI algorithms also play an important role in the management of SemCom networks. In this survey, we first overview the basics of GAI and SemCom as well as the synergies of the two technologies. Especially, the GAI-driven SemCom framework is presented, where many GAI models for information creation, SemCom-enabled information transmission and information effectiveness for AIGC are discussed separately. We then delve into the GAI-driven SemCom network management involving with novel management layers, knowledge management, and resource allocation. Finally, we envision several promising use cases, i.e., autonomous driving, smart city, and the Metaverse for a more comprehensive exploration.
TeLeS: Temporal Lexeme Similarity Score to Estimate Confidence in End-to-End ASR
Jan 06, 2024Confidence estimation of predictions from an End-to-End (E2E) Automatic Speech Recognition (ASR) model benefits ASR's downstream and upstream tasks. Class-probability-based confidence scores do not accurately represent the quality of overconfident ASR predictions. An ancillary Confidence Estimation Model (CEM) calibrates the predictions. State-of-the-art (SOTA) solutions use binary target scores for CEM training. However, the binary labels do not reveal the granular information of predicted words, such as temporal alignment between reference and hypothesis and whether the predicted word is entirely incorrect or contains spelling errors. Addressing this issue, we propose a novel Temporal-Lexeme Similarity (TeLeS) confidence score to train CEM. To address the data imbalance of target scores while training CEM, we use shrinkage loss to focus on hard-to-learn data points and minimise the impact of easily learned data points. We conduct experiments with ASR models trained in three languages, namely Hindi, Tamil, and Kannada, with varying training data sizes. Experiments show that TeLeS generalises well across domains. To demonstrate the applicability of the proposed method, we formulate a TeLeS-based Acquisition (TeLeS-A) function for sampling uncertainty in active learning. We observe a significant reduction in the Word Error Rate (WER) as compared to SOTA methods.
Hybrid Internal Model: Learning Agile Legged Locomotion with Simulated Robot Response
Jan 02, 2024Robust locomotion control depends on accurate state estimations. However, the sensors of most legged robots can only provide partial and noisy observations, making the estimation particularly challenging, especially for external states like terrain frictions and elevation maps. Inspired by the classical Internal Model Control principle, we consider these external states as disturbances and introduce Hybrid Internal Model (HIM) to estimate them according to the response of the robot. The response, which we refer to as the hybrid internal embedding, contains the robot's explicit velocity and implicit stability representation, corresponding to two primary goals for locomotion tasks: explicitly tracking velocity and implicitly maintaining stability. We use contrastive learning to optimize the embedding to be close to the robot's successor state, in which the response is naturally embedded. HIM has several appealing benefits: It only needs the robot's proprioceptions, i.e., those from joint encoders and IMU as observations. It innovatively maintains consistent observations between simulation reference and reality that avoids information loss in mimicking learning. It exploits batch-level information that is more robust to noises and keeps better sample efficiency. It only requires 1 hour of training on an RTX 4090 to enable a quadruped robot to traverse any terrain under any disturbances. A wealth of real-world experiments demonstrates its agility, even in high-difficulty tasks and cases never occurred during the training process, revealing remarkable open-world generalizability.
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
Jan 03, 2024As Large Language Models (LLMs) continue to advance in their ability to write human-like text, a key challenge remains around their tendency to hallucinate generating content that appears factual but is ungrounded. This issue of hallucination is arguably the biggest hindrance to safely deploying these powerful LLMs into real-world production systems that impact people's lives. The journey toward widespread adoption of LLMs in practical settings heavily relies on addressing and mitigating hallucinations. Unlike traditional AI systems focused on limited tasks, LLMs have been exposed to vast amounts of online text data during training. While this allows them to display impressive language fluency, it also means they are capable of extrapolating information from the biases in training data, misinterpreting ambiguous prompts, or modifying the information to align superficially with the input. This becomes hugely alarming when we rely on language generation capabilities for sensitive applications, such as summarizing medical records, financial analysis reports, etc. This paper presents a comprehensive survey of over 32 techniques developed to mitigate hallucination in LLMs. Notable among these are Retrieval Augmented Generation (Lewis et al, 2021), Knowledge Retrieval (Varshney et al,2023), CoNLI (Lei et al, 2023), and CoVe (Dhuliawala et al, 2023). Furthermore, we introduce a detailed taxonomy categorizing these methods based on various parameters, such as dataset utilization, common tasks, feedback mechanisms, and retriever types. This classification helps distinguish the diverse approaches specifically designed to tackle hallucination issues in LLMs. Additionally, we analyze the challenges and limitations inherent in these techniques, providing a solid foundation for future research in addressing hallucinations and related phenomena within the realm of LLMs.
Rethinking Privacy in Machine Learning Pipelines from an Information Flow Control Perspective
Nov 27, 2023Modern machine learning systems use models trained on ever-growing corpora. Typically, metadata such as ownership, access control, or licensing information is ignored during training. Instead, to mitigate privacy risks, we rely on generic techniques such as dataset sanitization and differentially private model training, with inherent privacy/utility trade-offs that hurt model performance. Moreover, these techniques have limitations in scenarios where sensitive information is shared across multiple participants and fine-grained access control is required. By ignoring metadata, we therefore miss an opportunity to better address security, privacy, and confidentiality challenges. In this paper, we take an information flow control perspective to describe machine learning systems, which allows us to leverage metadata such as access control policies and define clear-cut privacy and confidentiality guarantees with interpretable information flows. Under this perspective, we contrast two different approaches to achieve user-level non-interference: 1) fine-tuning per-user models, and 2) retrieval augmented models that access user-specific datasets at inference time. We compare these two approaches to a trivially non-interfering zero-shot baseline using a public model and to a baseline that fine-tunes this model on the whole corpus. We evaluate trained models on two datasets of scientific articles and demonstrate that retrieval augmented architectures deliver the best utility, scalability, and flexibility while satisfying strict non-interference guarantees.
ArcMMLU: A Library and Information Science Benchmark for Large Language Models
Nov 30, 2023
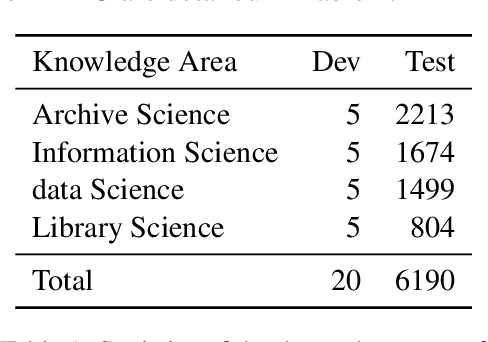

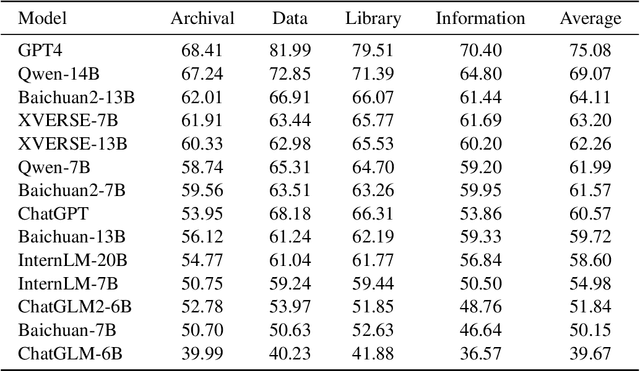
In light of the rapidly evolving capabilities of large language models (LLMs), it becomes imperative to develop rigorous domain-specific evaluation benchmarks to accurately assess their capabilities. In response to this need, this paper introduces ArcMMLU, a specialized benchmark tailored for the Library & Information Science (LIS) domain in Chinese. This benchmark aims to measure the knowledge and reasoning capability of LLMs within four key sub-domains: Archival Science, Data Science, Library Science, and Information Science. Following the format of MMLU/CMMLU, we collected over 6,000 high-quality questions for the compilation of ArcMMLU. This extensive compilation can reflect the diverse nature of the LIS domain and offer a robust foundation for LLM evaluation. Our comprehensive evaluation reveals that while most mainstream LLMs achieve an average accuracy rate above 50% on ArcMMLU, there remains a notable performance gap, suggesting substantial headroom for refinement in LLM capabilities within the LIS domain. Further analysis explores the effectiveness of few-shot examples on model performance and highlights challenging questions where models consistently underperform, providing valuable insights for targeted improvements. ArcMMLU fills a critical gap in LLM evaluations within the Chinese LIS domain and paves the way for future development of LLMs tailored to this specialized area.
Motion Control of Interactive Robotic Arms Based on Mixed Reality Development
Jan 03, 2024Mixed Reality (MR) is constantly evolving to inspire new patterns of robot manipulation for more advanced Human- Robot Interaction under the 4th Industrial Revolution Paradigm. Consider that Mixed Reality aims to connect physical and digital worlds to provide special immersive experiences, it is necessary to establish the information exchange platform and robot control systems within the developed MR scenarios. In this work, we mainly present multiple effective motion control methods applied on different interactive robotic arms (e.g., UR5, UR5e, myCobot) for the Unity-based development of MR applications, including GUI control panel, text input control panel, end-effector object dynamic tracking and ROS-Unity digital-twin connection.
Timeliness: A New Design Metric and a New Attack Surface
Dec 28, 2023As the landscape of time-sensitive applications gains prominence in 5G/6G communications, timeliness of information updates at network nodes has become crucial, which is popularly quantified in the literature by the age of information metric. However, as we devise policies to improve age of information of our systems, we inadvertently introduce a new vulnerability for adversaries to exploit. In this article, we comprehensively discuss the diverse threats that age-based systems are vulnerable to. We begin with discussion on densely interconnected networks that employ gossiping between nodes to expedite dissemination of dynamic information in the network, and show how the age-based nature of gossiping renders these networks uniquely susceptible to threats such as timestomping attacks, jamming attacks, and the propagation of misinformation. Later, we survey adversarial works within simpler network settings, specifically in one-hop and two-hop configurations, and delve into adversarial robustness concerning challenges posed by jamming, timestomping, and issues related to privacy leakage. We conclude this article with future directions that aim to address challenges posed by more intelligent adversaries and robustness of networks to them.
Latte: Latent Diffusion Transformer for Video Generation
Jan 05, 2024We propose a novel Latent Diffusion Transformer, namely Latte, for video generation. Latte first extracts spatio-temporal tokens from input videos and then adopts a series of Transformer blocks to model video distribution in the latent space. In order to model a substantial number of tokens extracted from videos, four efficient variants are introduced from the perspective of decomposing the spatial and temporal dimensions of input videos. To improve the quality of generated videos, we determine the best practices of Latte through rigorous experimental analysis, including video clip patch embedding, model variants, timestep-class information injection, temporal positional embedding, and learning strategies. Our comprehensive evaluation demonstrates that Latte achieves state-of-the-art performance across four standard video generation datasets, i.e., FaceForensics, SkyTimelapse, UCF101, and Taichi-HD. In addition, we extend Latte to text-to-video generation (T2V) task, where Latte achieves comparable results compared to recent T2V models. We strongly believe that Latte provides valuable insights for future research on incorporating Transformers into diffusion models for video generation.