 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Simplifying Two-Stage Detectors for On-Device Inference in Remote Sensing
Apr 11, 2024
Deep learning has been successfully applied to object detection from remotely sensed images. Images are typically processed on the ground rather than on-board due to the computation power of the ground system. Such offloaded processing causes delays in acquiring target mission information, which hinders its application to real-time use cases. For on-device object detection, researches have been conducted on designing efficient detectors or model compression to reduce inference latency. However, highly accurate two-stage detectors still need further exploitation for acceleration. In this paper, we propose a model simplification method for two-stage object detectors. Instead of constructing a general feature pyramid, we utilize only one feature extraction in the two-stage detector. To compensate for the accuracy drop, we apply a high pass filter to the RPN's score map. Our approach is applicable to any two-stage detector using a feature pyramid network. In the experiments with state-of-the-art two-stage detectors such as ReDet, Oriented-RCNN, and LSKNet, our method reduced computation costs upto 61.2% with the accuracy loss within 2.1% on the DOTAv1.5 dataset. Source code will be released.
How Consistent are Clinicians? Evaluating the Predictability of Sepsis Disease Progression with Dynamics Models
Apr 10, 2024Reinforcement learning (RL) is a promising approach to generate treatment policies for sepsis patients in intensive care. While retrospective evaluation metrics show decreased mortality when these policies are followed, studies with clinicians suggest their recommendations are often spurious. We propose that these shortcomings may be due to lack of diversity in observed actions and outcomes in the training data, and we construct experiments to investigate the feasibility of predicting sepsis disease severity changes due to clinician actions. Preliminary results suggest incorporating action information does not significantly improve model performance, indicating that clinician actions may not be sufficiently variable to yield measurable effects on disease progression. We discuss the implications of these findings for optimizing sepsis treatment.
LLMs in HCI Data Work: Bridging the Gap Between Information Retrieval and Responsible Research Practices
Mar 27, 2024Efficient and accurate information extraction from scientific papers is significant in the rapidly developing human-computer interaction research in the literature review process. Our paper introduces and analyses a new information retrieval system using state-of-the-art Large Language Models (LLMs) in combination with structured text analysis techniques to extract experimental data from HCI literature, emphasizing key elements. Then We analyze the challenges and risks of using LLMs in the world of research. We performed a comprehensive analysis on our conducted dataset, which contained the specified information of 300 CHI 2020-2022 papers, to evaluate the performance of the two large language models, GPT-3.5 (text-davinci-003) and Llama-2-70b, paired with structured text analysis techniques. The GPT-3.5 model gains an accuracy of 58\% and a mean absolute error of 7.00. In contrast, the Llama2 model indicates an accuracy of 56\% with a mean absolute error of 7.63. The ability to answer questions was also included in the system in order to work with streamlined data. By evaluating the risks and opportunities presented by LLMs, our work contributes to the ongoing dialogue on establishing methodological validity and ethical guidelines for LLM use in HCI data work.
Automatic detection of relevant information, predictions and forecasts in financial news through topic modelling with Latent Dirichlet Allocation
Mar 30, 2024Financial news items are unstructured sources of information that can be mined to extract knowledge for market screening applications. Manual extraction of relevant information from the continuous stream of finance-related news is cumbersome and beyond the skills of many investors, who, at most, can follow a few sources and authors. Accordingly, we focus on the analysis of financial news to identify relevant text and, within that text, forecasts and predictions. We propose a novel Natural Language Processing (NLP) system to assist investors in the detection of relevant financial events in unstructured textual sources by considering both relevance and temporality at the discursive level. Firstly, we segment the text to group together closely related text. Secondly, we apply co-reference resolution to discover internal dependencies within segments. Finally, we perform relevant topic modelling with Latent Dirichlet Allocation (LDA) to separate relevant from less relevant text and then analyse the relevant text using a Machine Learning-oriented temporal approach to identify predictions and speculative statements. We created an experimental data set composed of 2,158 financial news items that were manually labelled by NLP researchers to evaluate our solution. The ROUGE-L values for the identification of relevant text and predictions/forecasts were 0.662 and 0.982, respectively. To our knowledge, this is the first work to jointly consider relevance and temporality at the discursive level. It contributes to the transfer of human associative discourse capabilities to expert systems through the combination of multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns, topic modelling with LDA to detect relevant text, and discursive temporality analysis to identify forecasts and predictions within this text.
Language Models Can Reduce Asymmetry in Information Markets
Mar 21, 2024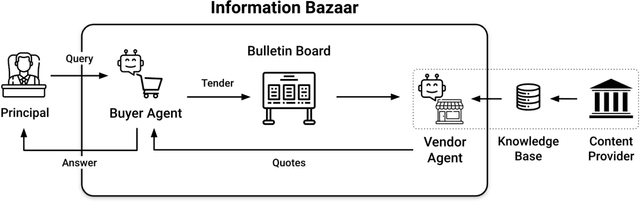

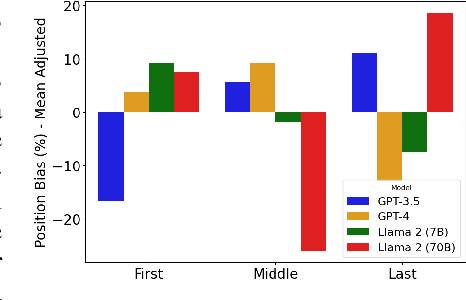
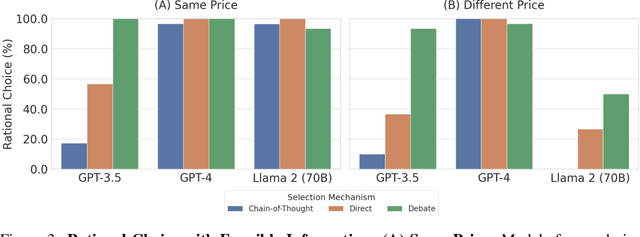
This work addresses the buyer's inspection paradox for information markets. The paradox is that buyers need to access information to determine its value, while sellers need to limit access to prevent theft. To study this, we introduce an open-source simulated digital marketplace where intelligent agents, powered by language models, buy and sell information on behalf of external participants. The central mechanism enabling this marketplace is the agents' dual capabilities: they not only have the capacity to assess the quality of privileged information but also come equipped with the ability to forget. This ability to induce amnesia allows vendors to grant temporary access to proprietary information, significantly reducing the risk of unauthorized retention while enabling agents to accurately gauge the information's relevance to specific queries or tasks. To perform well, agents must make rational decisions, strategically explore the marketplace through generated sub-queries, and synthesize answers from purchased information. Concretely, our experiments (a) uncover biases in language models leading to irrational behavior and evaluate techniques to mitigate these biases, (b) investigate how price affects demand in the context of informational goods, and (c) show that inspection and higher budgets both lead to higher quality outcomes.
LaTiM: Longitudinal representation learning in continuous-time models to predict disease progression
Apr 10, 2024This work proposes a novel framework for analyzing disease progression using time-aware neural ordinary differential equations (NODE). We introduce a "time-aware head" in a framework trained through self-supervised learning (SSL) to leverage temporal information in latent space for data augmentation. This approach effectively integrates NODEs with SSL, offering significant performance improvements compared to traditional methods that lack explicit temporal integration. We demonstrate the effectiveness of our strategy for diabetic retinopathy progression prediction using the OPHDIAT database. Compared to the baseline, all NODE architectures achieve statistically significant improvements in area under the ROC curve (AUC) and Kappa metrics, highlighting the efficacy of pre-training with SSL-inspired approaches. Additionally, our framework promotes stable training for NODEs, a commonly encountered challenge in time-aware modeling.
Is There a One-Model-Fits-All Approach to Information Extraction? Revisiting Task Definition Biases
Mar 25, 2024Definition bias is a negative phenomenon that can mislead models. Definition bias in information extraction appears not only across datasets from different domains but also within datasets sharing the same domain. We identify two types of definition bias in IE: bias among information extraction datasets and bias between information extraction datasets and instruction tuning datasets. To systematically investigate definition bias, we conduct three probing experiments to quantitatively analyze it and discover the limitations of unified information extraction and large language models in solving definition bias. To mitigate definition bias in information extraction, we propose a multi-stage framework consisting of definition bias measurement, bias-aware fine-tuning, and task-specific bias mitigation. Experimental results demonstrate the effectiveness of our framework in addressing definition bias. Resources of this paper can be found at https://github.com/EZ-hwh/definition-bias
DWE+: Dual-Way Matching Enhanced Framework for Multimodal Entity Linking
Apr 07, 2024Multimodal entity linking (MEL) aims to utilize multimodal information (usually textual and visual information) to link ambiguous mentions to unambiguous entities in knowledge base. Current methods facing main issues: (1)treating the entire image as input may contain redundant information. (2)the insufficient utilization of entity-related information, such as attributes in images. (3)semantic inconsistency between the entity in knowledge base and its representation. To this end, we propose DWE+ for multimodal entity linking. DWE+ could capture finer semantics and dynamically maintain semantic consistency with entities. This is achieved by three aspects: (a)we introduce a method for extracting fine-grained image features by partitioning the image into multiple local objects. Then, hierarchical contrastive learning is used to further align semantics between coarse-grained information(text and image) and fine-grained (mention and visual objects). (b)we explore ways to extract visual attributes from images to enhance fusion feature such as facial features and identity. (c)we leverage Wikipedia and ChatGPT to capture the entity representation, achieving semantic enrichment from both static and dynamic perspectives, which better reflects the real-world entity semantics. Experiments on Wikimel, Richpedia, and Wikidiverse datasets demonstrate the effectiveness of DWE+ in improving MEL performance. Specifically, we optimize these datasets and achieve state-of-the-art performance on the enhanced datasets. The code and enhanced datasets are released on https://github.com/season1blue/DWET
ConsistencyDet: Robust Object Detector with Denoising Paradigm of Consistency Model
Apr 11, 2024Object detection, a quintessential task in the realm of perceptual computing, can be tackled using a generative methodology. In the present study, we introduce a novel framework designed to articulate object detection as a denoising diffusion process, which operates on perturbed bounding boxes of annotated entities. This framework, termed ConsistencyDet, leverages an innovative denoising concept known as the Consistency Model. The hallmark of this model is its self-consistency feature, which empowers the model to map distorted information from any temporal stage back to its pristine state, thereby realizing a ``one-step denoising'' mechanism. Such an attribute markedly elevates the operational efficiency of the model, setting it apart from the conventional Diffusion Model. Throughout the training phase, ConsistencyDet initiates the diffusion sequence with noise-infused boxes derived from the ground-truth annotations and conditions the model to perform the denoising task. Subsequently, in the inference stage, the model employs a denoising sampling strategy that commences with bounding boxes randomly sampled from a normal distribution. Through iterative refinement, the model transforms an assortment of arbitrarily generated boxes into the definitive detections. Comprehensive evaluations employing standard benchmarks, such as MS-COCO and LVIS, corroborate that ConsistencyDet surpasses other leading-edge detectors in performance metrics.
Mitigating Vulnerable Road Users Occlusion Risk Via Collective Perception: An Empirical Analysis
Apr 11, 2024Recent reports from the World Health Organization highlight that Vulnerable Road Users (VRUs) have been involved in over half of the road fatalities in recent years, with occlusion risk - a scenario where VRUs are hidden from drivers' view by obstacles like parked vehicles - being a critical contributing factor. To address this, we present a novel algorithm that quantifies occlusion risk based on the dynamics of both vehicles and VRUs. This algorithm has undergone testing and evaluation using a real-world dataset from German intersections. Additionally, we introduce the concept of Maximum Tracking Loss (MTL), which measures the longest consecutive duration a VRU remains untracked by any vehicle in a given scenario. Our study extends to examining the role of the Collective Perception Service (CPS) in VRU safety. CPS enhances safety by enabling vehicles to share sensor information, thereby potentially reducing occlusion risks. Our analysis reveals that a 25% market penetration of CPS-equipped vehicles can substantially diminish occlusion risks and significantly curtail MTL. These findings demonstrate how various scenarios pose different levels of risk to VRUs and how the deployment of Collective Perception can markedly improve their safety. Furthermore, they underline the efficacy of our proposed metrics to capture occlusion risk as a safety factor.