 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CHAMP: A Competition-level Dataset for Fine-Grained Analyses of LLMs' Mathematical Reasoning Capabilities
Jan 13, 2024
Recent large language models (LLMs) have shown indications of mathematical reasoning ability. However it has not been clear how they would fare on more challenging competition-level problems. And while self-generated verbalizations of intermediate reasoning steps (i.e., chain-of-thought prompting) have been shown to be helpful, whether LLMs can make use of helpful side information such as problem-specific hints has not been investigated before. In this paper, we propose a challenging benchmark dataset for enabling such analyses. The Concept and Hint-Annotated Math Problems (CHAMP) consists of high school math competition problems, annotated with concepts, or general math facts, and hints, or problem-specific tricks. These annotations allow us to explore the effects of additional information, such as relevant hints, misleading concepts, or related problems. This benchmark is difficult, with the best model only scoring 58.1% in standard settings. With concepts and hints, performance sometimes improves, indicating that some models can make use of such side information. We further annotate model-generated solutions for their correctness. Using this corpus, we find that models often arrive at the correct final answer through wrong reasoning steps. In addition, we test whether models are able to verify these solutions, and find that most models struggle. The dataset and code are available on the project website.
SARA: A Collection of Sensitivity-Aware Relevance Assessments
Jan 10, 2024Large archival collections, such as email or government documents, must be manually reviewed to identify any sensitive information before the collection can be released publicly. Sensitivity classification has received a lot of attention in the literature. However, more recently, there has been increasing interest in developing sensitivity-aware search engines that can provide users with relevant search results, while ensuring that no sensitive documents are returned to the user. Sensitivity-aware search would mitigate the need for a manual sensitivity review prior to collections being made available publicly. To develop such systems, there is a need for test collections that contain relevance assessments for a set of information needs as well as ground-truth labels for a variety of sensitivity categories. The well-known Enron email collection contains a classification ground-truth that can be used to represent sensitive information, e.g., the Purely Personal and Personal but in Professional Context categories can be used to represent sensitive personal information. However, the existing Enron collection does not contain a set of information needs and relevance assessments. In this work, we present a collection of fifty information needs (topics) with crowdsourced query formulations (3 per topic) and relevance assessments (11,471 in total) for the Enron collection (mean number of relevant documents per topic = 11, variance = 34.7). The developed information needs, queries and relevance judgements are available on GitHub and will be available along with the existing Enron collection through the popular ir_datasets library. Our proposed collection results in the first freely available test collection for developing sensitivity-aware search systems.
3D Room Geometry Inference from Multichannel Room Impulse Response using Deep Neural Network
Jan 19, 2024Room geometry inference (RGI) aims at estimating room shapes from measured room impulse responses (RIRs) and has received lots of attention for its importance in environment-aware audio rendering and virtual acoustic representation of a real venue. A lot of estimation models utilizing time difference of arrival (TDoA) or time of arrival (ToA) information in RIRs have been proposed. However, an estimation model should be able to handle more general features and complex relations between reflections to cope with various room shapes and uncertainties such as the unknown number of walls. In this study, we propose a deep neural network that can estimate various room shapes without prior assumptions on the shape or number of walls. The proposed model consists of three sub-networks: a feature extractor, parameter estimation, and evaluation networks, which extract key features from RIRs, estimate parameters, and evaluate the confidence of estimated parameters, respectively. The network is trained by about 40,000 RIRs simulated in rooms of different shapes using a single source and spherical microphone array and tested for rooms of unseen shapes and dimensions. The proposed algorithm achieves almost perfect accuracy in finding the true number of walls and shows negligible errors in room shapes.
* 5 pages, 2 figures, Proceedings of the 24th International Congress on Acoustics
SCENES: Subpixel Correspondence Estimation With Epipolar Supervision
Jan 19, 2024Extracting point correspondences from two or more views of a scene is a fundamental computer vision problem with particular importance for relative camera pose estimation and structure-from-motion. Existing local feature matching approaches, trained with correspondence supervision on large-scale datasets, obtain highly-accurate matches on the test sets. However, they do not generalise well to new datasets with different characteristics to those they were trained on, unlike classic feature extractors. Instead, they require finetuning, which assumes that ground-truth correspondences or ground-truth camera poses and 3D structure are available. We relax this assumption by removing the requirement of 3D structure, e.g., depth maps or point clouds, and only require camera pose information, which can be obtained from odometry. We do so by replacing correspondence losses with epipolar losses, which encourage putative matches to lie on the associated epipolar line. While weaker than correspondence supervision, we observe that this cue is sufficient for finetuning existing models on new data. We then further relax the assumption of known camera poses by using pose estimates in a novel bootstrapping approach. We evaluate on highly challenging datasets, including an indoor drone dataset and an outdoor smartphone camera dataset, and obtain state-of-the-art results without strong supervision.
Cross-Modality Perturbation Synergy Attack for Person Re-identification
Jan 19, 2024In recent years, there has been significant research focusing on addressing security concerns in single-modal person re-identification (ReID) systems that are based on RGB images. However, the safety of cross-modality scenarios, which are more commonly encountered in practical applications involving images captured by infrared cameras, has not received adequate attention. The main challenge in cross-modality ReID lies in effectively dealing with visual differences between different modalities. For instance, infrared images are typically grayscale, unlike visible images that contain color information. Existing attack methods have primarily focused on the characteristics of the visible image modality, overlooking the features of other modalities and the variations in data distribution among different modalities. This oversight can potentially undermine the effectiveness of these methods in image retrieval across diverse modalities. This study represents the first exploration into the security of cross-modality ReID models and proposes a universal perturbation attack specifically designed for cross-modality ReID. This attack optimizes perturbations by leveraging gradients from diverse modality data, thereby disrupting the discriminator and reinforcing the differences between modalities. We conducted experiments on two widely used cross-modality datasets, namely RegDB and SYSU, which not only demonstrated the effectiveness of our method but also provided insights for future enhancements in the robustness of cross-modality ReID systems.
MultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World
Jan 16, 2024Human beings possess the capability to multiply a melange of multisensory cues while actively exploring and interacting with the 3D world. Current multi-modal large language models, however, passively absorb sensory data as inputs, lacking the capacity to actively interact with the objects in the 3D environment and dynamically collect their multisensory information. To usher in the study of this area, we propose MultiPLY, a multisensory embodied large language model that could incorporate multisensory interactive data, including visual, audio, tactile, and thermal information into large language models, thereby establishing the correlation among words, actions, and percepts. To this end, we first collect Multisensory Universe, a large-scale multisensory interaction dataset comprising 500k data by deploying an LLM-powered embodied agent to engage with the 3D environment. To perform instruction tuning with pre-trained LLM on such generated data, we first encode the 3D scene as abstracted object-centric representations and then introduce action tokens denoting that the embodied agent takes certain actions within the environment, as well as state tokens that represent the multisensory state observations of the agent at each time step. In the inference time, MultiPLY could generate action tokens, instructing the agent to take the action in the environment and obtain the next multisensory state observation. The observation is then appended back to the LLM via state tokens to generate subsequent text or action tokens. We demonstrate that MultiPLY outperforms baselines by a large margin through a diverse set of embodied tasks involving object retrieval, tool use, multisensory captioning, and task decomposition.
CLIP-Driven Semantic Discovery Network for Visible-Infrared Person Re-Identification
Jan 12, 2024Visible-infrared person re-identification (VIReID) primarily deals with matching identities across person images from different modalities. Due to the modality gap between visible and infrared images, cross-modality identity matching poses significant challenges. Recognizing that high-level semantics of pedestrian appearance, such as gender, shape, and clothing style, remain consistent across modalities, this paper intends to bridge the modality gap by infusing visual features with high-level semantics. Given the capability of CLIP to sense high-level semantic information corresponding to visual representations, we explore the application of CLIP within the domain of VIReID. Consequently, we propose a CLIP-Driven Semantic Discovery Network (CSDN) that consists of Modality-specific Prompt Learner, Semantic Information Integration (SII), and High-level Semantic Embedding (HSE). Specifically, considering the diversity stemming from modality discrepancies in language descriptions, we devise bimodal learnable text tokens to capture modality-private semantic information for visible and infrared images, respectively. Additionally, acknowledging the complementary nature of semantic details across different modalities, we integrate text features from the bimodal language descriptions to achieve comprehensive semantics. Finally, we establish a connection between the integrated text features and the visual features across modalities. This process embed rich high-level semantic information into visual representations, thereby promoting the modality invariance of visual representations. The effectiveness and superiority of our proposed CSDN over existing methods have been substantiated through experimental evaluations on multiple widely used benchmarks. The code will be released at \url{https://github.com/nengdong96/CSDN}.
BoNuS: Boundary Mining for Nuclei Segmentation with Partial Point Labels
Jan 15, 2024Nuclei segmentation is a fundamental prerequisite in the digital pathology workflow. The development of automated methods for nuclei segmentation enables quantitative analysis of the wide existence and large variances in nuclei morphometry in histopathology images. However, manual annotation of tens of thousands of nuclei is tedious and time-consuming, which requires significant amount of human effort and domain-specific expertise. To alleviate this problem, in this paper, we propose a weakly-supervised nuclei segmentation method that only requires partial point labels of nuclei. Specifically, we propose a novel boundary mining framework for nuclei segmentation, named BoNuS, which simultaneously learns nuclei interior and boundary information from the point labels. To achieve this goal, we propose a novel boundary mining loss, which guides the model to learn the boundary information by exploring the pairwise pixel affinity in a multiple-instance learning manner. Then, we consider a more challenging problem, i.e., partial point label, where we propose a nuclei detection module with curriculum learning to detect the missing nuclei with prior morphological knowledge. The proposed method is validated on three public datasets, MoNuSeg, CPM, and CoNIC datasets. Experimental results demonstrate the superior performance of our method to the state-of-the-art weakly-supervised nuclei segmentation methods. Code: https://github.com/hust-linyi/bonus.
Wikiformer: Pre-training with Structured Information of Wikipedia for Ad-hoc Retrieval
Dec 17, 2023
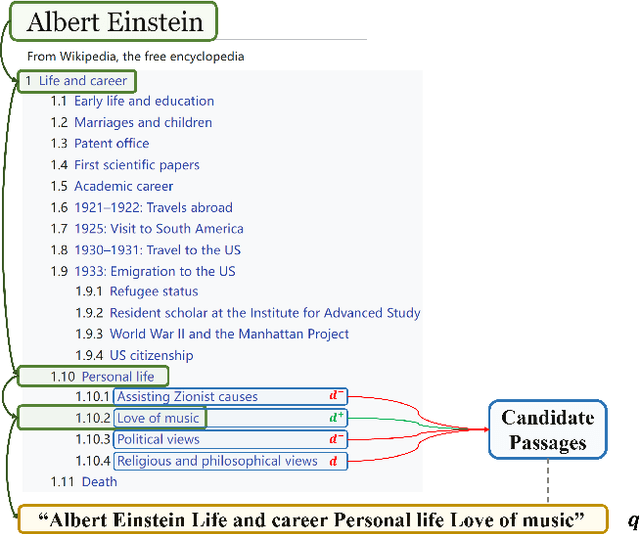
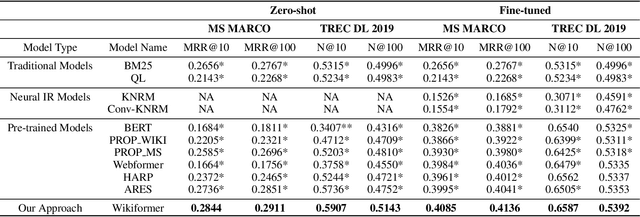
With the development of deep learning and natural language processing techniques, pre-trained language models have been widely used to solve information retrieval (IR) problems. Benefiting from the pre-training and fine-tuning paradigm, these models achieve state-of-the-art performance. In previous works, plain texts in Wikipedia have been widely used in the pre-training stage. However, the rich structured information in Wikipedia, such as the titles, abstracts, hierarchical heading (multi-level title) structure, relationship between articles, references, hyperlink structures, and the writing organizations, has not been fully explored. In this paper, we devise four pre-training objectives tailored for IR tasks based on the structured knowledge of Wikipedia. Compared to existing pre-training methods, our approach can better capture the semantic knowledge in the training corpus by leveraging the human-edited structured data from Wikipedia. Experimental results on multiple IR benchmark datasets show the superior performance of our model in both zero-shot and fine-tuning settings compared to existing strong retrieval baselines. Besides, experimental results in biomedical and legal domains demonstrate that our approach achieves better performance in vertical domains compared to previous models, especially in scenarios where long text similarity matching is needed.
Discovering Low-rank Subspaces for Language-agnostic Multilingual Representations
Jan 11, 2024Large pretrained multilingual language models (ML-LMs) have shown remarkable capabilities of zero-shot cross-lingual transfer, without direct cross-lingual supervision. While these results are promising, follow-up works found that, within the multilingual embedding spaces, there exists strong language identity information which hinders the expression of linguistic factors shared across languages. For semantic tasks like cross-lingual sentence retrieval, it is desired to remove such language identity signals to fully leverage semantic information. In this work, we provide a novel view of projecting away language-specific factors from a multilingual embedding space. Specifically, we discover that there exists a low-rank subspace that primarily encodes information irrelevant to semantics (e.g., syntactic information). To identify this subspace, we present a simple but effective unsupervised method based on singular value decomposition with multiple monolingual corpora as input. Once the subspace is found, we can directly project the original embeddings into the null space to boost language agnosticism without finetuning. We systematically evaluate our method on various tasks including the challenging language-agnostic QA retrieval task. Empirical results show that applying our method consistently leads to improvements over commonly used ML-LMs.