 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Curious Case of Nonverbal Abstract Reasoning with Multi-Modal Large Language Models
Jan 22, 2024
While large language models (LLMs) are still being adopted to new domains and utilized in novel applications, we are experiencing an influx of the new generation of foundation models, namely multi-modal large language models (MLLMs). These models integrate verbal and visual information, opening new possibilities to demonstrate more complex reasoning abilities at the intersection of the two modalities. However, despite the revolutionizing prospect of MLLMs, our understanding of their reasoning abilities is limited. In this study, we assess the nonverbal abstract reasoning abilities of open-source and closed-source MLLMs using variations of Raven's Progressive Matrices. Our experiments expose the difficulty of solving such problems while showcasing the immense gap between open-source and closed-source models. We also reveal critical shortcomings with individual visual and textual modules, subjecting the models to low-performance ceilings. Finally, to improve MLLMs' performance, we experiment with various methods, such as Chain-of-Thought prompting, resulting in a significant (up to 100%) boost in performance.
Spatial-Contextual Discrepancy Information Compensation for GAN Inversion
Dec 12, 2023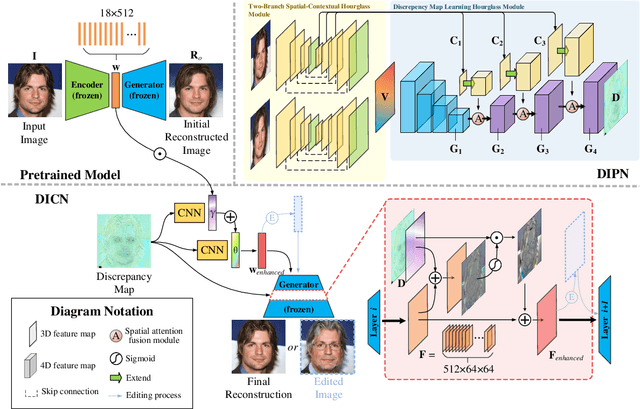
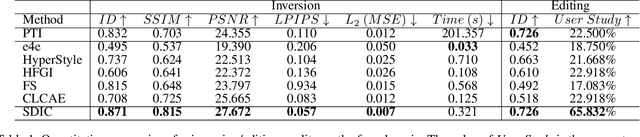
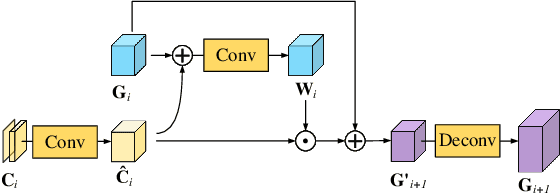
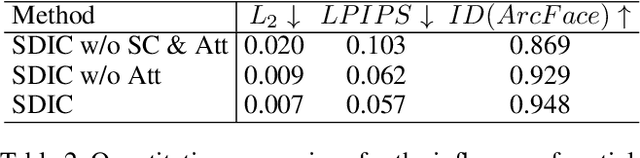
Most existing GAN inversion methods either achieve accurate reconstruction but lack editability or offer strong editability at the cost of fidelity. Hence, how to balance the distortioneditability trade-off is a significant challenge for GAN inversion. To address this challenge, we introduce a novel spatial-contextual discrepancy information compensationbased GAN-inversion method (SDIC), which consists of a discrepancy information prediction network (DIPN) and a discrepancy information compensation network (DICN). SDIC follows a "compensate-and-edit" paradigm and successfully bridges the gap in image details between the original image and the reconstructed/edited image. On the one hand, DIPN encodes the multi-level spatial-contextual information of the original and initial reconstructed images and then predicts a spatial-contextual guided discrepancy map with two hourglass modules. In this way, a reliable discrepancy map that models the contextual relationship and captures finegrained image details is learned. On the other hand, DICN incorporates the predicted discrepancy information into both the latent code and the GAN generator with different transformations, generating high-quality reconstructed/edited images. This effectively compensates for the loss of image details during GAN inversion. Both quantitative and qualitative experiments demonstrate that our proposed method achieves the excellent distortion-editability trade-off at a fast inference speed for both image inversion and editing tasks.
On the Audio Hallucinations in Large Audio-Video Language Models
Jan 18, 2024Large audio-video language models can generate descriptions for both video and audio. However, they sometimes ignore audio content, producing audio descriptions solely reliant on visual information. This paper refers to this as audio hallucinations and analyzes them in large audio-video language models. We gather 1,000 sentences by inquiring about audio information and annotate them whether they contain hallucinations. If a sentence is hallucinated, we also categorize the type of hallucination. The results reveal that 332 sentences are hallucinated with distinct trends observed in nouns and verbs for each hallucination type. Based on this, we tackle a task of audio hallucination classification using pre-trained audio-text models in the zero-shot and fine-tuning settings. Our experimental results reveal that the zero-shot models achieve higher performance (52.2% in F1) than the random (40.3%) and the fine-tuning models achieve 87.9%, outperforming the zero-shot models.
Fine-grained Contract NER using instruction based model
Jan 24, 2024Lately, instruction-based techniques have made significant strides in improving performance in few-shot learning scenarios. They achieve this by bridging the gap between pre-trained language models and fine-tuning for specific downstream tasks. Despite these advancements, the performance of Large Language Models (LLMs) in information extraction tasks like Named Entity Recognition (NER), using prompts or instructions, still falls short of supervised baselines. The reason for this performance gap can be attributed to the fundamental disparity between NER and LLMs. NER is inherently a sequence labeling task, where the model must assign entity-type labels to individual tokens within a sentence. In contrast, LLMs are designed as a text generation task. This distinction between semantic labeling and text generation leads to subpar performance. In this paper, we transform the NER task into a text-generation task that can be readily adapted by LLMs. This involves enhancing source sentences with task-specific instructions and answer choices, allowing for the identification of entities and their types within natural language. We harness the strength of LLMs by integrating supervised learning within them. The goal of this combined strategy is to boost the performance of LLMs in extraction tasks like NER while simultaneously addressing hallucination issues often observed in LLM-generated content. A novel corpus Contract NER comprising seven frequently observed contract categories, encompassing named entities associated with 18 distinct legal entity types is released along with our baseline models. Our models and dataset are available to the community for future research * .
Question answering systems for health professionals at the point of care -- a systematic review
Jan 24, 2024Objective: Question answering (QA) systems have the potential to improve the quality of clinical care by providing health professionals with the latest and most relevant evidence. However, QA systems have not been widely adopted. This systematic review aims to characterize current medical QA systems, assess their suitability for healthcare, and identify areas of improvement. Materials and methods: We searched PubMed, IEEE Xplore, ACM Digital Library, ACL Anthology and forward and backward citations on 7th February 2023. We included peer-reviewed journal and conference papers describing the design and evaluation of biomedical QA systems. Two reviewers screened titles, abstracts, and full-text articles. We conducted a narrative synthesis and risk of bias assessment for each study. We assessed the utility of biomedical QA systems. Results: We included 79 studies and identified themes, including question realism, answer reliability, answer utility, clinical specialism, systems, usability, and evaluation methods. Clinicians' questions used to train and evaluate QA systems were restricted to certain sources, types and complexity levels. No system communicated confidence levels in the answers or sources. Many studies suffered from high risks of bias and applicability concerns. Only 8 studies completely satisfied any criterion for clinical utility, and only 7 reported user evaluations. Most systems were built with limited input from clinicians. Discussion: While machine learning methods have led to increased accuracy, most studies imperfectly reflected real-world healthcare information needs. Key research priorities include developing more realistic healthcare QA datasets and considering the reliability of answer sources, rather than merely focusing on accuracy.
Multilingual Visual Speech Recognition with a Single Model by Learning with Discrete Visual Speech Units
Jan 18, 2024This paper explores sentence-level Multilingual Visual Speech Recognition with a single model for the first time. As the massive multilingual modeling of visual data requires huge computational costs, we propose a novel strategy, processing with visual speech units. Motivated by the recent success of the audio speech unit, the proposed visual speech unit is obtained by discretizing the visual speech features extracted from the self-supervised visual speech model. To correctly capture multilingual visual speech, we first train the self-supervised visual speech model on 5,512 hours of multilingual audio-visual data. Through analysis, we verify that the visual speech units mainly contain viseme information while suppressing non-linguistic information. By using the visual speech units as the inputs of our system, we pre-train the model to predict corresponding text outputs on massive multilingual data constructed by merging several VSR databases. As both the inputs and outputs are discrete, we can greatly improve the training efficiency compared to the standard VSR training. Specifically, the input data size is reduced to 0.016% of the original video inputs. In order to complement the insufficient visual information in speech recognition, we apply curriculum learning where the inputs of the system begin with audio-visual speech units and gradually change to visual speech units. After pre-training, the model is finetuned on continuous features. We set new state-of-the-art multilingual VSR performances by achieving comparable performances to the previous language-specific VSR models, with a single trained model.
Truck Parking Usage Prediction with Decomposed Graph Neural Networks
Jan 23, 2024Truck parking on freight corridors faces various challenges, such as insufficient parking spaces and compliance with Hour-of-Service (HOS) regulations. These constraints often result in unauthorized parking practices, causing safety concerns. To enhance the safety of freight operations, providing accurate parking usage prediction proves to be a cost-effective solution. Despite the existing research demonstrating satisfactory accuracy for predicting individual truck parking site usage, few approaches have been proposed for predicting usage with spatial dependencies of multiple truck parking sites. We present the Regional Temporal Graph Neural Network (RegT-GCN) as a predictive framework for assessing parking usage across the entire state to provide better truck parking information and mitigate unauthorized parking. The framework leverages the topological structures of truck parking site distributions and historical parking data to predict occupancy rates across a state. To achieve this, we introduce a Regional Decomposition approach, which effectively captures the geographical characteristics. We also introduce the spatial module working efficiently with the temporal module. Evaluation results demonstrate that the proposed model surpasses other baseline models, improving the performance by more than $20\%$ compared with the original model. The proposed model allows truck parking sites' percipience of the topological structures and provides higher performance.
Control-Aware Trajectory Predictions for Communication-Efficient Drone Swarm Coordination in Cluttered Environments
Jan 23, 2024Swarms of Unmanned Aerial Vehicles (UAV) have demonstrated enormous potential in many industrial and commercial applications. However, before deploying UAVs in the real world, it is essential to ensure they can operate safely in complex environments, especially with limited communication capabilities. To address this challenge, we propose a control-aware learning-based trajectory prediction algorithm that can enable communication-efficient UAV swarm control in a cluttered environment. Specifically, our proposed algorithm can enable each UAV to predict the planned trajectories of its neighbors in scenarios with various levels of communication capabilities. The predicted planned trajectories will serve as input to a distributed model predictive control (DMPC) approach. The proposed algorithm combines (1) a trajectory compression and reconstruction model based on Variational Auto-Encoder, (2) a trajectory prediction model based on EvolveGCN, a graph convolutional network (GCN) that can handle dynamic graphs, and (3) a KKT-informed training approach that applies the Karush-Kuhn-Tucker (KKT) conditions in the training process to encode DMPC information into the trained neural network. We evaluate our proposed algorithm in a funnel-like environment. Results show that the proposed algorithm outperforms state-of-the-art benchmarks, providing close-to-optimal control performance and robustness to limited communication capabilities and measurement noises.
TD^2-Net: Toward Denoising and Debiasing for Dynamic Scene Graph Generation
Jan 23, 2024Dynamic scene graph generation (SGG) focuses on detecting objects in a video and determining their pairwise relationships. Existing dynamic SGG methods usually suffer from several issues, including 1) Contextual noise, as some frames might contain occluded and blurred objects. 2) Label bias, primarily due to the high imbalance between a few positive relationship samples and numerous negative ones. Additionally, the distribution of relationships exhibits a long-tailed pattern. To address the above problems, in this paper, we introduce a network named TD$^2$-Net that aims at denoising and debiasing for dynamic SGG. Specifically, we first propose a denoising spatio-temporal transformer module that enhances object representation with robust contextual information. This is achieved by designing a differentiable Top-K object selector that utilizes the gumbel-softmax sampling strategy to select the relevant neighborhood for each object. Second, we introduce an asymmetrical reweighting loss to relieve the issue of label bias. This loss function integrates asymmetry focusing factors and the volume of samples to adjust the weights assigned to individual samples. Systematic experimental results demonstrate the superiority of our proposed TD$^2$-Net over existing state-of-the-art approaches on Action Genome databases. In more detail, TD$^2$-Net outperforms the second-best competitors by 12.7 \% on mean-Recall@10 for predicate classification.
Boosting Unknown-number Speaker Separation with Transformer Decoder-based Attractor
Jan 23, 2024We propose a novel speech separation model designed to separate mixtures with an unknown number of speakers. The proposed model stacks 1) a dual-path processing block that can model spectro-temporal patterns, 2) a transformer decoder-based attractor (TDA) calculation module that can deal with an unknown number of speakers, and 3) triple-path processing blocks that can model inter-speaker relations. Given a fixed, small set of learned speaker queries and the mixture embedding produced by the dual-path blocks, TDA infers the relations of these queries and generates an attractor vector for each speaker. The estimated attractors are then combined with the mixture embedding by feature-wise linear modulation conditioning, creating a speaker dimension. The mixture embedding, conditioned with speaker information produced by TDA, is fed to the final triple-path blocks, which augment the dual-path blocks with an additional pathway dedicated to inter-speaker processing. The proposed approach outperforms the previous best reported in the literature, achieving 24.0 and 23.7 dB SI-SDR improvement (SI-SDRi) on WSJ0-2 and 3mix respectively, with a single model trained to separate 2- and 3-speaker mixtures. The proposed model also exhibits strong performance and generalizability at counting sources and separating mixtures with up to 5 speakers.