 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
NaroNet: Discovery of tumor microenvironment elements from highly multiplexed images
Mar 25, 2021
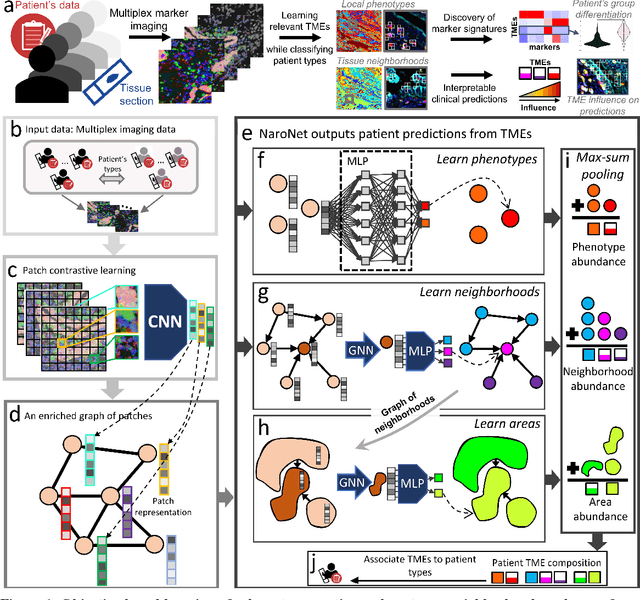
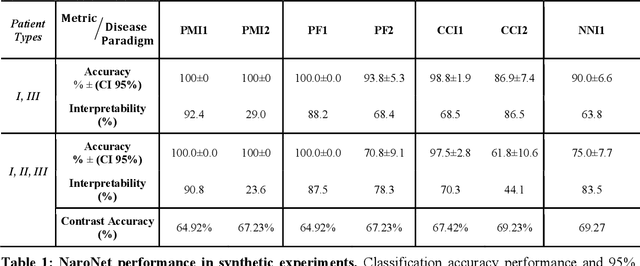
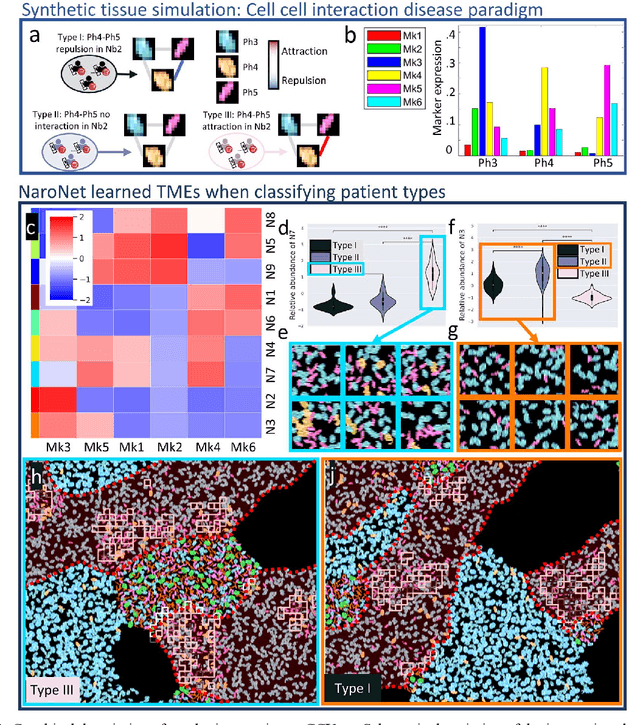
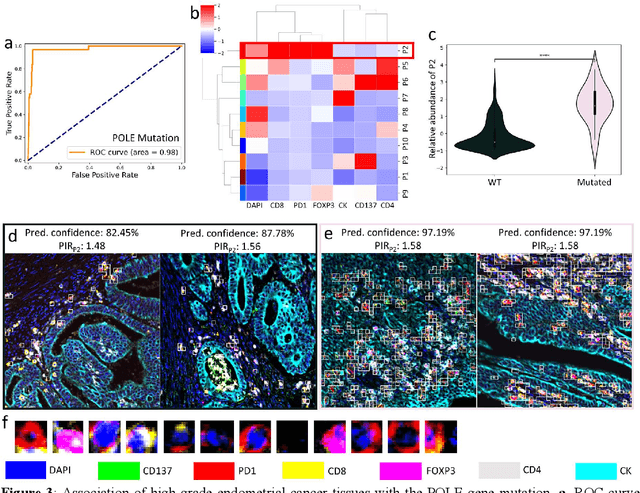
Many efforts have been made to discover tumor-specific microenvironment elements (TMEs) from immunostained tissue sections. However, the identification of yet unknown but relevant TMEs from multiplex immunostained tissues remains a challenge, due to the number of markers involved (tens) and the complexity of their spatial interactions. We present NaroNet, which uses machine learning to identify and annotate known as well as novel TMEs from self-supervised embeddings of cells, organized at different levels (local cell phenotypes and cellular neighborhoods). Then it uses the abundance of TMEs to classify patients based on biological or clinical features. We validate NaroNet using synthetic patient cohorts with adjustable incidence of different TMEs and two cancer patient datasets. In both synthetic and real datasets, NaroNet unsupervisedly identifies novel TMEs, relevant for the user-defined classification task. As NaroNet requires only patient-level information, it renders state-of-the-art computational methods accessible to a broad audience, accelerating the discovery of biomarker signatures.
Cross Chest Graph for Disease Diagnosis with Structural Relational Reasoning
Jan 22, 2021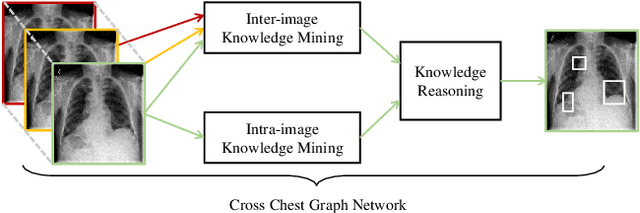
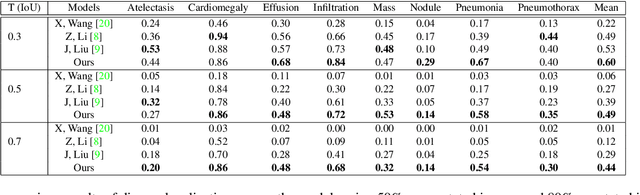
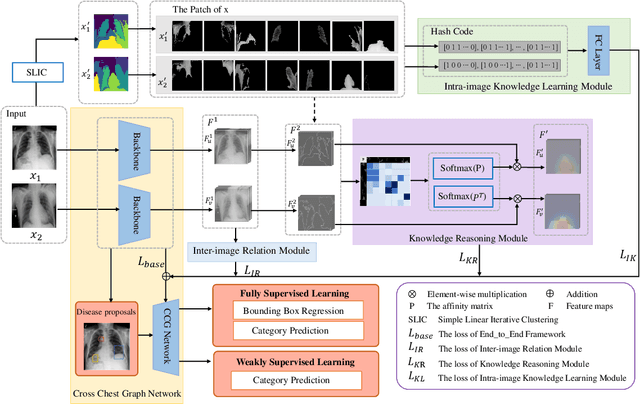
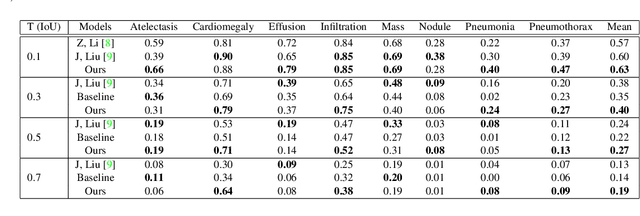
Locating lesions is important in the computer-aided diagnosis of X-ray images. However, box-level annotation is time-consuming and laborious. How to locate lesions accurately with few, or even without careful annotations is an urgent problem. Although several works have approached this problem with weakly-supervised methods, the performance needs to be improved. One obstacle is that general weakly-supervised methods have failed to consider the characteristics of X-ray images, such as the highly-structural attribute. We therefore propose the Cross-chest Graph (CCG), which improves the performance of automatic lesion detection by imitating doctor's training and decision-making process. CCG models the intra-image relationship between different anatomical areas by leveraging the structural information to simulate the doctor's habit of observing different areas. Meanwhile, the relationship between any pair of images is modeled by a knowledge-reasoning module to simulate the doctor's habit of comparing multiple images. We integrate intra-image and inter-image information into a unified end-to-end framework. Experimental results on the NIH Chest-14 database (112,120 frontal-view X-ray images with 14 diseases) demonstrate that the proposed method achieves state-of-the-art performance in weakly-supervised localization of lesions by absorbing professional knowledge in the medical field.
Deep Learning-Empowered Predictive Beamforming for IRS-Assisted Multi-User Communications
Apr 26, 2021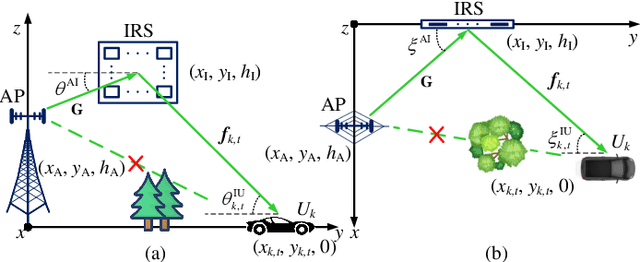
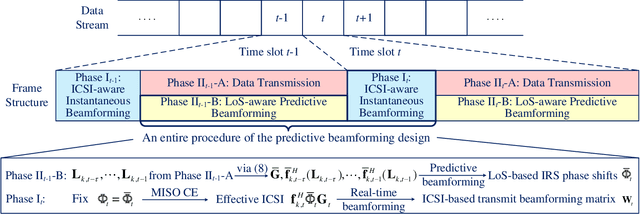
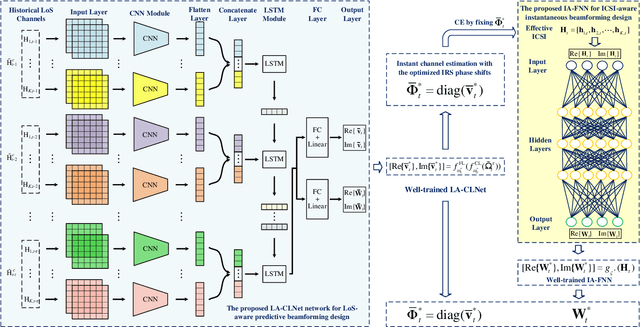
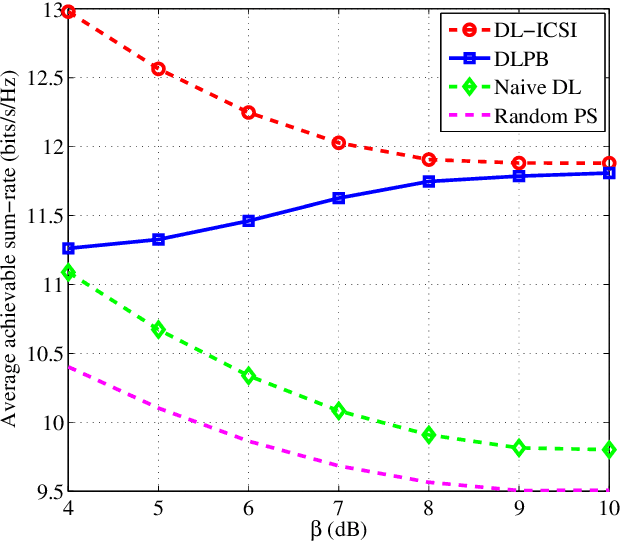
The realization of practical intelligent reflecting surface (IRS)-assisted multi-user communication (IRS-MUC) systems critically depends on the proper beamforming design exploiting accurate channel state information (CSI). However, channel estimation (CE) in IRS-MUC systems requires a significantly large training overhead due to the numerous reflection elements involved in IRS. In this paper, we adopt a deep learning approach to implicitly learn the historical channel features and directly predict the IRS phase shifts for the next time slot to maximize the average achievable sum-rate of an IRS-MUC system taking into account the user mobility. By doing this, only a low-dimension multiple-input single-output (MISO) CE is needed for transmit beamforming design, thus significantly reducing the CE overhead. To this end, a location-aware convolutional long short-term memory network (LA-CLNet) is first developed to facilitate predictive beamforming at IRS, where the convolutional and recurrent units are jointly adopted to exploit both the spatial and temporal features of channels simultaneously. Given the predictive IRS phase shift beamforming, an instantaneous CSI (ICSI)-aware fully-connected neural network (IA-FNN) is then proposed to optimize the transmit beamforming matrix at the access point. Simulation results demonstrate that the sum-rate performance achieved by the proposed method approaches that of the genie-aided scheme with the full perfect ICSI.
Trajectory Servoing: Image-Based Trajectory Tracking Using SLAM
Feb 26, 2021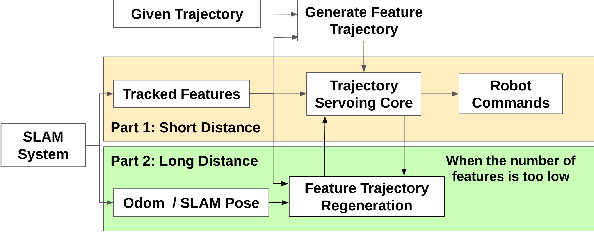
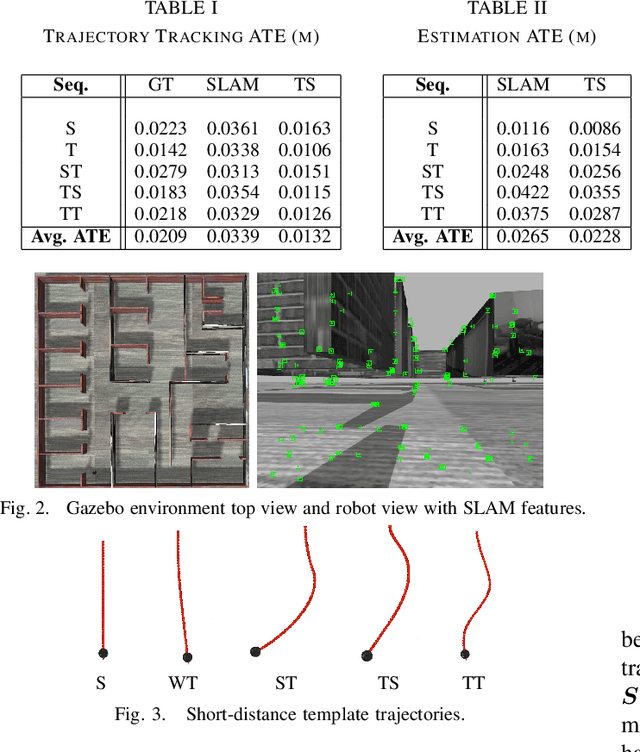
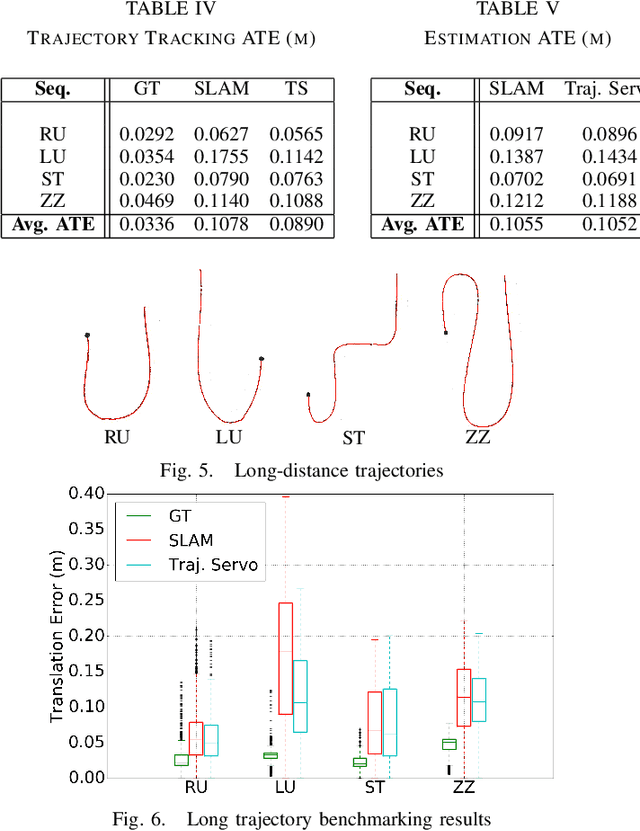
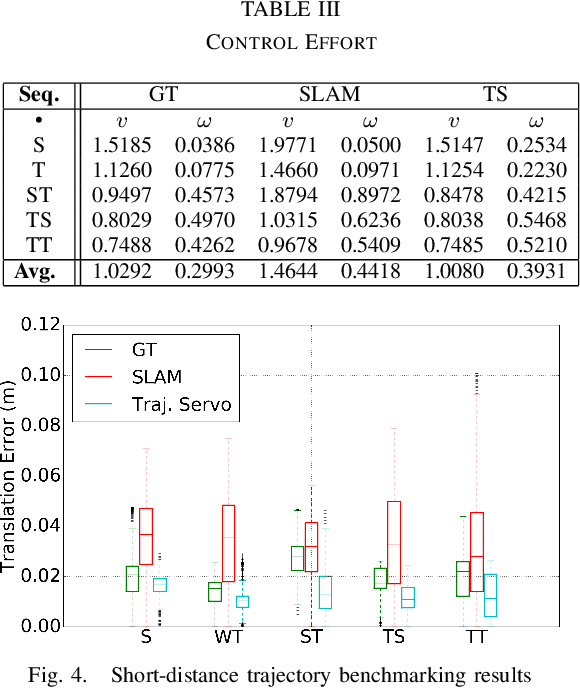
This paper describes an image based visual servoing (IBVS) system for a nonholonomic robot to achieve good trajectory following without real-time robot pose information and without a known visual map of the environment. We call it trajectory servoing. The critical component is a feature-based, indirect SLAM method to provide a pool of available features with estimated depth, so that they may be propagated forward in time to generate image feature trajectories for visual servoing. Short and long distance experiments show the benefits of trajectory servoing for navigating unknown areas without absolute positioning. Trajectory servoing is shown to be more accurate than pose-based feedback when both rely on the same underlying SLAM system.
A Structural Causal Model for MR Images of Multiple Sclerosis
Mar 04, 2021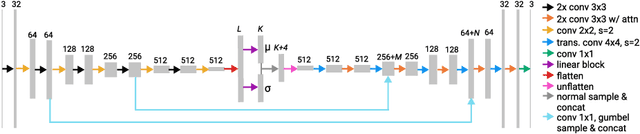


Precision medicine involves answering counterfactual questions such as "Would this patient respond better to treatment A or treatment B?" These types of questions are causal in nature and require the tools of causal inference to be answered, e.g., with a structural causal model (SCM). In this work, we develop an SCM that models the interaction between demographic information, disease covariates, and magnetic resonance (MR) images of the brain for people with multiple sclerosis (MS). Inference in the SCM generates counterfactual images that show what an MR image of the brain would look like when demographic or disease covariates are changed. These images can be used for modeling disease progression or used for downstream image processing tasks where controlling for confounders is necessary.
DRO: Deep Recurrent Optimizer for Structure-from-Motion
Mar 25, 2021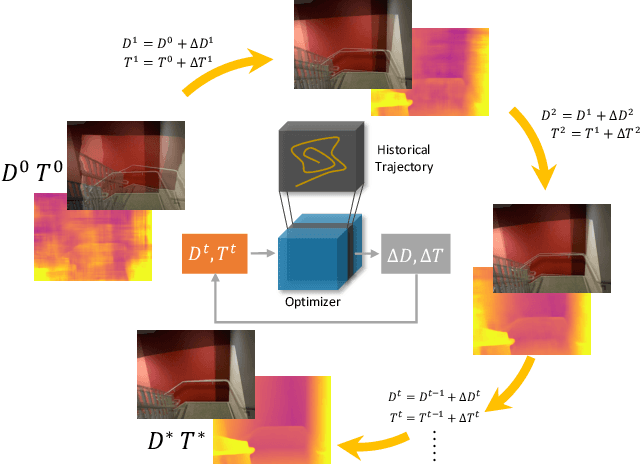
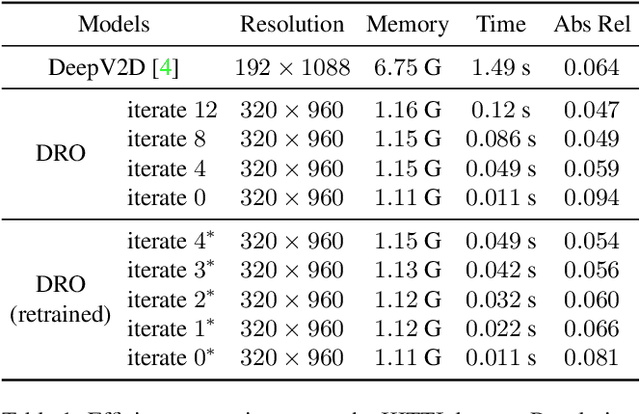
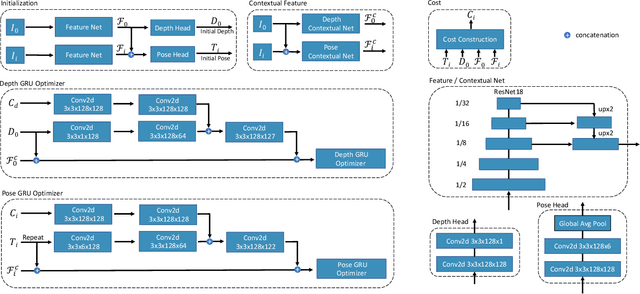
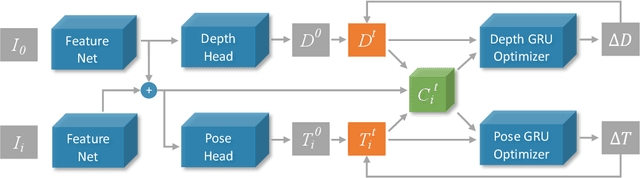
There are increasing interests of studying the structure-from-motion (SfM) problem with machine learning techniques. While earlier methods directly learn a mapping from images to depth maps and camera poses, more recent works enforce multi-view geometry through optimization embed in the learning framework. This paper presents a novel optimization method based on recurrent neural networks to further exploit the potential of neural networks in SfM. Our neural optimizer alternatively updates the depth and camera poses through iterations to minimize a feature-metric cost. Two gated recurrent units are designed to trace the historical information during the iterations. Our network works as a zeroth-order optimizer, where the computation and memory expensive cost volume or gradients are avoided. Experiments demonstrate that our recurrent optimizer effectively reduces the feature-metric cost while refining the depth and poses. Our method outperforms previous methods and is more efficient in computation and memory consumption than cost-volume-based methods. The code of our method will be made public.
Multicriteria Group Decision-Making Under Uncertainty Using Interval Data and Cloud Models
Dec 01, 2020In this study, we propose a multicriteria group decision making (MCGDM) algorithm under uncertainty where data is collected as intervals. The proposed MCGDM algorithm aggregates the data, determines the optimal weights for criteria and ranks alternatives with no further input. The intervals give flexibility to experts in assessing alternatives against criteria and provide an opportunity to gain maximum information. We also propose a novel method to aggregate expert judgements using cloud models. We introduce an experimental approach to check the validity of the aggregation method. After that, we use the aggregation method for an MCGDM problem. Here, we find the optimal weights for each criterion by proposing a bilevel optimisation model. Then, we extend the technique for order of preference by similarity to ideal solution (TOPSIS) for data based on cloud models to prioritise alternatives. As a result, the algorithm can gain information from decision makers with different levels of uncertainty and examine alternatives with no more information from decision-makers. The proposed MCGDM algorithm is implemented on a case study of a cybersecurity problem to illustrate its feasibility and effectiveness. The results verify the robustness and validity of the proposed MCGDM using sensitivity analysis and comparison with other existing algorithms.
Efficient approximation of DNA hybridisation using deep learning
Feb 19, 2021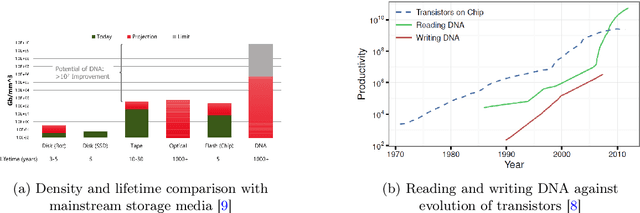

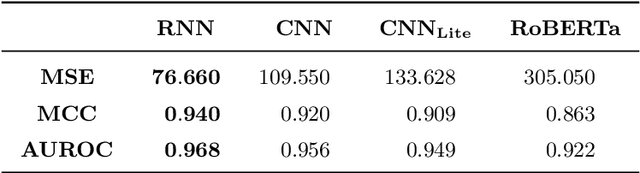
Deoxyribonucleic acid (DNA) has shown great promise in enabling computational applications, most notably in the fields of DNA data storage and DNA computing. The former exploits the natural properties of DNA, such as high storage density and longevity, for the archival of digital information, while the latter aims to use the interactivity of DNA to encode computations. Recently, the two paradigms were jointly used to formulate the near-data processing concept for DNA databases, where the computations are performed directly on the stored data. The fundamental, low-level operation that DNA naturally possesses is that of hybridisation, also called annealing, of complementary sequences. Information is encoded as DNA strands, which will naturally bind in solution, thus enabling search and pattern-matching capabilities. Being able to control and predict the process of hybridisation is crucial for the ambitious future of the so-called Hybrid Molecular-Electronic Computing. Current tools are, however, limited in terms of throughput and applicability to large-scale problems. In this work, we present the first comprehensive study of machine learning methods applied to the task of predicting DNA hybridisation. For this purpose, we introduce a synthetic hybridisation dataset of over 2.5 million data points, enabling the use of a wide range of machine learning algorithms, including the latest in deep learning. Depending on the hardware, the proposed models provide a reduction in inference time ranging from one to over two orders of magnitude compared to the state-of-the-art, while retaining high fidelity. We then discuss the integration of our methods in modern, scalable workflows. The implementation is available at: https://github.com/davidbuterez/dna-hyb-deep-learning
Towards Real-time Semantic RGB-D SLAM in Dynamic Environments
Apr 03, 2021


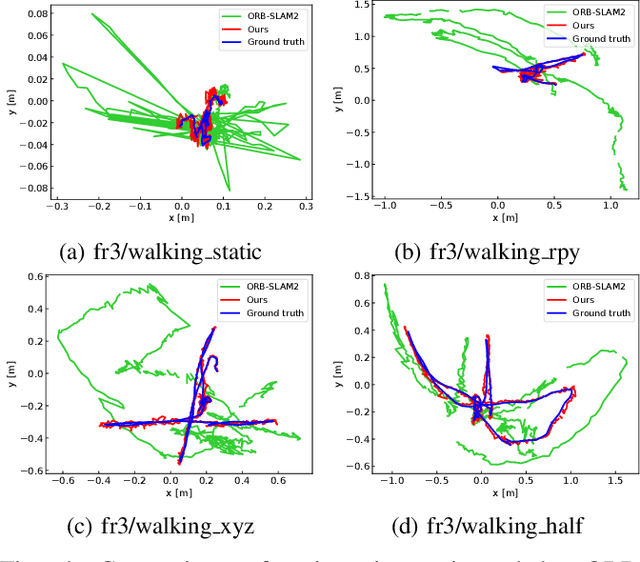
Most of the existing visual SLAM methods heavily rely on a static world assumption and easily fail in dynamic environments. Some recent works eliminate the influence of dynamic objects by introducing deep learning-based semantic information to SLAM systems. However such methods suffer from high computational cost and cannot handle unknown objects. In this paper, we propose a real-time semantic RGB-D SLAM system for dynamic environments that is capable of detecting both known and unknown moving objects. To reduce the computational cost, we only perform semantic segmentation on keyframes to remove known dynamic objects, and maintain a static map for robust camera tracking. Furthermore, we propose an efficient geometry module to detect unknown moving objects by clustering the depth image into a few regions and identifying the dynamic regions via their reprojection errors. The proposed method is evaluated on public datasets and real-world conditions. To the best of our knowledge, it is one of the first semantic RGB-D SLAM systems that run in real-time on a low-power embedded platform and provide high localization accuracy in dynamic environments.
AirMixML: Over-the-Air Data Mixup for Inherently Privacy-Preserving Edge Machine Learning
May 02, 2021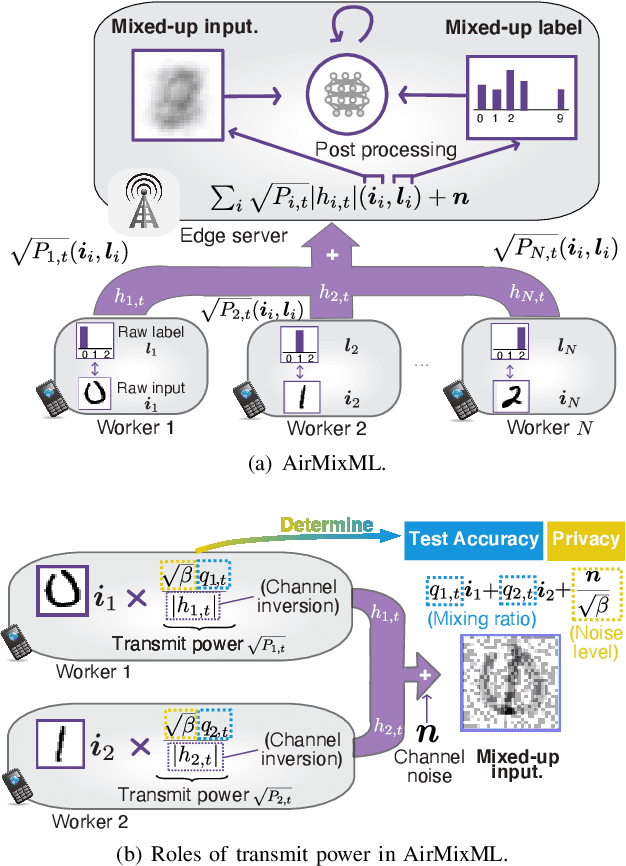
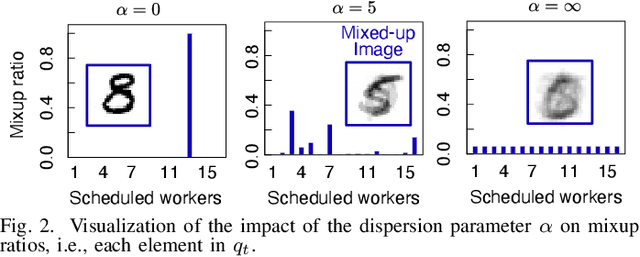
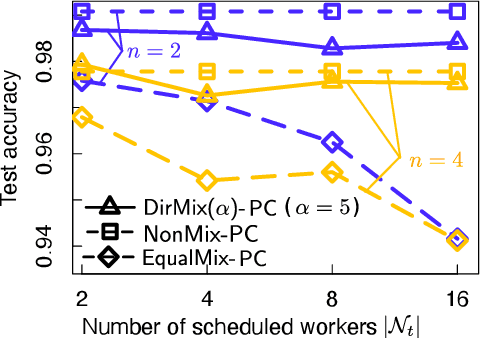
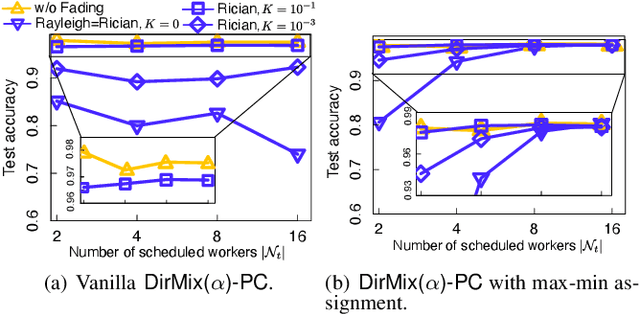
Wireless channels can be inherently privacy-preserving by distorting the received signals due to channel noise, and superpositioning multiple signals over-the-air. By harnessing these natural distortions and superpositions by wireless channels, we propose a novel privacy-preserving machine learning (ML) framework at the network edge, coined over-the-air mixup ML (AirMixML). In AirMixML, multiple workers transmit analog-modulated signals of their private data samples to an edge server who trains an ML model using the received noisy-and superpositioned samples. AirMixML coincides with model training using mixup data augmentation achieving comparable accuracy to that with raw data samples. From a privacy perspective, AirMixML is a differentially private (DP) mechanism limiting the disclosure of each worker's private sample information at the server, while the worker's transmit power determines the privacy disclosure level. To this end, we develop a fractional channel-inversion power control (PC) method, {\alpha}-Dirichlet mixup PC (DirMix({\alpha})-PC), wherein for a given global power scaling factor after channel inversion, each worker's local power contribution to the superpositioned signal is controlled by the Dirichlet dispersion ratio {\alpha}. Mathematically, we derive a closed-form expression clarifying the relationship between the local and global PC factors to guarantee a target DP level. By simulations, we provide DirMix({\alpha})-PC design guidelines to improve accuracy, privacy, and energy-efficiency. Finally, AirMixML with DirMix({\alpha})-PC is shown to achieve reasonable accuracy compared to a privacy-violating baseline with neither superposition nor PC.