 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A High-order Tuner for Accelerated Learning and Control
Mar 23, 2021
Gradient-descent based iterative algorithms pervade a variety of problems in estimation, prediction, learning, control, and optimization. Recently iterative algorithms based on higher-order information have been explored in an attempt to lead to accelerated learning. In this paper, we explore a specific a high-order tuner that has been shown to result in stability with time-varying regressors in linearly parametrized systems, and accelerated convergence with constant regressors. We show that this tuner continues to provide bounded parameter estimates even if the gradients are corrupted by noise. Additionally, we also show that the parameter estimates converge exponentially to a compact set whose size is dependent on noise statistics. As the HT algorithms can be applied to a wide range of problems in estimation, filtering, control, and machine learning, the result obtained in this paper represents an important extension to the topic of real-time and fast decision making.
Concentric Spherical GNN for 3D Representation Learning
Mar 18, 2021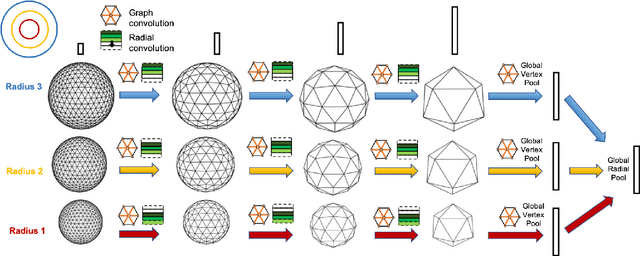
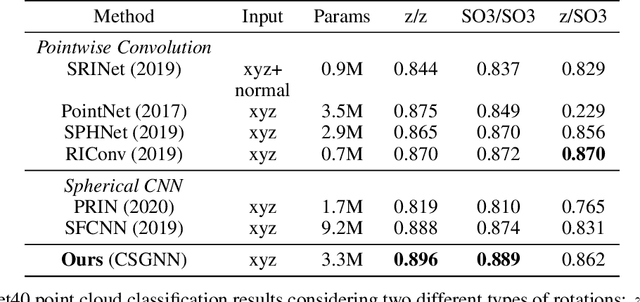
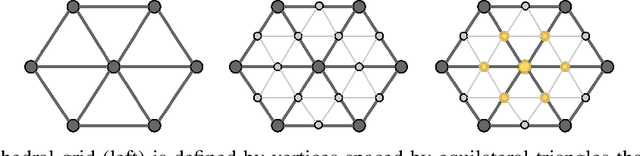
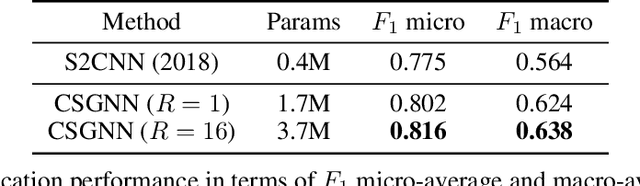
Learning 3D representations that generalize well to arbitrarily oriented inputs is a challenge of practical importance in applications varying from computer vision to physics and chemistry. We propose a novel multi-resolution convolutional architecture for learning over concentric spherical feature maps, of which the single sphere representation is a special case. Our hierarchical architecture is based on alternatively learning to incorporate both intra-sphere and inter-sphere information. We show the applicability of our method for two different types of 3D inputs, mesh objects, which can be regularly sampled, and point clouds, which are irregularly distributed. We also propose an efficient mapping of point clouds to concentric spherical images, thereby bridging spherical convolutions on grids with general point clouds. We demonstrate the effectiveness of our approach in improving state-of-the-art performance on 3D classification tasks with rotated data.
Towards Self-Supervision for Video Identification of Individual Holstein-Friesian Cattle: The Cows2021 Dataset
May 05, 2021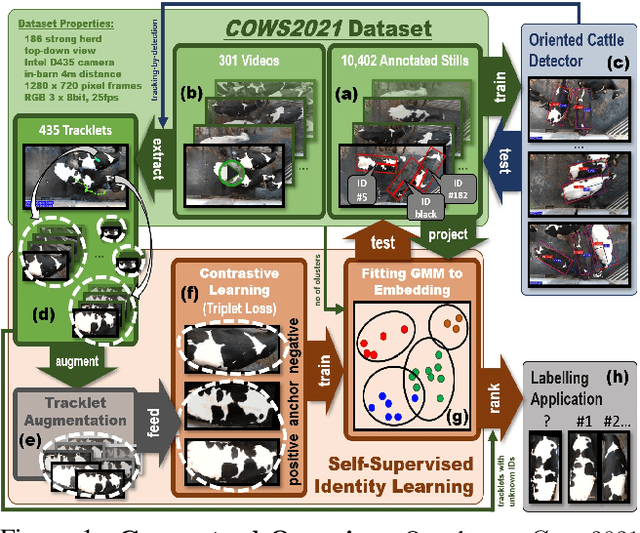


In this paper we publish the largest identity-annotated Holstein-Friesian cattle dataset Cows2021 and a first self-supervision framework for video identification of individual animals. The dataset contains 10,402 RGB images with labels for localisation and identity as well as 301 videos from the same herd. The data shows top-down in-barn imagery, which captures the breed's individually distinctive black and white coat pattern. Motivated by the labelling burden involved in constructing visual cattle identification systems, we propose exploiting the temporal coat pattern appearance across videos as a self-supervision signal for animal identity learning. Using an individual-agnostic cattle detector that yields oriented bounding-boxes, rotation-normalised tracklets of individuals are formed via tracking-by-detection and enriched via augmentations. This produces a `positive' sample set per tracklet, which is paired against a `negative' set sampled from random cattle of other videos. Frame-triplet contrastive learning is then employed to construct a metric latent space. The fitting of a Gaussian Mixture Model to this space yields a cattle identity classifier. Results show an accuracy of Top-1 57.0% and Top-4: 76.9% and an Adjusted Rand Index: 0.53 compared to the ground truth. Whilst supervised training surpasses this benchmark by a large margin, we conclude that self-supervision can nevertheless play a highly effective role in speeding up labelling efforts when initially constructing supervision information. We provide all data and full source code alongside an analysis and evaluation of the system.
A Neural Dynamic Model based on Activation Diffusion and a Micro-Explanation for Cognitive Operations
Nov 27, 2020The neural mechanism of memory has a very close relation with the problem of representation in artificial intelligence. In this paper a computational model was proposed to simulate the network of neurons in brain and how they process information. The model refers to morphological and electrophysiological characteristics of neural information processing, and is based on the assumption that neurons encode their firing sequence. The network structure, functions for neural encoding at different stages, the representation of stimuli in memory, and an algorithm to form a memory were presented. It also analyzed the stability and recall rate for learning and the capacity of memory. Because neural dynamic processes, one succeeding another, achieve a neuron-level and coherent form by which information is represented and processed, it may facilitate examination of various branches of Artificial Intelligence, such as inference, problem solving, pattern recognition, natural language processing and learning. The processes of cognitive manipulation occurring in intelligent behavior have a consistent representation while all being modeled from the perspective of computational neuroscience. Thus, the dynamics of neurons make it possible to explain the inner mechanisms of different intelligent behaviors by a unified model of cognitive architecture at a micro-level.
Constrained Radar Waveform Design for Range Profiling
Mar 18, 2021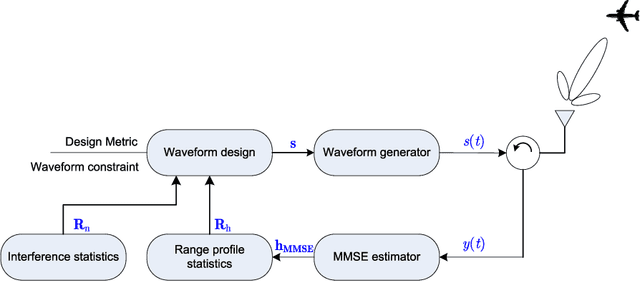
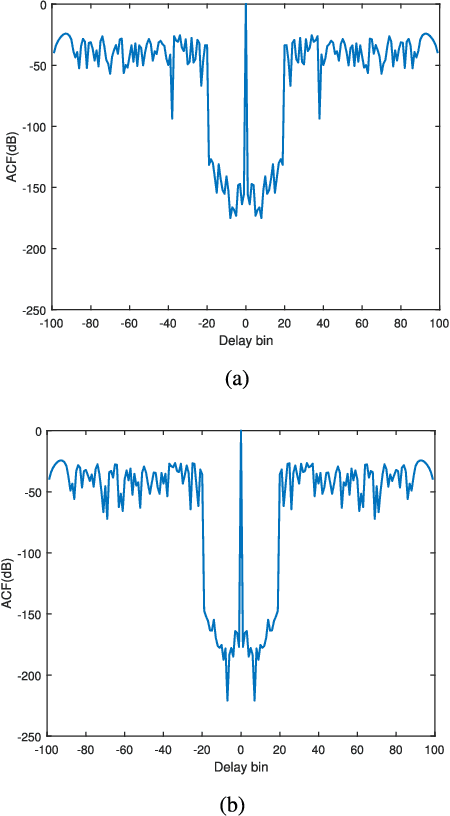
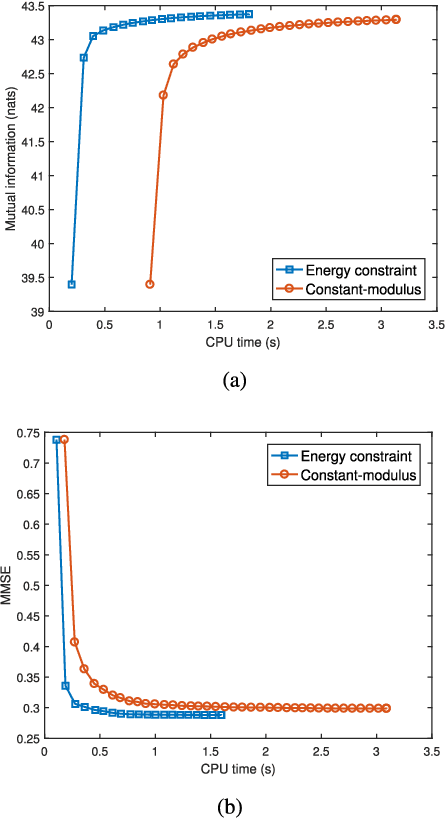
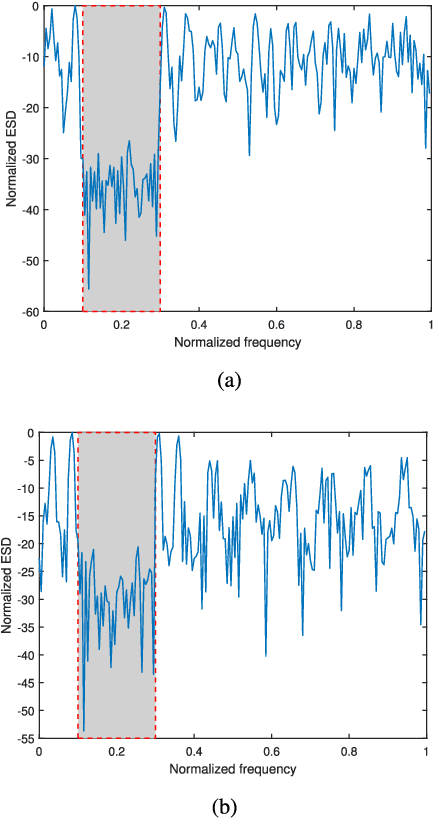
Range profiling refers to the measurement of target response along the radar slant range. It plays an important role in automatic target recognition. In this paper, we consider the design of transmit waveform to improve the range profiling performance of radar systems. Two design metrics are adopted for the waveform optimization problem: one is to maximize the mutual information between the received signal and the target impulse response (TIR); the other is to minimize the minimum mean-square error for estimating the TIR. In addition, practical constraints on the waveforms are considered, including an energy constraint, a peak-to-average-power-ratio constraint, and a spectral constraint. Based on minorization-maximization, we propose a unified optimization framework to tackle the constrained waveform design problem. Numerical examples show the superiority of the waveforms synthesized by the proposed algorithms.
Continual learning in cross-modal retrieval
Apr 14, 2021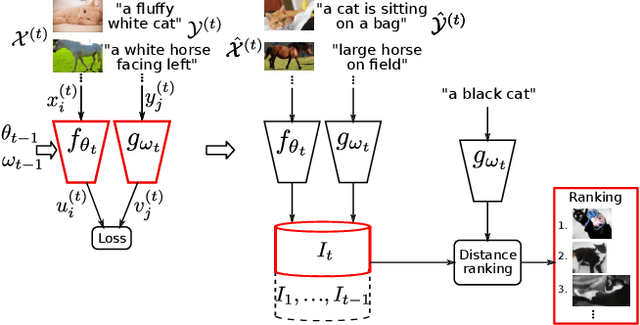
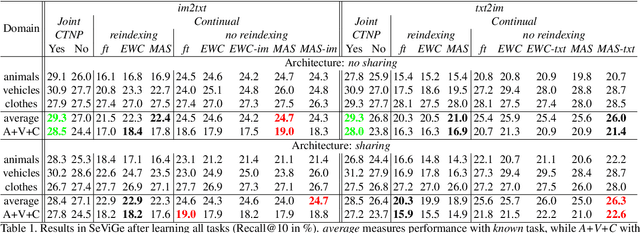
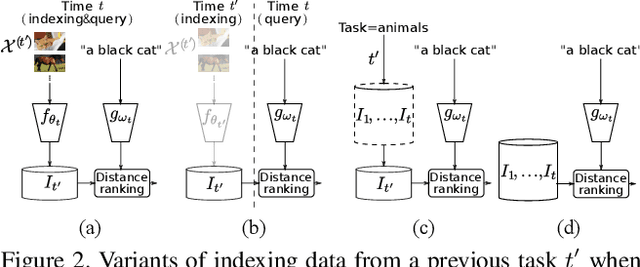
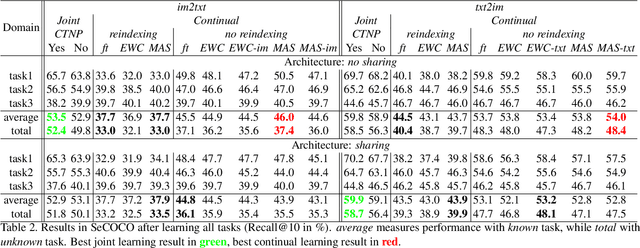
Multimodal representations and continual learning are two areas closely related to human intelligence. The former considers the learning of shared representation spaces where information from different modalities can be compared and integrated (we focus on cross-modal retrieval between language and visual representations). The latter studies how to prevent forgetting a previously learned task when learning a new one. While humans excel in these two aspects, deep neural networks are still quite limited. In this paper, we propose a combination of both problems into a continual cross-modal retrieval setting, where we study how the catastrophic interference caused by new tasks impacts the embedding spaces and their cross-modal alignment required for effective retrieval. We propose a general framework that decouples the training, indexing and querying stages. We also identify and study different factors that may lead to forgetting, and propose tools to alleviate it. We found that the indexing stage pays an important role and that simply avoiding reindexing the database with updated embedding networks can lead to significant gains. We evaluated our methods in two image-text retrieval datasets, obtaining significant gains with respect to the fine tuning baseline.
Reverse-engineering Bar Charts Using Neural Networks
Sep 05, 2020
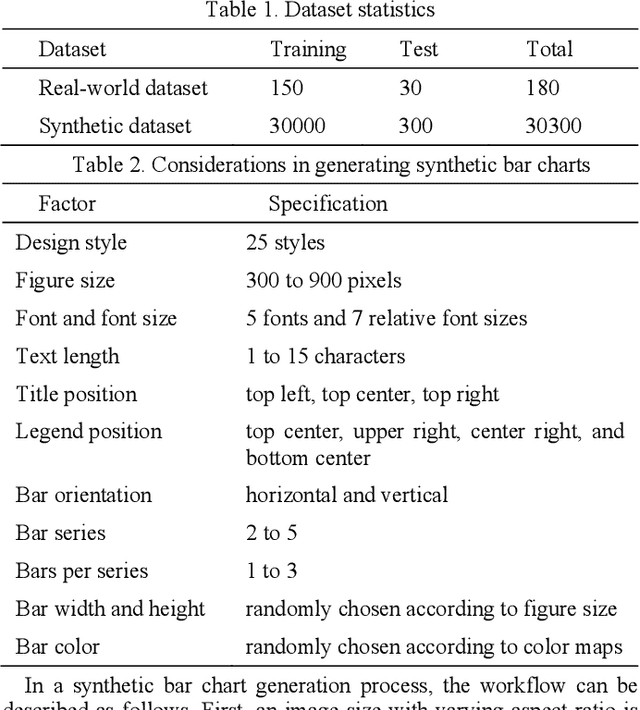
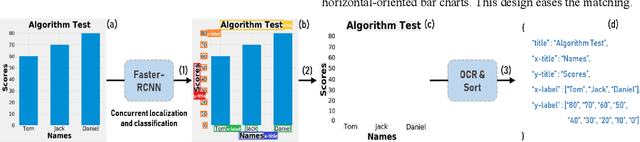
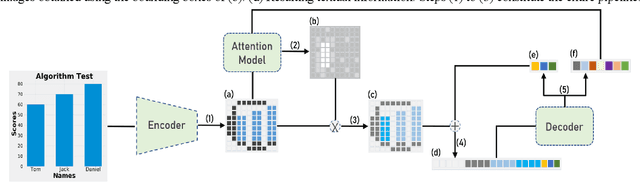
Reverse-engineering bar charts extracts textual and numeric information from the visual representations of bar charts to support application scenarios that require the underlying information. In this paper, we propose a neural network-based method for reverse-engineering bar charts. We adopt a neural network-based object detection model to simultaneously localize and classify textual information. This approach improves the efficiency of textual information extraction. We design an encoder-decoder framework that integrates convolutional and recurrent neural networks to extract numeric information. We further introduce an attention mechanism into the framework to achieve high accuracy and robustness. Synthetic and real-world datasets are used to evaluate the effectiveness of the method. To the best of our knowledge, this work takes the lead in constructing a complete neural network-based method of reverse-engineering bar charts.
Representation Learning by Ranking under multiple tasks
Mar 28, 2021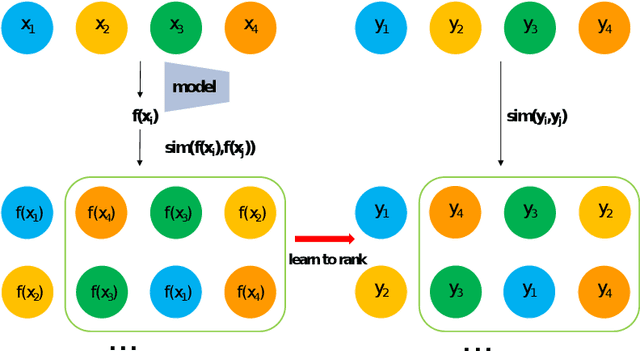

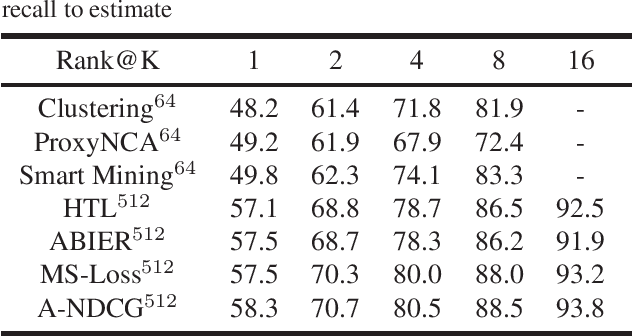
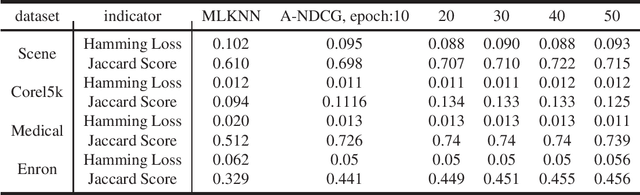
In recent years, representation learning has become the research focus of the machine learning community. Large-scale pre-training neural networks have become the first step to realize general intelligence. The key to the success of neural networks lies in their abstract representation capabilities for data. Several learning fields are actually discussing how to learn representations and there lacks a unified perspective. We convert the representation learning problem under multiple tasks into a ranking problem, taking the ranking problem as a unified perspective, the representation learning under different tasks is solved by optimizing the approximate NDCG loss. Experiments under different learning tasks like classification, retrieval, multi-label learning, regression, self-supervised learning prove the superiority of approximate NDCG loss. Further, under the self-supervised learning task, the training data is transformed by data augmentation method to improve the performance of the approximate NDCG loss, which proves that the approximate NDCG loss can make full use of the information of the unsupervised training data.
Multimodal Personal Ear Authentication Using Smartphones
Mar 23, 2021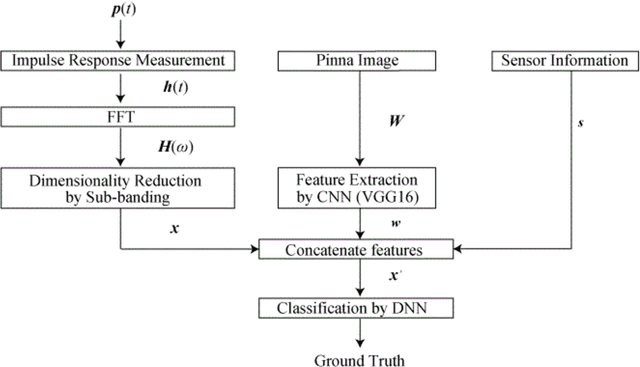


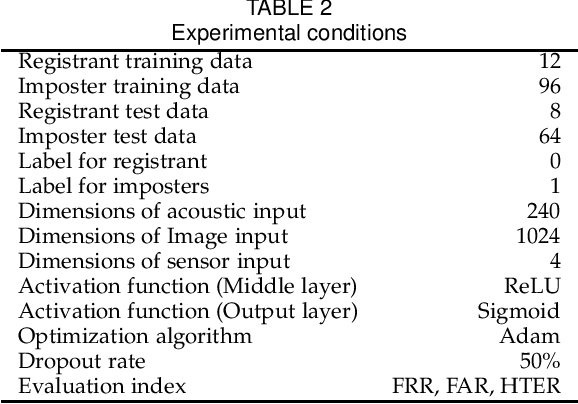
In recent years, biometric authentication technology for smartphones has become widespread, with the mainstream methods being fingerprint authentication and face recognition. However, fingerprint authentication cannot be used when hands are wet, and face recognition cannot be used when a person is wearing a mask. Therefore, we examine a personal authentication system using the pinna as a new approach for biometric authentication on smartphones. Authentication systems based on the acoustic transfer function of the pinna (PRTF: Pinna Related Transfer Function) have been investigated. However, the authentication accuracy decreases due to the positional fluctuation across each measurement. In this paper, we propose multimodal personal authentication on smartphones using PRTF. The pinna image and positional sensor information are used with the PRTF, and the effectiveness of the authentication method is examined. We demonstrate that the proposed authentication system can compensate for the positional changes in each measurement and improve robustness.
Simple and Efficient Learning using Privileged Information
Apr 06, 2016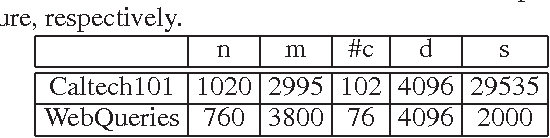
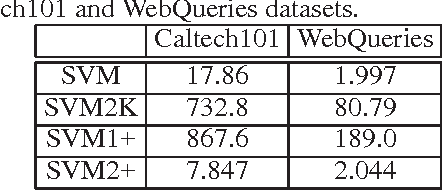

The Support Vector Machine using Privileged Information (SVM+) has been proposed to train a classifier to utilize the additional privileged information that is only available in the training phase but not available in the test phase. In this work, we propose an efficient solution for SVM+ by simply utilizing the squared hinge loss instead of the hinge loss as in the existing SVM+ formulation, which interestingly leads to a dual form with less variables and in the same form with the dual of the standard SVM. The proposed algorithm is utilized to leverage the additional web knowledge that is only available during training for the image categorization tasks. The extensive experimental results on both Caltech101 andWebQueries datasets show that our proposed method can achieve a factor of up to hundred times speedup with the comparable accuracy when compared with the existing SVM+ method.