 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Representation by Mutual Information
Mar 28, 2021


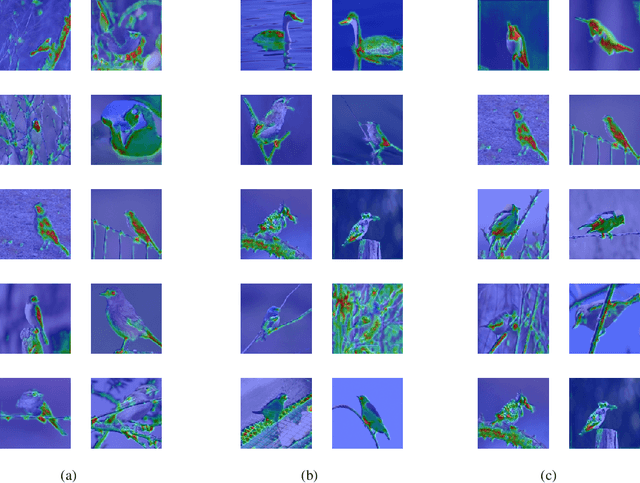
Science is used to discover the law of world. Machine learning can be used to discover the law of data. In recent years, there are more and more research about interpretability in machine learning community. We hope the machine learning methods are safe, interpretable, and they can help us to find meaningful pattern in data. In this paper, we focus on interpretability of deep representation. We propose a interpretable method of representation based on mutual information, which summarizes the interpretation of representation into three types of information between input data and representation. We further proposed MI-LR module, which can be inserted into the model to estimate the amount of information to explain the model's representation. Finally, we verify the method through the visualization of the prototype network.
Hierarchical Relationship Alignment Metric Learning
Mar 28, 2021
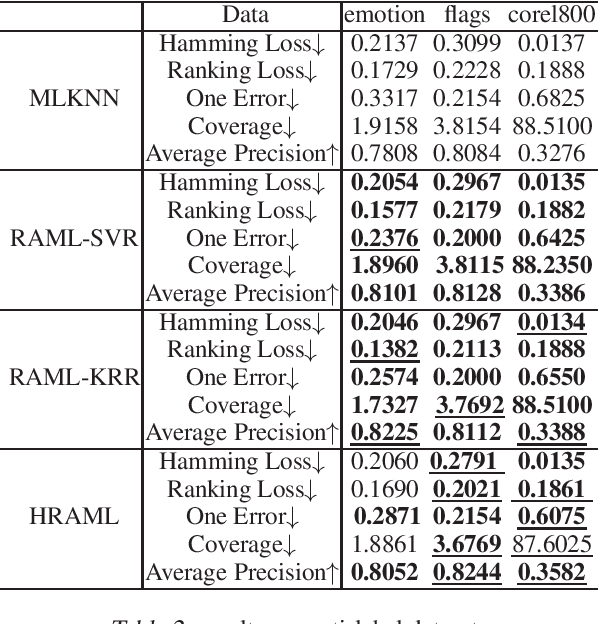
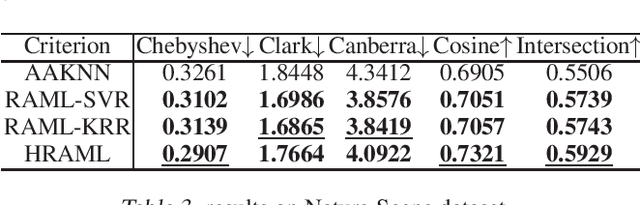
Most existing metric learning methods focus on learning a similarity or distance measure relying on similar and dissimilar relations between sample pairs. However, pairs of samples cannot be simply identified as similar or dissimilar in many real-world applications, e.g., multi-label learning, label distribution learning. To this end, relation alignment metric learning (RAML) framework is proposed to handle the metric learning problem in those scenarios. But RAML learn a linear metric, which can't model complex datasets. Combining with deep learning and RAML framework, we propose a hierarchical relationship alignment metric leaning model HRAML, which uses the concept of relationship alignment to model metric learning problems under multiple learning tasks, and makes full use of the consistency between the sample pair relationship in the feature space and the sample pair relationship in the label space. Further we organize several experiment divided by learning tasks, and verified the better performance of HRAML against many popular methods and RAML framework.
Representation Learning by Ranking under multiple tasks
Mar 28, 2021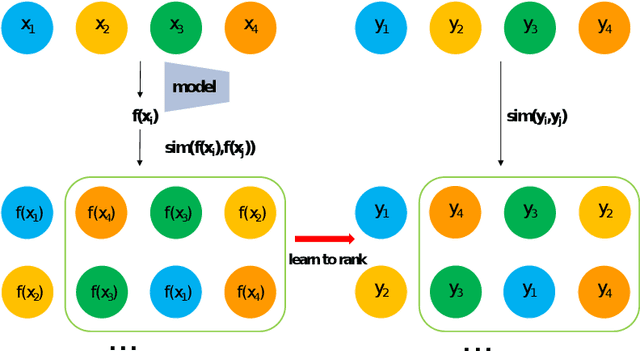

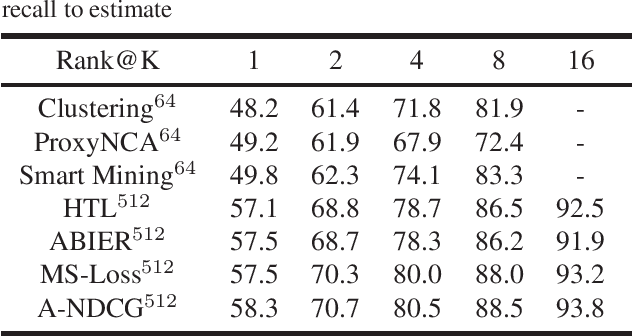
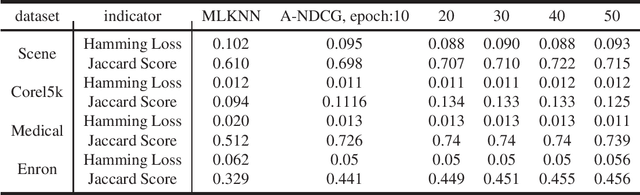
In recent years, representation learning has become the research focus of the machine learning community. Large-scale pre-training neural networks have become the first step to realize general intelligence. The key to the success of neural networks lies in their abstract representation capabilities for data. Several learning fields are actually discussing how to learn representations and there lacks a unified perspective. We convert the representation learning problem under multiple tasks into a ranking problem, taking the ranking problem as a unified perspective, the representation learning under different tasks is solved by optimizing the approximate NDCG loss. Experiments under different learning tasks like classification, retrieval, multi-label learning, regression, self-supervised learning prove the superiority of approximate NDCG loss. Further, under the self-supervised learning task, the training data is transformed by data augmentation method to improve the performance of the approximate NDCG loss, which proves that the approximate NDCG loss can make full use of the information of the unsupervised training data.
Positive semidefinite support vector regression metric learning
Aug 18, 2020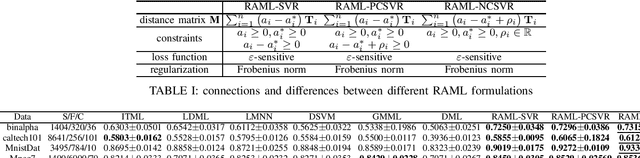
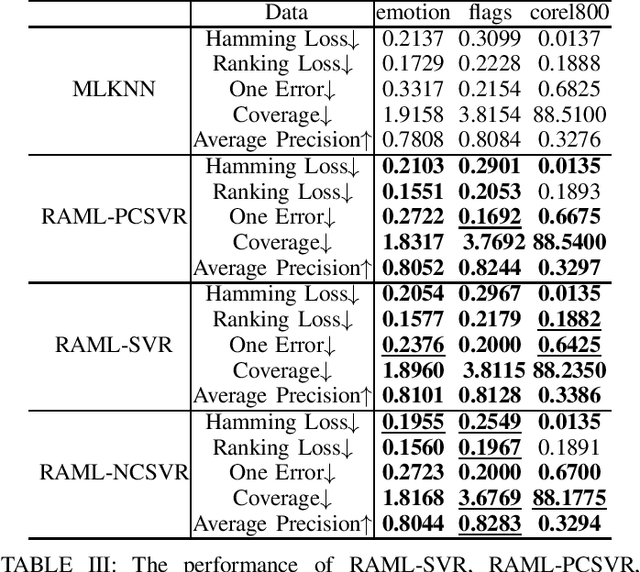
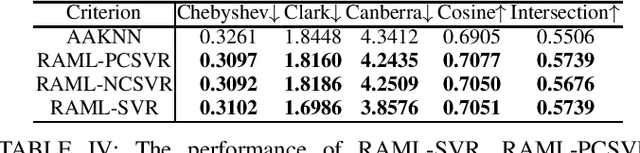
Most existing metric learning methods focus on learning a similarity or distance measure relying on similar and dissimilar relations between sample pairs. However, pairs of samples cannot be simply identified as similar or dissimilar in many real-world applications, e.g., multi-label learning, label distribution learning. To this end, relation alignment metric learning (RAML) framework is proposed to handle the metric learning problem in those scenarios. But RAML framework uses SVR solvers for optimization. It can't learn positive semidefinite distance metric which is necessary in metric learning. In this paper, we propose two methds to overcame the weakness. Further, We carry out several experiments on the single-label classification, multi-label classification, label distribution learning to demonstrate the new methods achieves favorable performance against RAML framework.