 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Brain Tumor Segmentation and Survival Prediction using 3D Attention UNet
Apr 02, 2021
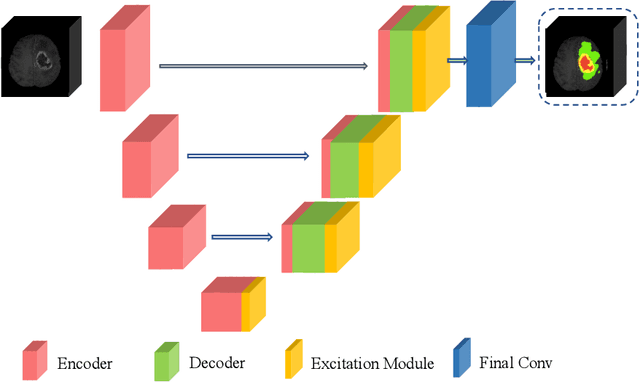
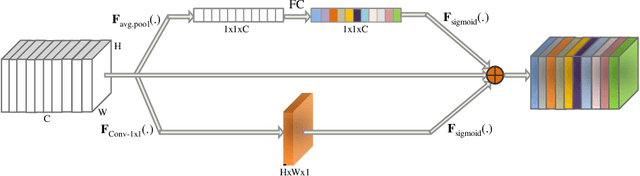
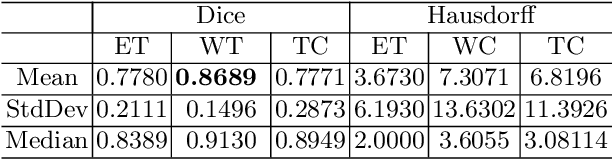
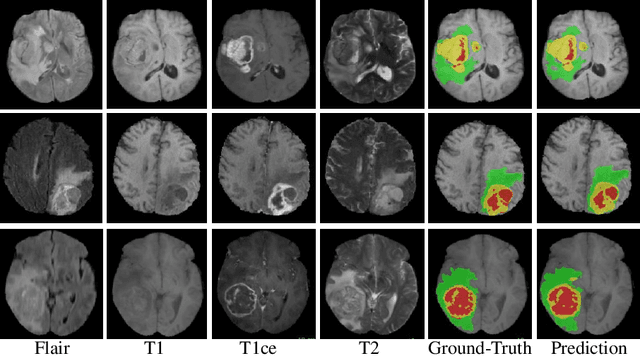
In this work, we develop an attention convolutional neural network (CNN) to segment brain tumors from Magnetic Resonance Images (MRI). Further, we predict the survival rate using various machine learning methods. We adopt a 3D UNet architecture and integrate channel and spatial attention with the decoder network to perform segmentation. For survival prediction, we extract some novel radiomic features based on geometry, location, the shape of the segmented tumor and combine them with clinical information to estimate the survival duration for each patient. We also perform extensive experiments to show the effect of each feature for overall survival (OS) prediction. The experimental results infer that radiomic features such as histogram, location, and shape of the necrosis region and clinical features like age are the most critical parameters to estimate the OS.
Identifying the Limits of Cross-Domain Knowledge Transfer for Pretrained Models
Apr 17, 2021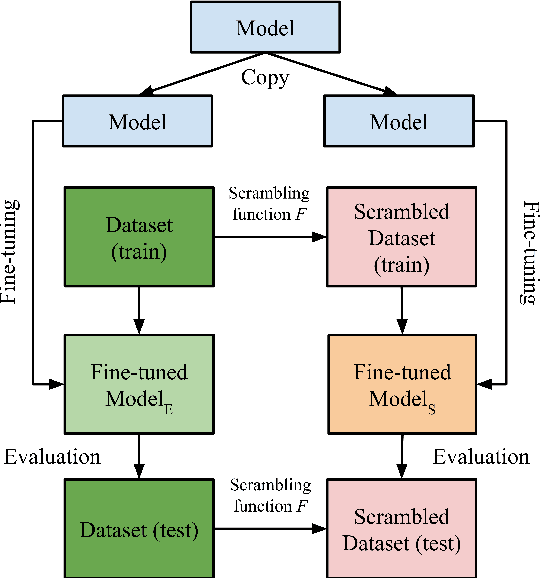

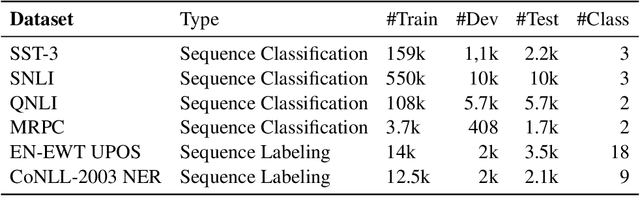
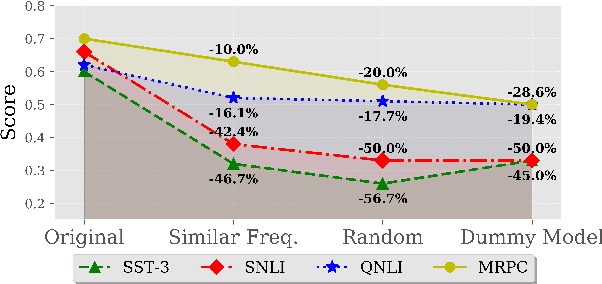
There is growing evidence that pretrained language models improve task-specific fine-tuning not just for the languages seen in pretraining, but also for new languages and even non-linguistic data. What is the nature of this surprising cross-domain transfer? We offer a partial answer via a systematic exploration of how much transfer occurs when models are denied any information about word identity via random scrambling. In four classification tasks and two sequence labeling tasks, we evaluate baseline models, LSTMs using GloVe embeddings, and BERT. We find that only BERT shows high rates of transfer into our scrambled domains, and for classification but not sequence labeling tasks. Our analyses seek to explain why transfer succeeds for some tasks but not others, to isolate the separate contributions of pretraining versus fine-tuning, and to quantify the role of word frequency. These findings help explain where and why cross-domain transfer occurs, which can guide future studies and practical fine-tuning efforts.
IdentityDP: Differential Private Identification Protection for Face Images
Mar 02, 2021

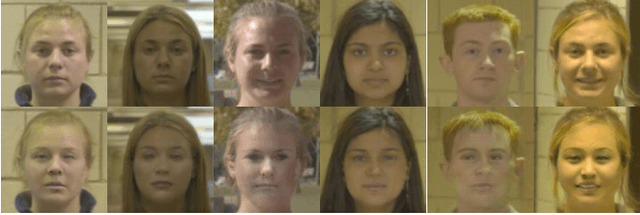

Because of the explosive growth of face photos as well as their widespread dissemination and easy accessibility in social media, the security and privacy of personal identity information becomes an unprecedented challenge. Meanwhile, the convenience brought by advanced identity-agnostic computer vision technologies is attractive. Therefore, it is important to use face images while taking careful consideration in protecting people's identities. Given a face image, face de-identification, also known as face anonymization, refers to generating another image with similar appearance and the same background, while the real identity is hidden. Although extensive efforts have been made, existing face de-identification techniques are either insufficient in photo-reality or incapable of well-balancing privacy and utility. In this paper, we focus on tackling these challenges to improve face de-identification. We propose IdentityDP, a face anonymization framework that combines a data-driven deep neural network with a differential privacy (DP) mechanism. This framework encompasses three stages: facial representations disentanglement, $\epsilon$-IdentityDP perturbation and image reconstruction. Our model can effectively obfuscate the identity-related information of faces, preserve significant visual similarity, and generate high-quality images that can be used for identity-agnostic computer vision tasks, such as detection, tracking, etc. Different from the previous methods, we can adjust the balance of privacy and utility through the privacy budget according to pratical demands and provide a diversity of results without pre-annotations. Extensive experiments demonstrate the effectiveness and generalization ability of our proposed anonymization framework.
Phase Transitions in Transfer Learning for High-Dimensional Perceptrons
Jan 06, 2021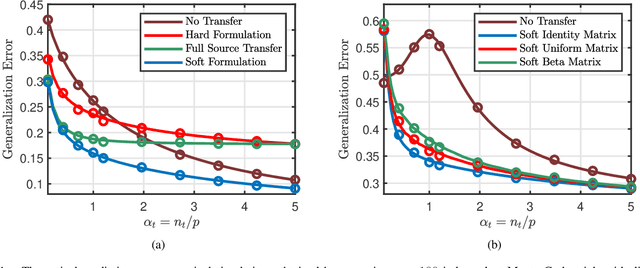
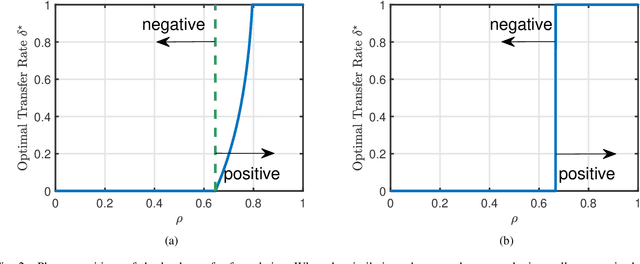
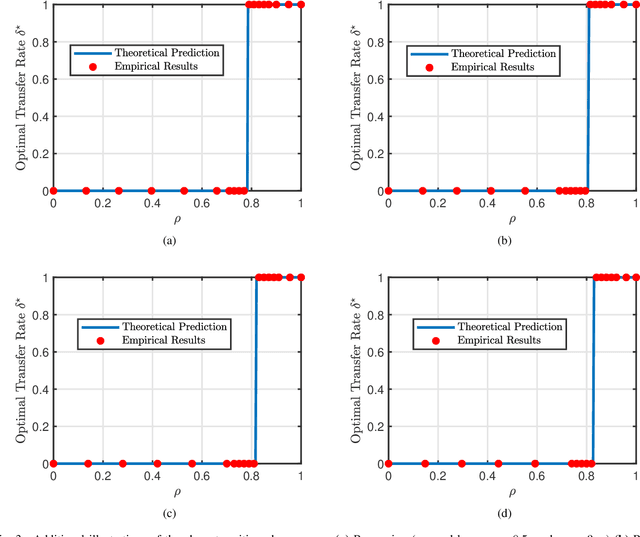

Transfer learning seeks to improve the generalization performance of a target task by exploiting the knowledge learned from a related source task. Central questions include deciding what information one should transfer and when transfer can be beneficial. The latter question is related to the so-called negative transfer phenomenon, where the transferred source information actually reduces the generalization performance of the target task. This happens when the two tasks are sufficiently dissimilar. In this paper, we present a theoretical analysis of transfer learning by studying a pair of related perceptron learning tasks. Despite the simplicity of our model, it reproduces several key phenomena observed in practice. Specifically, our asymptotic analysis reveals a phase transition from negative transfer to positive transfer as the similarity of the two tasks moves past a well-defined threshold.
Robust and Transferable Anomaly Detection in Log Data using Pre-Trained Language Models
Feb 23, 2021
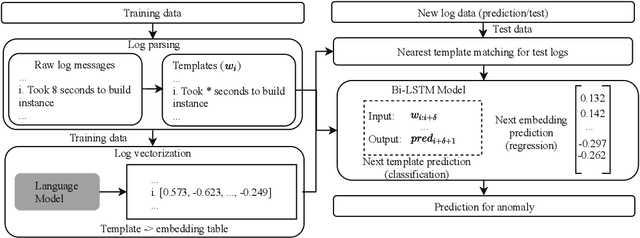
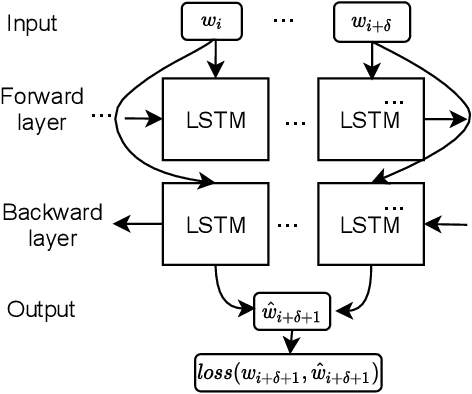

Anomalies or failures in large computer systems, such as the cloud, have an impact on a large number of users that communicate, compute, and store information. Therefore, timely and accurate anomaly detection is necessary for reliability, security, safe operation, and mitigation of losses in these increasingly important systems. Recently, the evolution of the software industry opens up several problems that need to be tackled including (1) addressing the software evolution due software upgrades, and (2) solving the cold-start problem, where data from the system of interest is not available. In this paper, we propose a framework for anomaly detection in log data, as a major troubleshooting source of system information. To that end, we utilize pre-trained general-purpose language models to preserve the semantics of log messages and map them into log vector embeddings. The key idea is that these representations for the logs are robust and less invariant to changes in the logs, and therefore, result in a better generalization of the anomaly detection models. We perform several experiments on a cloud dataset evaluating different language models for obtaining numerical log representations such as BERT, GPT-2, and XL. The robustness is evaluated by gradually altering log messages, to simulate a change in semantics. Our results show that the proposed approach achieves high performance and robustness, which opens up possibilities for future research in this direction.
MPN: Multimodal Parallel Network for Audio-Visual Event Localization
Apr 07, 2021
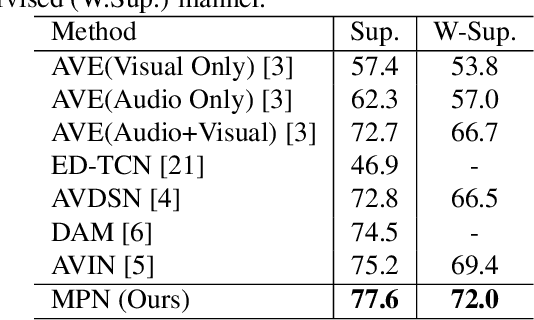
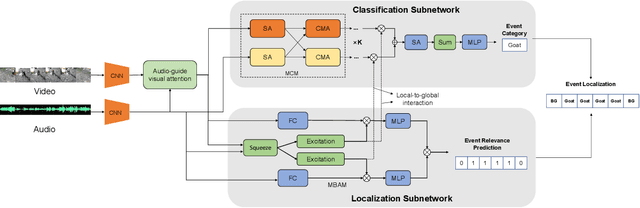

Audio-visual event localization aims to localize an event that is both audible and visible in the wild, which is a widespread audio-visual scene analysis task for unconstrained videos. To address this task, we propose a Multimodal Parallel Network (MPN), which can perceive global semantics and unmixed local information parallelly. Specifically, our MPN framework consists of a classification subnetwork to predict event categories and a localization subnetwork to predict event boundaries. The classification subnetwork is constructed by the Multimodal Co-attention Module (MCM) and obtains global contexts. The localization subnetwork consists of Multimodal Bottleneck Attention Module (MBAM), which is designed to extract fine-grained segment-level contents. Extensive experiments demonstrate that our framework achieves the state-of-the-art performance both in fully supervised and weakly supervised settings on the Audio-Visual Event (AVE) dataset.
Information Projection and Approximate Inference for Structured Sparse Variables
Jul 12, 2016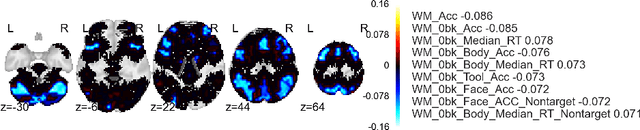
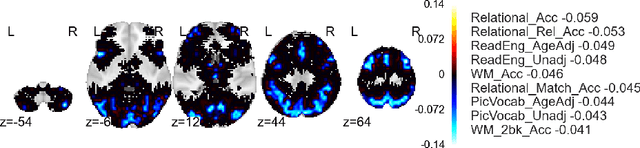
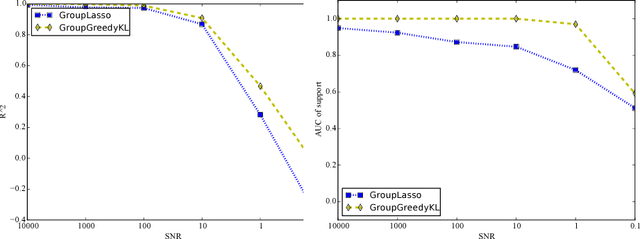
Approximate inference via information projection has been recently introduced as a general-purpose approach for efficient probabilistic inference given sparse variables. This manuscript goes beyond classical sparsity by proposing efficient algorithms for approximate inference via information projection that are applicable to any structure on the set of variables that admits enumeration using a \emph{matroid}. We show that the resulting information projection can be reduced to combinatorial submodular optimization subject to matroid constraints. Further, leveraging recent advances in submodular optimization, we provide an efficient greedy algorithm with strong optimization-theoretic guarantees. The class of probabilistic models that can be expressed in this way is quite broad and, as we show, includes group sparse regression, group sparse principal components analysis and sparse canonical correlation analysis, among others. Moreover, empirical results on simulated data and high dimensional neuroimaging data highlight the superior performance of the information projection approach as compared to established baselines for a range of probabilistic models.
3D/2D regularized CNN feature hierarchy for Hyperspectral image classification
Apr 25, 2021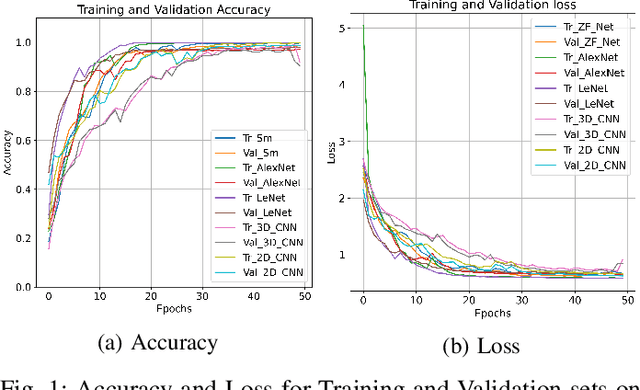
Convolutional Neural Networks (CNN) have been rigorously studied for Hyperspectral Image Classification (HSIC) and are known to be effective in exploiting joint spatial-spectral information with the expense of lower generalization performance and learning speed due to the hard labels and non-uniform distribution over labels. Several regularization techniques have been used to overcome the aforesaid issues. However, sometimes models learn to predict the samples extremely confidently which is not good from a generalization point of view. Therefore, this paper proposed an idea to enhance the generalization performance of a hybrid CNN for HSIC using soft labels that are a weighted average of the hard labels and uniform distribution over ground labels. The proposed method helps to prevent CNN from becoming over-confident. We empirically show that in improving generalization performance, label smoothing also improves model calibration which significantly improves beam-search. Several publicly available Hyperspectral datasets are used to validate the experimental evaluation which reveals improved generalization performance, statistical significance, and computational complexity as compared to the state-of-the-art models. The code will be made available at https://github.com/mahmad00.
Robotic Inspection and 3D GPR-based Reconstruction for Underground Utilities
Jun 03, 2021

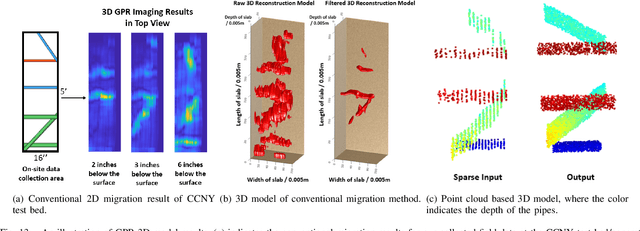
Ground Penetrating Radar (GPR) is an effective non-destructive evaluation (NDE) device for inspecting and surveying subsurface objects (i.e., rebars, utility pipes) in complex environments. However, the current practice for GPR data collection requires a human inspector to move a GPR cart along pre-marked grid lines and record the GPR data in both X and Y directions for post-processing by 3D GPR imaging software. It is time-consuming and tedious work to survey a large area. Furthermore, identifying the subsurface targets depends on the knowledge of an experienced engineer, who has to make manual and subjective interpretation that limits the GPR applications, especially in large-scale scenarios. In addition, the current GPR imaging technology is not intuitive, and not for normal users to understand, and not friendly to visualize. To address the above challenges, this paper presents a novel robotic system to collect GPR data, interpret GPR data, localize the underground utilities, reconstruct and visualize the underground objects' dense point cloud model in a user-friendly manner. This system is composed of three modules: 1) a vision-aided Omni-directional robotic data collection platform, which enables the GPR antenna to scan the target area freely with an arbitrary trajectory while using a visual-inertial-based positioning module tags the GPR measurements with positioning information; 2) a deep neural network (DNN) migration module to interpret the raw GPR B-scan image into a cross-section of object model; 3) a DNN-based 3D reconstruction method, i.e., GPRNet, to generate underground utility model represented as fine 3D point cloud. Comparative studies on synthetic and field GPR raw data with various incompleteness and noise are performed.
SCTN: Sparse Convolution-Transformer Network for Scene Flow Estimation
May 10, 2021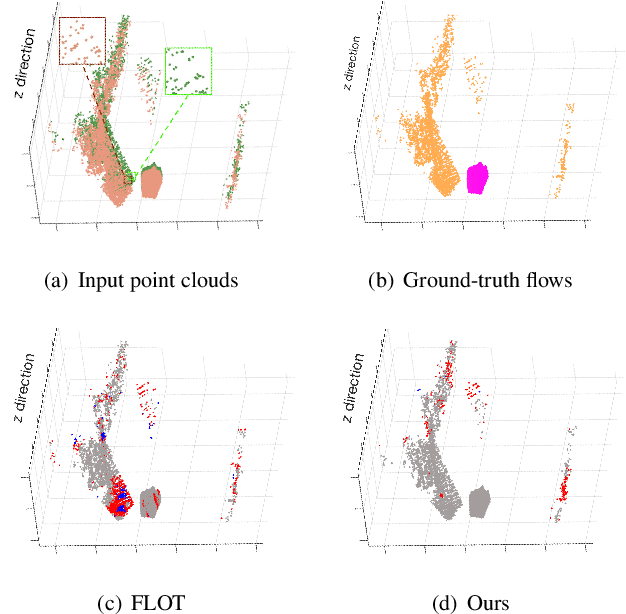
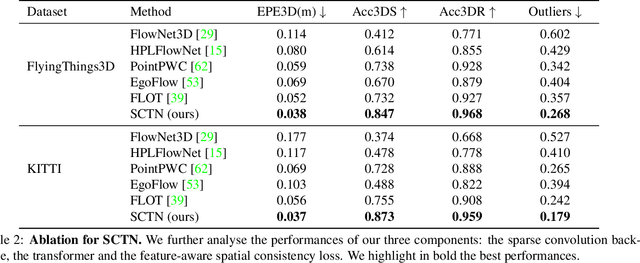
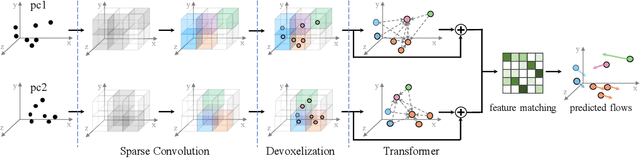
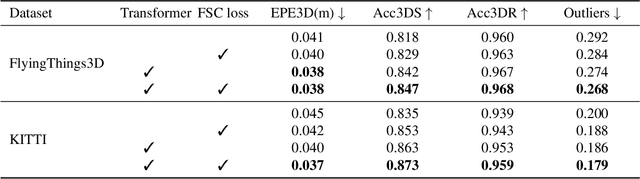
We propose a novel scene flow estimation approach to capture and infer 3D motions from point clouds. Estimating 3D motions for point clouds is challenging, since a point cloud is unordered and its density is significantly non-uniform. Such unstructured data poses difficulties in matching corresponding points between point clouds, leading to inaccurate flow estimation. We propose a novel architecture named Sparse Convolution-Transformer Network (SCTN) that equips the sparse convolution with the transformer. Specifically, by leveraging the sparse convolution, SCTN transfers irregular point cloud into locally consistent flow features for estimating continuous and consistent motions within an object/local object part. We further propose to explicitly learn point relations using a point transformer module, different from exiting methods. We show that the learned relation-based contextual information is rich and helpful for matching corresponding points, benefiting scene flow estimation. In addition, a novel loss function is proposed to adaptively encourage flow consistency according to feature similarity. Extensive experiments demonstrate that our proposed approach achieves a new state of the art in scene flow estimation. Our approach achieves an error of 0.038 and 0.037 (EPE3D) on FlyingThings3D and KITTI Scene Flow respectively, which significantly outperforms previous methods by large margins.