 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
One-shot Compositional Data Generation for Low Resource Handwritten Text Recognition
May 11, 2021

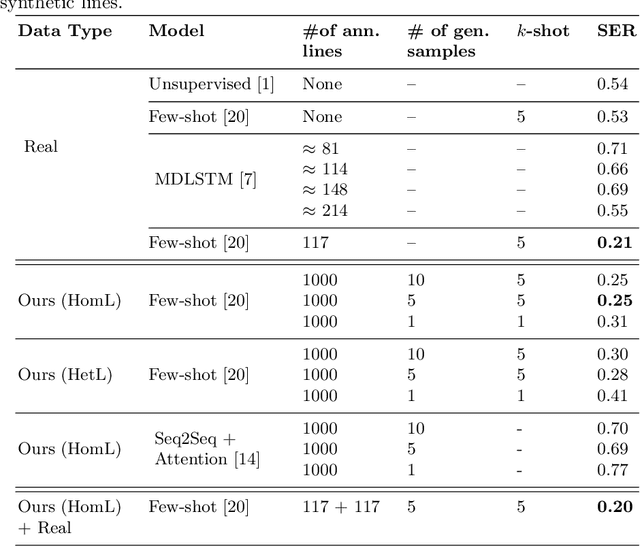
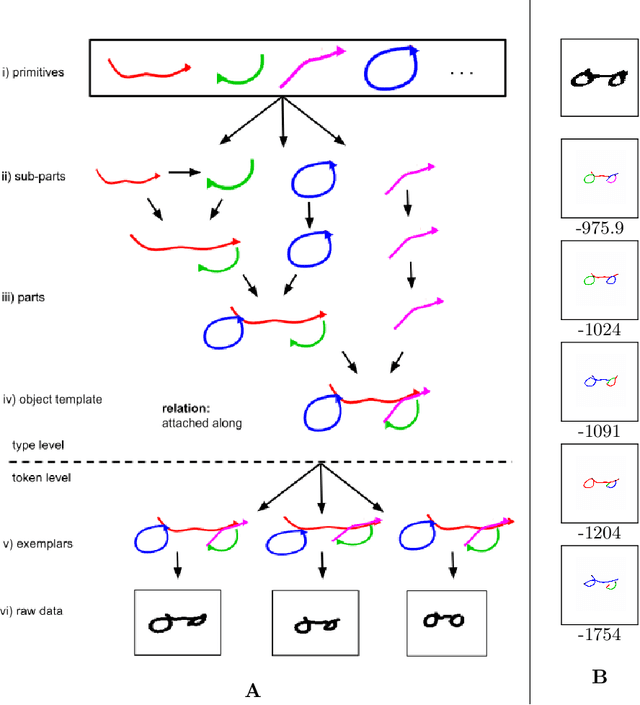

Low resource Handwritten Text Recognition (HTR) is a hard problem due to the scarce annotated data and the very limited linguistic information (dictionaries and language models). This appears, for example, in the case of historical ciphered manuscripts, which are usually written with invented alphabets to hide the content. Thus, in this paper we address this problem through a data generation technique based on Bayesian Program Learning (BPL). Contrary to traditional generation approaches, which require a huge amount of annotated images, our method is able to generate human-like handwriting using only one sample of each symbol from the desired alphabet. After generating symbols, we create synthetic lines to train state-of-the-art HTR architectures in a segmentation free fashion. Quantitative and qualitative analyses were carried out and confirm the effectiveness of the proposed method, achieving competitive results compared to the usage of real annotated data.
Regression Networks For Calculating Englacial Layer Thickness
Apr 10, 2021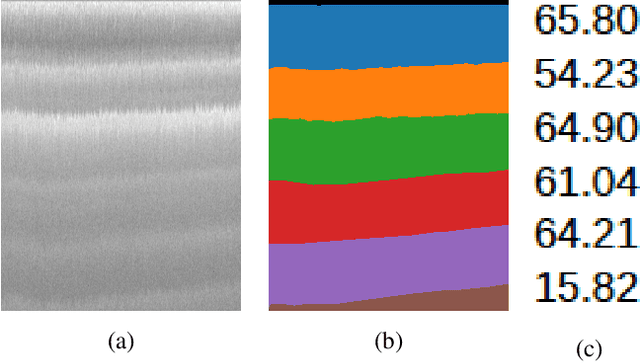
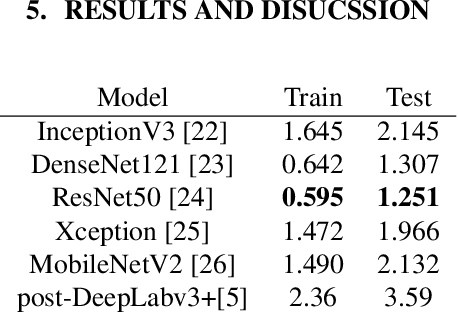
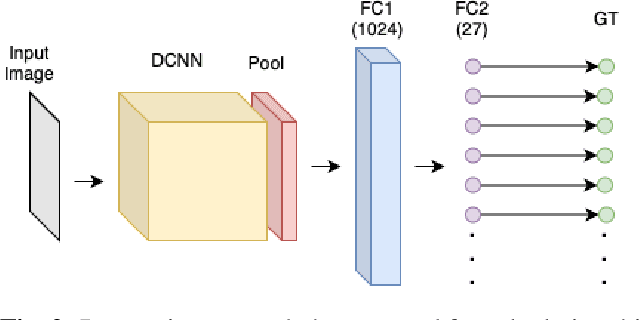
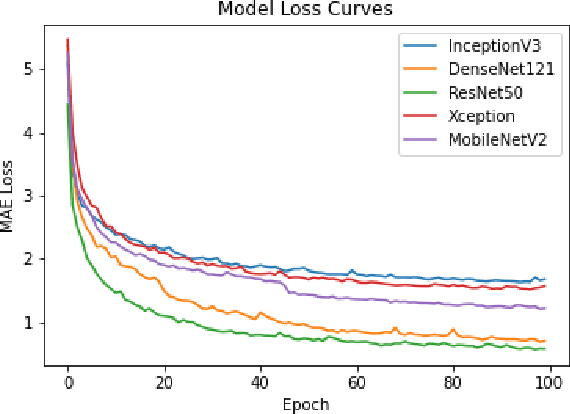
Ice thickness estimation is an important aspect of ice sheet studies. In this work, we use convolutional neural networks with multiple output nodes to regress and learn the thickness of internal ice layers in Snow Radar images collected in northwest Greenland. We experiment with some state-of-the-art networks and find that with the residual connections of ResNet50, we could achieve a mean absolute error of 1.251 pixels over the test set. Such regression-based networks can further be improved by embedding domain knowledge and radar information in the neural network in order to reduce the requirement of manual annotations.
ExSinGAN: Learning an Explainable Generative Model from a Single Image
May 16, 2021
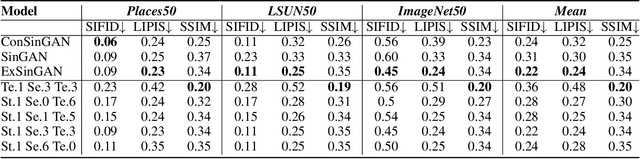
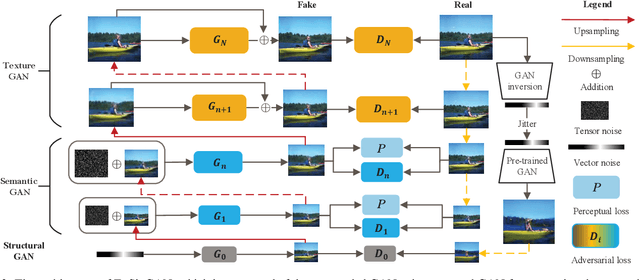
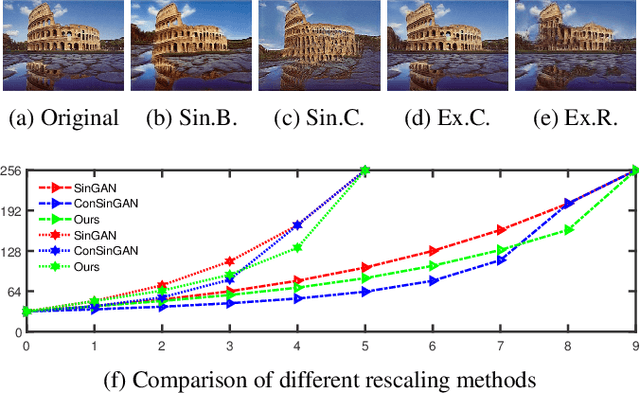
Generating images from a single sample, as a newly developing branch of image synthesis, has attracted extensive attention. In this paper, we formulate this problem as sampling from the conditional distribution of a single image, and propose a hierarchical framework that simplifies the learning of the intricate conditional distributions through the successive learning of the distributions about structure, semantics and texture, making the process of learning and generation comprehensible. On this basis, we design ExSinGAN composed of three cascaded GANs for learning an explainable generative model from a given image, where the cascaded GANs model the distributions about structure, semantics and texture successively. ExSinGAN is learned not only from the internal patches of the given image as the previous works did, but also from the external prior obtained by the GAN inversion technique. Benefiting from the appropriate combination of internal and external information, ExSinGAN has a more powerful capability of generation and competitive generalization ability for the image manipulation tasks compared with prior works.
Interactions in information spread: quantification and interpretation using stochastic block models
Apr 09, 2020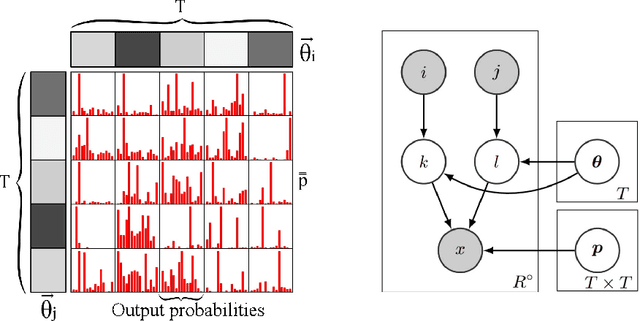
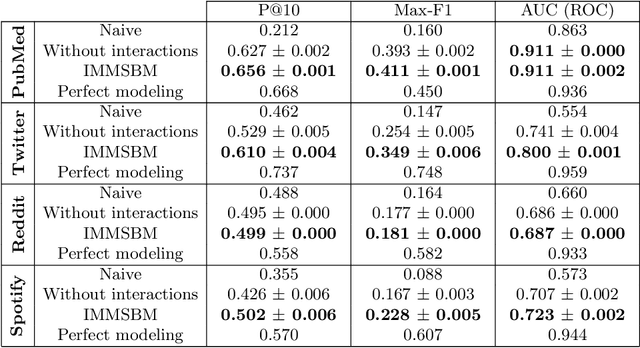
In most real-world applications, it is seldom the case that a given observable evolves independently of its environment. In social networks, users' behavior results from the people they interact with, news in their feed, or trending topics. In natural language, the meaning of phrases emerges from the combination of words. In general medicine, a diagnosis is established on the basis of the interaction of symptoms. Here, we propose a new model, the Interactive Mixed Membership Stochastic Block Model (IMMSBM), which investigates the role of interactions between entities (hashtags, words, memes, etc.) and quantifies their importance within the aforementioned corpora. We find that interactions play an important role in those corpora. In inference tasks, taking them into account leads to average relative changes with respect to non-interactive models of up to 150\% in the probability of an outcome. Furthermore, their role greatly improves the predictive power of the model. Our findings suggest that neglecting interactions when modeling real-world phenomena might lead to incorrect conclusions being drawn.
An Approach for Weakly-Supervised Deep Information Retrieval
Jul 24, 2017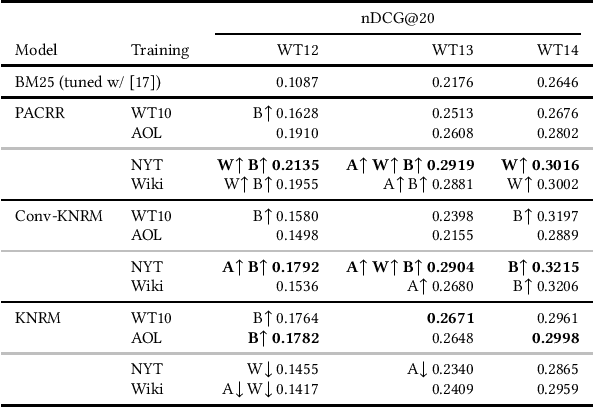
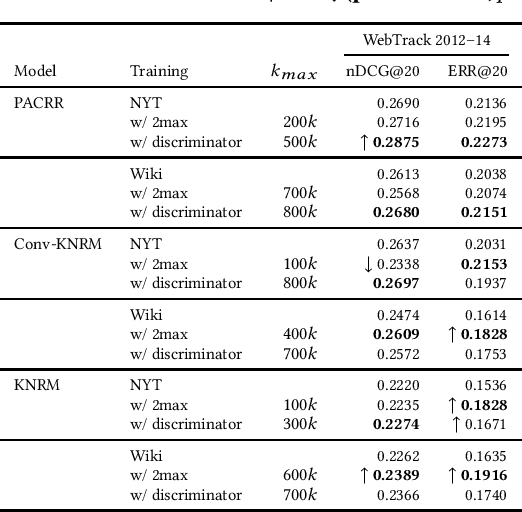
Recent developments in neural information retrieval models have been promising, but a problem remains: human relevance judgments are expensive to produce, while neural models require a considerable amount of training data. In an attempt to fill this gap, we present an approach that---given a weak training set of pseudo-queries, documents, relevance information---filters the data to produce effective positive and negative query-document pairs. This allows large corpora to be used as neural IR model training data, while eliminating training examples that do not transfer well to relevance scoring. The filters include unsupervised ranking heuristics and a novel measure of interaction similarity. We evaluate our approach using a news corpus with article headlines acting as pseudo-queries and article content as documents, with implicit relevance between an article's headline and its content. By using our approach to train state-of-the-art neural IR models and comparing to established baselines, we find that training data generated by our approach can lead to good results on a benchmark test collection.
Neighbourhood-guided Feature Reconstruction for Occluded Person Re-Identification
May 16, 2021
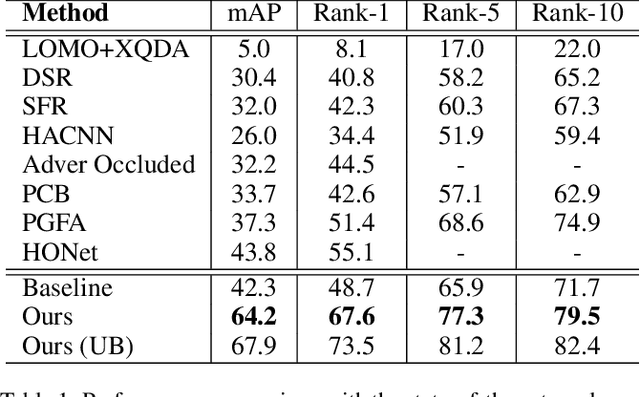
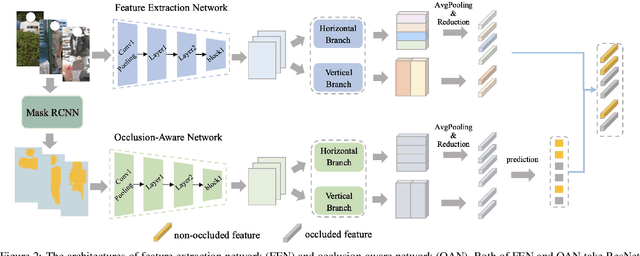
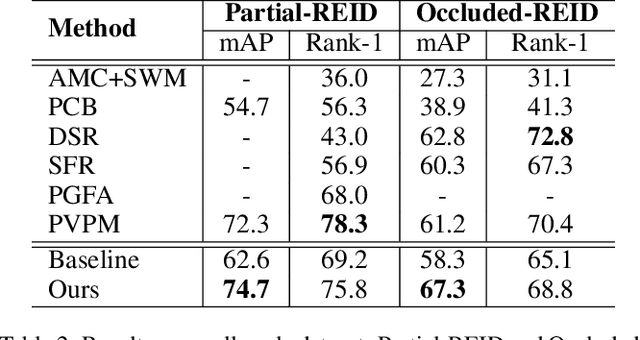
Person images captured by surveillance cameras are often occluded by various obstacles, which lead to defective feature representation and harm person re-identification (Re-ID) performance. To tackle this challenge, we propose to reconstruct the feature representation of occluded parts by fully exploiting the information of its neighborhood in a gallery image set. Specifically, we first introduce a visible part-based feature by body mask for each person image. Then we identify its neighboring samples using the visible features and reconstruct the representation of the full body by an outlier-removable graph neural network with all the neighboring samples as input. Extensive experiments show that the proposed approach obtains significant improvements. In the large-scale Occluded-DukeMTMC benchmark, our approach achieves 64.2% mAP and 67.6% rank-1 accuracy which outperforms the state-of-the-art approaches by large margins, i.e.,20.4% and 12.5%, respectively, indicating the effectiveness of our method on occluded Re-ID problem.
Rethinking of Radar's Role: A Camera-Radar Dataset and Systematic Annotator via Coordinate Alignment
May 11, 2021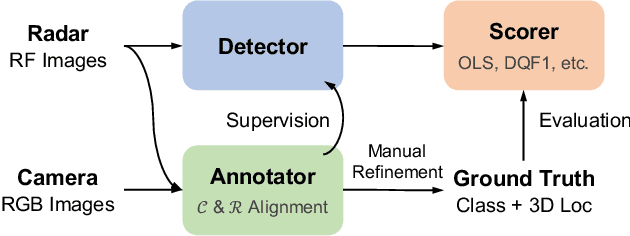
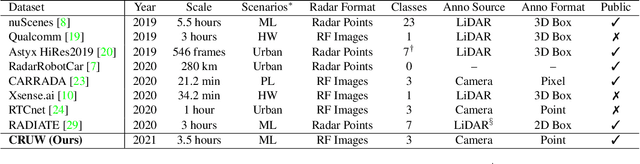
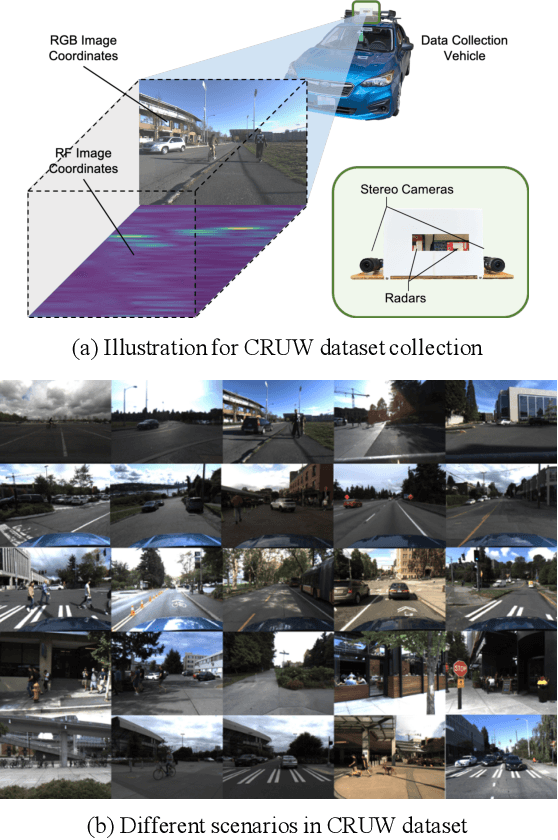
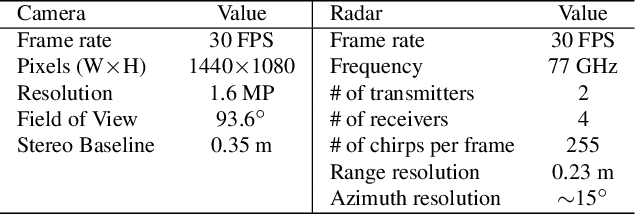
Radar has long been a common sensor on autonomous vehicles for obstacle ranging and speed estimation. However, as a robust sensor to all-weather conditions, radar's capability has not been well-exploited, compared with camera or LiDAR. Instead of just serving as a supplementary sensor, radar's rich information hidden in the radio frequencies can potentially provide useful clues to achieve more complicated tasks, like object classification and detection. In this paper, we propose a new dataset, named CRUW, with a systematic annotator and performance evaluation system to address the radar object detection (ROD) task, which aims to classify and localize the objects in 3D purely from radar's radio frequency (RF) images. To the best of our knowledge, CRUW is the first public large-scale dataset with a systematic annotation and evaluation system, which involves camera RGB images and radar RF images, collected in various driving scenarios.
Learning Granularity-Aware Convolutional Neural Network for Fine-Grained Visual Classification
Mar 04, 2021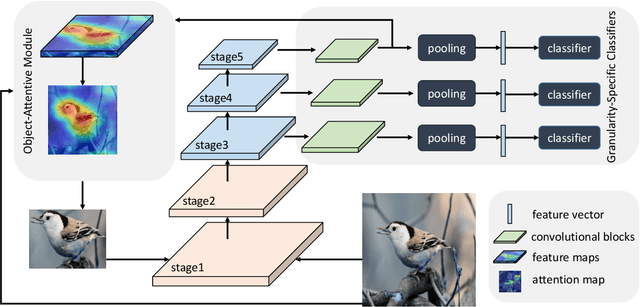
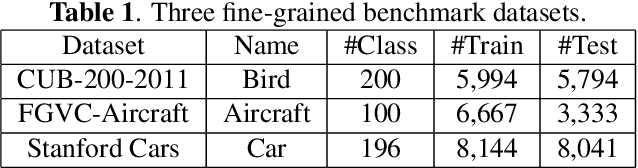

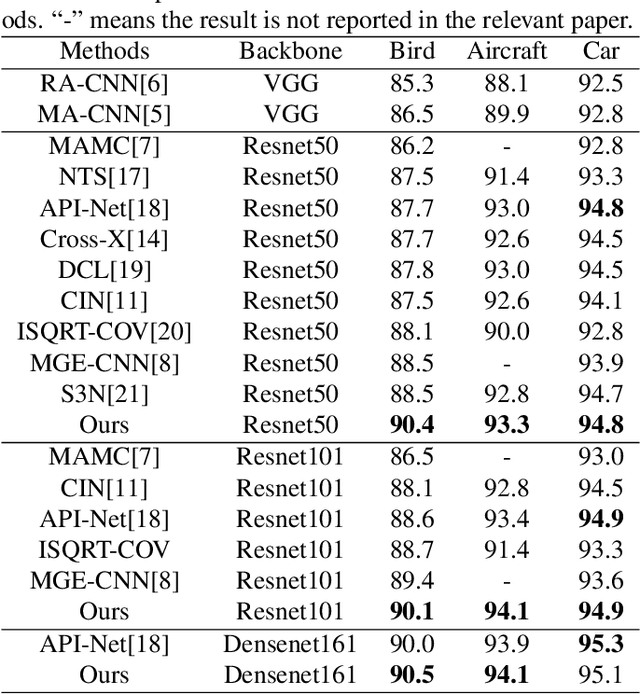
Locating discriminative parts plays a key role in fine-grained visual classification due to the high similarities between different objects. Recent works based on convolutional neural networks utilize the feature maps taken from the last convolutional layer to mine discriminative regions. However, the last convolutional layer tends to focus on the whole object due to the large receptive field, which leads to a reduced ability to spot the differences. To address this issue, we propose a novel Granularity-Aware Convolutional Neural Network (GA-CNN) that progressively explores discriminative features. Specifically, GA-CNN utilizes the differences of the receptive fields at different layers to learn multi-granularity features, and it exploits larger granularity information based on the smaller granularity information found at the previous stages. To further boost the performance, we introduce an object-attentive module that can effectively localize the object given a raw image. GA-CNN does not need bounding boxes/part annotations and can be trained end-to-end. Extensive experimental results show that our approach achieves state-of-the-art performances on three benchmark datasets.
Large-Scale Network Embedding in Apache Spark
Jun 20, 2021
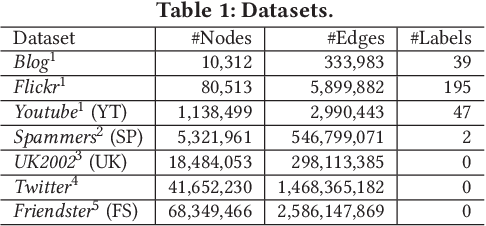
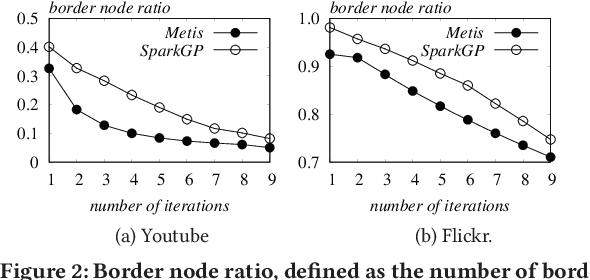
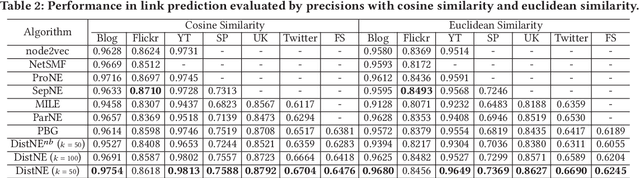
Network embedding has been widely used in social recommendation and network analysis, such as recommendation systems and anomaly detection with graphs. However, most of previous approaches cannot handle large graphs efficiently, due to that (i) computation on graphs is often costly and (ii) the size of graph or the intermediate results of vectors could be prohibitively large, rendering it difficult to be processed on a single machine. In this paper, we propose an efficient and effective distributed algorithm for network embedding on large graphs using Apache Spark, which recursively partitions a graph into several small-sized subgraphs to capture the internal and external structural information of nodes, and then computes the network embedding for each subgraph in parallel. Finally, by aggregating the outputs on all subgraphs, we obtain the embeddings of nodes in a linear cost. After that, we demonstrate in various experiments that our proposed approach is able to handle graphs with billions of edges within a few hours and is at least 4 times faster than the state-of-the-art approaches. Besides, it achieves up to $4.25\%$ and $4.27\%$ improvements on link prediction and node classification tasks respectively. In the end, we deploy the proposed algorithms in two online games of Tencent with the applications of friend recommendation and item recommendation, which improve the competitors by up to $91.11\%$ in running time and up to $12.80\%$ in the corresponding evaluation metrics.
Online Non-Additive Path Learning under Full and Partial Information
Sep 18, 2018
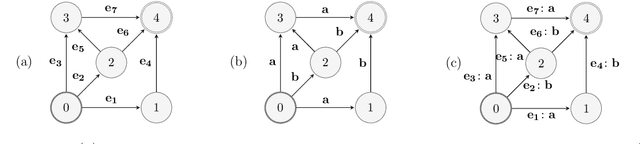
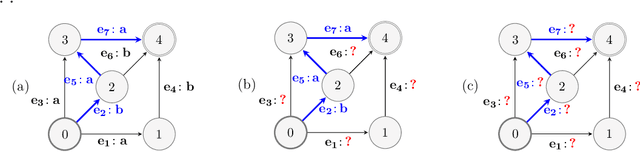

We study the problem of online path learning with non-additive gains, which is a central problem appearing in several applications, including ensemble structured prediction. We present new online algorithms for path learning with non-additive count-based gains for the three settings of full information, semi-bandit and full bandit. These algorithms admit very favorable regret guarantees and their guarantees can be viewed as the non-additive counterparts to the best known guarantees in the additive case. A key component of our algorithms is the definition and computation of an intermediate context-dependent automaton that enables us to use existing algorithms designed for additive gains. We further apply our methods to the important application of ensemble structured prediction. Finally, beyond count-based gains, we give an efficient implementation of the EXP3 algorithm for the full bandit setting with an arbitrary (non-additive) gain.