 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Granularity-Aware Convolutional Neural Network for Fine-Grained Visual Classification
Mar 04, 2021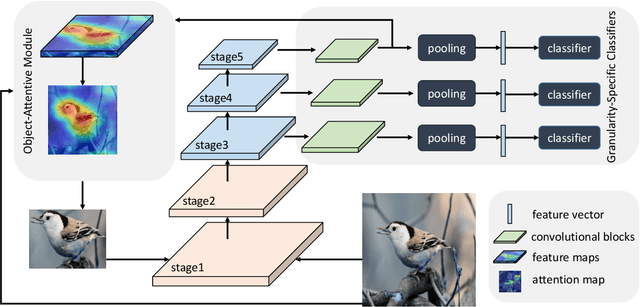

Locating discriminative parts plays a key role in fine-grained visual classification due to the high similarities between different objects. Recent works based on convolutional neural networks utilize the feature maps taken from the last convolutional layer to mine discriminative regions. However, the last convolutional layer tends to focus on the whole object due to the large receptive field, which leads to a reduced ability to spot the differences. To address this issue, we propose a novel Granularity-Aware Convolutional Neural Network (GA-CNN) that progressively explores discriminative features. Specifically, GA-CNN utilizes the differences of the receptive fields at different layers to learn multi-granularity features, and it exploits larger granularity information based on the smaller granularity information found at the previous stages. To further boost the performance, we introduce an object-attentive module that can effectively localize the object given a raw image. GA-CNN does not need bounding boxes/part annotations and can be trained end-to-end. Extensive experimental results show that our approach achieves state-of-the-art performances on three benchmark datasets.
Feature Boosting, Suppression, and Diversification for Fine-Grained Visual Classification
Mar 04, 2021
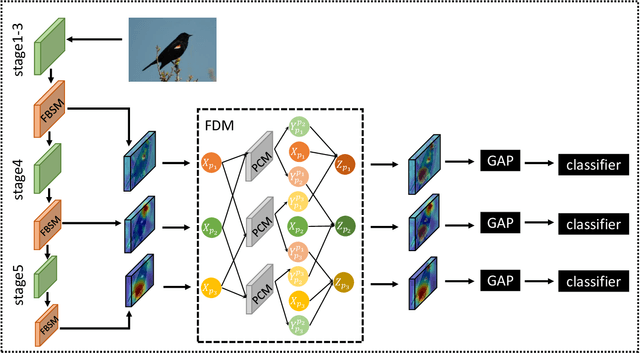
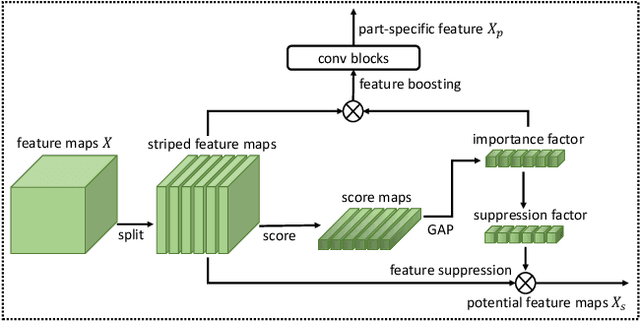
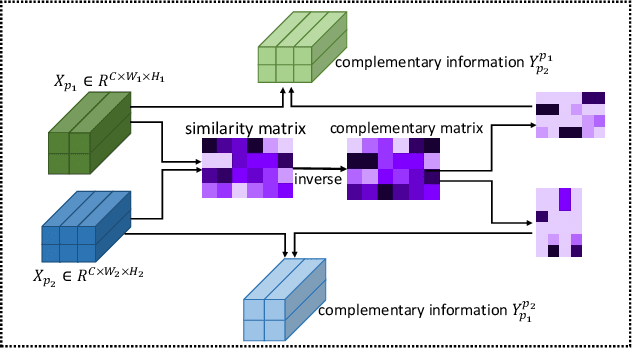
Learning feature representation from discriminative local regions plays a key role in fine-grained visual classification. Employing attention mechanisms to extract part features has become a trend. However, there are two major limitations in these methods: First, they often focus on the most salient part while neglecting other inconspicuous but distinguishable parts. Second, they treat different part features in isolation while neglecting their relationships. To handle these limitations, we propose to locate multiple different distinguishable parts and explore their relationships in an explicit way. In this pursuit, we introduce two lightweight modules that can be easily plugged into existing convolutional neural networks. On one hand, we introduce a feature boosting and suppression module that boosts the most salient part of feature maps to obtain a part-specific representation and suppresses it to force the following network to mine other potential parts. On the other hand, we introduce a feature diversification module that learns semantically complementary information from the correlated part-specific representations. Our method does not need bounding boxes/part annotations and can be trained end-to-end. Extensive experimental results show that our method achieves state-of-the-art performances on several benchmark fine-grained datasets.