 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Real Negatives Matter: Continuous Training with Real Negatives for Delayed Feedback Modeling
Apr 29, 2021
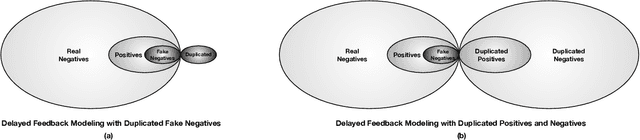

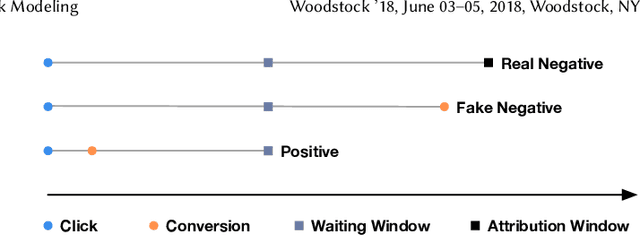
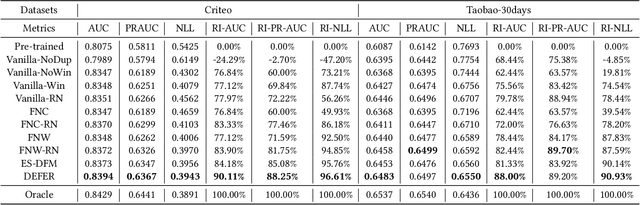
One of the difficulties of conversion rate (CVR) prediction is that the conversions can delay and take place long after the clicks. The delayed feedback poses a challenge: fresh data are beneficial to continuous training but may not have complete label information at the time they are ingested into the training pipeline. To balance model freshness and label certainty, previous methods set a short waiting window or even do not wait for the conversion signal. If conversion happens outside the waiting window, this sample will be duplicated and ingested into the training pipeline with a positive label. However, these methods have some issues. First, they assume the observed feature distribution remains the same as the actual distribution. But this assumption does not hold due to the ingestion of duplicated samples. Second, the certainty of the conversion action only comes from the positives. But the positives are scarce as conversions are sparse in commercial systems. These issues induce bias during the modeling of delayed feedback. In this paper, we propose DElayed FEedback modeling with Real negatives (DEFER) method to address these issues. The proposed method ingests real negative samples into the training pipeline. The ingestion of real negatives ensures the observed feature distribution is equivalent to the actual distribution, thus reducing the bias. The ingestion of real negatives also brings more certainty information of the conversion. To correct the distribution shift, DEFER employs importance sampling to weigh the loss function. Experimental results on industrial datasets validate the superiority of DEFER. DEFER have been deployed in the display advertising system of Alibaba, obtaining over 6.0% improvement on CVR in several scenarios. The code and data in this paper are now open-sourced {https://github.com/gusuperstar/defer.git}.
VA-GCN: A Vector Attention Graph Convolution Network for learning on Point Clouds
Jun 01, 2021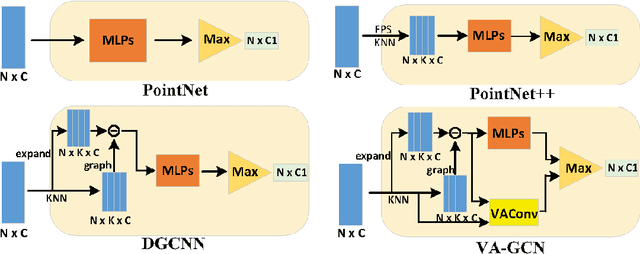
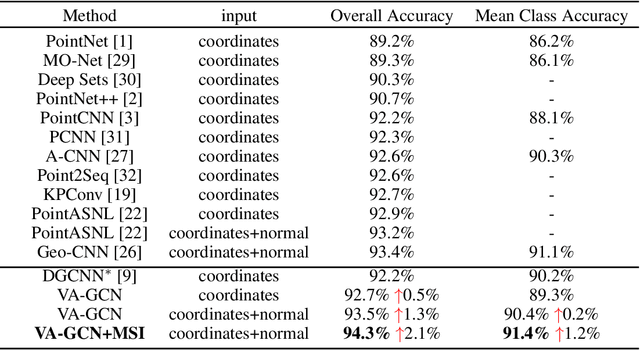
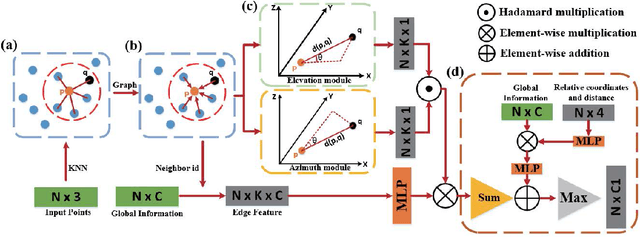
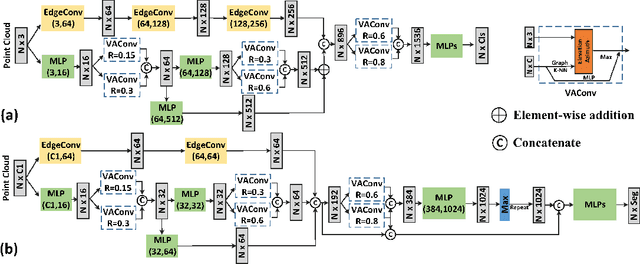
Owing to the development of research on local aggregation operators, dramatic breakthrough has been made in point cloud analysis models. However, existing local aggregation operators in the current literature fail to attach decent importance to the local information of the point cloud, which limits the power of the models. To fit this gap, we propose an efficient Vector Attention Convolution module (VAConv), which utilizes K-Nearest Neighbor (KNN) to extract the neighbor points of each input point, and then uses the elevation and azimuth relationship of the vectors between the center point and its neighbors to construct an attention weight matrix for edge features. Afterwards, the VAConv adopts a dual-channel structure to fuse weighted edge features and global features. To verify the efficiency of the VAConv, we connect the VAConvs with different receptive fields in parallel to obtain a Multi-scale graph convolutional network, VA-GCN. The proposed VA-GCN achieves state-of-the-art performance on standard benchmarks including ModelNet40, S3DIS and ShapeNet. Remarkably, on the ModelNet40 dataset for 3D classification, VA-GCN increased by 2.4% compared to the baseline.
Augmenting Molecular Deep Generative Models with Topological Data Analysis Representations
Jun 08, 2021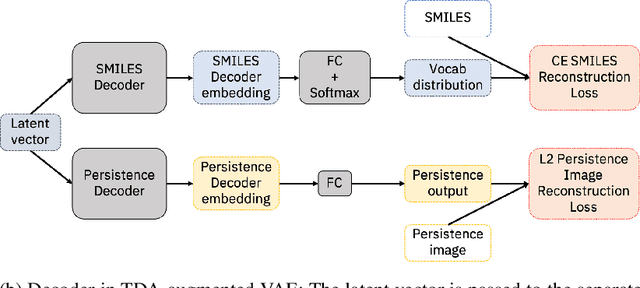


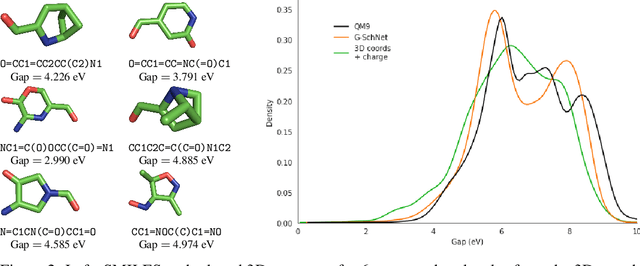
Deep generative models have emerged as a powerful tool for learning informative molecular representations and designing novel molecules with desired properties, with applications in drug discovery and material design. Deep generative auto-encoders defined over molecular SMILES strings have been a popular choice for that purpose. However, capturing salient molecular properties like quantum-chemical energies remains challenging and requires sophisticated neural net models of molecular graphs or geometry-based information. As a simpler and more efficient alternative, we present a SMILES Variational Auto-Encoder (VAE) augmented with topological data analysis (TDA) representations of molecules, known as persistence images. Our experiments show that this TDA augmentation enables a SMILES VAE to capture the complex relation between 3D geometry and electronic properties, and allows generation of novel, diverse, and valid molecules with geometric features consistent with the training data, which exhibit a varying range of global electronic structural properties, such as a small HOMO-LUMO gap - a critical property for designing organic solar cells. We demonstrate that our TDA augmentation yields better success in downstream tasks compared to models trained without these representations and can assist in targeted molecule discovery.
Learning Unknown from Correlations: Graph Neural Network for Inter-novel-protein Interaction Prediction
Jun 01, 2021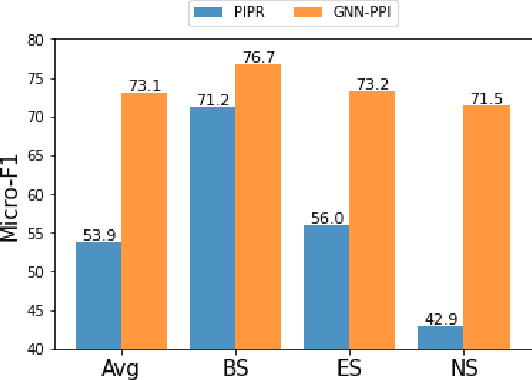
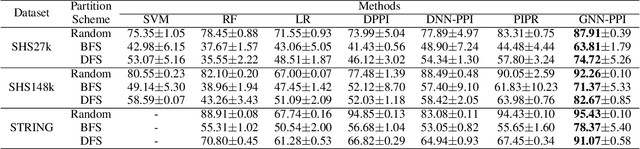
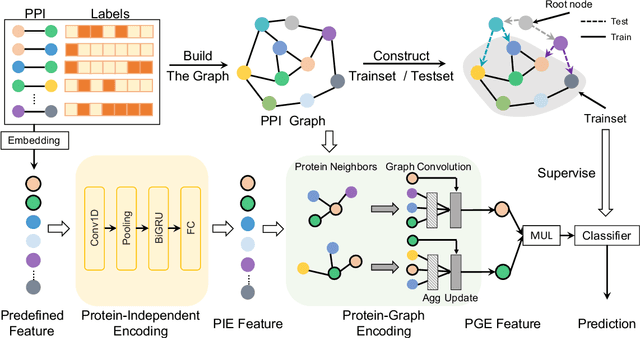
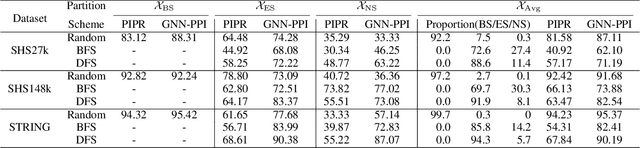
The study of multi-type Protein-Protein Interaction (PPI) is fundamental for understanding biological processes from a systematic perspective and revealing disease mechanisms. Existing methods suffer from significant performance degradation when tested in unseen dataset. In this paper, we investigate the problem and find that it is mainly attributed to the poor performance for inter-novel-protein interaction prediction. However, current evaluations overlook the inter-novel-protein interactions, and thus fail to give an instructive assessment. As a result, we propose to address the problem from both the evaluation and the methodology. Firstly, we design a new evaluation framework that fully respects the inter-novel-protein interactions and gives consistent assessment across datasets. Secondly, we argue that correlations between proteins must provide useful information for analysis of novel proteins, and based on this, we propose a graph neural network based method (GNN-PPI) for better inter-novel-protein interaction prediction. Experimental results on real-world datasets of different scales demonstrate that GNN-PPI significantly outperforms state-of-the-art PPI prediction methods, especially for the inter-novel-protein interaction prediction.
Lifting Transformer for 3D Human Pose Estimation in Video
Apr 04, 2021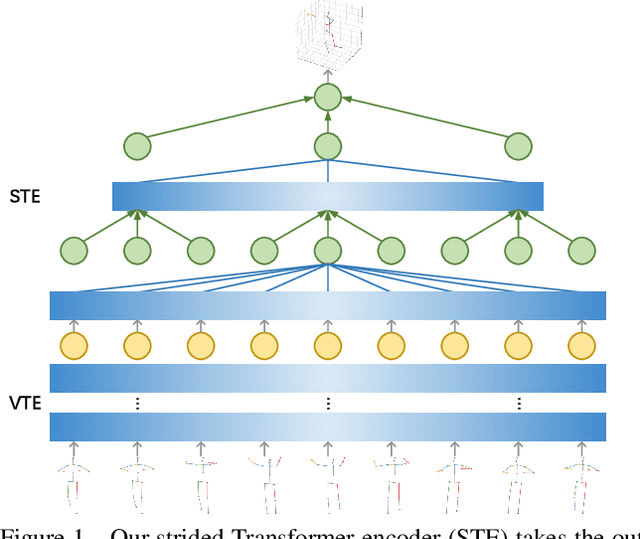
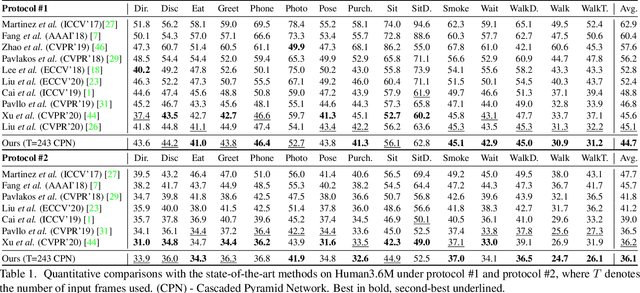
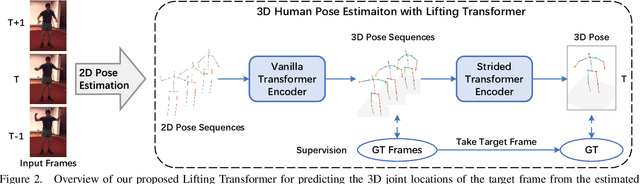
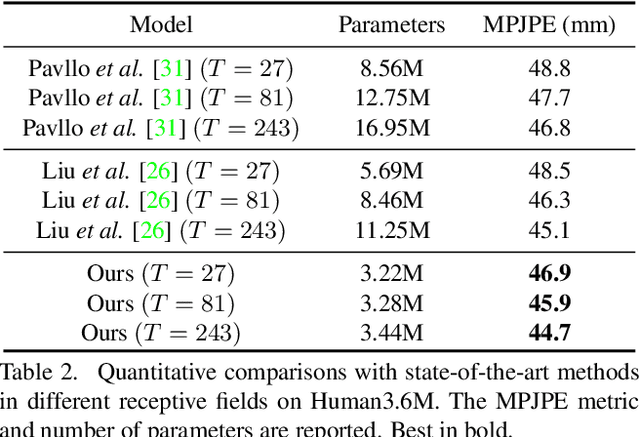
Despite great progress in video-based 3D human pose estimation, it is still challenging to learn a discriminative single-pose representation from redundant sequences. To this end, we propose a novel Transformer-based architecture, called Lifting Transformer, for 3D human pose estimation to lift a sequence of 2D joint locations to a 3D pose. Specifically, a vanilla Transformer encoder (VTE) is adopted to model long-range dependencies of 2D pose sequences. To reduce redundancy of the sequence and aggregate information from local context, fully-connected layers in the feed-forward network of VTE are replaced with strided convolutions to progressively reduce the sequence length. The modified VTE is termed as strided Transformer encoder (STE) and it is built upon the outputs of VTE. STE not only significantly reduces the computation cost but also effectively aggregates information to a single-vector representation in a global and local fashion. Moreover, a full-to-single supervision scheme is employed at both the full sequence scale and single target frame scale, applying to the outputs of VTE and STE, respectively. This scheme imposes extra temporal smoothness constraints in conjunction with the single target frame supervision. The proposed architecture is evaluated on two challenging benchmark datasets, namely, Human3.6M and HumanEva-I, and achieves state-of-the-art results with much fewer parameters.
Referring Segmentation in Images and Videos with Cross-Modal Self-Attention Network
Feb 09, 2021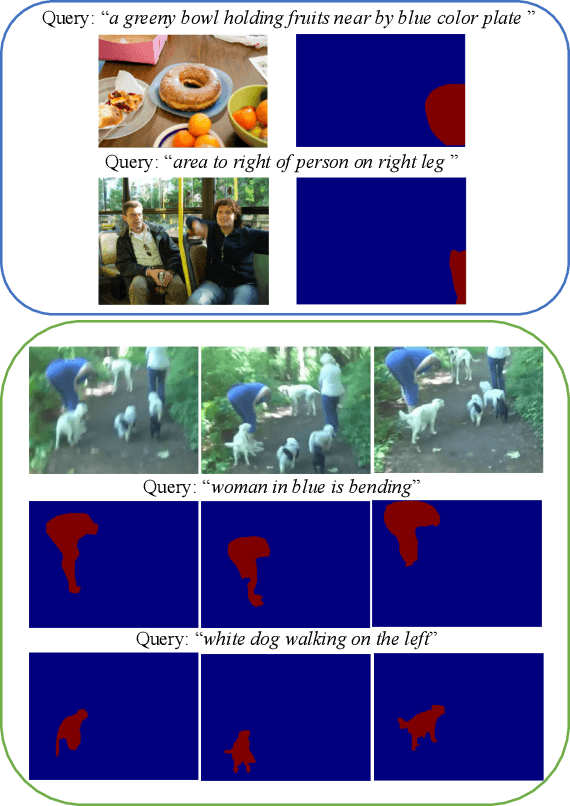

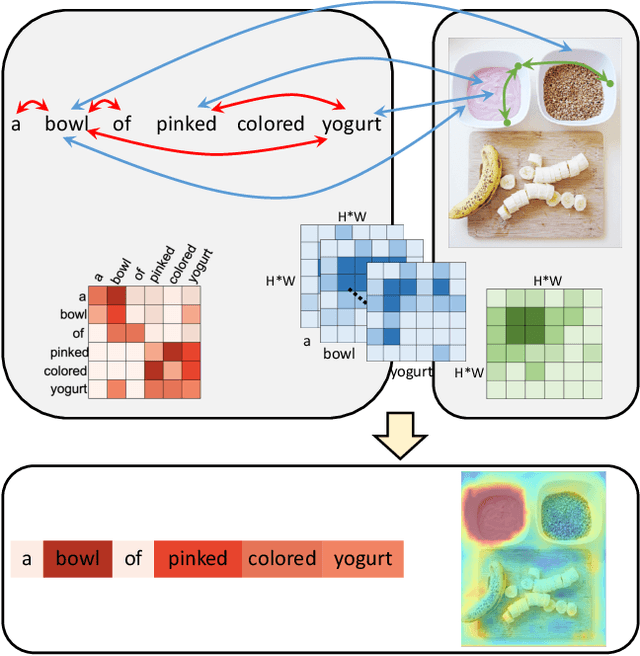
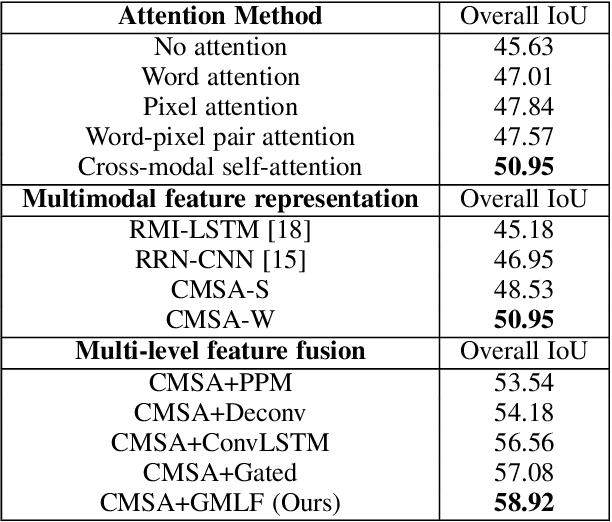
We consider the problem of referring segmentation in images and videos with natural language. Given an input image (or video) and a referring expression, the goal is to segment the entity referred by the expression in the image or video. In this paper, we propose a cross-modal self-attention (CMSA) module to utilize fine details of individual words and the input image or video, which effectively captures the long-range dependencies between linguistic and visual features. Our model can adaptively focus on informative words in the referring expression and important regions in the visual input. We further propose a gated multi-level fusion (GMLF) module to selectively integrate self-attentive cross-modal features corresponding to different levels of visual features. This module controls the feature fusion of information flow of features at different levels with high-level and low-level semantic information related to different attentive words. Besides, we introduce cross-frame self-attention (CFSA) module to effectively integrate temporal information in consecutive frames which extends our method in the case of referring segmentation in videos. Experiments on benchmark datasets of four referring image datasets and two actor and action video segmentation datasets consistently demonstrate that our proposed approach outperforms existing state-of-the-art methods.
Efficient training for future video generation based on hierarchical disentangled representation of latent variables
Jun 08, 2021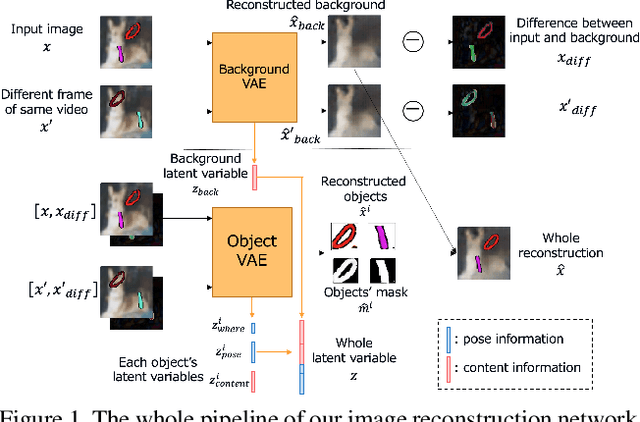
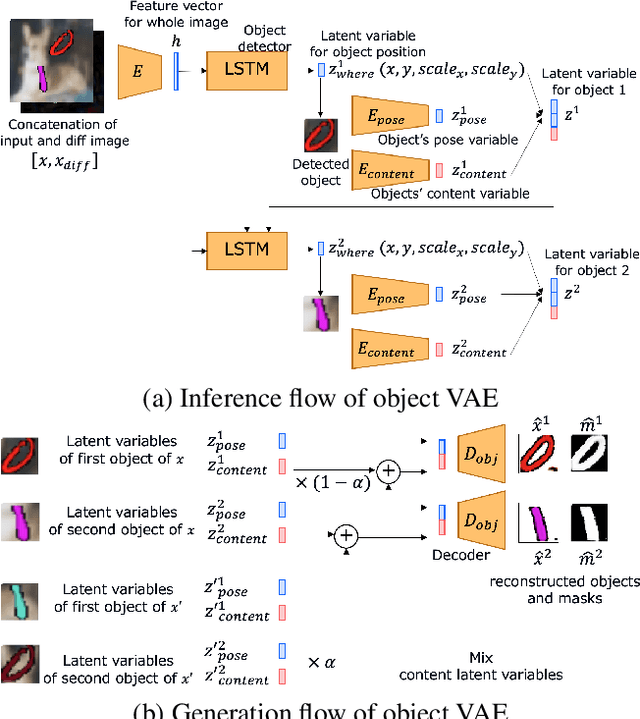


Generating videos predicting the future of a given sequence has been an area of active research in recent years. However, an essential problem remains unsolved: most of the methods require large computational cost and memory usage for training. In this paper, we propose a novel method for generating future prediction videos with less memory usage than the conventional methods. This is a critical stepping stone in the path towards generating videos with high image quality, similar to that of generated images in the latest works in the field of image generation. We achieve high-efficiency by training our method in two stages: (1) image reconstruction to encode video frames into latent variables, and (2) latent variable prediction to generate the future sequence. Our method achieves an efficient compression of video into low-dimensional latent variables by decomposing each frame according to its hierarchical structure. That is, we consider that video can be separated into background and foreground objects, and that each object holds time-varying and time-independent information independently. Our experiments show that the proposed method can efficiently generate future prediction videos, even for complex datasets that cannot be handled by previous methods.
News Meets Microblog: Hashtag Annotation via Retriever-Generator
Apr 18, 2021
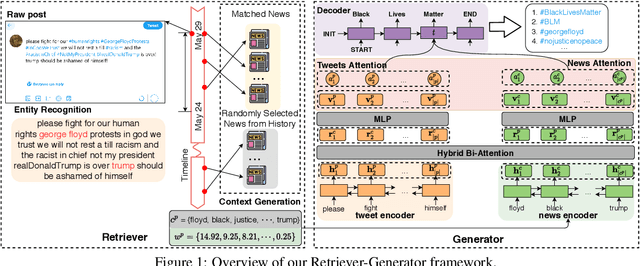
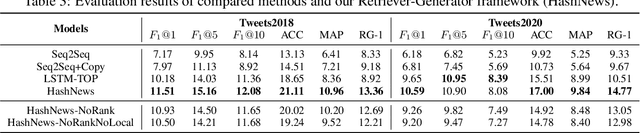
Hashtag annotation for microblog posts has been recently formulated as a sequence generation problem to handle emerging hashtags that are unseen in the training set. The state-of-the-art method leverages conversations initiated by posts to enrich contextual information for the short posts. However, it is unrealistic to assume the existence of conversations before the hashtag annotation itself. Therefore, we propose to leverage news articles published before the microblog post to generate hashtags following a Retriever-Generator framework. Extensive experiments on English Twitter datasets demonstrate superior performance and significant advantages of leveraging news articles to generate hashtags.
Reinforcement Learning for Resource Allocation in Steerable Laser-based Optical Wireless Systems
Jun 21, 2021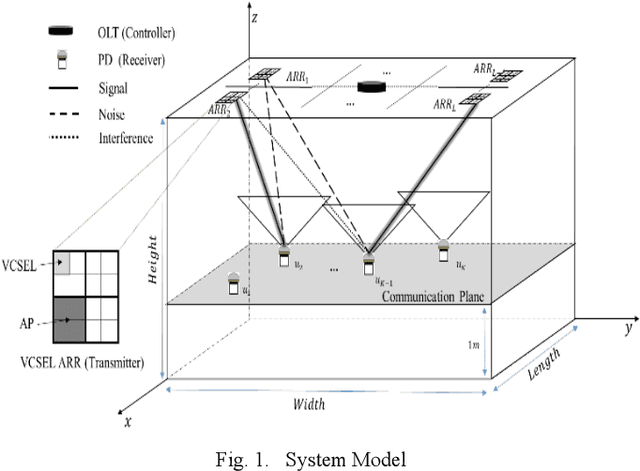
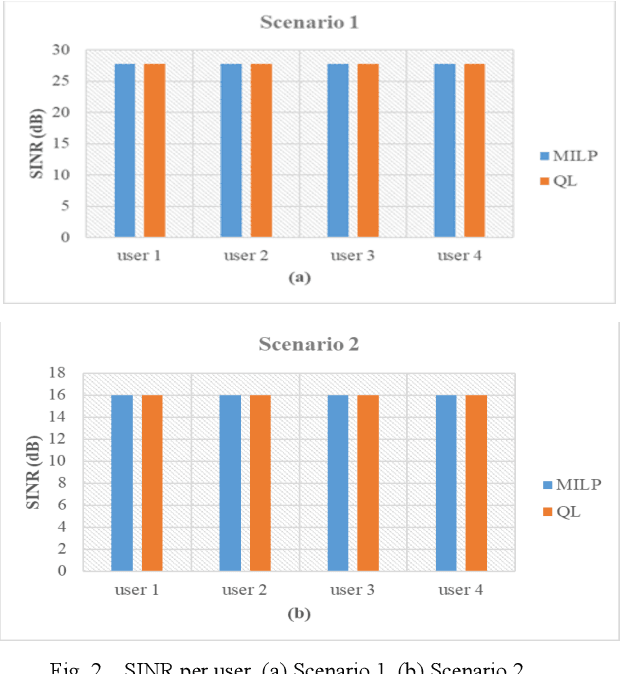
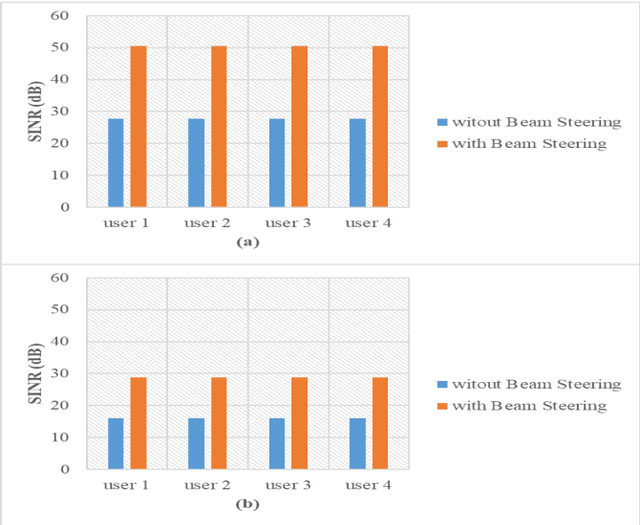
Vertical Cavity Surface Emitting Lasers (VCSELs) have demonstrated suitability for data transmission in indoor optical wireless communication (OWC) systems due to the high modulation bandwidth and low manufacturing cost of these sources. Specifically, resource allocation is one of the major challenges that can affect the performance of multi-user optical wireless systems. In this paper, an optimisation problem is formulated to optimally assign each user to an optical access point (AP) composed of multiple VCSELs within a VCSEL array at a certain time to maximise the signal to interference plus noise ratio (SINR). In this context, a mixed-integer linear programming (MILP) model is introduced to solve this optimisation problem. Despite the optimality of the MILP model, it is considered impractical due to its high complexity, high memory and full system information requirements. Therefore, reinforcement Learning (RL) is considered, which recently has been widely investigated as a practical solution for various optimization problems in cellular networks due to its ability to interact with environments with no previous experience. In particular, a Q-learning (QL) algorithm is investigated to perform resource management in a steerable VCSEL-based OWC systems. The results demonstrate the ability of the QL algorithm to achieve optimal solutions close to the MILP model. Moreover, the adoption of beam steering, using holograms implemented by exploiting liquid crystal devices, results in further enhancement in the performance of the network considered.
Adaptive Machine Unlearning
Jun 08, 2021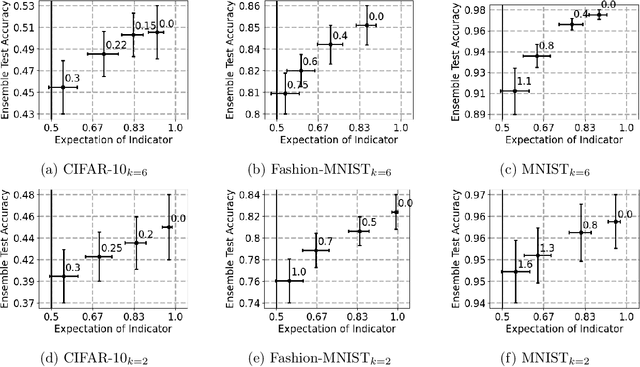
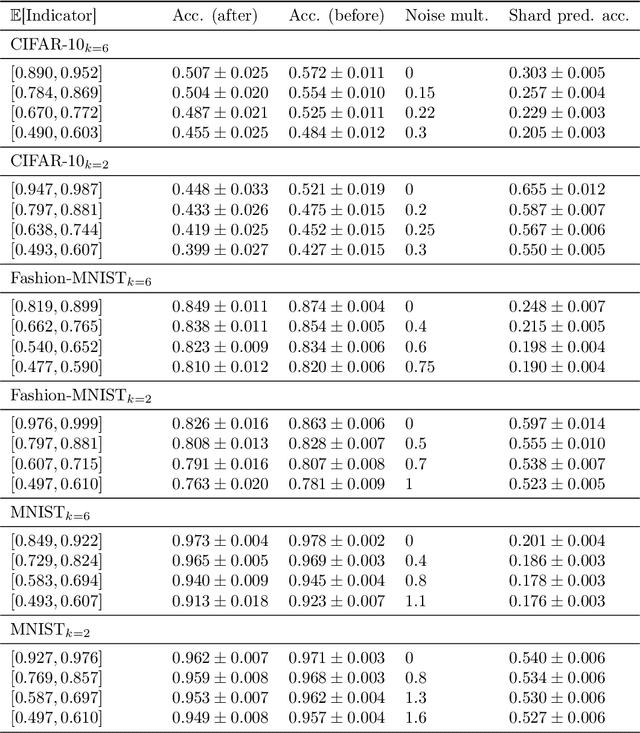
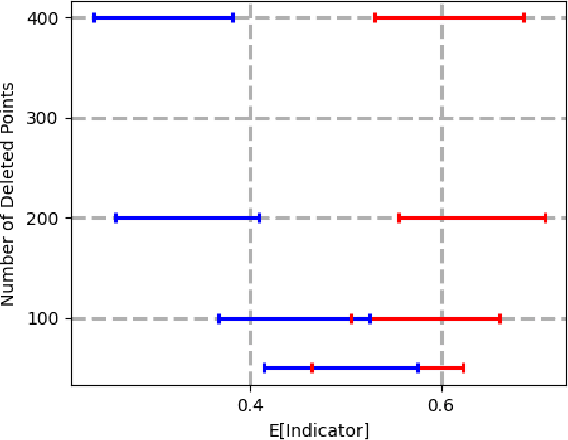
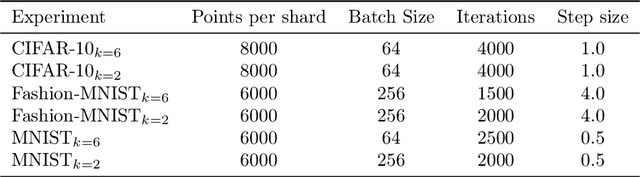
Data deletion algorithms aim to remove the influence of deleted data points from trained models at a cheaper computational cost than fully retraining those models. However, for sequences of deletions, most prior work in the non-convex setting gives valid guarantees only for sequences that are chosen independently of the models that are published. If people choose to delete their data as a function of the published models (because they don't like what the models reveal about them, for example), then the update sequence is adaptive. In this paper, we give a general reduction from deletion guarantees against adaptive sequences to deletion guarantees against non-adaptive sequences, using differential privacy and its connection to max information. Combined with ideas from prior work which give guarantees for non-adaptive deletion sequences, this leads to extremely flexible algorithms able to handle arbitrary model classes and training methodologies, giving strong provable deletion guarantees for adaptive deletion sequences. We show in theory how prior work for non-convex models fails against adaptive deletion sequences, and use this intuition to design a practical attack against the SISA algorithm of Bourtoule et al. [2021] on CIFAR-10, MNIST, Fashion-MNIST.