 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGigaSpeechBench: A Real-World Multilingual Speech-to-Text Benchmark
Jun 27, 2026While modern ASR systems achieve low error rates on high-resource benchmarks, such performance often overestimates real-world robustness. Existing evaluations address challenges in isolation, lacking a unified benchmark for domain terminology, age variation, dialects, accents, and low-resource languages, particularly across the Middle East and Southeast Asia, representing over one billion under-evaluated speakers. To address this gap, we introduce GigaSpeechBench, a comprehensive multilingual and multidimensional in-the-wild ASR & AST benchmark comprising 680 hours of human-annotated speech. It features five modules: (1) 12 low-resource Middle Eastern and Southeast Asian languages, plus challenging Japanese and Korean; (2) 6 Chinese dialects; (3) 6 English accents; (4) dense terminology across 12 vertical domains for Chinese and English; and (5) older adult and child speech. We further provide human-annotated Chinese and English translations for 11 languages to support AST evaluation. Extensive evaluations of leading foundation models and commercial APIs reveal significant performance degradation in these challenging settings, exposing critical evaluation blind spots.
Something from Nothing: Data Augmentation for Robust Severity Level Estimation of Dysarthric Speech
Mar 16, 2026Dysarthric speech quality assessment (DSQA) is critical for clinical diagnostics and inclusive speech technologies. However, subjective evaluation is costly and difficult to scale, and the scarcity of labeled data limits robust objective modeling. To address this, we propose a three-stage framework that leverages unlabeled dysarthric speech and large-scale typical speech datasets to scale training. A teacher model first generates pseudo-labels for unlabeled samples, followed by weakly supervised pretraining using a label-aware contrastive learning strategy that exposes the model to diverse speakers and acoustic conditions. The pretrained model is then fine-tuned for the downstream DSQA task. Experiments on five unseen datasets spanning multiple etiologies and languages demonstrate the robustness of our approach. Our Whisper-based baseline significantly outperforms SOTA DSQA predictors such as SpICE, and the full framework achieves an average SRCC of 0.761 across unseen test datasets.
MICRO: A Lightweight Middleware for Optimizing Cross-store Cross-model Graph-Relation Joins [Technical Report]
Mar 14, 2026Modern data applications increasingly involve heterogeneous data managed in different models and stored across disparate database engines, often deployed as separate installs. Limited research has addressed cross-model query processing in federated environments. This paper takes a step toward bridging this gap by: (1) formally defining a class of cross-model join queries between a graph store and a relational store by proposing a unified algebra; (2) introducing one real-world benchmark and four semi-synthetic benchmarks to evaluate such queries; and (3) proposing a lightweight middleware, MICRO, for efficient query execution. At the core of MICRO is CMLero, a learning-to-rank-based query optimizer that selects efficient execution plans without requiring exact cost estimation. By avoiding the need to materialize or convert all data into a single model, which is often infeasible due to third-party data control or cost, MICRO enables native querying across heterogeneous systems. Experimental results on the benchmark workloads demonstrate that MICRO outperforms the state-of-the-art federated relational system XDB by up to 2.1x in total runtime across the full test set. On the 93 test queries of real-world benchmark, 14 queries achieve over 100 speedup, including 4 queries with more than 100x speedup; however, 4 queries experienced slowdowns of over 5 seconds, highlighting opportunities for future improvement of MICRO. Further comparisons show that CMLero consistently outperforms rule-based and regression-based optimizers, highlighting the advantage of learning-to-rank in complex cross-model optimization.
Towards Robust Dysarthric Speech Recognition: LLM-Agent Post-ASR Correction Beyond WER
Jan 29, 2026While Automatic Speech Recognition (ASR) is typically benchmarked by word error rate (WER), real-world applications ultimately hinge on semantic fidelity. This mismatch is particularly problematic for dysarthric speech, where articulatory imprecision and disfluencies can cause severe semantic distortions. To bridge this gap, we introduce a Large Language Model (LLM)-based agent for post-ASR correction: a Judge-Editor over the top-k ASR hypotheses that keeps high-confidence spans, rewrites uncertain segments, and operates in both zero-shot and fine-tuned modes. In parallel, we release SAP-Hypo5, the largest benchmark for dysarthric speech correction, to enable reproducibility and future exploration. Under multi-perspective evaluation, our agent achieves a 14.51% WER reduction alongside substantial semantic gains, including a +7.59 pp improvement in MENLI and +7.66 pp in Slot Micro F1 on challenging samples. Our analysis further reveals that WER is highly sensitive to domain shift, whereas semantic metrics correlate more closely with downstream task performance.
AVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
The Interspeech 2025 Speech Accessibility Project Challenge
Jul 29, 2025While the last decade has witnessed significant advancements in Automatic Speech Recognition (ASR) systems, performance of these systems for individuals with speech disabilities remains inadequate, partly due to limited public training data. To bridge this gap, the 2025 Interspeech Speech Accessibility Project (SAP) Challenge was launched, utilizing over 400 hours of SAP data collected and transcribed from more than 500 individuals with diverse speech disabilities. Hosted on EvalAI and leveraging the remote evaluation pipeline, the SAP Challenge evaluates submissions based on Word Error Rate and Semantic Score. Consequently, 12 out of 22 valid teams outperformed the whisper-large-v2 baseline in terms of WER, while 17 teams surpassed the baseline on SemScore. Notably, the top team achieved the lowest WER of 8.11\%, and the highest SemScore of 88.44\% at the same time, setting new benchmarks for future ASR systems in recognizing impaired speech.
Fine-Tuning Automatic Speech Recognition for People with Parkinson's: An Effective Strategy for Enhancing Speech Technology Accessibility
Sep 29, 2024



This paper enhances dysarthric and dysphonic speech recognition by fine-tuning pretrained automatic speech recognition (ASR) models on the 2023-10-05 data package of the Speech Accessibility Project (SAP), which contains the speech of 253 people with Parkinson's disease. Experiments tested methods that have been effective for Cerebral Palsy, including the use of speaker clustering and severity-dependent models, weighted fine-tuning, and multi-task learning. Best results were obtained using a multi-task learning model, in which the ASR is trained to produce an estimate of the speaker's impairment severity as an auxiliary output. The resulting word error rates are considerably improved relative to a baseline model fine-tuned using only Librispeech data, with word error rate improvements of 37.62\% and 26.97\% compared to fine-tuning on 100h and 960h of LibriSpeech data, respectively.
News Meets Microblog: Hashtag Annotation via Retriever-Generator
Apr 18, 2021
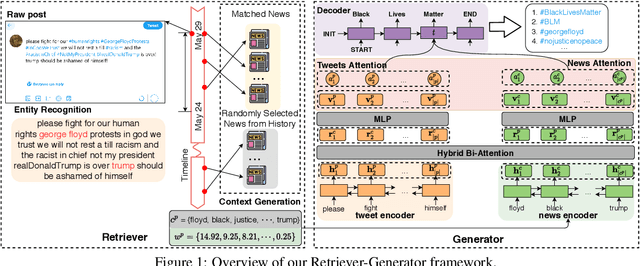
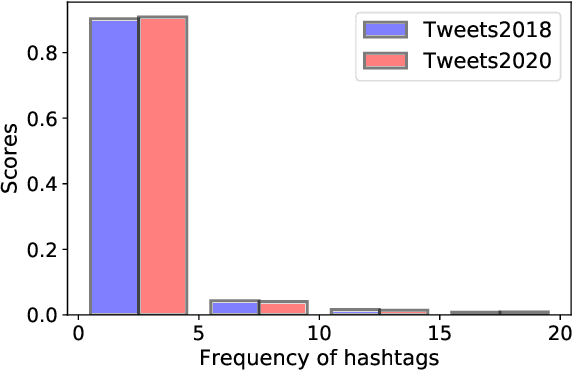
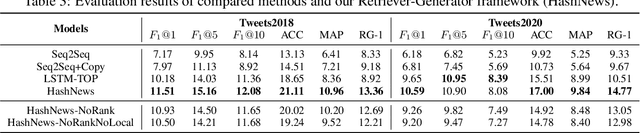
Hashtag annotation for microblog posts has been recently formulated as a sequence generation problem to handle emerging hashtags that are unseen in the training set. The state-of-the-art method leverages conversations initiated by posts to enrich contextual information for the short posts. However, it is unrealistic to assume the existence of conversations before the hashtag annotation itself. Therefore, we propose to leverage news articles published before the microblog post to generate hashtags following a Retriever-Generator framework. Extensive experiments on English Twitter datasets demonstrate superior performance and significant advantages of leveraging news articles to generate hashtags.