 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Answer Generation for Retrieval-based Question Answering Systems
Jun 02, 2021

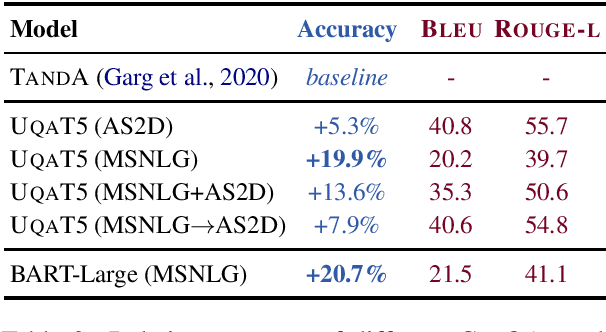
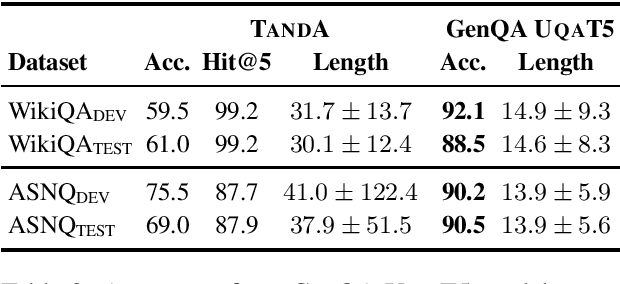
Recent advancements in transformer-based models have greatly improved the ability of Question Answering (QA) systems to provide correct answers; in particular, answer sentence selection (AS2) models, core components of retrieval-based systems, have achieved impressive results. While generally effective, these models fail to provide a satisfying answer when all retrieved candidates are of poor quality, even if they contain correct information. In AS2, models are trained to select the best answer sentence among a set of candidates retrieved for a given question. In this work, we propose to generate answers from a set of AS2 top candidates. Rather than selecting the best candidate, we train a sequence to sequence transformer model to generate an answer from a candidate set. Our tests on three English AS2 datasets show improvement up to 32 absolute points in accuracy over the state of the art.
A modular framework for object-based saccadic decisions in dynamic scenes
Jun 10, 2021
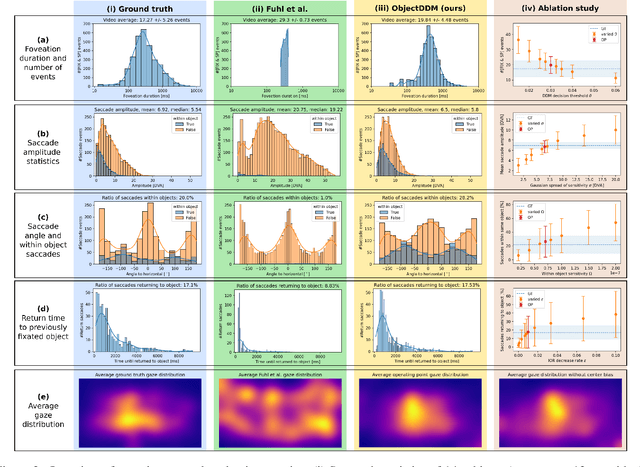
Visually exploring the world around us is not a passive process. Instead, we actively explore the world and acquire visual information over time. Here, we present a new model for simulating human eye-movement behavior in dynamic real-world scenes. We model this active scene exploration as a sequential decision making process. We adapt the popular drift-diffusion model (DDM) for perceptual decision making and extend it towards multiple options, defined by objects present in the scene. For each possible choice, the model integrates evidence over time and a decision (saccadic eye movement) is triggered as soon as evidence crosses a decision threshold. Drawing this explicit connection between decision making and object-based scene perception is highly relevant in the context of active viewing, where decisions are made continuously while interacting with an external environment. We validate our model with a carefully designed ablation study and explore influences of our model parameters. A comparison on the VidCom dataset supports the plausibility of the proposed approach.
Multi-Object Tracking with Interacting Vehicles and Road Map Information
Dec 20, 2018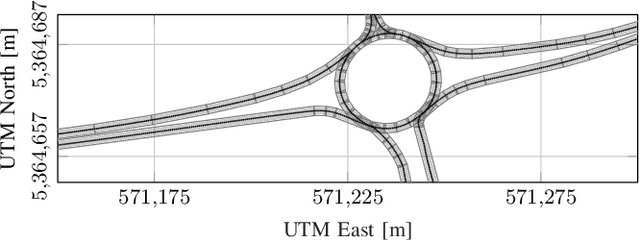
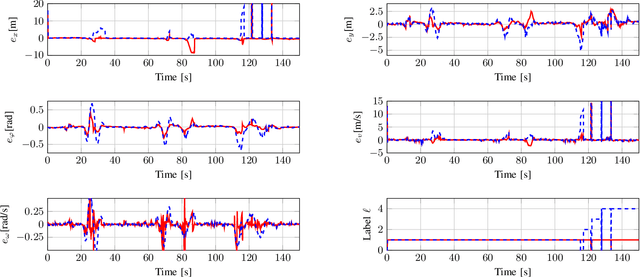

In many applications, tracking of multiple objects is crucial for a perception of the current environment. Most of the present multi-object tracking algorithms assume that objects move independently regarding other dynamic objects as well as the static environment. Since in many traffic situations objects interact with each other and in addition there are restrictions due to drivable areas, the assumption of an independent object motion is not fulfilled. This paper proposes an approach adapting a multi-object tracking system to model interaction between vehicles, and the current road geometry. Therefore, the prediction step of a Labeled Multi-Bernoulli filter is extended to facilitate modeling interaction between objects using the Intelligent Driver Model. Furthermore, to consider road map information, an approximation of a highly precise road map is used. The results show that in scenarios where the assumption of a standard motion model is violated, the tracking system adapted with the proposed method achieves higher accuracy and robustness in its track estimations.
Unsupervised Neural Rendering for Image Hazing
Jul 14, 2021


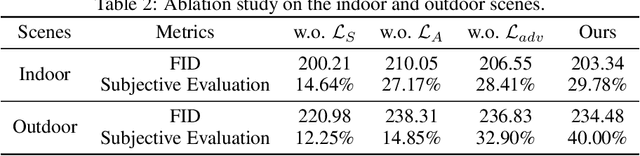
Image hazing aims to render a hazy image from a given clean one, which could be applied to a variety of practical applications such as gaming, filming, photographic filtering, and image dehazing. To generate plausible haze, we study two less-touched but challenging problems in hazy image rendering, namely, i) how to estimate the transmission map from a single image without auxiliary information, and ii) how to adaptively learn the airlight from exemplars, i.e., unpaired real hazy images. To this end, we propose a neural rendering method for image hazing, dubbed as HazeGEN. To be specific, HazeGEN is a knowledge-driven neural network which estimates the transmission map by leveraging a new prior, i.e., there exists the structure similarity (e.g., contour and luminance) between the transmission map and the input clean image. To adaptively learn the airlight, we build a neural module based on another new prior, i.e., the rendered hazy image and the exemplar are similar in the airlight distribution. To the best of our knowledge, this could be the first attempt to deeply rendering hazy images in an unsupervised fashion. Comparing with existing haze generation methods, HazeGEN renders the hazy images in an unsupervised, learnable, and controllable manner, thus avoiding the labor-intensive efforts in paired data collection and the domain-shift issue in haze generation. Extensive experiments show the promising performance of our method comparing with some baselines in both qualitative and quantitative comparisons. The code will be released on GitHub after acceptance.
From syntactic structure to semantic relationship: hypernym extraction from definitions by recurrent neural networks using the part of speech information
Dec 07, 2020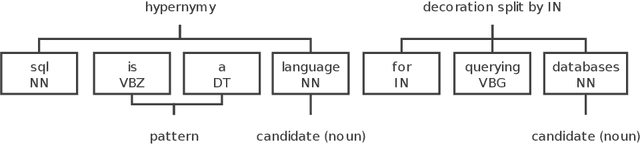

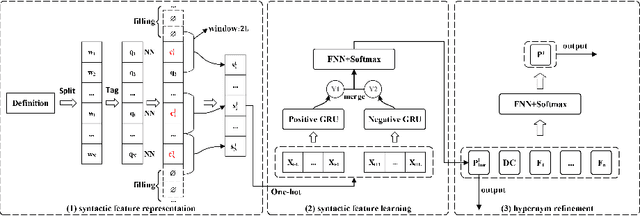

The hyponym-hypernym relation is an essential element in the semantic network. Identifying the hypernym from a definition is an important task in natural language processing and semantic analysis. While a public dictionary such as WordNet works for common words, its application in domain-specific scenarios is limited. Existing tools for hypernym extraction either rely on specific semantic patterns or focus on the word representation, which all demonstrate certain limitations.
Streaming Belief Propagation for Community Detection
Jun 10, 2021

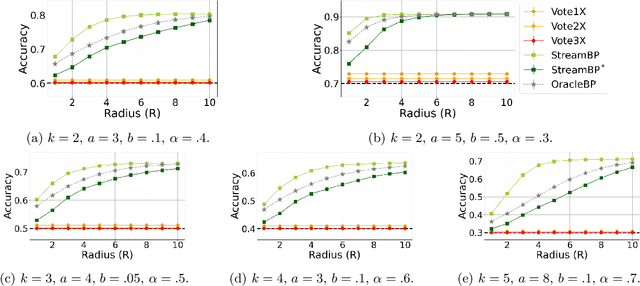
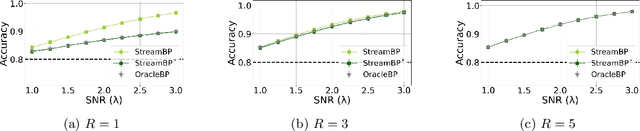
The community detection problem requires to cluster the nodes of a network into a small number of well-connected "communities". There has been substantial recent progress in characterizing the fundamental statistical limits of community detection under simple stochastic block models. However, in real-world applications, the network structure is typically dynamic, with nodes that join over time. In this setting, we would like a detection algorithm to perform only a limited number of updates at each node arrival. While standard voting approaches satisfy this constraint, it is unclear whether they exploit the network information optimally. We introduce a simple model for networks growing over time which we refer to as streaming stochastic block model (StSBM). Within this model, we prove that voting algorithms have fundamental limitations. We also develop a streaming belief-propagation (StreamBP) approach, for which we prove optimality in certain regimes. We validate our theoretical findings on synthetic and real data.
BRepNet: A topological message passing system for solid models
Apr 01, 2021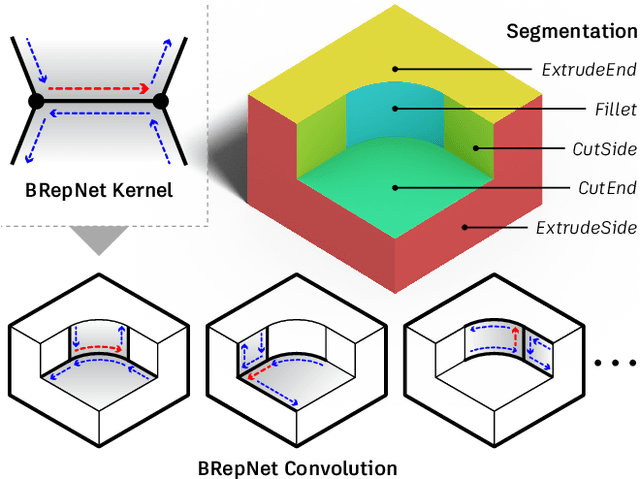


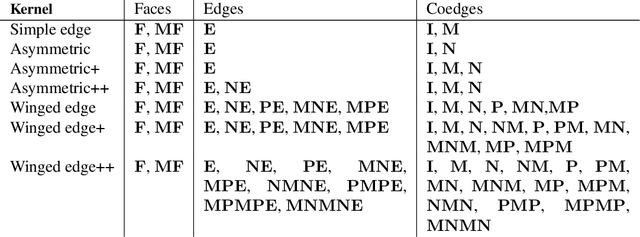
Boundary representation (B-rep) models are the standard way 3D shapes are described in Computer-Aided Design (CAD) applications. They combine lightweight parametric curves and surfaces with topological information which connects the geometric entities to describe manifolds. In this paper we introduce BRepNet, a neural network architecture designed to operate directly on B-rep data structures, avoiding the need to approximate the model as meshes or point clouds. BRepNet defines convolutional kernels with respect to oriented coedges in the data structure. In the neighborhood of each coedge, a small collection of faces, edges and coedges can be identified and patterns in the feature vectors from these entities detected by specific learnable parameters. In addition, to encourage further deep learning research with B-reps, we publish the Fusion 360 Gallery segmentation dataset. A collection of over 35,000 B-rep models annotated with information about the modeling operations which created each face. We demonstrate that BRepNet can segment these models with higher accuracy than methods working on meshes, and point clouds.
Dynamics-Regulated Kinematic Policy for Egocentric Pose Estimation
Jun 10, 2021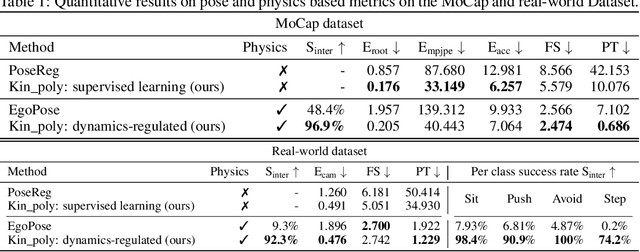
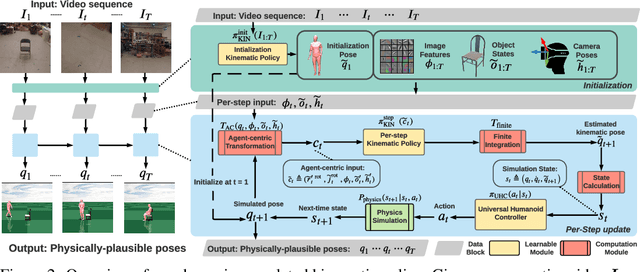
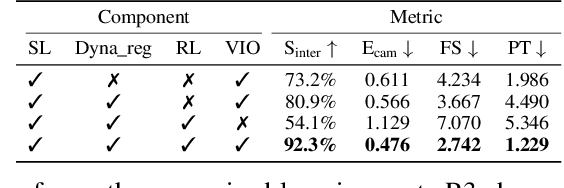
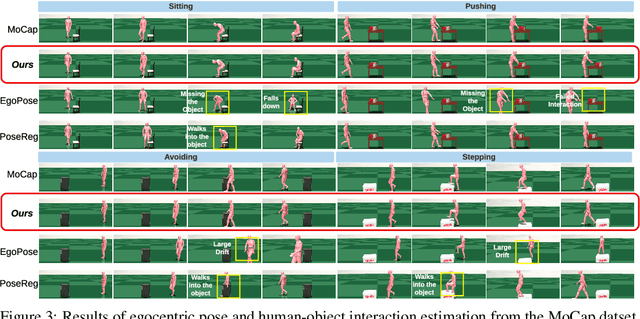
We propose a method for object-aware 3D egocentric pose estimation that tightly integrates kinematics modeling, dynamics modeling, and scene object information. Unlike prior kinematics or dynamics-based approaches where the two components are used disjointly, we synergize the two approaches via dynamics-regulated training. At each timestep, a kinematic model is used to provide a target pose using video evidence and simulation state. Then, a prelearned dynamics model attempts to mimic the kinematic pose in a physics simulator. By comparing the pose instructed by the kinematic model against the pose generated by the dynamics model, we can use their misalignment to further improve the kinematic model. By factoring in the 6DoF pose of objects (e.g., chairs, boxes) in the scene, we demonstrate for the first time, the ability to estimate physically-plausible 3D human-object interactions using a single wearable camera. We evaluate our egocentric pose estimation method in both controlled laboratory settings and real-world scenarios.
Attention-based Neural Beamforming Layers for Multi-channel Speech Recognition
May 12, 2021

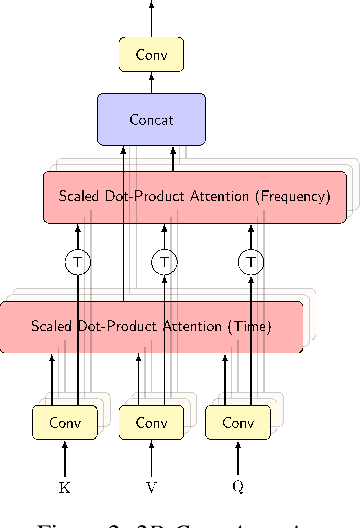

Attention-based beamformers have recently been shown to be effective for multi-channel speech recognition. However, they are less capable at capturing local information. In this work, we propose a 2D Conv-Attention module which combines convolution neural networks with attention for beamforming. We apply self- and cross-attention to explicitly model the correlations within and between the input channels. The end-to-end 2D Conv-Attention model is compared with a multi-head self-attention and superdirective-based neural beamformers. We train and evaluate on an in-house multi-channel dataset. The results show a relative improvement of 3.8% in WER by the proposed model over the baseline neural beamformer.
Multi-Modality Task Cascade for 3D Object Detection
Jul 08, 2021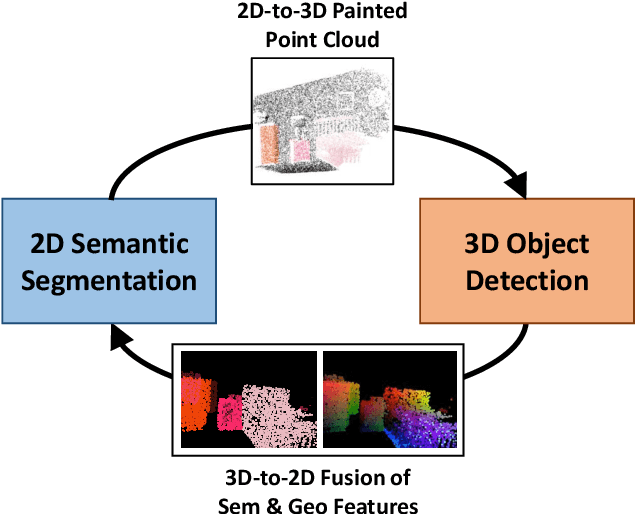
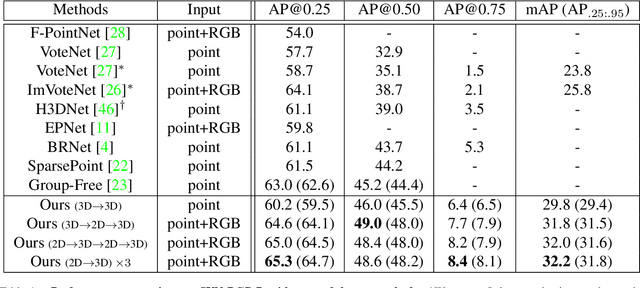
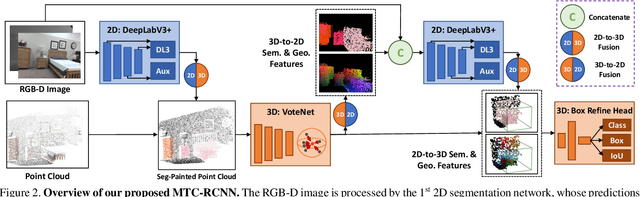
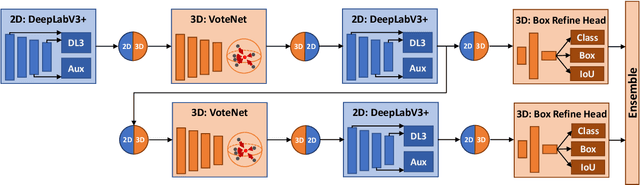
Point clouds and RGB images are naturally complementary modalities for 3D visual understanding - the former provides sparse but accurate locations of points on objects, while the latter contains dense color and texture information. Despite this potential for close sensor fusion, many methods train two models in isolation and use simple feature concatenation to represent 3D sensor data. This separated training scheme results in potentially sub-optimal performance and prevents 3D tasks from being used to benefit 2D tasks that are often useful on their own. To provide a more integrated approach, we propose a novel Multi-Modality Task Cascade network (MTC-RCNN) that leverages 3D box proposals to improve 2D segmentation predictions, which are then used to further refine the 3D boxes. We show that including a 2D network between two stages of 3D modules significantly improves both 2D and 3D task performance. Moreover, to prevent the 3D module from over-relying on the overfitted 2D predictions, we propose a dual-head 2D segmentation training and inference scheme, allowing the 2nd 3D module to learn to interpret imperfect 2D segmentation predictions. Evaluating our model on the challenging SUN RGB-D dataset, we improve upon state-of-the-art results of both single modality and fusion networks by a large margin ($\textbf{+3.8}$ mAP@0.5). Code will be released $\href{https://github.com/Divadi/MTC_RCNN}{\text{here.}}$