 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Dynamic Consistent Submodular Maximization
Jun 03, 2026Consistency is an important property in dynamic submodular maximization and entails maintaining a near-optimal solution at all times, making only a small number of adjustments to the solution in each step. Prior work has explored this question for the insertion-only case, where the algorithm faces a stream of $n$ insertions, and has established lower and upper bounds for the cardinality-constrained version of the problem. We consider this question in the fully dynamic setting, where the stream of operations may contain both insertions and deletions. We develop a general framework for designing algorithms for this setting, and instantiate it to obtain the first constant-factor approximations with sublinear consistency. For cardinality constraints, we propose a $\frac 12 - O(\varepsilon)$ approximation that is $O\left(\frac{1}{\varepsilon^2}\right)$ consistent. For rank-$k$ matroid constraints, we construct a $\frac 14 - O(\varepsilon)$ approximation to the dynamic optimum that is $O\left(\frac{\log k}{\varepsilon^2}\right)$ consistent.
Clustering with Label Consistency
Dec 22, 2025Designing efficient, effective, and consistent metric clustering algorithms is a significant challenge attracting growing attention. Traditional approaches focus on the stability of cluster centers; unfortunately, this neglects the real-world need for stable point labels, i.e., stable assignments of points to named sets (clusters). In this paper, we address this gap by initiating the study of label-consistent metric clustering. We first introduce a new notion of consistency, measuring the label distance between two consecutive solutions. Then, armed with this new definition, we design new consistent approximation algorithms for the classical $k$-center and $k$-median problems.
The Cost of Consistency: Submodular Maximization with Constant Recourse
Dec 03, 2024



In this work, we study online submodular maximization, and how the requirement of maintaining a stable solution impacts the approximation. In particular, we seek bounds on the best-possible approximation ratio that is attainable when the algorithm is allowed to make at most a constant number of updates per step. We show a tight information-theoretic bound of $\tfrac{2}{3}$ for general monotone submodular functions, and an improved (also tight) bound of $\tfrac{3}{4}$ for coverage functions. Since both these bounds are attained by non poly-time algorithms, we also give a poly-time randomized algorithm that achieves a $0.51$-approximation. Combined with an information-theoretic hardness of $\tfrac{1}{2}$ for deterministic algorithms from prior work, our work thus shows a separation between deterministic and randomized algorithms, both information theoretically and for poly-time algorithms.
Consistent Submodular Maximization
May 30, 2024


Maximizing monotone submodular functions under cardinality constraints is a classic optimization task with several applications in data mining and machine learning. In this paper we study this problem in a dynamic environment with consistency constraints: elements arrive in a streaming fashion and the goal is maintaining a constant approximation to the optimal solution while having a stable solution (i.e., the number of changes between two consecutive solutions is bounded). We provide algorithms in this setting with different trade-offs between consistency and approximation quality. We also complement our theoretical results with an experimental analysis showing the effectiveness of our algorithms in real-world instances.
Fairness in Submodular Maximization over a Matroid Constraint
Dec 21, 2023
Submodular maximization over a matroid constraint is a fundamental problem with various applications in machine learning. Some of these applications involve decision-making over datapoints with sensitive attributes such as gender or race. In such settings, it is crucial to guarantee that the selected solution is fairly distributed with respect to this attribute. Recently, fairness has been investigated in submodular maximization under a cardinality constraint in both the streaming and offline settings, however the more general problem with matroid constraint has only been considered in the streaming setting and only for monotone objectives. This work fills this gap. We propose various algorithms and impossibility results offering different trade-offs between quality, fairness, and generality.
Fully Dynamic Submodular Maximization over Matroids
May 31, 2023Maximizing monotone submodular functions under a matroid constraint is a classic algorithmic problem with multiple applications in data mining and machine learning. We study this classic problem in the fully dynamic setting, where elements can be both inserted and deleted in real-time. Our main result is a randomized algorithm that maintains an efficient data structure with an $\tilde{O}(k^2)$ amortized update time (in the number of additions and deletions) and yields a $4$-approximate solution, where $k$ is the rank of the matroid.
Fairness in Streaming Submodular Maximization over a Matroid Constraint
May 24, 2023
Streaming submodular maximization is a natural model for the task of selecting a representative subset from a large-scale dataset. If datapoints have sensitive attributes such as gender or race, it becomes important to enforce fairness to avoid bias and discrimination. This has spurred significant interest in developing fair machine learning algorithms. Recently, such algorithms have been developed for monotone submodular maximization under a cardinality constraint. In this paper, we study the natural generalization of this problem to a matroid constraint. We give streaming algorithms as well as impossibility results that provide trade-offs between efficiency, quality and fairness. We validate our findings empirically on a range of well-known real-world applications: exemplar-based clustering, movie recommendation, and maximum coverage in social networks.
Deletion Robust Non-Monotone Submodular Maximization over Matroids
Aug 16, 2022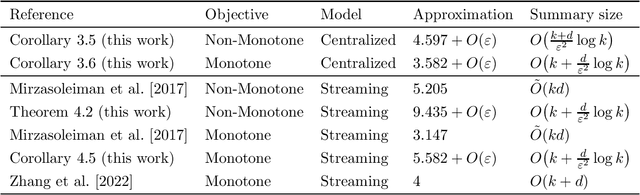
Maximizing a submodular function is a fundamental task in machine learning and in this paper we study the deletion robust version of the problem under the classic matroids constraint. Here the goal is to extract a small size summary of the dataset that contains a high value independent set even after an adversary deleted some elements. We present constant-factor approximation algorithms, whose space complexity depends on the rank $k$ of the matroid and the number $d$ of deleted elements. In the centralized setting we present a $(4.597+O(\varepsilon))$-approximation algorithm with summary size $O( \frac{k+d}{\varepsilon^2}\log \frac{k}{\varepsilon})$ that is improved to a $(3.582+O(\varepsilon))$-approximation with $O(k + \frac{d}{\varepsilon^2}\log \frac{k}{\varepsilon})$ summary size when the objective is monotone. In the streaming setting we provide a $(9.435 + O(\varepsilon))$-approximation algorithm with summary size and memory $O(k + \frac{d}{\varepsilon^2}\log \frac{k}{\varepsilon})$; the approximation factor is then improved to $(5.582+O(\varepsilon))$ in the monotone case.
Near-Optimal Correlation Clustering with Privacy
Mar 02, 2022Correlation clustering is a central problem in unsupervised learning, with applications spanning community detection, duplicate detection, automated labelling and many more. In the correlation clustering problem one receives as input a set of nodes and for each node a list of co-clustering preferences, and the goal is to output a clustering that minimizes the disagreement with the specified nodes' preferences. In this paper, we introduce a simple and computationally efficient algorithm for the correlation clustering problem with provable privacy guarantees. Our approximation guarantees are stronger than those shown in prior work and are optimal up to logarithmic factors.
Deletion Robust Submodular Maximization over Matroids
Jan 31, 2022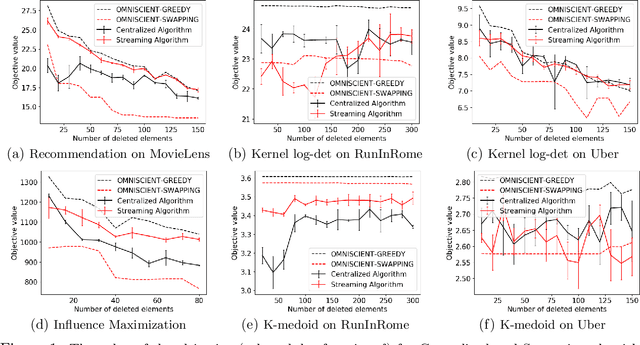
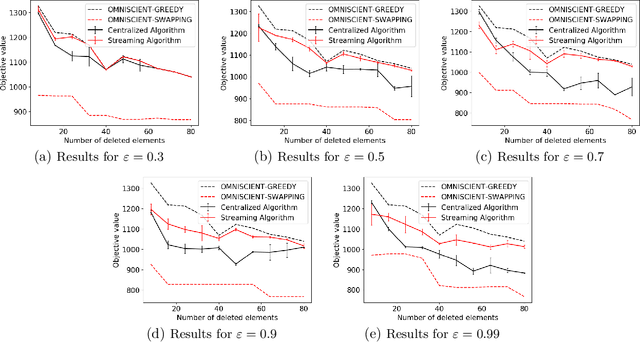
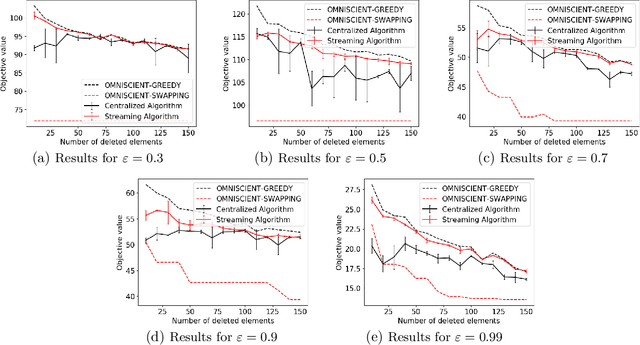
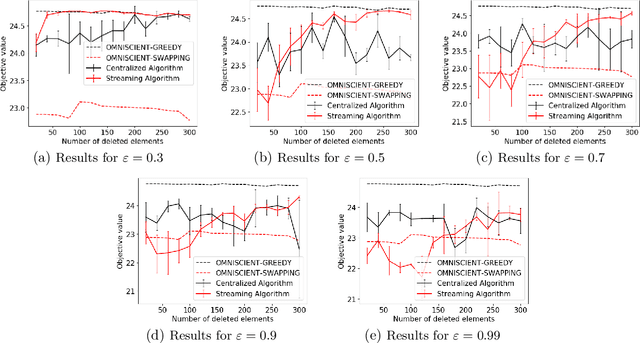
Maximizing a monotone submodular function is a fundamental task in machine learning. In this paper, we study the deletion robust version of the problem under the classic matroids constraint. Here the goal is to extract a small size summary of the dataset that contains a high value independent set even after an adversary deleted some elements. We present constant-factor approximation algorithms, whose space complexity depends on the rank $k$ of the matroid and the number $d$ of deleted elements. In the centralized setting we present a $(3.582+O(\varepsilon))$-approximation algorithm with summary size $O(k + \frac{d \log k}{\varepsilon^2})$. In the streaming setting we provide a $(5.582+O(\varepsilon))$-approximation algorithm with summary size and memory $O(k + \frac{d \log k}{\varepsilon^2})$. We complement our theoretical results with an in-depth experimental analysis showing the effectiveness of our algorithms on real-world datasets.