 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Differential Privacy for Text Analytics via Natural Text Sanitization
Jun 02, 2021
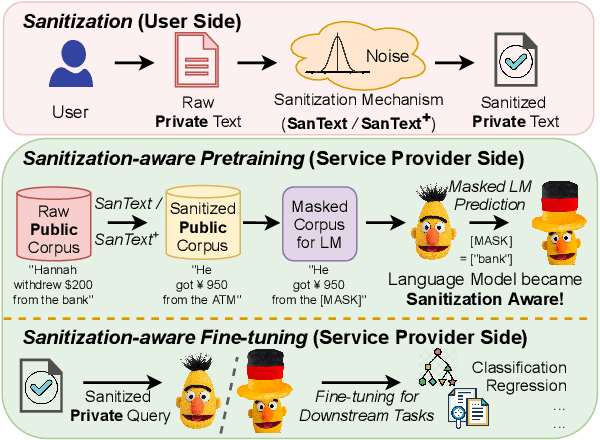
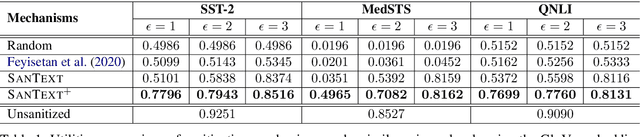
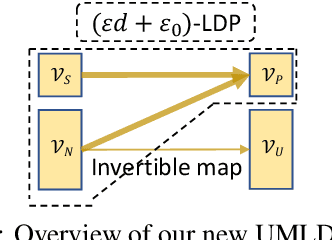
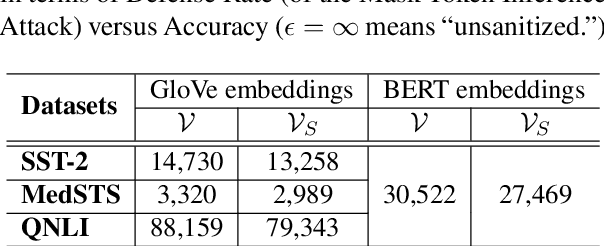
Texts convey sophisticated knowledge. However, texts also convey sensitive information. Despite the success of general-purpose language models and domain-specific mechanisms with differential privacy (DP), existing text sanitization mechanisms still provide low utility, as cursed by the high-dimensional text representation. The companion issue of utilizing sanitized texts for downstream analytics is also under-explored. This paper takes a direct approach to text sanitization. Our insight is to consider both sensitivity and similarity via our new local DP notion. The sanitized texts also contribute to our sanitization-aware pretraining and fine-tuning, enabling privacy-preserving natural language processing over the BERT language model with promising utility. Surprisingly, the high utility does not boost up the success rate of inference attacks.
Multi-objective Contextual Bandit Problem with Similarity Information
Mar 11, 2018
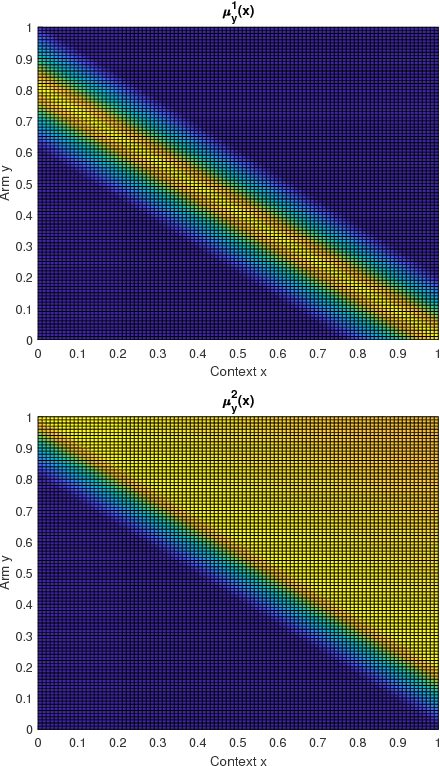
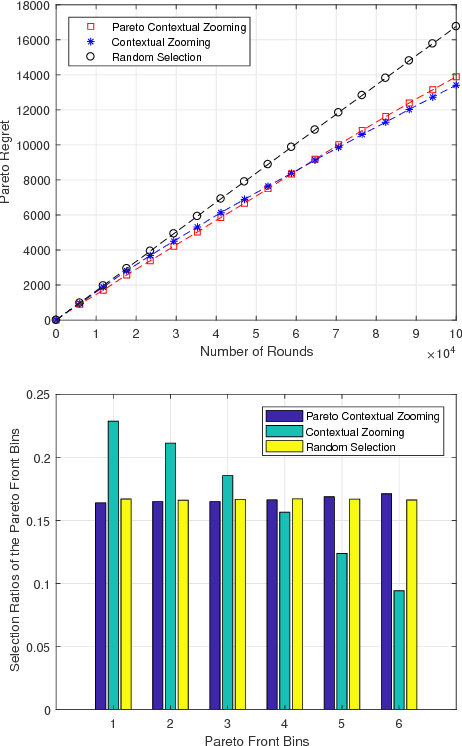
In this paper we propose the multi-objective contextual bandit problem with similarity information. This problem extends the classical contextual bandit problem with similarity information by introducing multiple and possibly conflicting objectives. Since the best arm in each objective can be different given the context, learning the best arm based on a single objective can jeopardize the rewards obtained from the other objectives. In order to evaluate the performance of the learner in this setup, we use a performance metric called the contextual Pareto regret. Essentially, the contextual Pareto regret is the sum of the distances of the arms chosen by the learner to the context dependent Pareto front. For this problem, we develop a new online learning algorithm called Pareto Contextual Zooming (PCZ), which exploits the idea of contextual zooming to learn the arms that are close to the Pareto front for each observed context by adaptively partitioning the joint context-arm set according to the observed rewards and locations of the context-arm pairs selected in the past. Then, we prove that PCZ achieves $\tilde O (T^{(1+d_p)/(2+d_p)})$ Pareto regret where $d_p$ is the Pareto zooming dimension that depends on the size of the set of near-optimal context-arm pairs. Moreover, we show that this regret bound is nearly optimal by providing an almost matching $\Omega (T^{(1+d_p)/(2+d_p)})$ lower bound.
Rethinking BiSeNet For Real-time Semantic Segmentation
Apr 27, 2021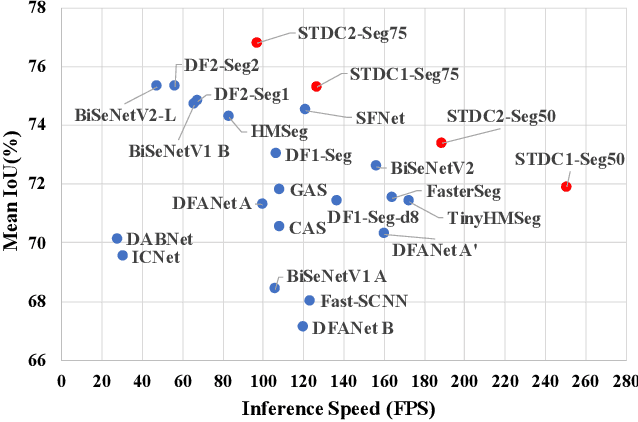
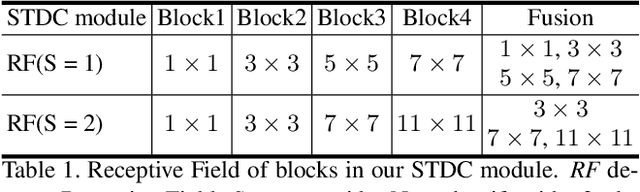
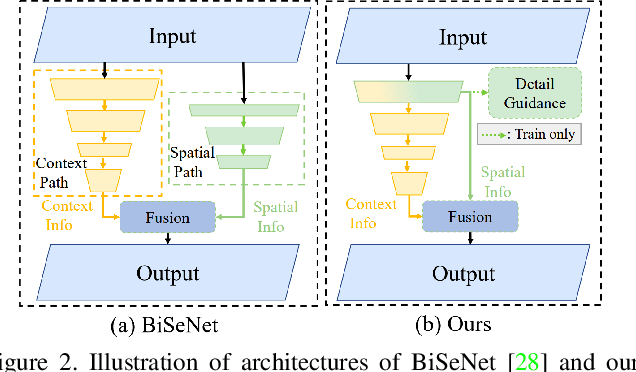
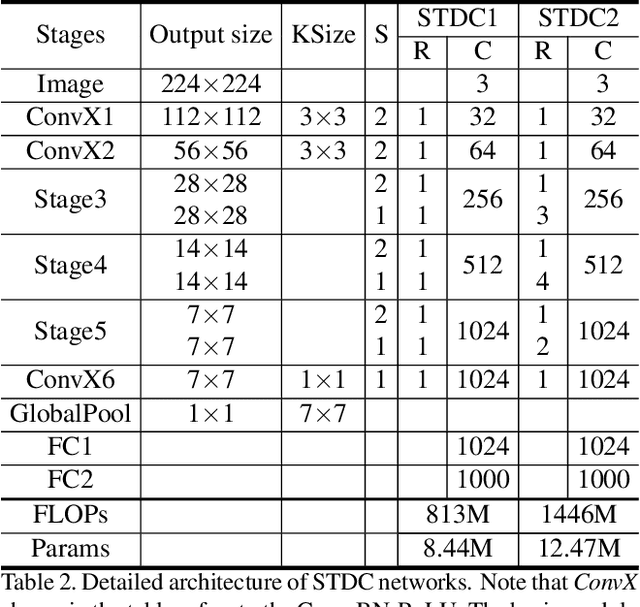
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
Refined method to extract frequency-noise components of lasers by delayed self-heterodyne
Jun 02, 2021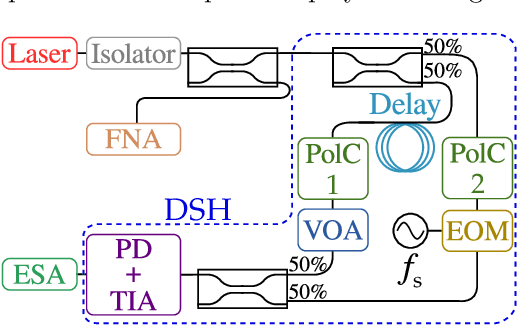
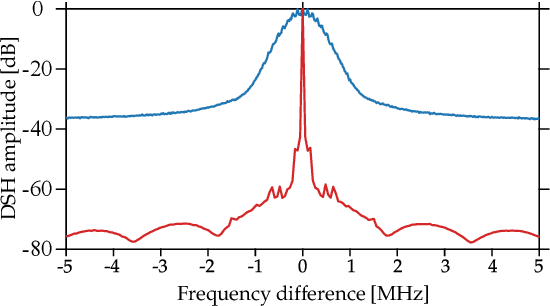
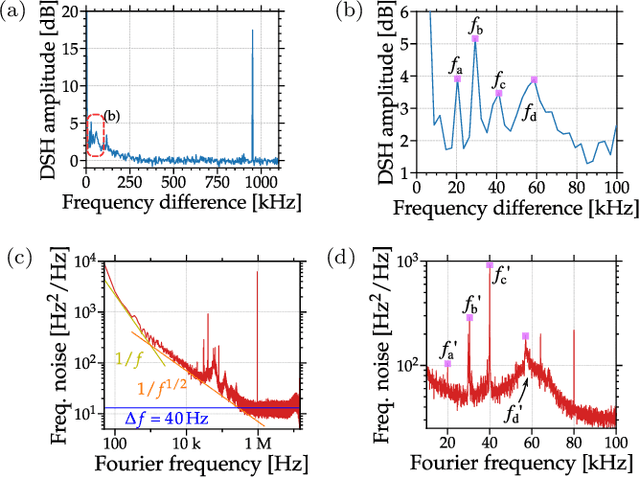
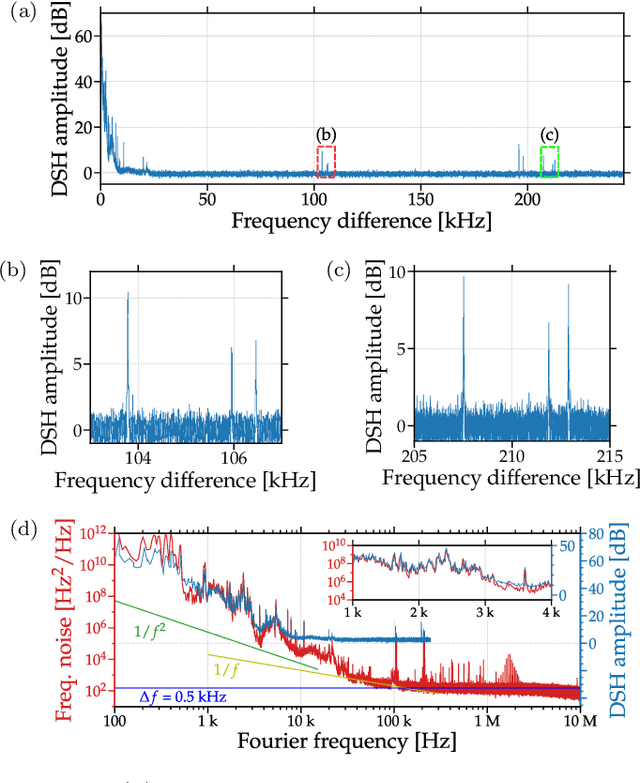
An essential metric to quantify the stability of a laser is its frequency noise (FN). This metric yields information on the linewidth and on noise components which limit its usage for high precision purposes such as coherent communication. Its experimental determination relies on challenging optical phase measurements, for which dedicated commercial instruments have been developed. In contrast, this work presents a simple and cost-effective method for extracting FN features employing a delayed self-heterodyne (DSH) setup. Using delay lengths much shorter than the coherence length of the laser, the DSH trace reveals a correspondence with the FN power spectral density (PSD) measured with commercial instruments. Results are found for multiple lasers, with discrepancies in intense dither tone frequencies below 0.2 percent
Legal Judgment Prediction with Multi-Stage CaseRepresentation Learning in the Real Court Setting
Jul 12, 2021

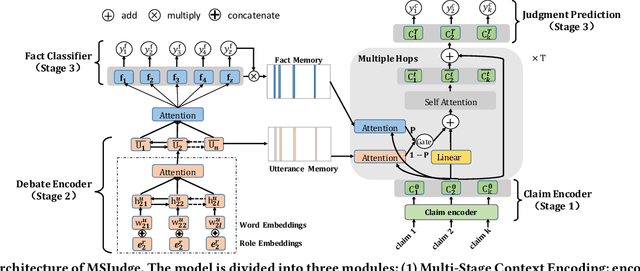
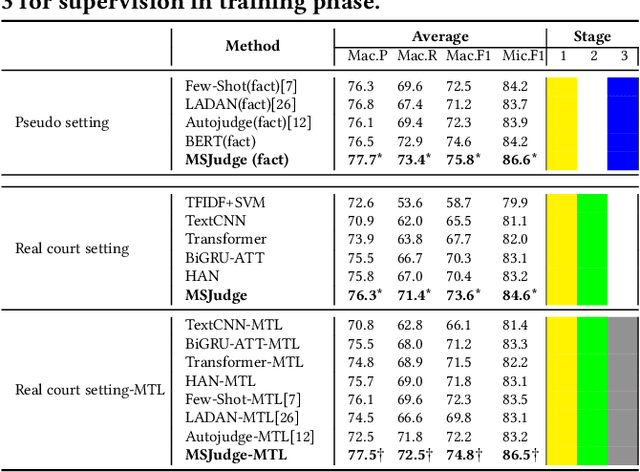
Legal judgment prediction(LJP) is an essential task for legal AI. While prior methods studied on this topic in a pseudo setting by employing the judge-summarized case narrative as the input to predict the judgment, neglecting critical case life-cycle information in real court setting could threaten the case logic representation quality and prediction correctness. In this paper, we introduce a novel challenging dataset from real courtrooms to predict the legal judgment in a reasonably encyclopedic manner by leveraging the genuine input of the case -- plaintiff's claims and court debate data, from which the case's facts are automatically recognized by comprehensively understanding the multi-role dialogues of the court debate, and then learnt to discriminate the claims so as to reach the final judgment through multi-task learning. An extensive set of experiments with a large civil trial data set shows that the proposed model can more accurately characterize the interactions among claims, fact and debate for legal judgment prediction, achieving significant improvements over strong state-of-the-art baselines. Moreover, the user study conducted with real judges and law school students shows the neural predictions can also be interpretable and easily observed, and thus enhancing the trial efficiency and judgment quality.
Icebreaker: Element-wise Active Information Acquisition with Bayesian Deep Latent Gaussian Model
Aug 14, 2019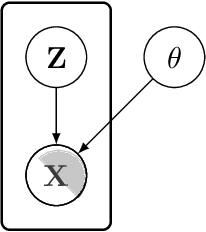
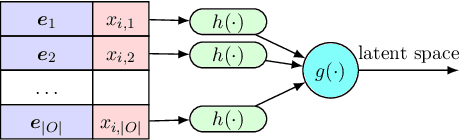
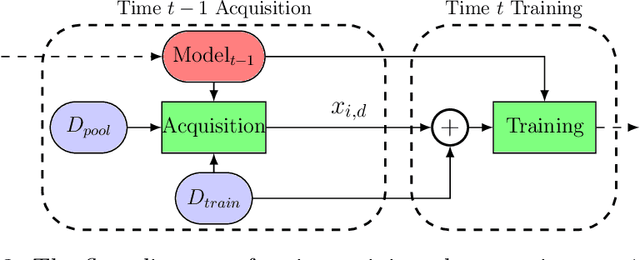
In this paper we introduce the ice-start problem, i.e., the challenge of deploying machine learning models when only little or no training data is initially available, and acquiring each feature element of data is associated with costs. This setting is representative for the real-world machine learning applications. For instance, in the health-care domain, when training an AI system for predicting patient metrics from lab tests, obtaining every single measurement comes with a high cost. Active learning, where only the label is associated with a cost does not apply to such problem, because performing all possible lab tests to acquire a new training datum would be costly, as well as unnecessary due to redundancy. We propose Icebreaker, a principled framework to approach the ice-start problem. Icebreaker uses a full Bayesian Deep Latent Gaussian Model (BELGAM) with a novel inference method. Our proposed method combines recent advances in amortized inference and stochastic gradient MCMC to enable fast and accurate posterior inference. By utilizing BELGAM's ability to fully quantify model uncertainty, we also propose two information acquisition functions for imputation and active prediction problems. We demonstrate that BELGAM performs significantly better than the previous VAE (Variational autoencoder) based models, when the data set size is small, using both machine learning benchmarks and real-world recommender systems and health-care applications. Moreover, based on BELGAM, Icebreaker further improves the performance and demonstrate the ability to use minimum amount of the training data to obtain the highest test time performance.
F-T-LSTM based Complex Network for Joint Acoustic Echo Cancellation and Speech Enhancement
Jun 16, 2021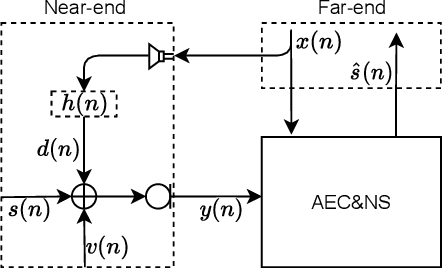
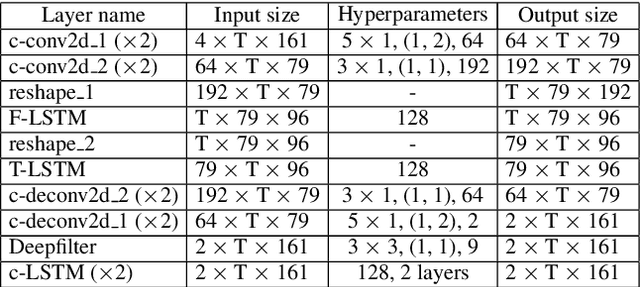
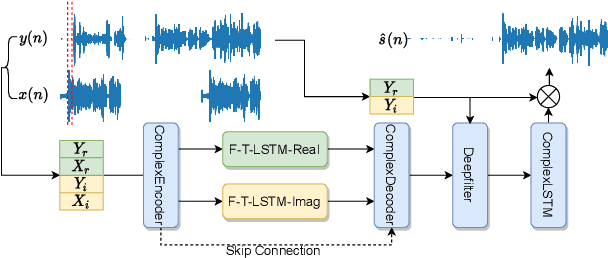
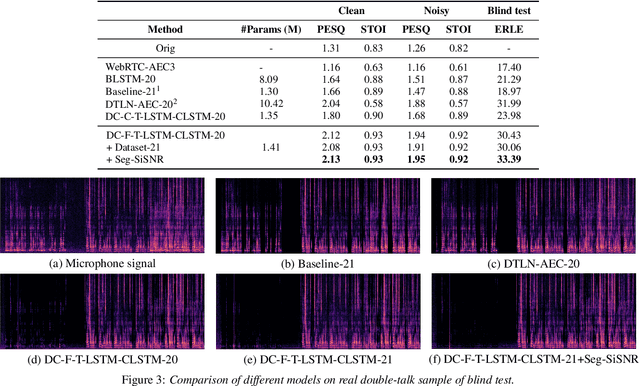
With the increasing demand for audio communication and online conference, ensuring the robustness of Acoustic Echo Cancellation (AEC) under the complicated acoustic scenario including noise, reverberation and nonlinear distortion has become a top issue. Although there have been some traditional methods that consider nonlinear distortion, they are still inefficient for echo suppression and the performance will be attenuated when noise is present. In this paper, we present a real-time AEC approach using complex neural network to better modeling the important phase information and frequency-time-LSTMs (F-T-LSTM), which scan both frequency and time axis, for better temporal modeling. Moreover, we utilize modified SI-SNR as cost function to make the model to have better echo cancellation and noise suppression (NS) performance. With only 1.4M parameters, the proposed approach outperforms the AEC-challenge baseline by 0.27 in terms of Mean Opinion Score (MOS).
Hyperbolic Busemann Learning with Ideal Prototypes
Jun 28, 2021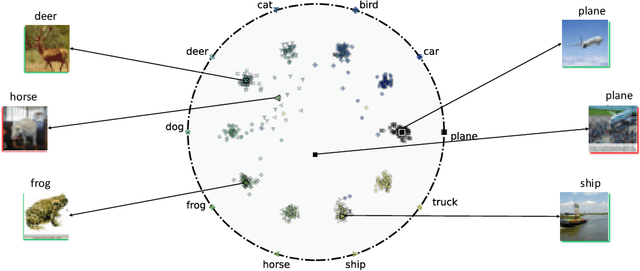

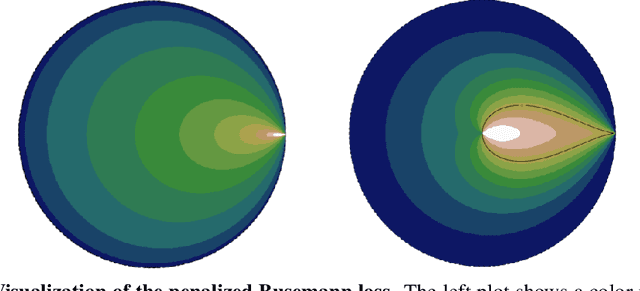

Hyperbolic space has become a popular choice of manifold for representation learning of arbitrary data, from tree-like structures and text to graphs. Building on the success of deep learning with prototypes in Euclidean and hyperspherical spaces, a few recent works have proposed hyperbolic prototypes for classification. Such approaches enable effective learning in low-dimensional output spaces and can exploit hierarchical relations amongst classes, but require privileged information about class labels to position the hyperbolic prototypes. In this work, we propose Hyperbolic Busemann Learning. The main idea behind our approach is to position prototypes on the ideal boundary of the Poincare ball, which does not require prior label knowledge. To be able to compute proximities to ideal prototypes, we introduce the penalised Busemann loss. We provide theory supporting the use of ideal prototypes and the proposed loss by proving its equivalence to logistic regression in the one-dimensional case. Empirically, we show that our approach provides a natural interpretation of classification confidence, while outperforming recent hyperspherical and hyperbolic prototype approaches.
Semantic-aware Knowledge Distillation for Few-Shot Class-Incremental Learning
Mar 31, 2021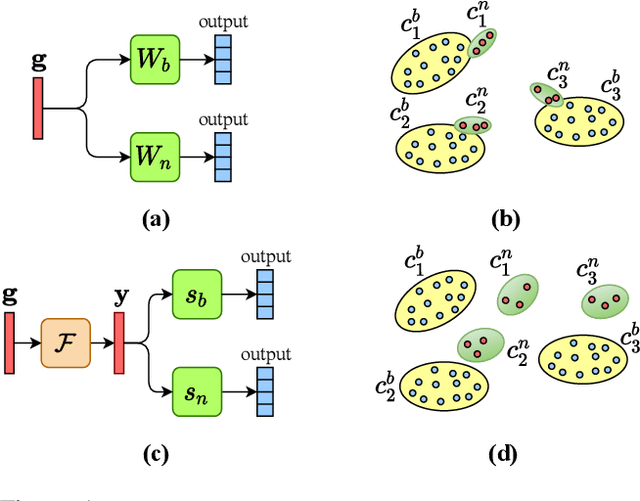
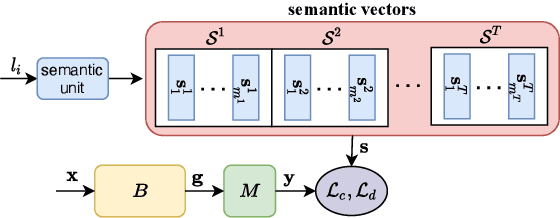

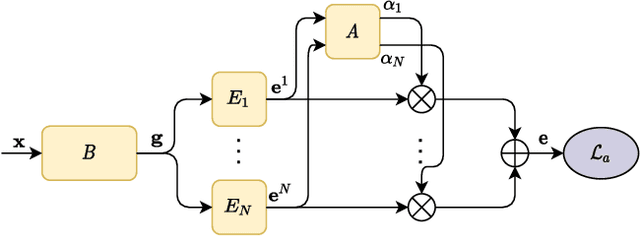
Few-shot class incremental learning (FSCIL) portrays the problem of learning new concepts gradually, where only a few examples per concept are available to the learner. Due to the limited number of examples for training, the techniques developed for standard incremental learning cannot be applied verbatim to FSCIL. In this work, we introduce a distillation algorithm to address the problem of FSCIL and propose to make use of semantic information during training. To this end, we make use of word embeddings as semantic information which is cheap to obtain and which facilitate the distillation process. Furthermore, we propose a method based on an attention mechanism on multiple parallel embeddings of visual data to align visual and semantic vectors, which reduces issues related to catastrophic forgetting. Via experiments on MiniImageNet, CUB200, and CIFAR100 dataset, we establish new state-of-the-art results by outperforming existing approaches.
AWCD: An Efficient Point Cloud Processing Approach via Wasserstein Curvature
May 11, 2021


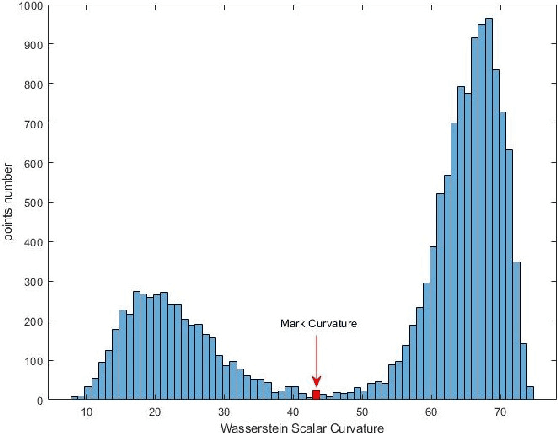
In this paper, we introduce the adaptive Wasserstein curvature denoising (AWCD), an original processing approach for point cloud data. By collecting curvatures information from Wasserstein distance, AWCD consider more precise structures of data and preserves stability and effectiveness even for data with noise in high density. This paper contains some theoretical analysis about the Wasserstein curvature and the complete algorithm of AWCD. In addition, we design digital experiments to show the denoising effect of AWCD. According to comparison results, we present the advantages of AWCD against traditional algorithms.