 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Hyperbolic Learning of Instances and Classes
Jun 12, 2025



Continual learning has traditionally focused on classifying either instances or classes, but real-world applications, such as robotics and self-driving cars, require models to handle both simultaneously. To mirror real-life scenarios, we introduce the task of continual learning of instances and classes, at the same time. This task challenges models to adapt to multiple levels of granularity over time, which requires balancing fine-grained instance recognition with coarse-grained class generalization. In this paper, we identify that classes and instances naturally form a hierarchical structure. To model these hierarchical relationships, we propose HyperCLIC, a continual learning algorithm that leverages hyperbolic space, which is uniquely suited for hierarchical data due to its ability to represent tree-like structures with low distortion and compact embeddings. Our framework incorporates hyperbolic classification and distillation objectives, enabling the continual embedding of hierarchical relations. To evaluate performance across multiple granularities, we introduce continual hierarchical metrics. We validate our approach on EgoObjects, the only dataset that captures the complexity of hierarchical object recognition in dynamic real-world environments. Empirical results show that HyperCLIC operates effectively at multiple granularities with improved hierarchical generalization.
Hyperbolic Deep Learning in Computer Vision: A Survey
May 11, 2023



Deep representation learning is a ubiquitous part of modern computer vision. While Euclidean space has been the de facto standard manifold for learning visual representations, hyperbolic space has recently gained rapid traction for learning in computer vision. Specifically, hyperbolic learning has shown a strong potential to embed hierarchical structures, learn from limited samples, quantify uncertainty, add robustness, limit error severity, and more. In this paper, we provide a categorization and in-depth overview of current literature on hyperbolic learning for computer vision. We research both supervised and unsupervised literature and identify three main research themes in each direction. We outline how hyperbolic learning is performed in all themes and discuss the main research problems that benefit from current advances in hyperbolic learning for computer vision. Moreover, we provide a high-level intuition behind hyperbolic geometry and outline open research questions to further advance research in this direction.
Hyperbolic Busemann Learning with Ideal Prototypes
Jun 28, 2021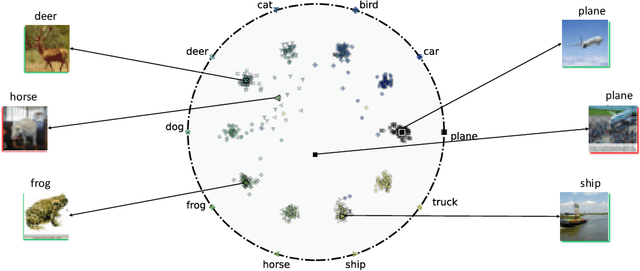

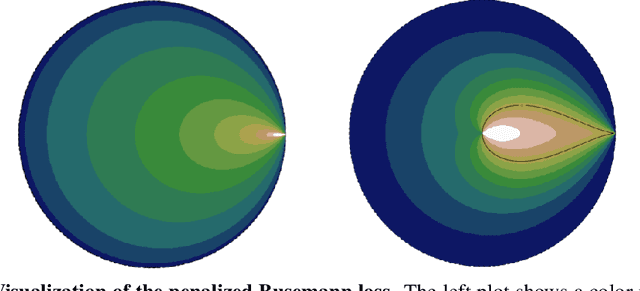

Hyperbolic space has become a popular choice of manifold for representation learning of arbitrary data, from tree-like structures and text to graphs. Building on the success of deep learning with prototypes in Euclidean and hyperspherical spaces, a few recent works have proposed hyperbolic prototypes for classification. Such approaches enable effective learning in low-dimensional output spaces and can exploit hierarchical relations amongst classes, but require privileged information about class labels to position the hyperbolic prototypes. In this work, we propose Hyperbolic Busemann Learning. The main idea behind our approach is to position prototypes on the ideal boundary of the Poincare ball, which does not require prior label knowledge. To be able to compute proximities to ideal prototypes, we introduce the penalised Busemann loss. We provide theory supporting the use of ideal prototypes and the proposed loss by proving its equivalence to logistic regression in the one-dimensional case. Empirically, we show that our approach provides a natural interpretation of classification confidence, while outperforming recent hyperspherical and hyperbolic prototype approaches.
Convolutional Relational Machine for Group Activity Recognition
Apr 05, 2019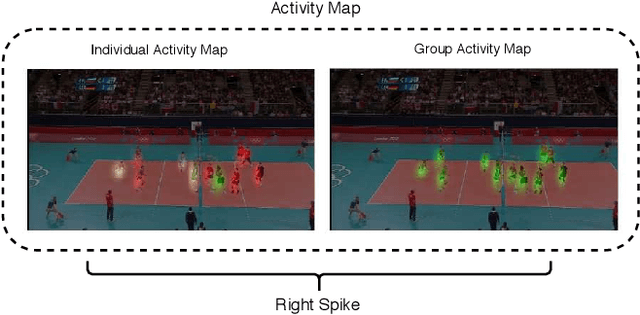
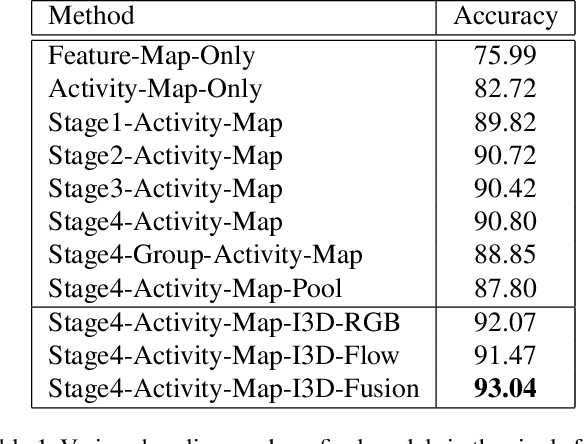
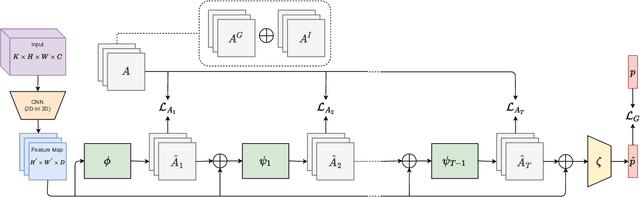
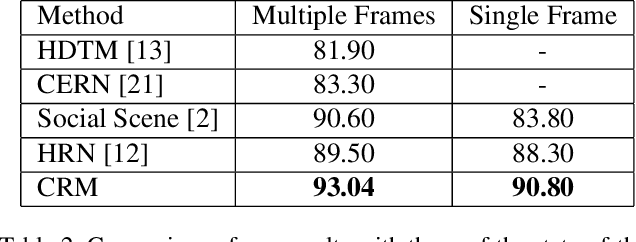
We present an end-to-end deep Convolutional Neural Network called Convolutional Relational Machine (CRM) for recognizing group activities that utilizes the information in spatial relations between individual persons in image or video. It learns to produce an intermediate spatial representation (activity map) based on individual and group activities. A multi-stage refinement component is responsible for decreasing the incorrect predictions in the activity map. Finally, an aggregation component uses the refined information to recognize group activities. Experimental results demonstrate the constructive contribution of the information extracted and represented in the form of the activity map. CRM shows advantages over state-of-the-art models on Volleyball and Collective Activity datasets.
A Multi-Stream Convolutional Neural Network Framework for Group Activity Recognition
Dec 26, 2018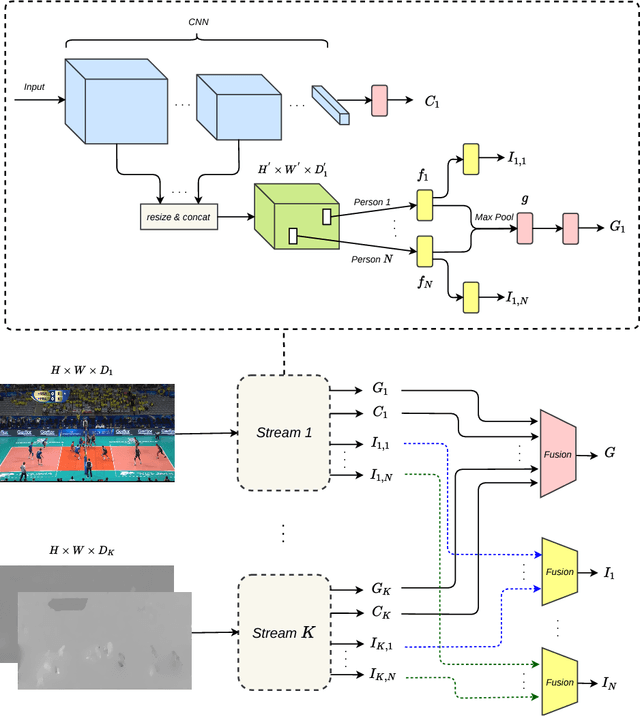
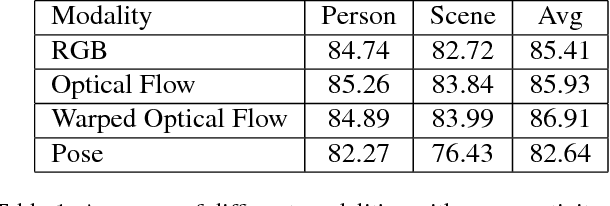

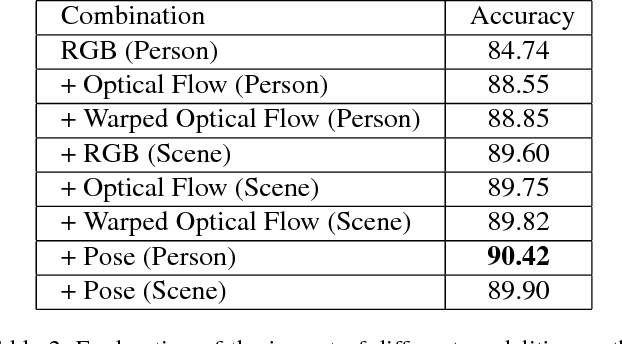
In this work, we present a framework based on multi-stream convolutional neural networks (CNNs) for group activity recognition. Streams of CNNs are separately trained on different modalities and their predictions are fused at the end. Each stream has two branches to predict the group activity based on person and scene level representations. A new modality based on the human pose estimation is presented to add extra information to the model. We evaluate our method on the Volleyball and Collective Activity datasets. Experimental results show that the proposed framework is able to achieve state-of-the-art results when multiple or single frames are given as input to the model with 90.50% and 86.61% accuracy on Volleyball dataset, respectively, and 87.01% accuracy of multiple frames group activity on Collective Activity dataset.
Zoom-RNN: A Novel Method for Person Recognition Using Recurrent Neural Networks
Sep 26, 2018The overwhelming popularity of social media has resulted in bulk amounts of personal photos being uploaded to the internet every day. Since these photos are taken in unconstrained settings, recognizing the identities of people among the photos remains a challenge. Studies have indicated that utilizing evidence other than face appearance improves the performance of person recognition systems. In this work, we aim to take advantage of additional cues obtained from different body regions in a zooming in fashion for person recognition. Hence, we present Zoom-RNN, a novel method based on recurrent neural networks for combining evidence extracted from the whole body, upper body, and head regions. Our model is evaluated on a challenging dataset, namely People In Photo Albums (PIPA), and we demonstrate that employing our system improves the performance of conventional fusion methods by a noticeable margin.