 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
Jun 15, 2021
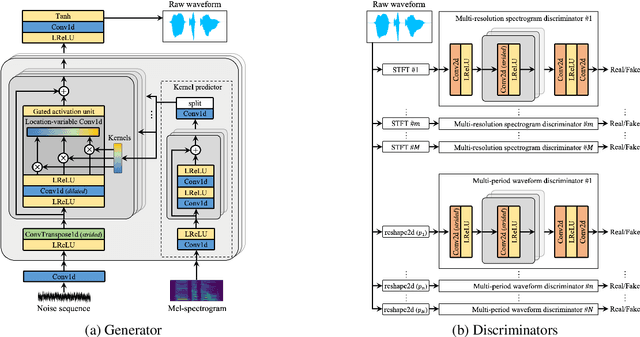
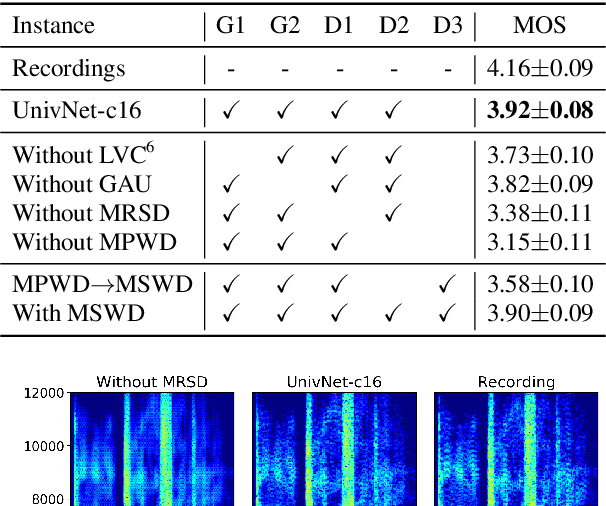
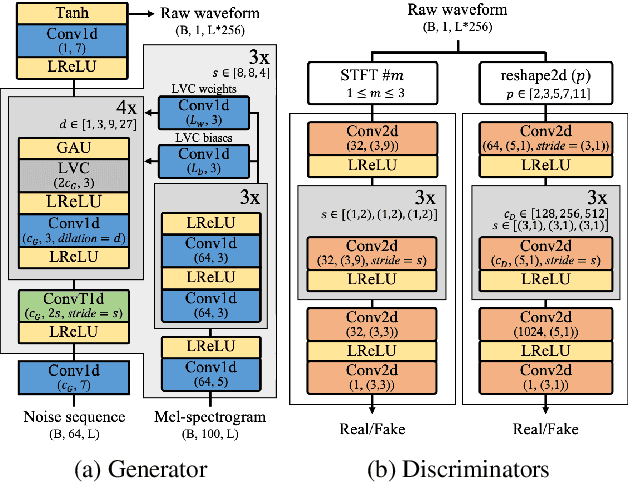
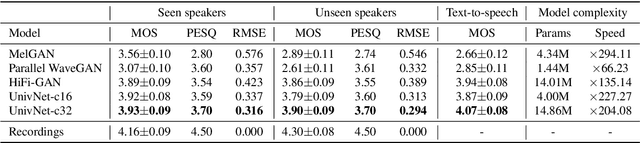
Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.
Truth Discovery in Sequence Labels from Crowds
Sep 09, 2021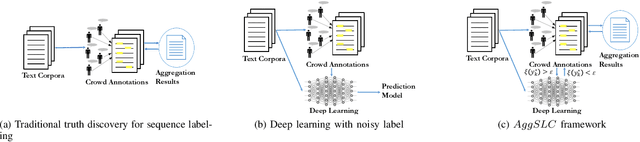
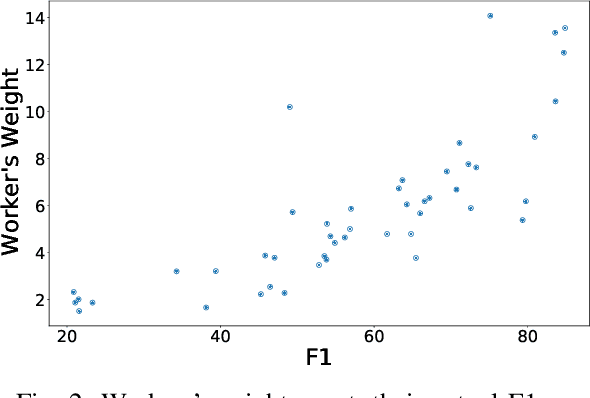
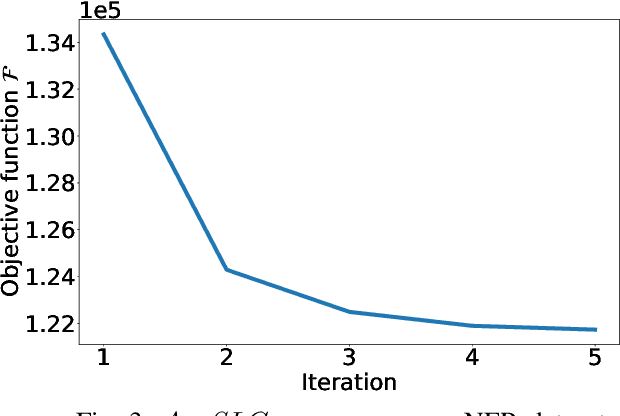
Annotations quality and quantity positively affect the performance of sequence labeling, a vital task in Natural Language Processing. Hiring domain experts to annotate a corpus set is very costly in terms of money and time. Crowdsourcing platforms, such as Amazon Mechanical Turk (AMT), have been deployed to assist in this purpose. However, these platforms are prone to human errors due to the lack of expertise; hence, one worker's annotations cannot be directly used to train the model. Existing literature in annotation aggregation more focuses on binary or multi-choice problems. In recent years, handling the sequential label aggregation tasks on imbalanced datasets with complex dependencies between tokens has been challenging. To conquer the challenge, we propose an optimization-based method that infers the best set of aggregated annotations using labels provided by workers. The proposed Aggregation method for Sequential Labels from Crowds ($AggSLC$) jointly considers the characteristics of sequential labeling tasks, workers' reliabilities, and advanced machine learning techniques. We evaluate $AggSLC$ on different crowdsourced data for Named Entity Recognition (NER), Information Extraction tasks in biomedical (PICO), and the simulated dataset. Our results show that the proposed method outperforms the state-of-the-art aggregation methods. To achieve insights into the framework, we study $AggSLC$ components' effectiveness through ablation studies by evaluating our model in the absence of the prediction module and inconsistency loss function. Theoretical analysis of our algorithm's convergence points that the proposed $AggSLC$ halts after a finite number of iterations.
Luminance Attentive Networks for HDR Image and Panorama Reconstruction
Sep 14, 2021
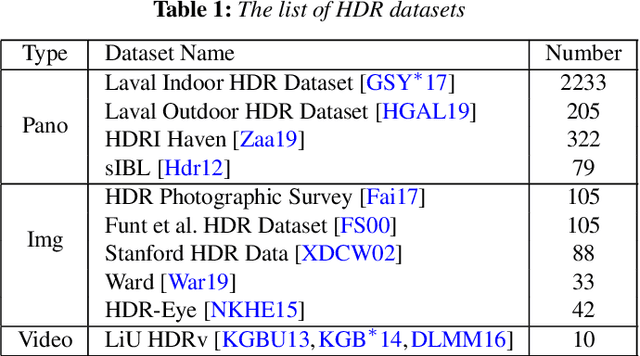
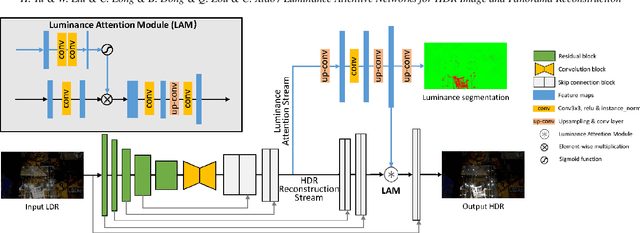
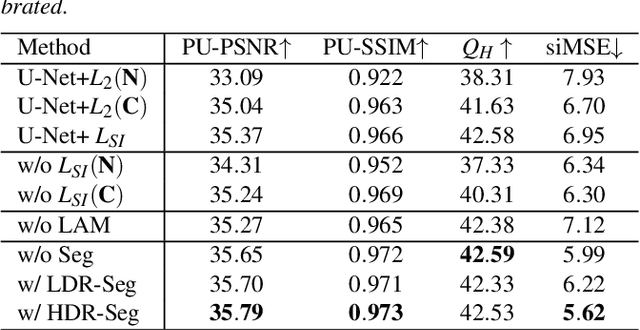
It is very challenging to reconstruct a high dynamic range (HDR) from a low dynamic range (LDR) image as an ill-posed problem. This paper proposes a luminance attentive network named LANet for HDR reconstruction from a single LDR image. Our method is based on two fundamental observations: (1) HDR images stored in relative luminance are scale-invariant, which means the HDR images will hold the same information when multiplied by any positive real number. Based on this observation, we propose a novel normalization method called " HDR calibration " for HDR images stored in relative luminance, calibrating HDR images into a similar luminance scale according to the LDR images. (2) The main difference between HDR images and LDR images is in under-/over-exposed areas, especially those highlighted. Following this observation, we propose a luminance attention module with a two-stream structure for LANet to pay more attention to the under-/over-exposed areas. In addition, we propose an extended network called panoLANet for HDR panorama reconstruction from an LDR panorama and build a dualnet structure for panoLANet to solve the distortion problem caused by the equirectangular panorama. Extensive experiments show that our proposed approach LANet can reconstruct visually convincing HDR images and demonstrate its superiority over state-of-the-art approaches in terms of all metrics in inverse tone mapping. The image-based lighting application with our proposed panoLANet also demonstrates that our method can simulate natural scene lighting using only LDR panorama. Our source code is available at https://github.com/LWT3437/LANet.
Not All Words are Equal: Video-specific Information Loss for Video Captioning
Jan 01, 2019
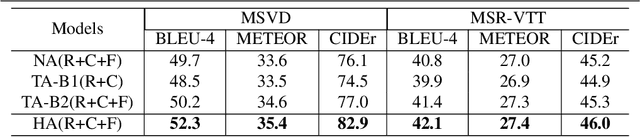
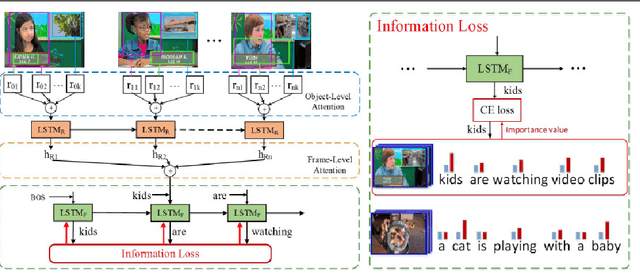
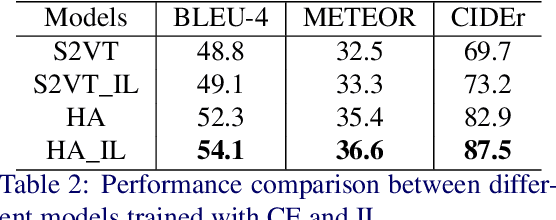
An ideal description for a given video should fix its gaze on salient and representative content, which is capable of distinguishing this video from others. However, the distribution of different words is unbalanced in video captioning datasets, where distinctive words for describing video-specific salient objects are far less than common words such as 'a' 'the' and 'person'. The dataset bias often results in recognition error or detail deficiency of salient but unusual objects. To address this issue, we propose a novel learning strategy called Information Loss, which focuses on the relationship between the video-specific visual content and corresponding representative words. Moreover, a framework with hierarchical visual representations and an optimized hierarchical attention mechanism is established to capture the most salient spatial-temporal visual information, which fully exploits the potential strength of the proposed learning strategy. Extensive experiments demonstrate that the ingenious guidance strategy together with the optimized architecture outperforms state-of-the-art video captioning methods on MSVD with CIDEr score 87.5, and achieves superior CIDEr score 47.7 on MSR-VTT. We also show that our Information Loss is generic which improves various models by significant margins.
HintedBT: Augmenting Back-Translation with Quality and Transliteration Hints
Sep 09, 2021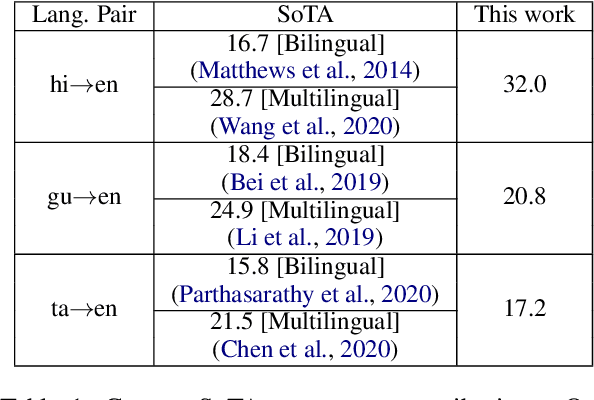


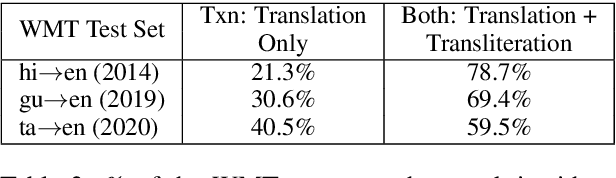
Back-translation (BT) of target monolingual corpora is a widely used data augmentation strategy for neural machine translation (NMT), especially for low-resource language pairs. To improve effectiveness of the available BT data, we introduce HintedBT -- a family of techniques which provides hints (through tags) to the encoder and decoder. First, we propose a novel method of using both high and low quality BT data by providing hints (as source tags on the encoder) to the model about the quality of each source-target pair. We don't filter out low quality data but instead show that these hints enable the model to learn effectively from noisy data. Second, we address the problem of predicting whether a source token needs to be translated or transliterated to the target language, which is common in cross-script translation tasks (i.e., where source and target do not share the written script). For such cases, we propose training the model with additional hints (as target tags on the decoder) that provide information about the operation required on the source (translation or both translation and transliteration). We conduct experiments and detailed analyses on standard WMT benchmarks for three cross-script low/medium-resource language pairs: {Hindi,Gujarati,Tamil}-to-English. Our methods compare favorably with five strong and well established baselines. We show that using these hints, both separately and together, significantly improves translation quality and leads to state-of-the-art performance in all three language pairs in corresponding bilingual settings.
Inspecting the Process of Bank Credit Rating via Visual Analytics
Aug 06, 2021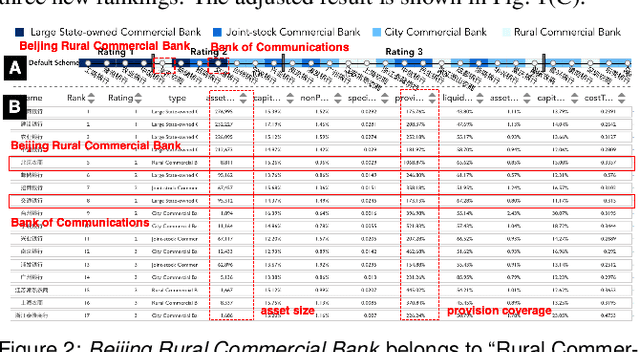
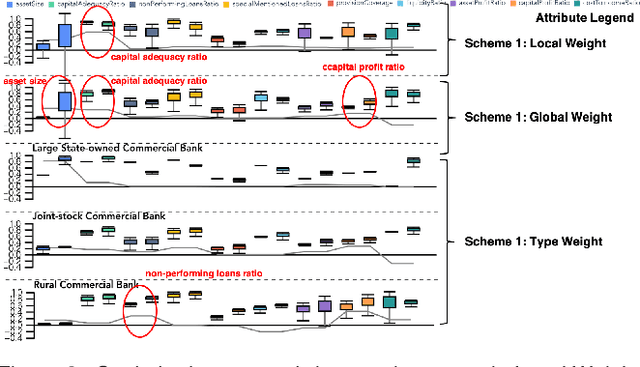
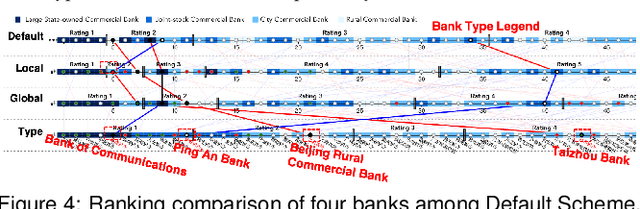
Bank credit rating classifies banks into different levels based on publicly disclosed and internal information, serving as an important input in financial risk management. However, domain experts have a vague idea of exploring and comparing different bank credit rating schemes. A loose connection between subjective and quantitative analysis and difficulties in determining appropriate indicator weights obscure understanding of bank credit ratings. Furthermore, existing models fail to consider bank types by just applying a unified indicator weight set to all banks. We propose RatingVis to assist experts in exploring and comparing different bank credit rating schemes. It supports interactively inferring indicator weights for banks by involving domain knowledge and considers bank types in the analysis loop. We conduct a case study with real-world bank data to verify the efficacy of RatingVis. Expert feedback suggests that our approach helps them better understand different rating schemes.
Self-supervised Learning of Occlusion Aware Flow Guided 3D Geometry Perception with Adaptive Cross Weighted Loss from Monocular Videos
Aug 10, 2021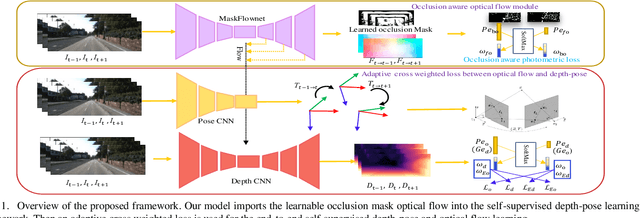
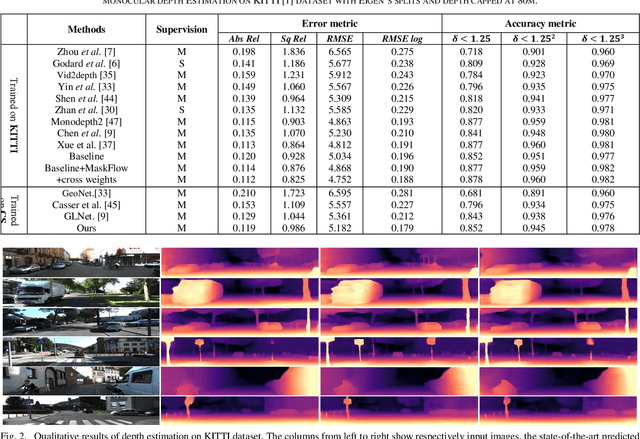
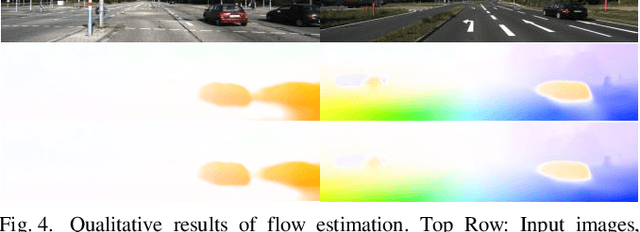
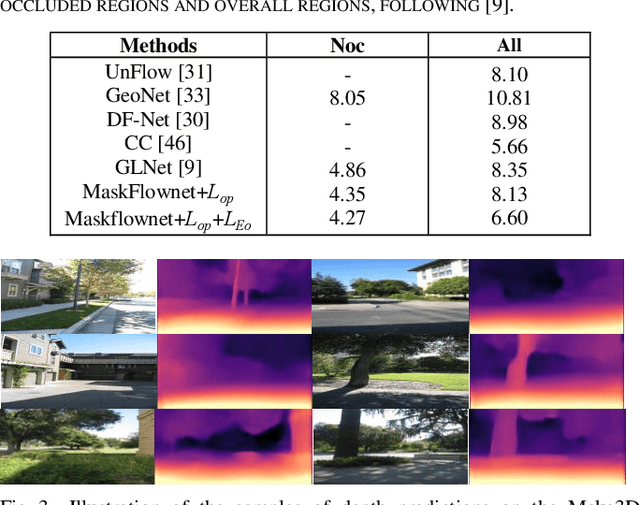
Self-supervised deep learning-based 3D scene understanding methods can overcome the difficulty of acquiring the densely labeled ground-truth and have made a lot of advances. However, occlusions and moving objects are still some of the major limitations. In this paper, we explore the learnable occlusion aware optical flow guided self-supervised depth and camera pose estimation by an adaptive cross weighted loss to address the above limitations. Firstly, we explore to train the learnable occlusion mask fused optical flow network by an occlusion-aware photometric loss with the temporally supplemental information and backward-forward consistency of adjacent views. And then, we design an adaptive cross-weighted loss between the depth-pose and optical flow loss of the geometric and photometric error to distinguish the moving objects which violate the static scene assumption. Our method shows promising results on KITTI, Make3D, and Cityscapes datasets under multiple tasks. We also show good generalization ability under a variety of challenging scenarios.
MetaSketch: Wireless Semantic Segmentation by Metamaterial Surfaces
Aug 29, 2021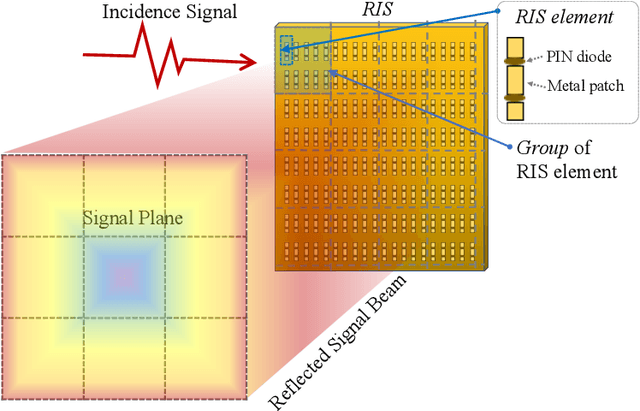
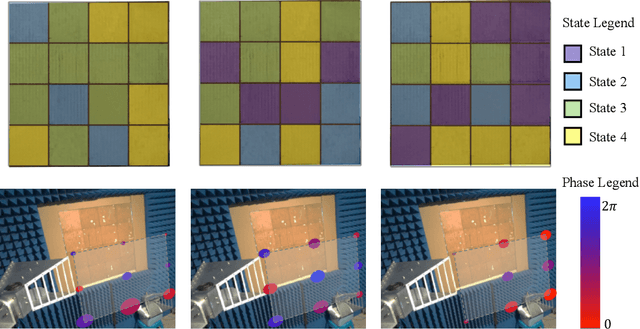

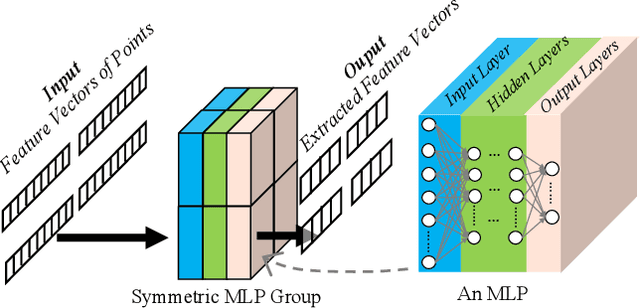
Semantic segmentation is a process of partitioning an image into multiple segments for recognizing humans and objects, which can be widely applied in scenarios such as healthcare and safety monitoring. To avoid privacy violation, using RF signals instead of an image for human and object recognition has gained increasing attention. However, human and object recognition by using RF signals is usually a passive signal collection and analysis process without changing the radio environment, and the recognition accuracy is restricted significantly by unwanted multi-path fading, and/or the limited number of independent channels between RF transceivers in uncontrollable radio environments. This paper introduces MetaSketch, a novel RF-sensing system that performs semantic recognition and segmentation for humans and objects by making the radio environment reconfigurable. A metamaterial surface is incorporated into MetaSketch and diversifies the information carried by RF signals. Using compressive sensing techniques, MetaSketch reconstructs a point cloud consisting of the reflection coefficients of humans and objects at different spatial points, and recognizes the semantic meaning of the points by using symmetric multilayer perceptron groups. Our evaluation results show that MetaSketch is capable of generating favorable radio environments and extracting exact point clouds, and labeling the semantic meaning of the points with an average error rate of less than 1% in an indoor space.
Probabilistic Monocular 3D Human Pose Estimation with Normalizing Flows
Aug 02, 2021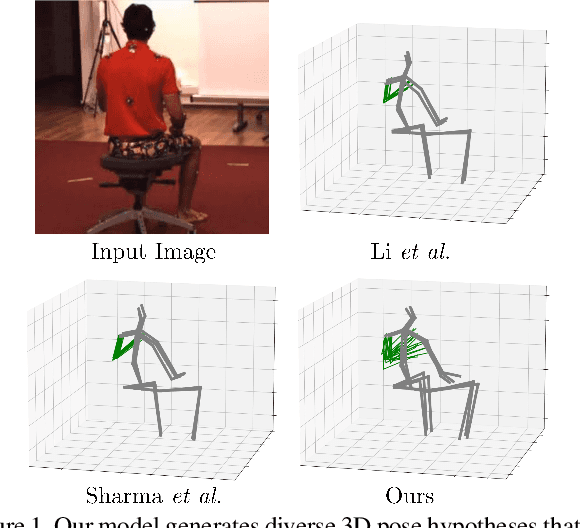
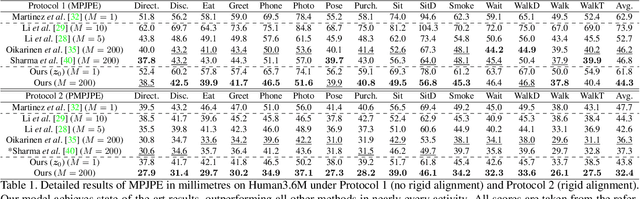
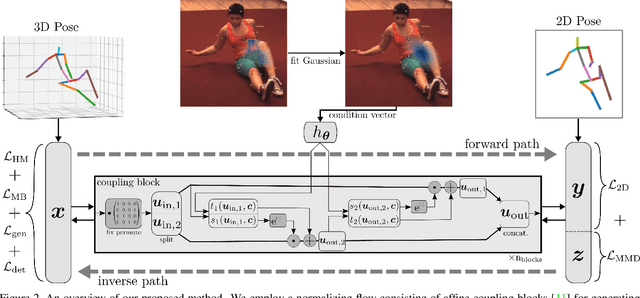

3D human pose estimation from monocular images is a highly ill-posed problem due to depth ambiguities and occlusions. Nonetheless, most existing works ignore these ambiguities and only estimate a single solution. In contrast, we generate a diverse set of hypotheses that represents the full posterior distribution of feasible 3D poses. To this end, we propose a normalizing flow based method that exploits the deterministic 3D-to-2D mapping to solve the ambiguous inverse 2D-to-3D problem. Additionally, uncertain detections and occlusions are effectively modeled by incorporating uncertainty information of the 2D detector as condition. Further keys to success are a learned 3D pose prior and a generalization of the best-of-M loss. We evaluate our approach on the two benchmark datasets Human3.6M and MPI-INF-3DHP, outperforming all comparable methods in most metrics. The implementation is available on GitHub.
Prediction of Metacarpophalangeal joint angles and Classification of Hand configurations based on Ultrasound Imaging of the Forearm
Sep 23, 2021

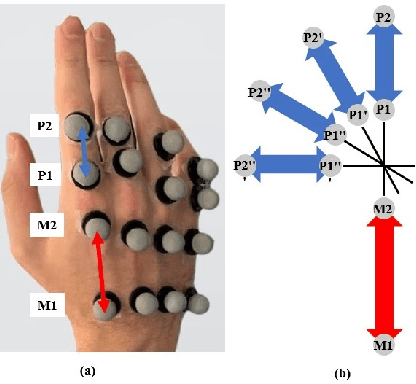
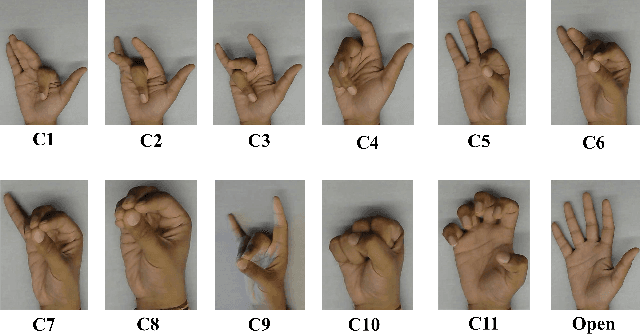
With the advancement in computing and robotics, it is necessary to develop fluent and intuitive methods for interacting with digital systems, AR/VR interfaces, and physical robotic systems. Hand movement recognition is widely used to enable this interaction. Hand configuration classification and Metacarpophalangeal (MCP) joint angle detection are important for a comprehensive reconstruction of the hand motion. Surface electromyography and other technologies have been used for the detection of hand motions. Ultrasound images of the forearm offer a way to visualize the internal physiology of the hand from a musculoskeletal perspective. Recent work has shown that these images can be classified using machine learning to predict various hand configurations. In this paper, we propose a Convolutional Neural Network (CNN) based deep learning pipeline for predicting the MCP joint angles. We supplement our results by using a Support Vector Classifier (SVC) to classify the ultrasound information into several predefined hand configurations based on activities of daily living (ADL). Ultrasound data from the forearm was obtained from 6 subjects who were instructed to move their hands according to predefined hand configurations relevant to ADLs. Motion capture data was acquired as the ground truth for hand movements at different speeds (0.5 Hz, 1 Hz, & 2 Hz) for the index, middle, ring, and pinky fingers. We were able to get promising SVC classification results on a subset of our collected data set. We demonstrated a correspondence between the predicted MCP joint angles and the actual MCP joint angles for the fingers, with an average root mean square error of 7.35 degrees. We implemented a low latency (6.25 - 9.1 Hz) pipeline for the prediction of both MCP joint angles and hand configuration estimation aimed at real-time control of digital devices, AR/VR interfaces, and physical robots.