 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Table Caption Generation in Scholarly Documents Leveraging Pre-trained Language Models
Aug 18, 2021
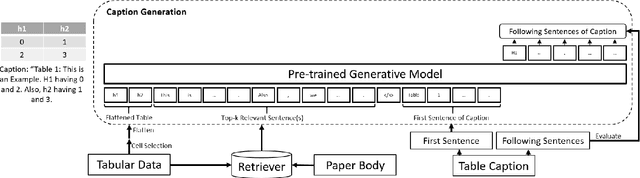

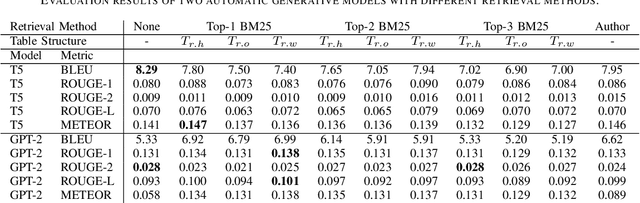
This paper addresses the problem of generating table captions for scholarly documents, which often require additional information outside the table. To this end, we propose a method of retrieving relevant sentences from the paper body, and feeding the table content as well as the retrieved sentences into pre-trained language models (e.g. T5 and GPT-2) for generating table captions. The contributions of this paper are: (1) discussion on the challenges in table captioning for scholarly documents; (2) development of a dataset DocBank-TB, which is publicly available; and (3) comparison of caption generation methods for scholarly documents with different strategies to retrieve relevant sentences from the paper body. Our experimental results showed that T5 is the better generation model for this task, as it outperformed GPT-2 in BLEU and METEOR implying that the generated text are clearer and more precise. Moreover, inputting relevant sentences matching the row header or whole table is effective.
Contrastive Learning with Temporal Correlated Medical Images: A Case Study using Lung Segmentation in Chest X-Rays
Sep 07, 2021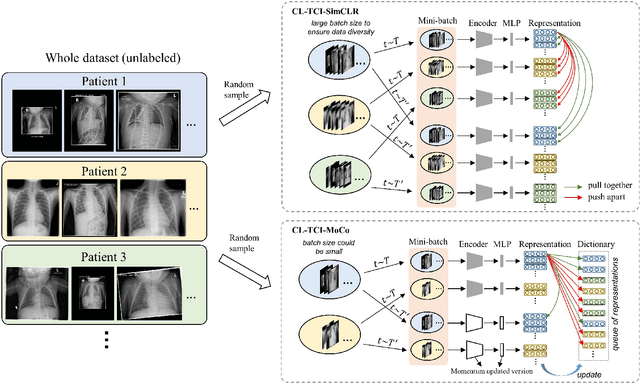
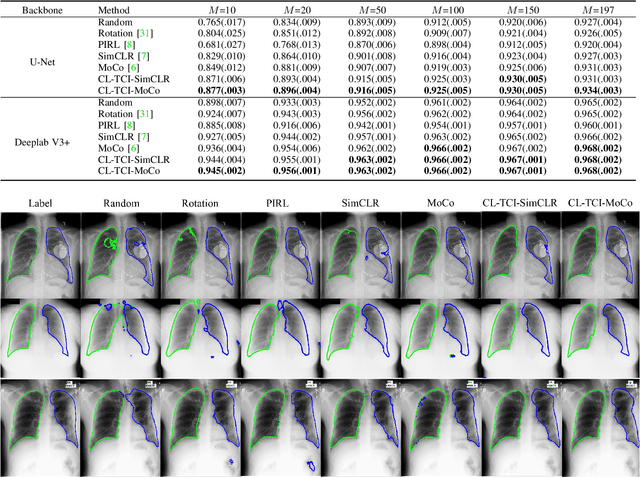
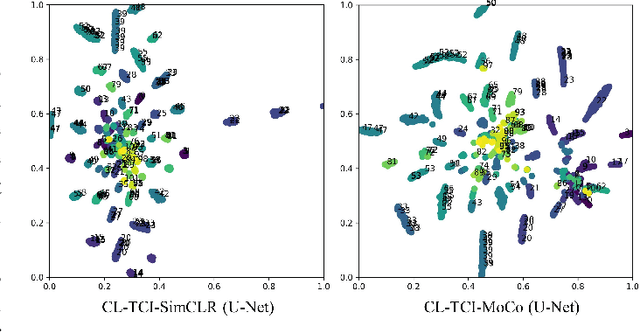
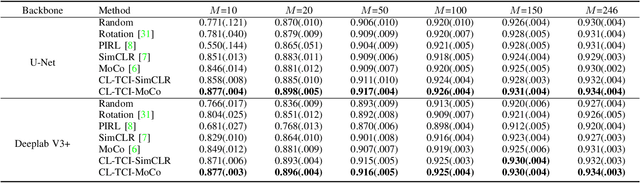
Contrastive learning has been proved to be a promising technique for image-level representation learning from unlabeled data. Many existing works have demonstrated improved results by applying contrastive learning in classification and object detection tasks for either natural images or medical images. However, its application to medical image segmentation tasks has been limited. In this work, we use lung segmentation in chest X-rays as a case study and propose a contrastive learning framework with temporal correlated medical images, named CL-TCI, to learn superior encoders for initializing the segmentation network. We adapt CL-TCI from two state-of-the-art contrastive learning methods-MoCo and SimCLR. Experiment results on three chest X-ray datasets show that under two different segmentation backbones, U-Net and Deeplab-V3, CL-TCI can outperform all baselines that do not incorporate any temporal correlation in both semi-supervised learning setting and transfer learning setting with limited annotation. This suggests that information among temporal correlated medical images can indeed improve contrastive learning performance. Between the two variations of CL-TCI, CL-TCI adapted from MoCo outperforms CL-TCI adapted from SimCLR in most settings, indicating that more contrastive samples can benefit the learning process and help the network learn high-quality representations.
Large-scale quantum machine learning
Aug 25, 2021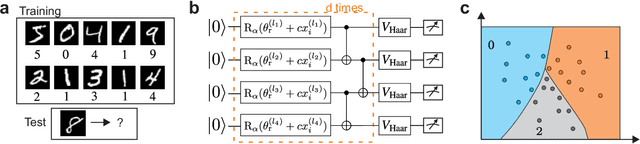
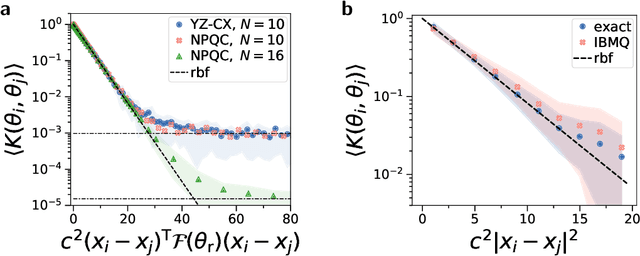
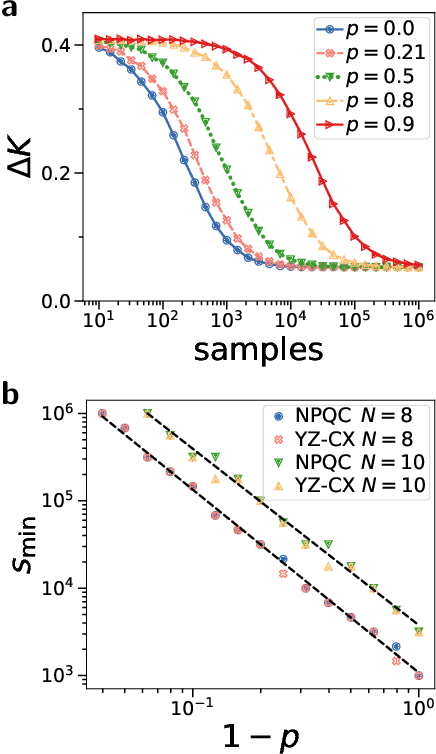
Quantum computers promise to enhance machine learning for practical applications. Quantum machine learning for real-world data has to handle extensive amounts of high-dimensional data. However, conventional methods for measuring quantum kernels are impractical for large datasets as they scale with the square of the dataset size. Here, we measure quantum kernels using randomized measurements to gain a quadratic speedup in computation time and quickly process large datasets. Further, we efficiently encode high-dimensional data into quantum computers with the number of features scaling linearly with the circuit depth. The encoding is characterized by the quantum Fisher information metric and is related to the radial basis function kernel. We demonstrate the advantages of our methods by classifying images with the IBM quantum computer. To achieve further speedups we distribute the quantum computational tasks between different quantum computers. Our approach is exceptionally robust to noise via a complementary error mitigation scheme. Using currently available quantum computers, the MNIST database can be processed within 220 hours instead of 10 years which opens up industrial applications of quantum machine learning.
Reasoning on $\textit{DL-Lite}_{\cal R}$ with Defeasibility in ASP
Jun 30, 2021


Reasoning on defeasible knowledge is a topic of interest in the area of description logics, as it is related to the need of representing exceptional instances in knowledge bases. In this direction, in our previous works we presented a framework for representing (contextualized) OWL RL knowledge bases with a notion of justified exceptions on defeasible axioms: reasoning in such framework is realized by a translation into ASP programs. The resulting reasoning process for OWL RL, however, introduces a complex encoding in order to capture reasoning on the negative information needed for reasoning on exceptions. In this paper, we apply the justified exception approach to knowledge bases in $\textit{DL-Lite}_{\cal R}$, i.e., the language underlying OWL QL. We provide a definition for $\textit{DL-Lite}_{\cal R}$ knowledge bases with defeasible axioms and study their semantic and computational properties. In particular, we study the effects of exceptions over unnamed individuals. The limited form of $\textit{DL-Lite}_{\cal R}$ axioms allows us to formulate a simpler ASP encoding, where reasoning on negative information is managed by direct rules. The resulting materialization method gives rise to a complete reasoning procedure for instance checking in $\textit{DL-Lite}_{\cal R}$ with defeasible axioms. Under consideration in Theory and Practice of Logic Programming (TPLP).
Robust Neural Abstractive Summarization Systems and Evaluation against Adversarial Information
Oct 14, 2018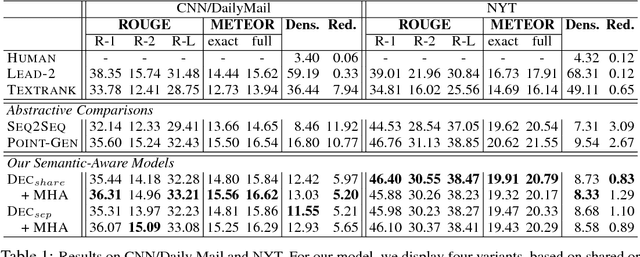
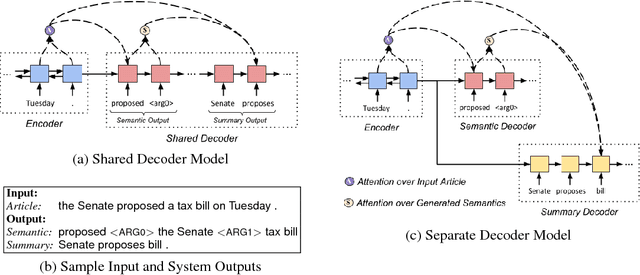
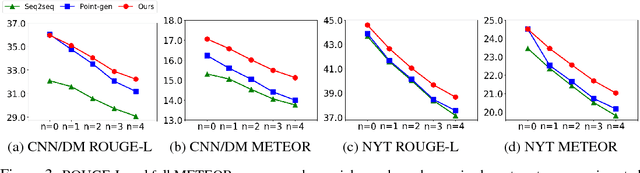
Sequence-to-sequence (seq2seq) neural models have been actively investigated for abstractive summarization. Nevertheless, existing neural abstractive systems frequently generate factually incorrect summaries and are vulnerable to adversarial information, suggesting a crucial lack of semantic understanding. In this paper, we propose a novel semantic-aware neural abstractive summarization model that learns to generate high quality summaries through semantic interpretation over salient content. A novel evaluation scheme with adversarial samples is introduced to measure how well a model identifies off-topic information, where our model yields significantly better performance than the popular pointer-generator summarizer. Human evaluation also confirms that our system summaries are uniformly more informative and faithful as well as less redundant than the seq2seq model.
DiffCloth: Differentiable Cloth Simulation with Dry Frictional Contact
Jun 09, 2021
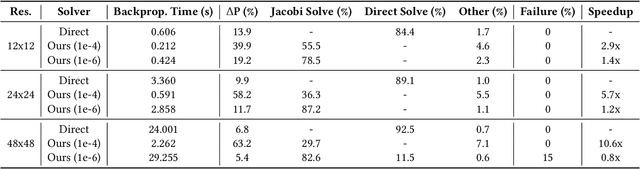
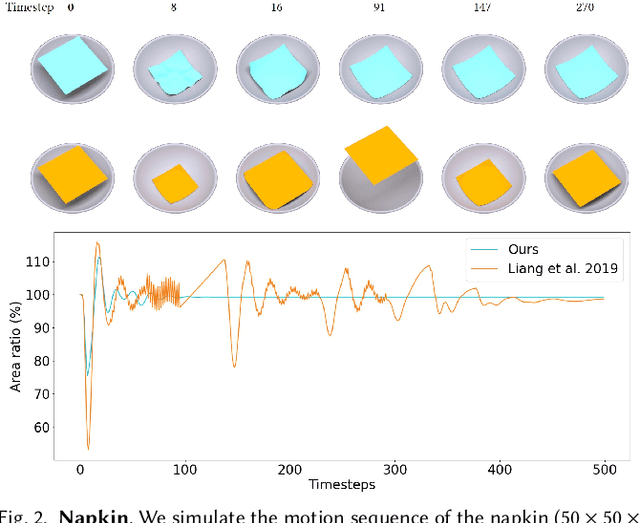
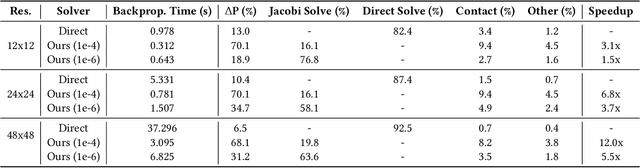
Cloth simulation has wide applications including computer animation, garment design, and robot-assisted dressing. In this work, we present a differentiable cloth simulator whose additional gradient information facilitates cloth-related applications. Our differentiable simulator extends the state-of-the-art cloth simulator based on Projective Dynamics and with dry frictional contact governed by the Signorini-Coulomb law. We derive gradients with contact in this forward simulation framework and speed up the computation with Jacobi iteration inspired by previous differentiable simulation work. To our best knowledge, we present the first differentiable cloth simulator with the Coulomb law of friction. We demonstrate the efficacy of our simulator in various applications, including system identification, manipulation, inverse design, and a real-to-sim task. Many of our applications have not been demonstrated in previous differentiable cloth simulators. The gradient information from our simulator enables efficient gradient-based task solvers from which we observe a substantial speedup over standard gradient-free methods.
Temporal envelope and fine structure cues for dysarthric speech detection using CNNs
Aug 25, 2021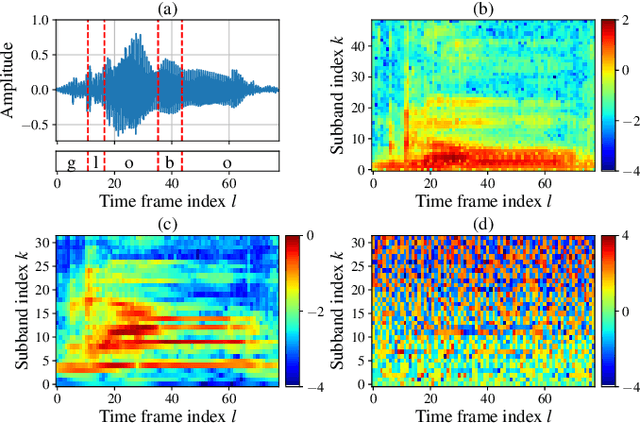
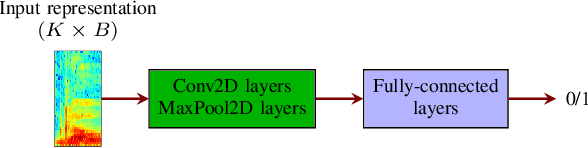
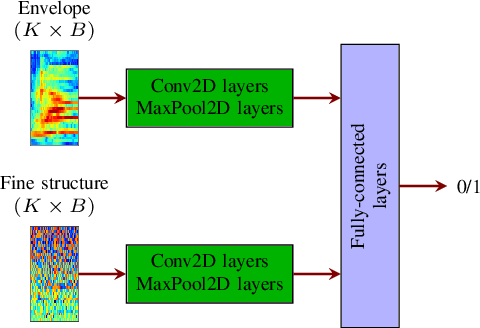
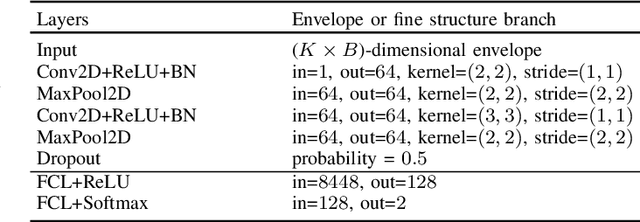
Deep learning-based techniques for automatic dysarthric speech detection have recently attracted interest in the research community. State-of-the-art techniques typically learn neurotypical and dysarthric discriminative representations by processing time-frequency input representations such as the magnitude spectrum of the short-time Fourier transform (STFT). Although these techniques are expected to leverage perceptual dysarthric cues, representations such as the magnitude spectrum of the STFT do not necessarily convey perceptual aspects of complex sounds. Inspired by the temporal processing mechanisms of the human auditory system, in this paper we factor signals into the product of a slowly varying envelope and a rapidly varying fine structure. Separately exploiting the different perceptual cues present in the envelope (i.e., phonetic information, stress, and voicing) and fine structure (i.e., pitch, vowel quality, and breathiness), two discriminative representations are learned through a convolutional neural network and used for automatic dysarthric speech detection. Experimental results show that processing both the envelope and fine structure representations yields a considerably better dysarthric speech detection performance than processing only the envelope, fine structure, or magnitude spectrum of the STFT representation.
PortaSpeech: Portable and High-Quality Generative Text-to-Speech
Sep 30, 2021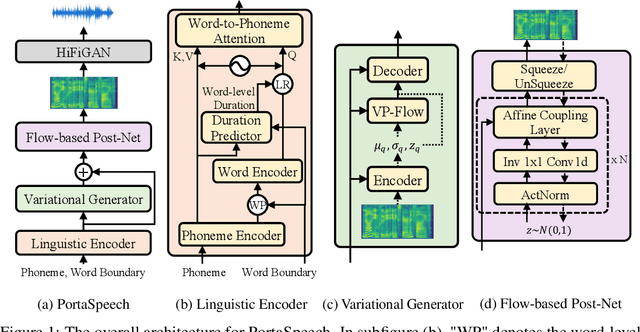
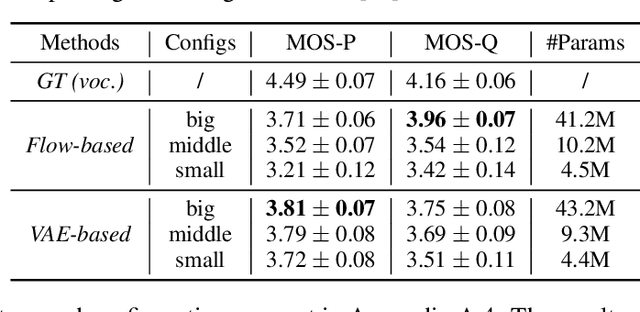
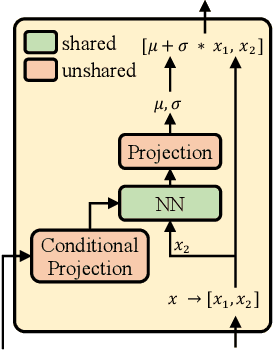
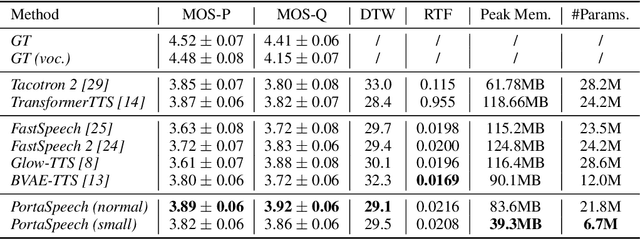
Non-autoregressive text-to-speech (NAR-TTS) models such as FastSpeech 2 and Glow-TTS can synthesize high-quality speech from the given text in parallel. After analyzing two kinds of generative NAR-TTS models (VAE and normalizing flow), we find that: VAE is good at capturing the long-range semantics features (e.g., prosody) even with small model size but suffers from blurry and unnatural results; and normalizing flow is good at reconstructing the frequency bin-wise details but performs poorly when the number of model parameters is limited. Inspired by these observations, to generate diverse speech with natural details and rich prosody using a lightweight architecture, we propose PortaSpeech, a portable and high-quality generative text-to-speech model. Specifically, 1) to model both the prosody and mel-spectrogram details accurately, we adopt a lightweight VAE with an enhanced prior followed by a flow-based post-net with strong conditional inputs as the main architecture. 2) To further compress the model size and memory footprint, we introduce the grouped parameter sharing mechanism to the affine coupling layers in the post-net. 3) To improve the expressiveness of synthesized speech and reduce the dependency on accurate fine-grained alignment between text and speech, we propose a linguistic encoder with mixture alignment combining hard inter-word alignment and soft intra-word alignment, which explicitly extracts word-level semantic information. Experimental results show that PortaSpeech outperforms other TTS models in both voice quality and prosody modeling in terms of subjective and objective evaluation metrics, and shows only a slight performance degradation when reducing the model parameters to 6.7M (about 4x model size and 3x runtime memory compression ratio compared with FastSpeech 2). Our extensive ablation studies demonstrate that each design in PortaSpeech is effective.
Information-Guided Robotic Maximum Seek-and-Sample in Partially Observable Continuous Environments
Sep 26, 2019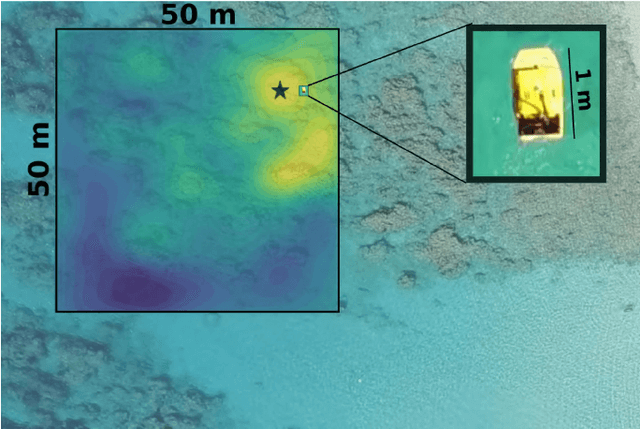
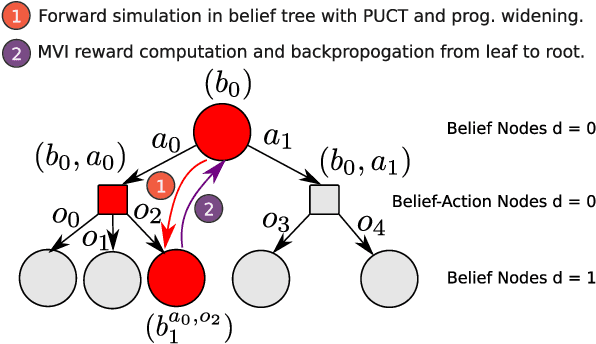
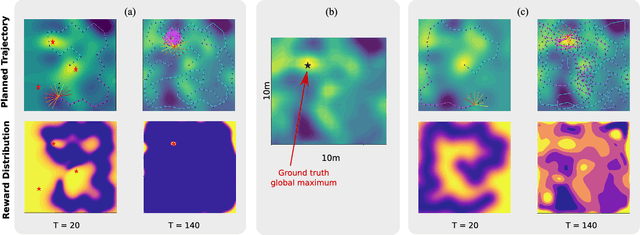

We present PLUMES, a planner to localizing and collecting samples at the global maximum of an a priori unknown and partially observable continuous environment. The "maximum-seek-and-sample" (MSS) problem is pervasive in the environmental and earth sciences. Experts want to collect scientifically valuable samples at an environmental maximum (e.g., an oil-spill source), but do not have prior knowledge about the phenomenon's distribution. We formulate the MSS problem as a partially-observable Markov decision process (POMDP) with continuous state and observation spaces, and a sparse reward signal. To solve the MSS POMDP, PLUMES uses an information-theoretic reward heuristic with continous-observation Monte Carlo Tree Search to efficiently localize and sample from the global maximum. In simulation and field experiments, PLUMES collects more scientifically valuable samples than state-of-the-art planners in a diverse set of environments, with various platforms, sensors, and challenging real-world conditions.
* 8 pages, 8 figures, To appear in the proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2019 Macau
Automatic Online Multi-Source Domain Adaptation
Sep 12, 2021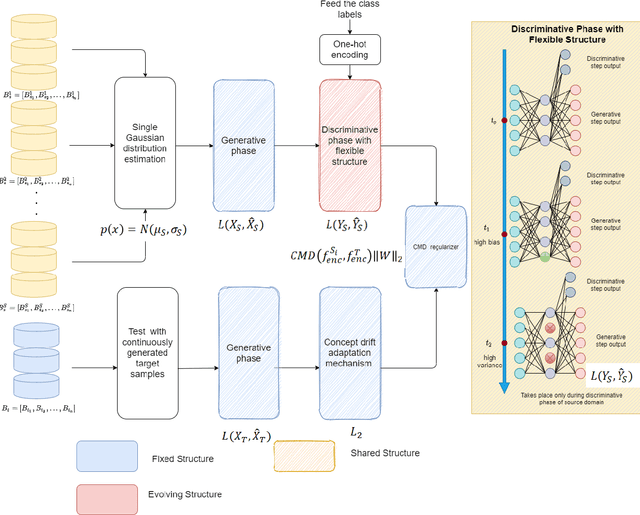
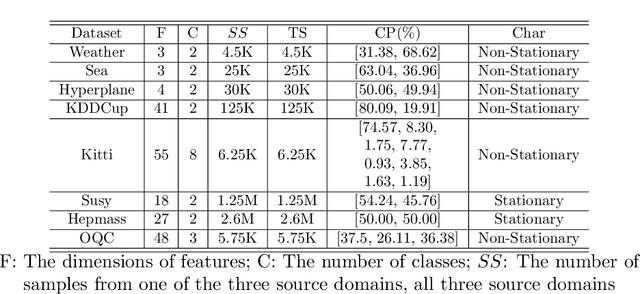
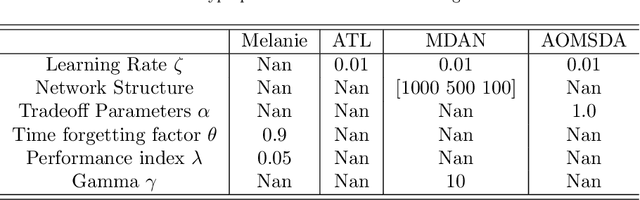
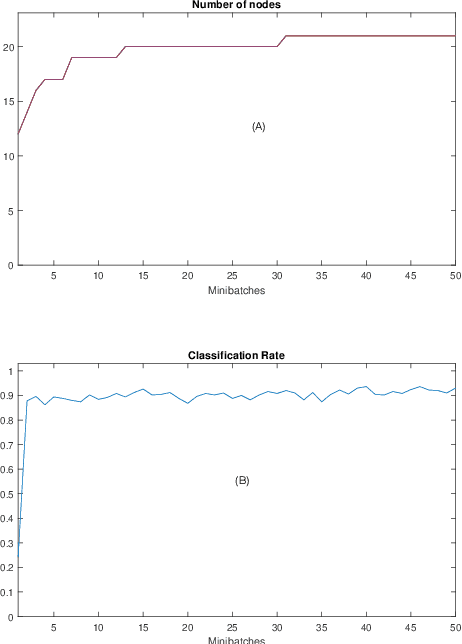
Knowledge transfer across several streaming processes remain challenging problem not only because of different distributions of each stream but also because of rapidly changing and never-ending environments of data streams. Albeit growing research achievements in this area, most of existing works are developed for a single source domain which limits its resilience to exploit multi-source domains being beneficial to recover from concept drifts quickly and to avoid the negative transfer problem. An online domain adaptation technique under multisource streaming processes, namely automatic online multi-source domain adaptation (AOMSDA), is proposed in this paper. The online domain adaptation strategy of AOMSDA is formulated under a coupled generative and discriminative approach of denoising autoencoder (DAE) where the central moment discrepancy (CMD)-based regularizer is integrated to handle the existence of multi-source domains thereby taking advantage of complementary information sources. The asynchronous concept drifts taking place at different time periods are addressed by a self-organizing structure and a node re-weighting strategy. Our numerical study demonstrates that AOMSDA is capable of outperforming its counterparts in 5 of 8 study cases while the ablation study depicts the advantage of each learning component. In addition, AOMSDA is general for any number of source streams. The source code of AOMSDA is shared publicly in https://github.com/Renchunzi-Xie/AOMSDA.git.