 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MIHash: Online Hashing with Mutual Information
Jul 29, 2017
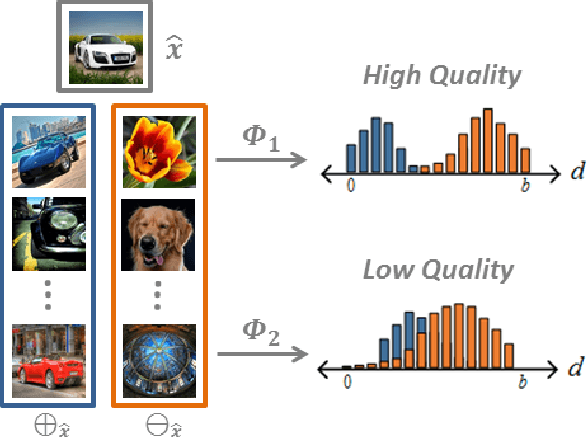
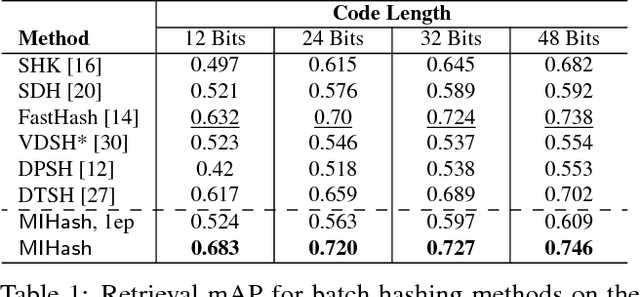
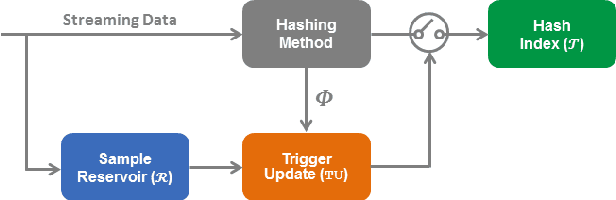
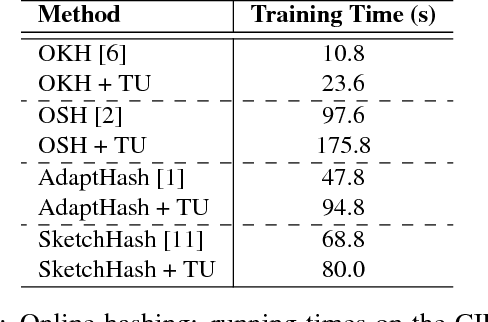
Learning-based hashing methods are widely used for nearest neighbor retrieval, and recently, online hashing methods have demonstrated good performance-complexity trade-offs by learning hash functions from streaming data. In this paper, we first address a key challenge for online hashing: the binary codes for indexed data must be recomputed to keep pace with updates to the hash functions. We propose an efficient quality measure for hash functions, based on an information-theoretic quantity, mutual information, and use it successfully as a criterion to eliminate unnecessary hash table updates. Next, we also show how to optimize the mutual information objective using stochastic gradient descent. We thus develop a novel hashing method, MIHash, that can be used in both online and batch settings. Experiments on image retrieval benchmarks (including a 2.5M image dataset) confirm the effectiveness of our formulation, both in reducing hash table recomputations and in learning high-quality hash functions.
An Upper Limit of Decaying Rate with Respect to Frequency in Deep Neural Network
May 25, 2021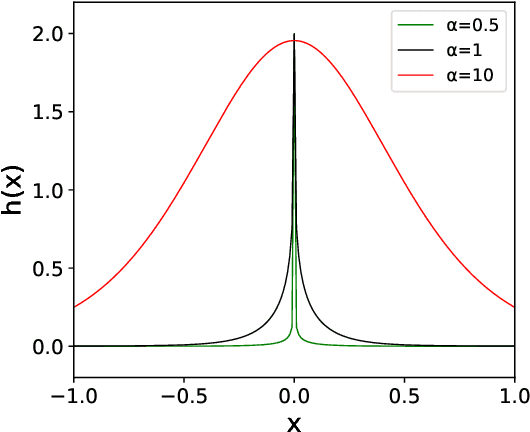
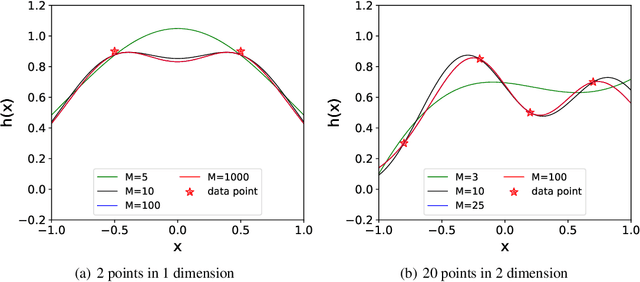
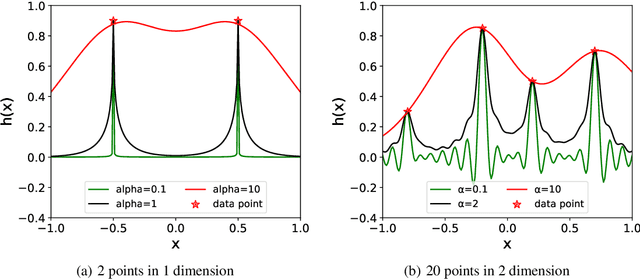
Deep neural network (DNN) usually learns the target function from low to high frequency, which is called frequency principle or spectral bias. This frequency principle sheds light on a high-frequency curse of DNNs -- difficult to learn high-frequency information. Inspired by the frequency principle, a series of works are devoted to develop algorithms for overcoming the high-frequency curse. A natural question arises: what is the upper limit of the decaying rate w.r.t. frequency when one trains a DNN? In this work, our theory, confirmed by numerical experiments, suggests that there is a critical decaying rate w.r.t. frequency in DNN training. Below the upper limit of the decaying rate, the DNN interpolates the training data by a function with a certain regularity. However, above the upper limit, the DNN interpolates the training data by a trivial function, i.e., a function is only non-zero at training data points. Our results indicate a better way to overcome the high-frequency curse is to design a proper pre-condition approach to shift high-frequency information to low-frequency one, which coincides with several previous developed algorithms for fast learning high-frequency information. More importantly, this work rigorously proves that the high-frequency curse is an intrinsic difficulty of DNNs.
Information Bottleneck Methods for Distributed Learning
Oct 26, 2018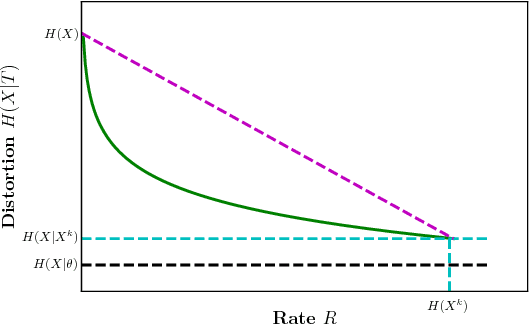
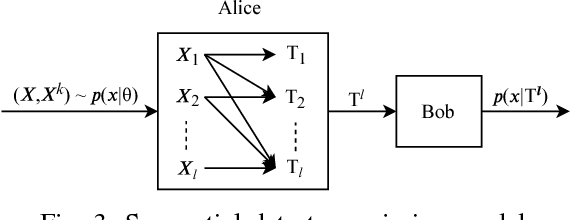
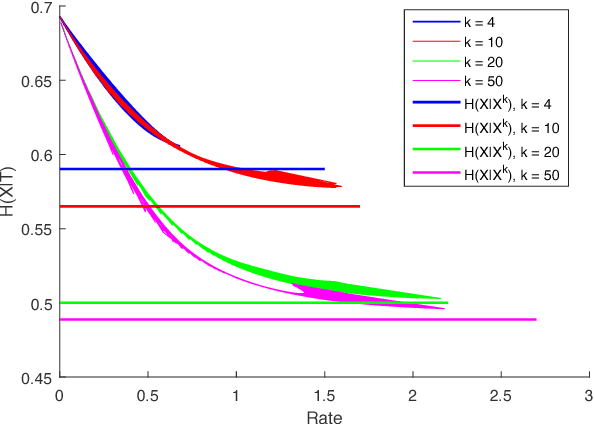
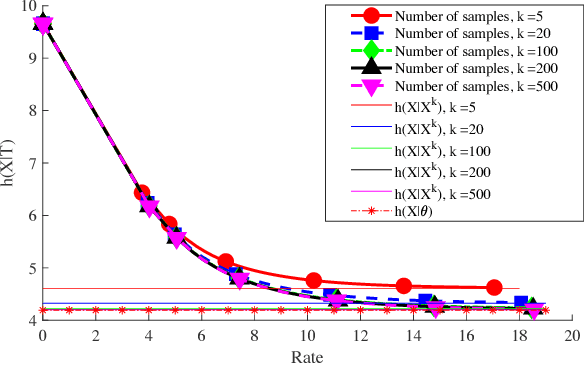
We study a distributed learning problem in which Alice sends a compressed distillation of a set of training data to Bob, who uses the distilled version to best solve an associated learning problem. We formalize this as a rate-distortion problem in which the training set is the source and Bob's cross-entropy loss is the distortion measure. We consider this problem for unsupervised learning for batch and sequential data. In the batch data, this problem is equivalent to the information bottleneck (IB), and we show that reduced-complexity versions of standard IB methods solve the associated rate-distortion problem. For the streaming data, we present a new algorithm, which may be of independent interest, that solves the rate-distortion problem for Gaussian sources. Furthermore, to improve the results of the iterative algorithm for sequential data we introduce a two-pass version of this algorithm. Finally, we show the dependency of the rate on the number of samples $k$ required for Gaussian sources to ensure cross-entropy loss that scales optimally with the growth of the training set.
ACFNet: Adaptively-Cooperative Fusion Network for RGB-D Salient Object Detection
Sep 10, 2021
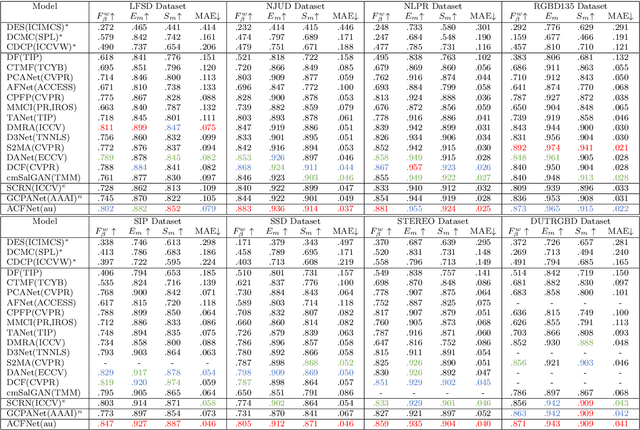
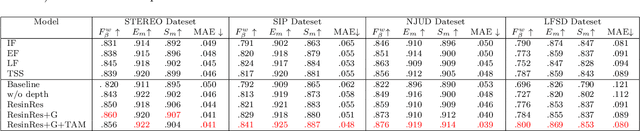
The reasonable employment of RGB and depth data show great significance in promoting the development of computer vision tasks and robot-environment interaction. However, there are different advantages and disadvantages in the early and late fusion of the two types of data. Besides, due to the diversity of object information, using a single type of data in a specific scenario tends to result in semantic misleading. Based on the above considerations, we propose an adaptively-cooperative fusion network (ACFNet) with ResinRes structure for salient object detection. This structure is designed to flexibly utilize the advantages of feature fusion in early and late stages. Secondly, an adaptively-cooperative semantic guidance (ACG) scheme is designed to suppress inaccurate features in the guidance phase. Further, we proposed a type-based attention module (TAM) to optimize the network and enhance the multi-scale perception of different objects. For different objects, the features generated by different types of convolution are enhanced or suppressed by the gated mechanism for segmentation optimization. ACG and TAM optimize the transfer of feature streams according to their data attributes and convolution attributes, respectively. Sufficient experiments conducted on RGB-D SOD datasets illustrate that the proposed network performs favorably against 18 state-of-the-art algorithms.
Feedback Pyramid Attention Networks for Single Image Super-Resolution
Jun 13, 2021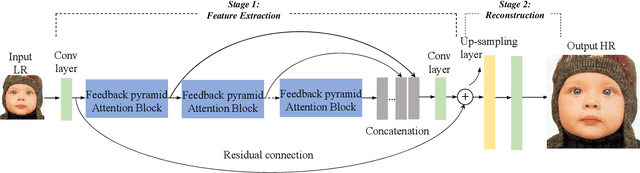
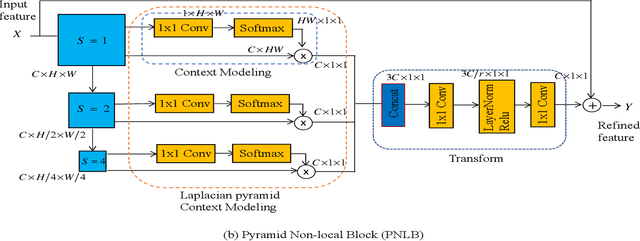

Recently, convolutional neural network (CNN) based image super-resolution (SR) methods have achieved significant performance improvement. However, most CNN-based methods mainly focus on feed-forward architecture design and neglect to explore the feedback mechanism, which usually exists in the human visual system. In this paper, we propose feedback pyramid attention networks (FPAN) to fully exploit the mutual dependencies of features. Specifically, a novel feedback connection structure is developed to enhance low-level feature expression with high-level information. In our method, the output of each layer in the first stage is also used as the input of the corresponding layer in the next state to re-update the previous low-level filters. Moreover, we introduce a pyramid non-local structure to model global contextual information in different scales and improve the discriminative representation of the network. Extensive experimental results on various datasets demonstrate the superiority of our FPAN in comparison with the state-of-the-art SR methods.
Non-imaging real-time detection and tracking of fast-moving objects using a single-pixel detector
Sep 10, 2021

Detection and tracking of fast-moving objects have widespread utility in many fields. However, fulfilling this demand for fast and efficient detecting and tracking using image-based techniques is problematic, owing to the complex calculations and limited data processing capabilities. To tackle this problem, we propose an image-free method to achieve real-time detection and tracking of fast-moving objects. It employs the Hadamard pattern to illuminate the fast-moving object by a spatial light modulator, in which the resulting light signal is collected by a single-pixel detector. The single-pixel measurement values are directly used to reconstruct the position information without image reconstruction. Furthermore, a new sampling method is used to optimize the pattern projection way for achieving an ultra-low sampling rate. Compared with the state-of-the-art methods, our approach is not only capable of handling real-time detection and tracking, but also it has a small amount of calculation and high efficiency. We experimentally demonstrate that the proposed method, using a 22kHz digital micro-mirror device, can implement a 105fps frame rate at a 1.28% sampling rate when tracks. Our method breaks through the traditional tracking ways, which can implement the object real-time tracking without image reconstruction.
Preview, Attend and Review: Schema-Aware Curriculum Learning for Multi-Domain Dialog State Tracking
Jun 01, 2021
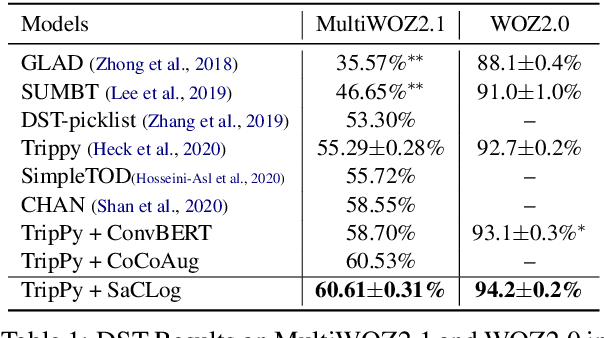
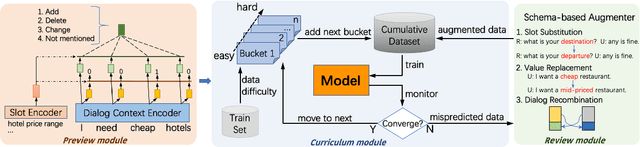
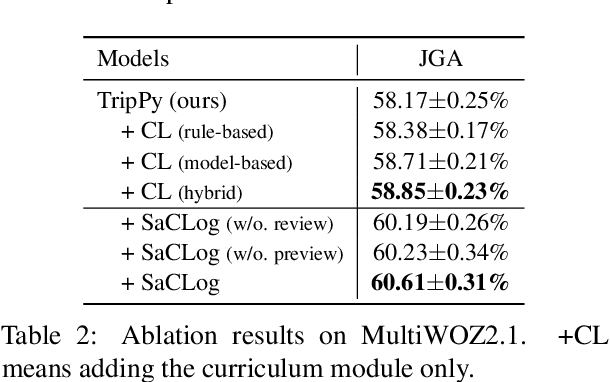
Existing dialog state tracking (DST) models are trained with dialog data in a random order, neglecting rich structural information in a dataset. In this paper, we propose to use curriculum learning (CL) to better leverage both the curriculum structure and schema structure for task-oriented dialogs. Specifically, we propose a model-agnostic framework called Schema-aware Curriculum Learning for Dialog State Tracking (SaCLog), which consists of a preview module that pre-trains a DST model with schema information, a curriculum module that optimizes the model with CL, and a review module that augments mispredicted data to reinforce the CL training. We show that our proposed approach improves DST performance over both a transformer-based and RNN-based DST model (TripPy and TRADE) and achieves new state-of-the-art results on WOZ2.0 and MultiWOZ2.1.
Trade When Opportunity Comes: Price Movement Forecasting via Locality-Aware Attention and Adaptive Refined Labeling
Jul 26, 2021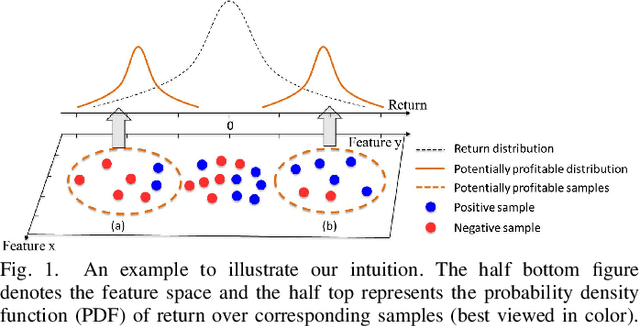
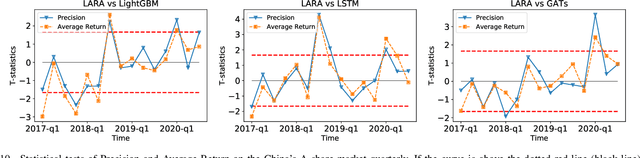
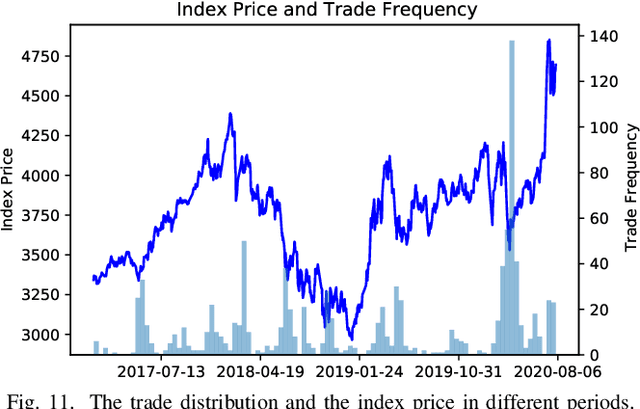
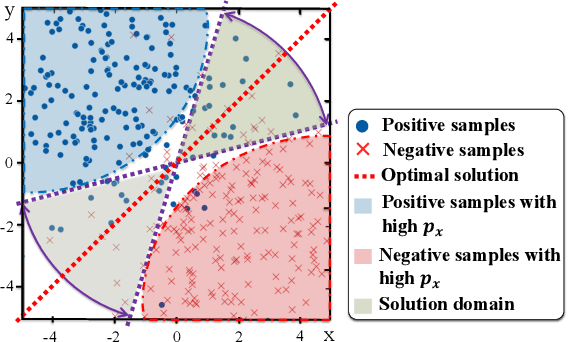
Price movement forecasting aims at predicting the future trends of financial assets based on the current market conditions and other relevant information. Recently, machine learning(ML) methods have become increasingly popular and achieved promising results for price movement forecasting in both academia and industry. Most existing ML solutions formulate the forecasting problem as a classification(to predict the direction) or a regression(to predict the return) problem in the entire set of training data. However, due to the extremely low signal-to-noise ratio and stochastic nature of financial data, good trading opportunities are extremely scarce. As a result, without careful selection of potentially profitable samples, such ML methods are prone to capture the patterns of noises instead of real signals. To address the above issues, we propose a novel framework-LARA(Locality-Aware Attention and Adaptive Refined Labeling), which contains the following three components: 1)Locality-aware attention automatically extracts the potentially profitable samples by attending to their label information in order to construct a more accurate classifier on these selected samples. 2)Adaptive refined labeling further iteratively refines the labels, alleviating the noise of samples. 3)Equipped with metric learning techniques, Locality-aware attention enjoys task-specific distance metrics and distributes attention on potentially profitable samples in a more effective way. To validate our method, we conduct comprehensive experiments on three real-world financial markets: ETFs, the China's A-share stock market, and the cryptocurrency market. LARA achieves superior performance compared with the time-series analysis methods and a set of machine learning based competitors on the Qlib platform. Extensive ablation studies and experiments demonstrate that LARA indeed captures more reliable trading opportunities.
Two-stream Convolutional Networks for Multi-frame Face Anti-spoofing
Aug 09, 2021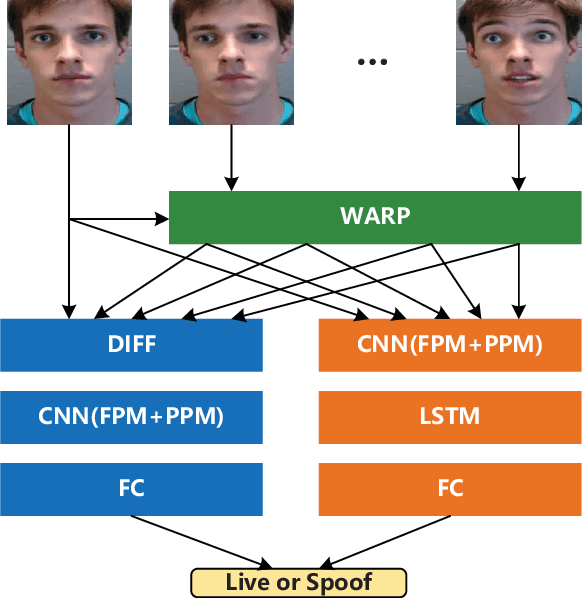
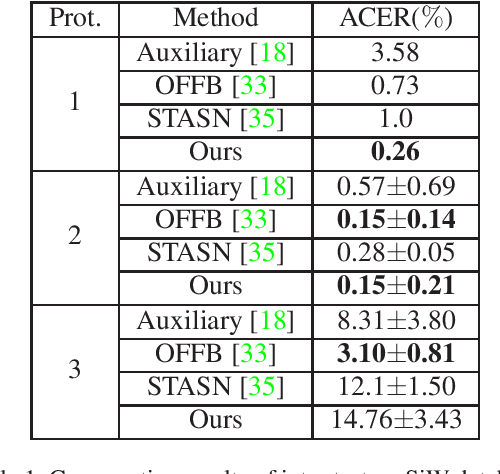
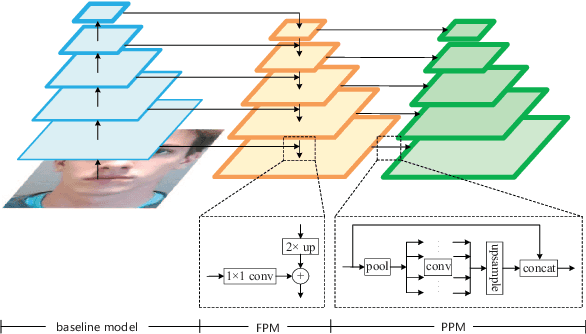
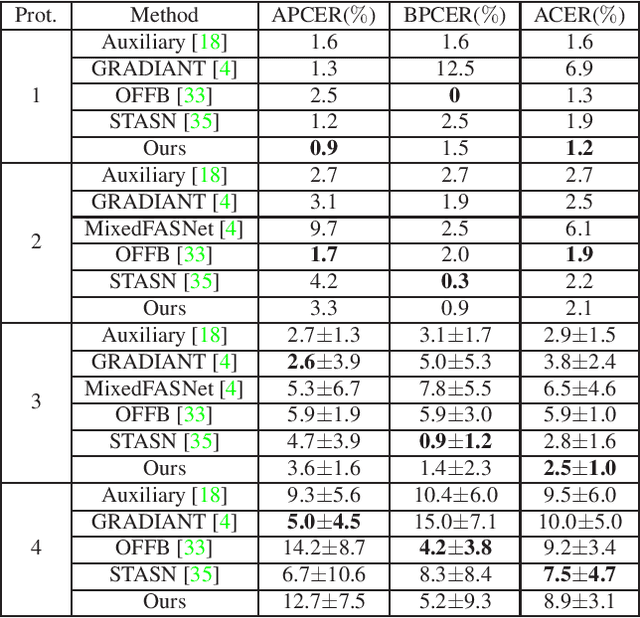
Face anti-spoofing is an important task to protect the security of face recognition. Most of previous work either struggle to capture discriminative and generalizable feature or rely on auxiliary information which is unavailable for most of industrial product. Inspired by the video classification work, we propose an efficient two-stream model to capture the key differences between live and spoof faces, which takes multi-frames and RGB difference as input respectively. Feature pyramid modules with two opposite fusion directions and pyramid pooling modules are applied to enhance feature representation. We evaluate the proposed method on the datasets of Siw, Oulu-NPU, CASIA-MFSD and Replay-Attack. The results show that our model achieves the state-of-the-art results on most of datasets' protocol with much less parameter size.
Expert Knowledge-Guided Length-Variant Hierarchical Label Generation for Proposal Classification
Sep 15, 2021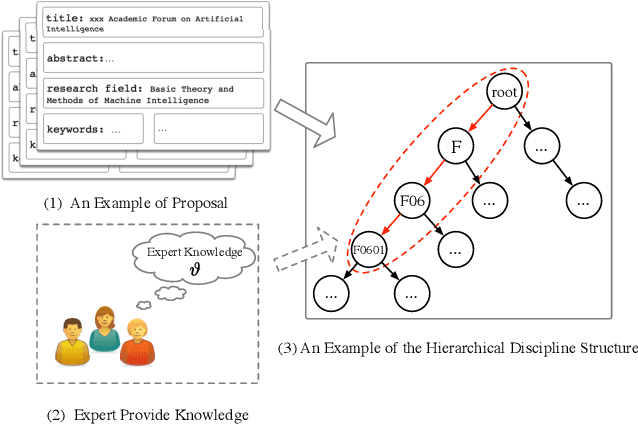
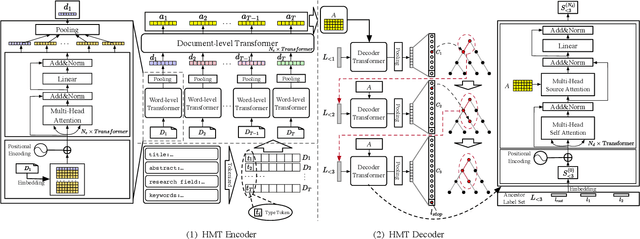
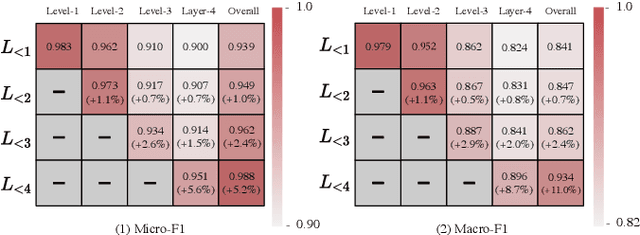
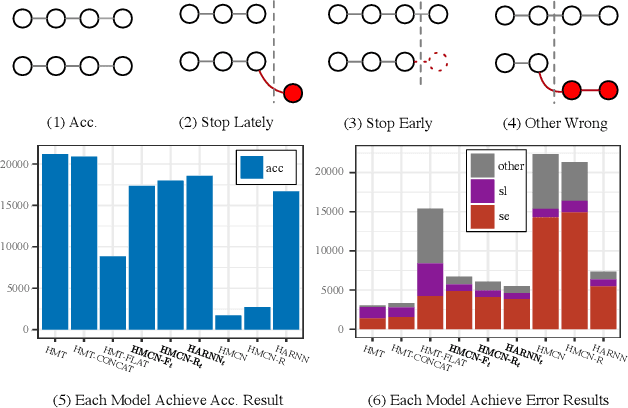
To advance the development of science and technology, research proposals are submitted to open-court competitive programs developed by government agencies (e.g., NSF). Proposal classification is one of the most important tasks to achieve effective and fair review assignments. Proposal classification aims to classify a proposal into a length-variant sequence of labels. In this paper, we formulate the proposal classification problem into a hierarchical multi-label classification task. Although there are certain prior studies, proposal classification exhibit unique features: 1) the classification result of a proposal is in a hierarchical discipline structure with different levels of granularity; 2) proposals contain multiple types of documents; 3) domain experts can empirically provide partial labels that can be leveraged to improve task performances. In this paper, we focus on developing a new deep proposal classification framework to jointly model the three features. In particular, to sequentially generate labels, we leverage previously-generated labels to predict the label of next level; to integrate partial labels from experts, we use the embedding of these empirical partial labels to initialize the state of neural networks. Our model can automatically identify the best length of label sequence to stop next label prediction. Finally, we present extensive results to demonstrate that our method can jointly model partial labels, textual information, and semantic dependencies in label sequences, and, thus, achieve advanced performances.