 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPerf Mobile Inference Benchmark: Why Mobile AI Benchmarking Is Hard and What to Do About It
Dec 03, 2020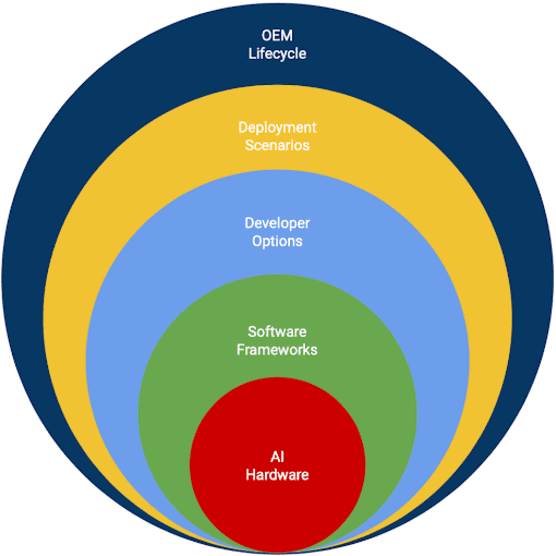

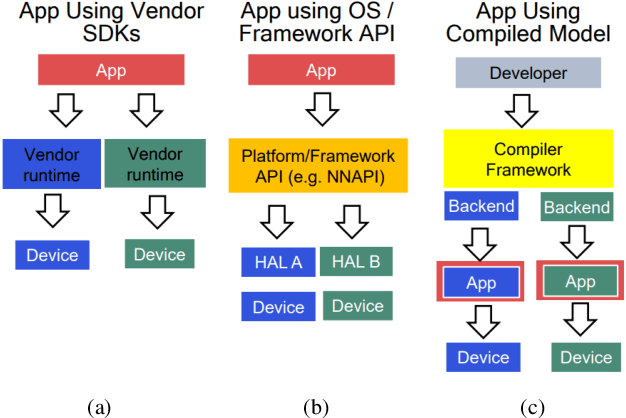
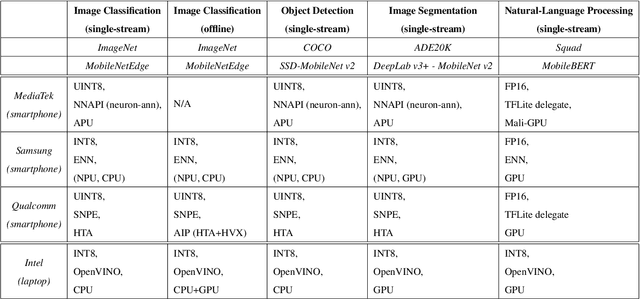
MLPerf Mobile is the first industry-standard open-source mobile benchmark developed by industry members and academic researchers to allow performance/accuracy evaluation of mobile devices with different AI chips and software stacks. The benchmark draws from the expertise of leading mobile-SoC vendors, ML-framework providers, and model producers. In this paper, we motivate the drive to demystify mobile-AI performance and present MLPerf Mobile's design considerations, architecture, and implementation. The benchmark comprises a suite of models that operate under standard models, data sets, quality metrics, and run rules. For the first iteration, we developed an app to provide an "out-of-the-box" inference-performance benchmark for computer vision and natural-language processing on mobile devices. MLPerf Mobile can serve as a framework for integrating future models, for customizing quality-target thresholds to evaluate system performance, for comparing software frameworks, and for assessing heterogeneous-hardware capabilities for machine learning, all fairly and faithfully with fully reproducible results.
Hashing as Tie-Aware Learning to Rank
Oct 09, 2018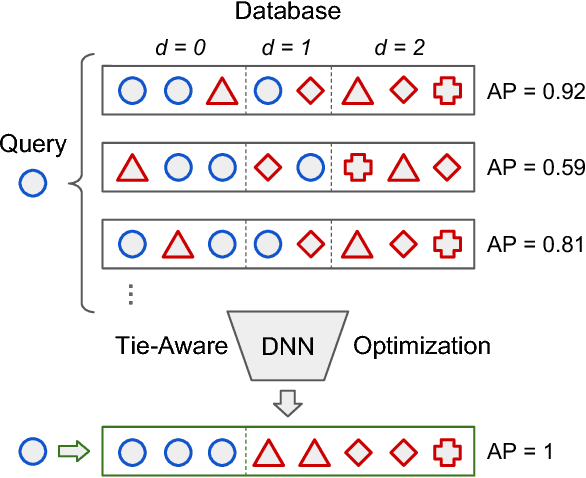
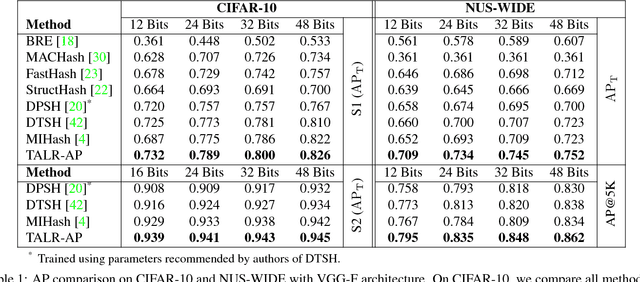
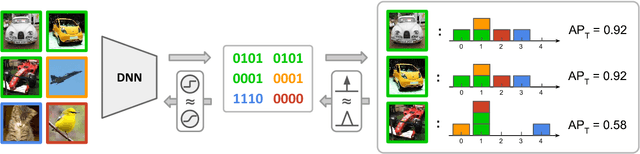
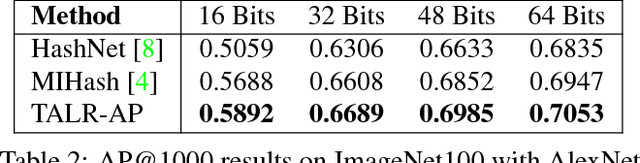
Hashing, or learning binary embeddings of data, is frequently used in nearest neighbor retrieval. In this paper, we develop learning to rank formulations for hashing, aimed at directly optimizing ranking-based evaluation metrics such as Average Precision (AP) and Normalized Discounted Cumulative Gain (NDCG). We first observe that the integer-valued Hamming distance often leads to tied rankings, and propose to use tie-aware versions of AP and NDCG to evaluate hashing for retrieval. Then, to optimize tie-aware ranking metrics, we derive their continuous relaxations, and perform gradient-based optimization with deep neural networks. Our results establish the new state-of-the-art for image retrieval by Hamming ranking in common benchmarks.
Hashing with Binary Matrix Pursuit
Aug 06, 2018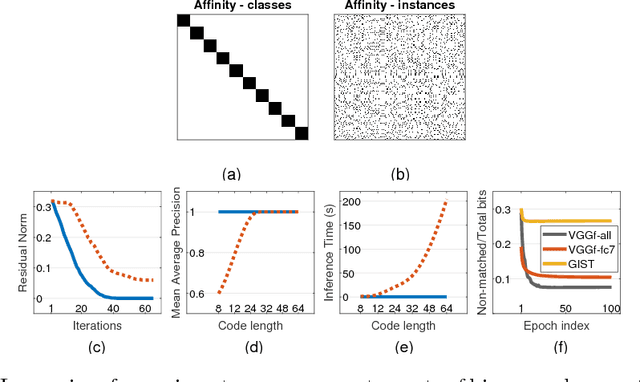
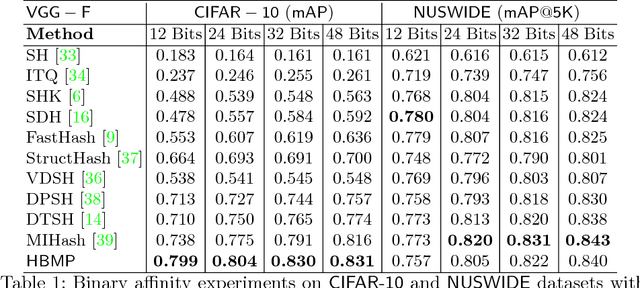
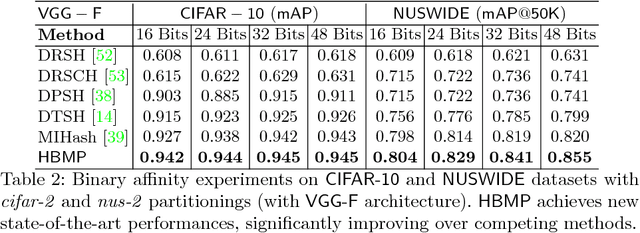
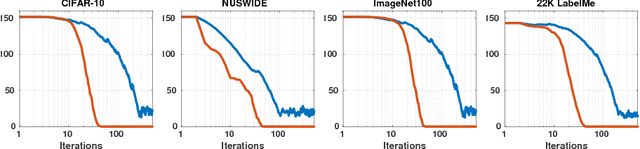
We propose theoretical and empirical improvements for two-stage hashing methods. We first provide a theoretical analysis on the quality of the binary codes and show that, under mild assumptions, a residual learning scheme can construct binary codes that fit any neighborhood structure with arbitrary accuracy. Secondly, we show that with high-capacity hash functions such as CNNs, binary code inference can be greatly simplified for many standard neighborhood definitions, yielding smaller optimization problems and more robust codes. Incorporating our findings, we propose a novel two-stage hashing method that significantly outperforms previous hashing studies on widely used image retrieval benchmarks.
Hashing with Mutual Information
Jun 25, 2018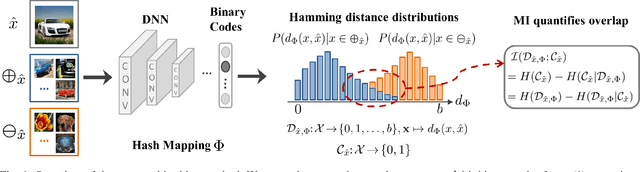
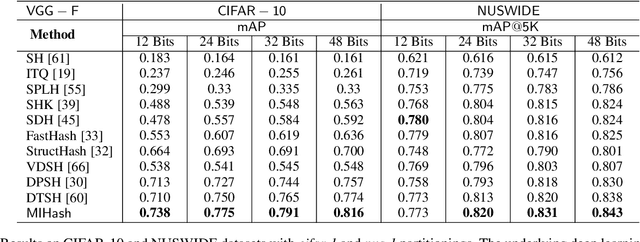
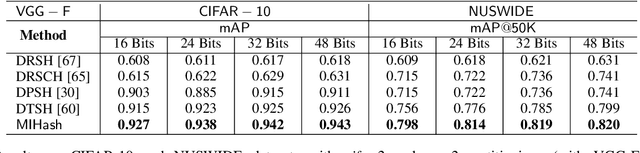
Binary vector embeddings enable fast nearest neighbor retrieval in large databases of high-dimensional objects, and play an important role in many practical applications, such as image and video retrieval. We study the problem of learning binary vector embeddings under a supervised setting, also known as hashing. We propose a novel supervised hashing method based on optimizing an information-theoretic quantity: mutual information. We show that optimizing mutual information can reduce ambiguity in the induced neighborhood structure in the learned Hamming space, which is essential in obtaining high retrieval performance. To this end, we optimize mutual information in deep neural networks with minibatch stochastic gradient descent, with a formulation that maximally and efficiently utilizes available supervision. Experiments on four image retrieval benchmarks, including ImageNet, confirm the effectiveness of our method in learning high-quality binary embeddings for nearest neighbor retrieval.
MIHash: Online Hashing with Mutual Information
Jul 29, 2017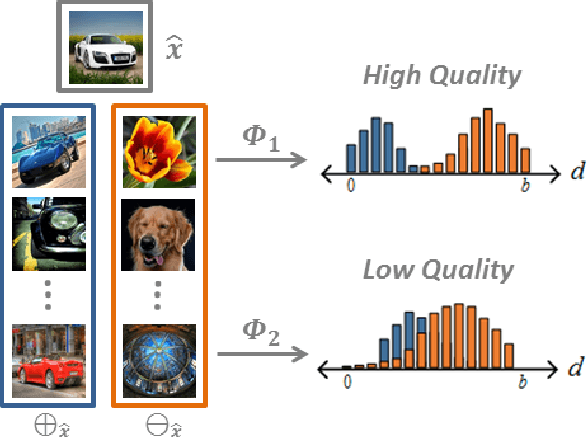
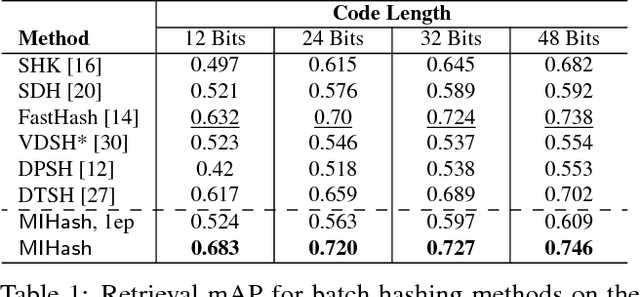
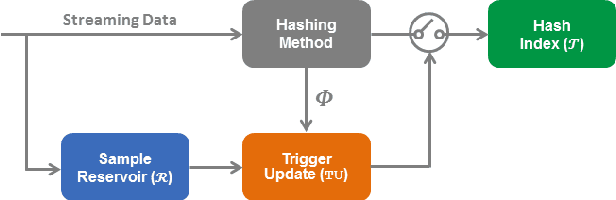
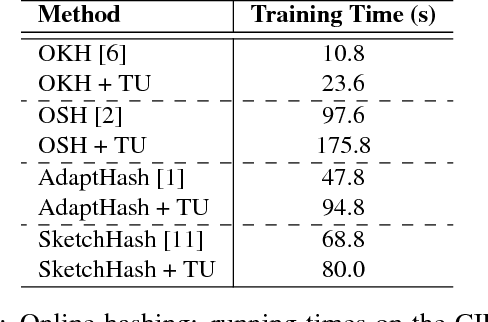
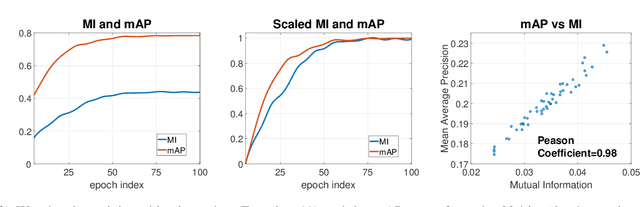
Learning-based hashing methods are widely used for nearest neighbor retrieval, and recently, online hashing methods have demonstrated good performance-complexity trade-offs by learning hash functions from streaming data. In this paper, we first address a key challenge for online hashing: the binary codes for indexed data must be recomputed to keep pace with updates to the hash functions. We propose an efficient quality measure for hash functions, based on an information-theoretic quantity, mutual information, and use it successfully as a criterion to eliminate unnecessary hash table updates. Next, we also show how to optimize the mutual information objective using stochastic gradient descent. We thus develop a novel hashing method, MIHash, that can be used in both online and batch settings. Experiments on image retrieval benchmarks (including a 2.5M image dataset) confirm the effectiveness of our formulation, both in reducing hash table recomputations and in learning high-quality hash functions.
Online Supervised Hashing for Ever-Growing Datasets
Nov 10, 2015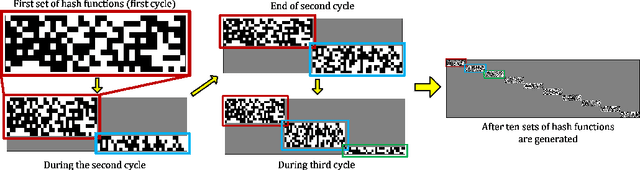
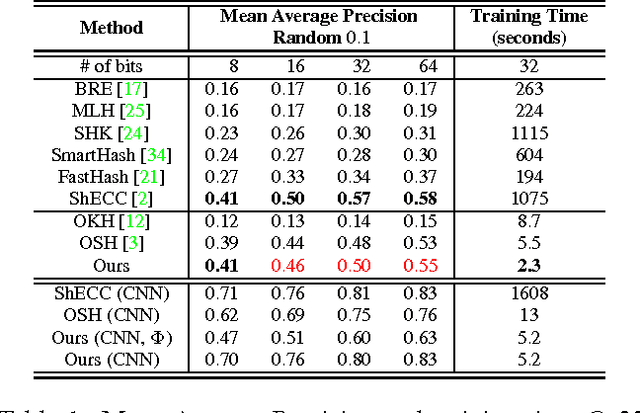
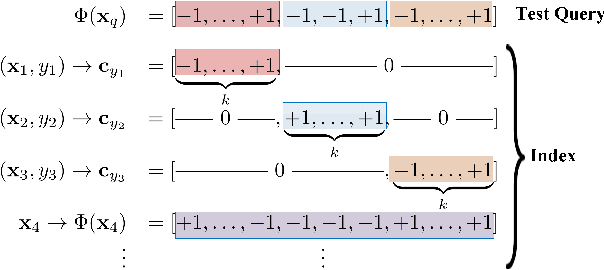
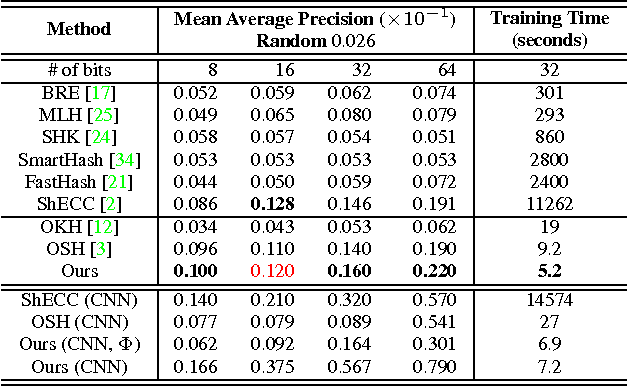
Supervised hashing methods are widely-used for nearest neighbor search in computer vision applications. Most state-of-the-art supervised hashing approaches employ batch-learners. Unfortunately, batch-learning strategies can be inefficient when confronted with large training datasets. Moreover, with batch-learners, it is unclear how to adapt the hash functions as a dataset continues to grow and diversify over time. Yet, in many practical scenarios the dataset grows and diversifies; thus, both the hash functions and the indexing must swiftly accommodate these changes. To address these issues, we propose an online hashing method that is amenable to changes and expansions of the datasets. Since it is an online algorithm, our approach offers linear complexity with the dataset size. Our solution is supervised, in that we incorporate available label information to preserve the semantic neighborhood. Such an adaptive hashing method is attractive; but it requires recomputing the hash table as the hash functions are updated. If the frequency of update is high, then recomputing the hash table entries may cause inefficiencies in the system, especially for large indexes. Thus, we also propose a framework to reduce hash table updates. We compare our method to state-of-the-art solutions on two benchmarks and demonstrate significant improvements over previous work.
Visual Word Selection without Re-Coding and Re-Pooling
Jul 23, 2014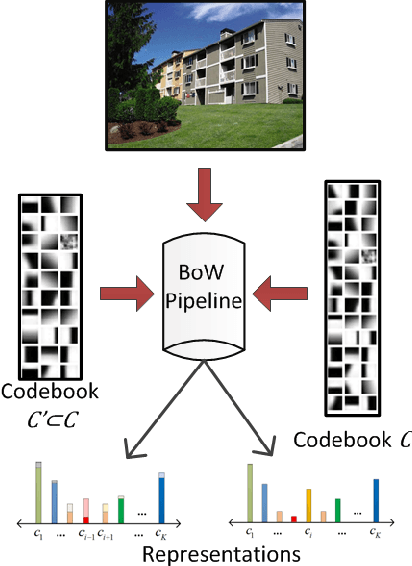


The Bag-of-Words (BoW) representation is widely used in computer vision. The size of the codebook impacts the time and space complexity of the applications that use BoW. Thus, given a training set for a particular computer vision task, a key problem is pruning a large codebook to select only a subset of visual words. Evaluating possible selections of words to be included in the pruned codebook can be computationally prohibitive; in a brute-force scheme, evaluating each pruned codebook requires re-coding of all features extracted from training images to words in the candidate codebook and then re-pooling the words to obtain a representation of each image, e.g., histogram of visual word frequencies. In this paper, a method is proposed that selects and evaluates a subset of words from an initially large codebook, without the need for re-coding or re-pooling. Formulations are proposed for two commonly-used schemes: hard and soft (kernel) coding of visual words with average-pooling. The effectiveness of these formulations is evaluated on the 15 Scenes and Caltech 10 benchmarks.