 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Calibrating sufficiently
May 29, 2021
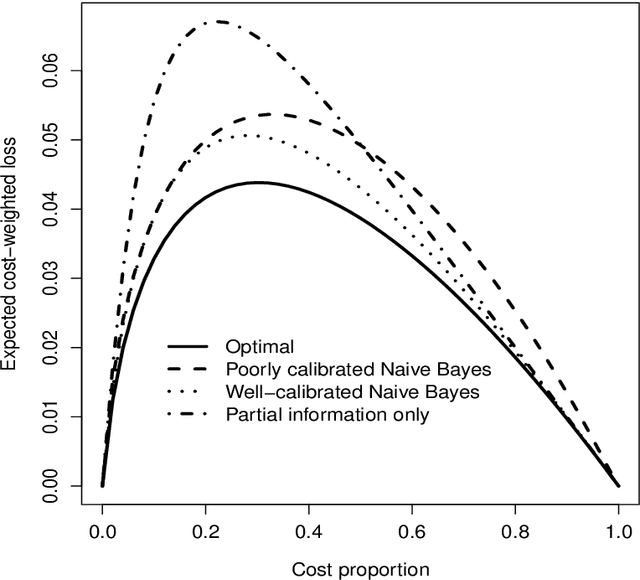
When probabilistic classifiers are trained and calibrated, the so-called grouping loss component of the calibration loss can easily be overlooked. Grouping loss refers to the gap between observable information and information actually exploited in the calibration exercise. We investigate the relation between grouping loss and the concept of sufficiency, identifying comonotonicity as a useful criterion for sufficiency. We revisit the probing reduction approach of Langford & Zadrozny (2005) and find that it produces an estimator of probabilistic classifiers that reduces grouping loss. Finally, we discuss Brier curves as tools to support training and 'sufficient' calibration of probabilistic classifiers.
Multilingual Speech Recognition for Low-Resource Indian Languages using Multi-Task conformer
Sep 10, 2021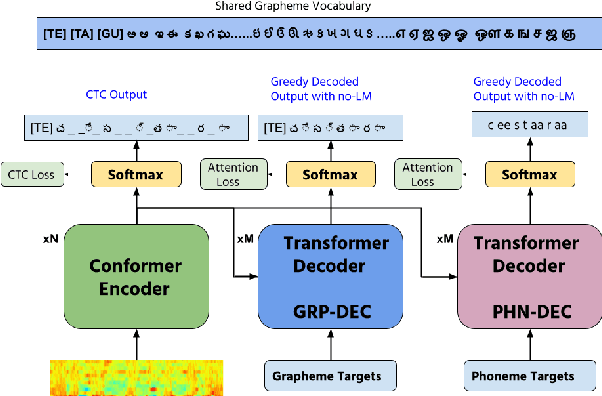

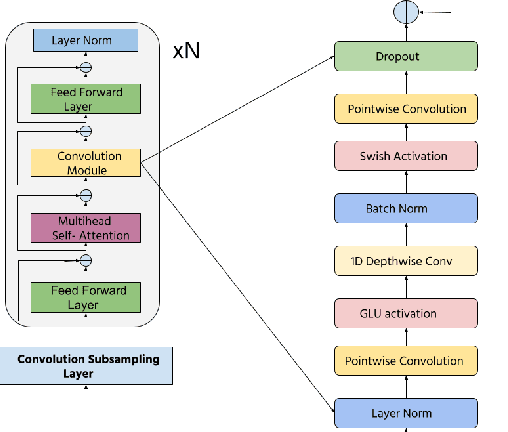
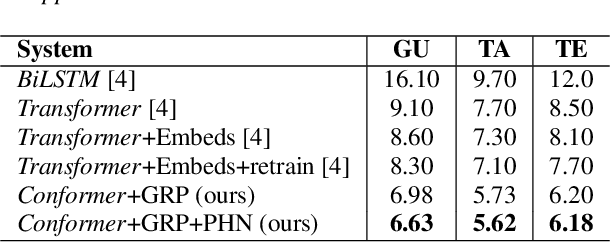
Transformers have recently become very popular for sequence-to-sequence applications such as machine translation and speech recognition. In this work, we propose a multi-task learning-based transformer model for low-resource multilingual speech recognition for Indian languages. Our proposed model consists of a conformer [1] encoder and two parallel transformer decoders. We use a phoneme decoder (PHN-DEC) for the phoneme recognition task and a grapheme decoder (GRP-DEC) to predict grapheme sequence. We consider the phoneme recognition task as an auxiliary task for our multi-task learning framework. We jointly optimize the network for both phoneme and grapheme recognition tasks using Joint CTC-Attention [2] training. We use a conditional decoding scheme to inject the language information into the model before predicting the grapheme sequence. Our experiments show that our proposed approach can obtain significant improvement over previous approaches [4]. We also show that our conformer-based dual-decoder approach outperforms both the transformer-based dual-decoder approach and single decoder approach. Finally, We compare monolingual ASR models with our proposed multilingual ASR approach.
Edge-featured Graph Neural Architecture Search
Sep 03, 2021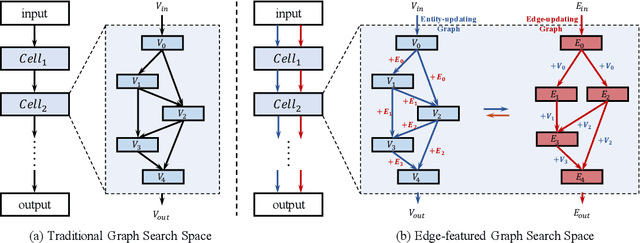

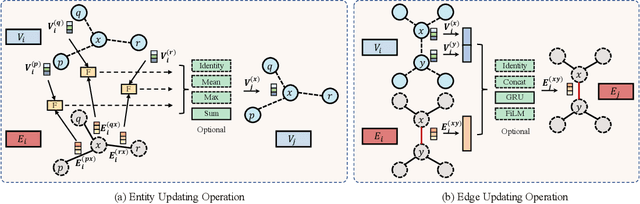
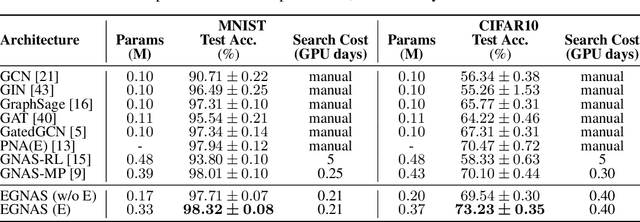
Graph neural networks (GNNs) have been successfully applied to learning representation on graphs in many relational tasks. Recently, researchers study neural architecture search (NAS) to reduce the dependence of human expertise and explore better GNN architectures, but they over-emphasize entity features and ignore latent relation information concealed in the edges. To solve this problem, we incorporate edge features into graph search space and propose Edge-featured Graph Neural Architecture Search to find the optimal GNN architecture. Specifically, we design rich entity and edge updating operations to learn high-order representations, which convey more generic message passing mechanisms. Moreover, the architecture topology in our search space allows to explore complex feature dependence of both entities and edges, which can be efficiently optimized by differentiable search strategy. Experiments at three graph tasks on six datasets show EGNAS can search better GNNs with higher performance than current state-of-the-art human-designed and searched-based GNNs.
Statistical Estimation and Inference via Local SGD in Federated Learning
Sep 03, 2021
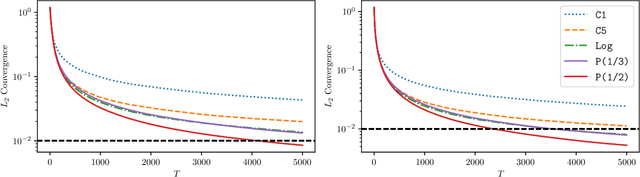
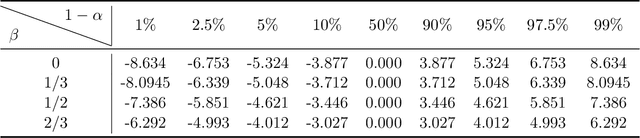
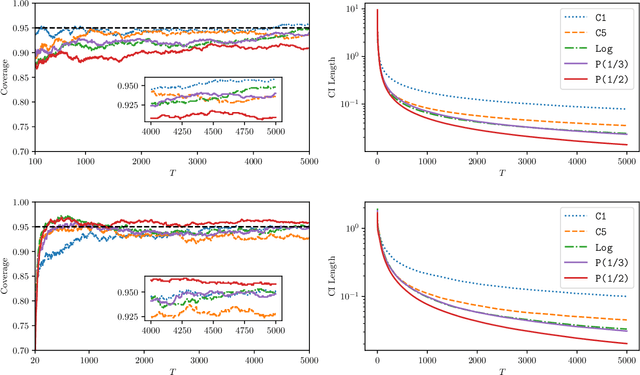
Federated Learning (FL) makes a large amount of edge computing devices (e.g., mobile phones) jointly learn a global model without data sharing. In FL, data are generated in a decentralized manner with high heterogeneity. This paper studies how to perform statistical estimation and inference in the federated setting. We analyze the so-called Local SGD, a multi-round estimation procedure that uses intermittent communication to improve communication efficiency. We first establish a {\it functional central limit theorem} that shows the averaged iterates of Local SGD weakly converge to a rescaled Brownian motion. We next provide two iterative inference methods: the {\it plug-in} and the {\it random scaling}. Random scaling constructs an asymptotically pivotal statistic for inference by using the information along the whole Local SGD path. Both the methods are communication efficient and applicable to online data. Our theoretical and empirical results show that Local SGD simultaneously achieves both statistical efficiency and communication efficiency.
Indexing Context-Sensitive Reachability
Sep 03, 2021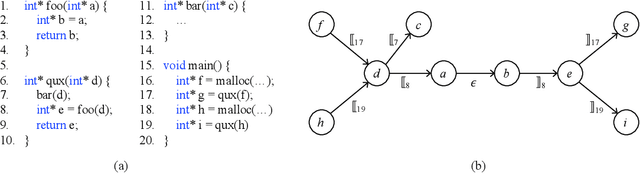
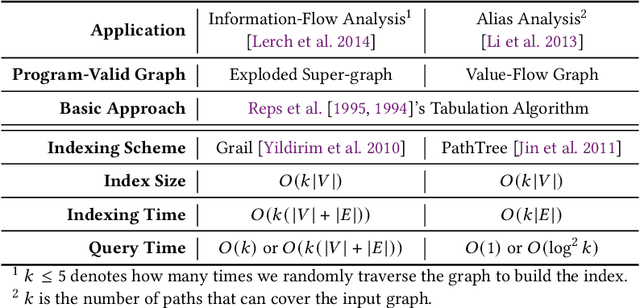
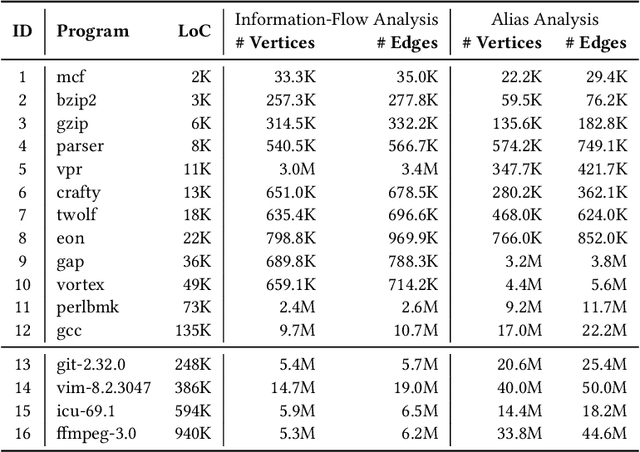
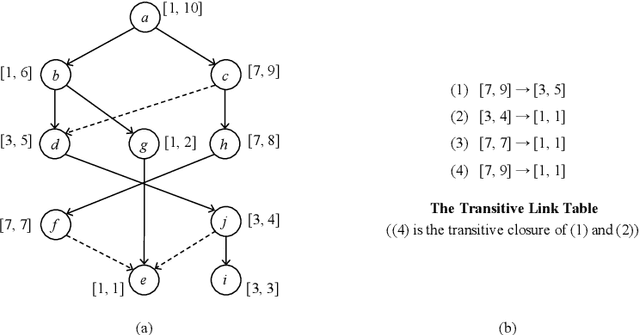
Many context-sensitive data flow analyses can be formulated as a variant of the all-pairs Dyck-CFL reachability problem, which, in general, is of sub-cubic time complexity and quadratic space complexity. Such high complexity significantly limits the scalability of context-sensitive data flow analysis and is not affordable for analyzing large-scale software. This paper presents \textsc{Flare}, a reduction from the CFL reachability problem to the conventional graph reachability problem for context-sensitive data flow analysis. This reduction allows us to benefit from recent advances in reachability indexing schemes, which often consume almost linear space for answering reachability queries in almost constant time. We have applied our reduction to a context-sensitive alias analysis and a context-sensitive information-flow analysis for C/C++ programs. Experimental results on standard benchmarks and open-source software demonstrate that we can achieve orders of magnitude speedup at the cost of only moderate space to store the indexes. The implementation of our approach is publicly available.
Adaptively Multi-view and Temporal Fusing Transformer for 3D Human Pose Estimation
Oct 11, 2021
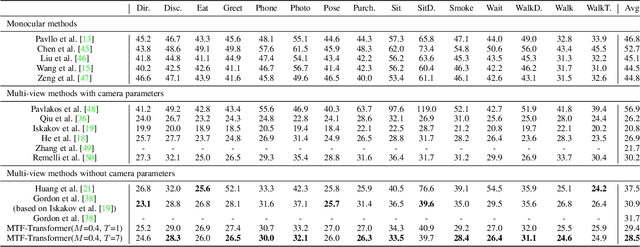


In practical application, 3D Human Pose Estimation (HPE) is facing with several variable elements, involving the number of views, the length of the video sequence, and whether using camera calibration. To this end, we propose a unified framework named Multi-view and Temporal Fusing Transformer (MTF-Transformer) to adaptively handle varying view numbers and video length without calibration. MTF-Transformer consists of Feature Extractor, Multi-view Fusing Transformer (MFT), and Temporal Fusing Transformer (TFT). Feature Extractor estimates the 2D pose from each image and encodes the predicted coordinates and confidence into feature embedding for further 3D pose inference. It discards the image features and focuses on lifting the 2D pose into the 3D pose, making the subsequent modules computationally lightweight enough to handle videos. MFT fuses the features of a varying number of views with a relative-attention block. It adaptively measures the implicit relationship between each pair of views and reconstructs the features. TFT aggregates the features of the whole sequence and predicts 3D pose via a transformer, which is adaptive to the length of the video and takes full advantage of the temporal information. With these modules, MTF-Transformer handles different application scenes, varying from a monocular-single-image to multi-view-video, and the camera calibration is avoidable. We demonstrate quantitative and qualitative results on the Human3.6M, TotalCapture, and KTH Multiview Football II. Compared with state-of-the-art methods with camera parameters, experiments show that MTF-Transformer not only obtains comparable results but also generalizes well to dynamic capture with an arbitrary number of unseen views. Code is available in https://github.com/lelexx/MTF-Transformer.
Chemical-Reaction-Aware Molecule Representation Learning
Sep 22, 2021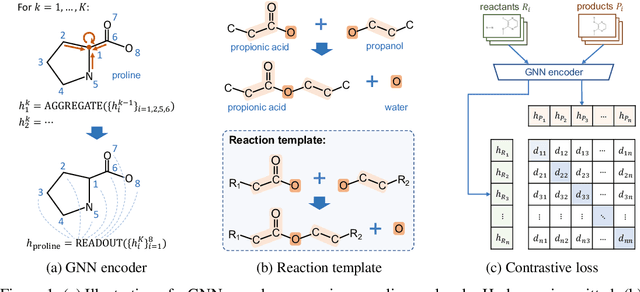
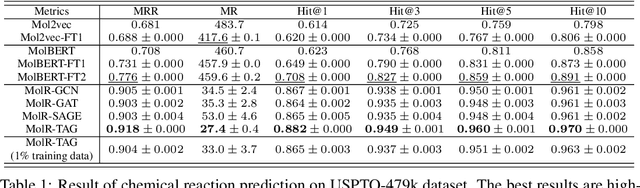
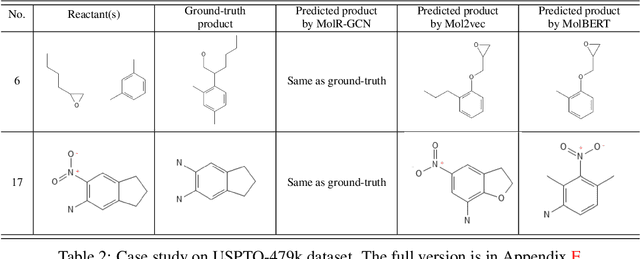
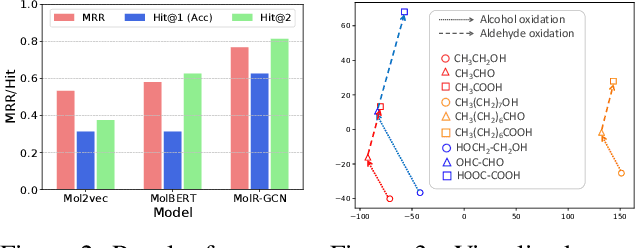
Molecule representation learning (MRL) methods aim to embed molecules into a real vector space. However, existing SMILES-based (Simplified Molecular-Input Line-Entry System) or GNN-based (Graph Neural Networks) MRL methods either take SMILES strings as input that have difficulty in encoding molecule structure information, or over-emphasize the importance of GNN architectures but neglect their generalization ability. Here we propose using chemical reactions to assist learning molecule representation. The key idea of our approach is to preserve the equivalence of molecules with respect to chemical reactions in the embedding space, i.e., forcing the sum of reactant embeddings and the sum of product embeddings to be equal for each chemical equation. This constraint is proven effective to 1) keep the embedding space well-organized and 2) improve the generalization ability of molecule embeddings. Moreover, our model can use any GNN as the molecule encoder and is thus agnostic to GNN architectures. Experimental results demonstrate that our method achieves state-of-the-art performance in a variety of downstream tasks, e.g., 17.4% absolute Hit@1 gain in chemical reaction prediction, 2.3% absolute AUC gain in molecule property prediction, and 18.5% relative RMSE gain in graph-edit-distance prediction, respectively, over the best baseline method. The code is available at https://github.com/hwwang55/MolR.
Towards disease-aware image editing of chest X-rays
Sep 03, 2021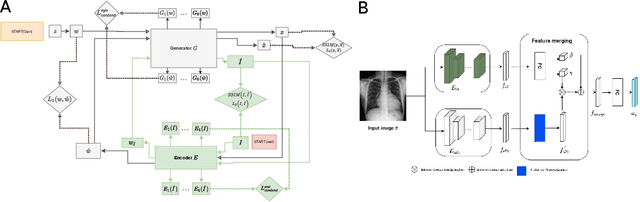
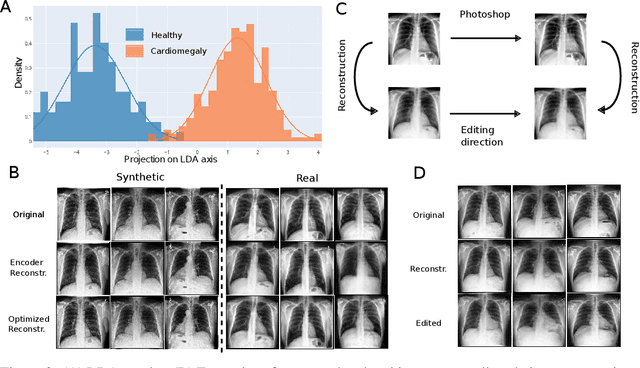
Disease-aware image editing by means of generative adversarial networks (GANs) constitutes a promising avenue for advancing the use of AI in the healthcare sector. Here, we present a proof of concept of this idea. While GAN-based techniques have been successful in generating and manipulating natural images, their application to the medical domain, however, is still in its infancy. Working with the CheXpert data set, we show that StyleGAN can be trained to generate realistic chest X-rays. Inspired by the Cyclic Reverse Generator (CRG) framework, we train an encoder that allows for faithfully inverting the generator on synthetic X-rays and provides organ-level reconstructions of real ones. Employing a guided manipulation of latent codes, we confer the medical condition of cardiomegaly (increased heart size) onto real X-rays from healthy patients. This work was presented in the Medical Imaging meets Neurips Workshop 2020, which was held as part of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020) in Vancouver, Canada
Efficient training of lightweight neural networks using Online Self-Acquired Knowledge Distillation
Aug 26, 2021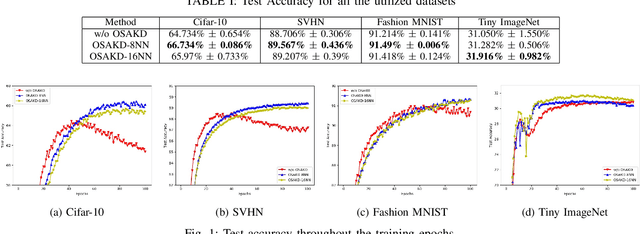
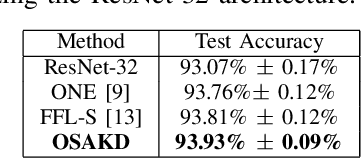
Knowledge Distillation has been established as a highly promising approach for training compact and faster models by transferring knowledge from heavyweight and powerful models. However, KD in its conventional version constitutes an enduring, computationally and memory demanding process. In this paper, Online Self-Acquired Knowledge Distillation (OSAKD) is proposed, aiming to improve the performance of any deep neural model in an online manner. We utilize k-nn non-parametric density estimation technique for estimating the unknown probability distributions of the data samples in the output feature space. This allows us for directly estimating the posterior class probabilities of the data samples, and we use them as soft labels that encode explicit information about the similarities of the data with the classes, negligibly affecting the computational cost. The experimental evaluation on four datasets validates the effectiveness of proposed method.
Beyond Monocular Deraining: Parallel Stereo Deraining Network Via Semantic Prior
May 09, 2021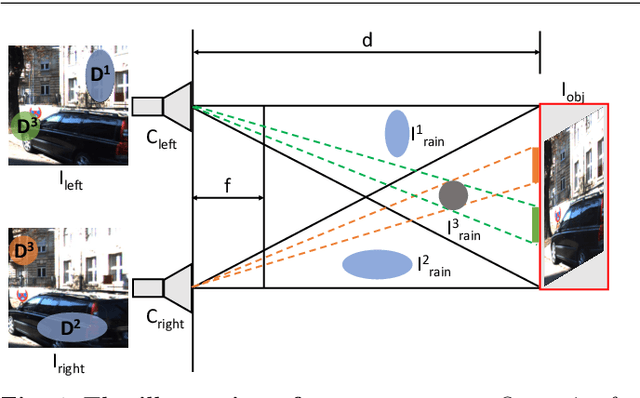
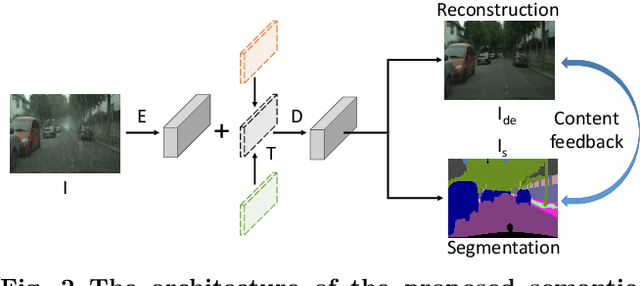
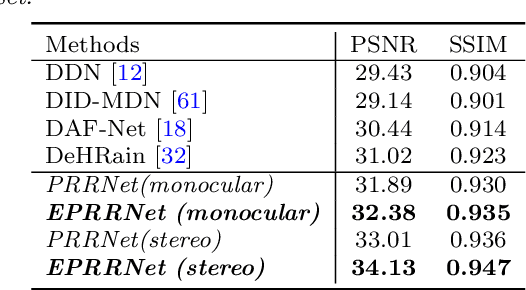
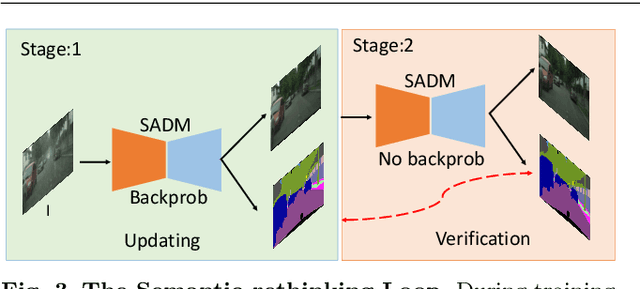
Rain is a common natural phenomenon. Taking images in the rain however often results in degraded quality of images, thus compromises the performance of many computer vision systems. Most existing de-rain algorithms use only one single input image and aim to recover a clean image. Few work has exploited stereo images. Moreover, even for single image based monocular deraining, many current methods fail to complete the task satisfactorily because they mostly rely on per pixel loss functions and ignore semantic information. In this paper, we present a Paired Rain Removal Network (PRRNet), which exploits both stereo images and semantic information. Specifically, we develop a Semantic-Aware Deraining Module (SADM) which solves both tasks of semantic segmentation and deraining of scenes, and a Semantic-Fusion Network (SFNet) and a View-Fusion Network (VFNet) which fuse semantic information and multi-view information respectively. In addition, we also introduce an Enhanced Paired Rain Removal Network (EPRRNet) which exploits semantic prior to remove rain streaks from stereo images. We first use a coarse deraining network to reduce the rain streaks on the input images, and then adopt a pre-trained semantic segmentation network to extract semantic features from the coarse derained image. Finally, a parallel stereo deraining network fuses semantic and multi-view information to restore finer results. We also propose new stereo based rainy datasets for benchmarking. Experiments on both monocular and the newly proposed stereo rainy datasets demonstrate that the proposed method achieves the state-of-the-art performance.