 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DDR-Net: Dividing and Downsampling Mixed Network for Diffeomorphic Image Registration
May 24, 2021
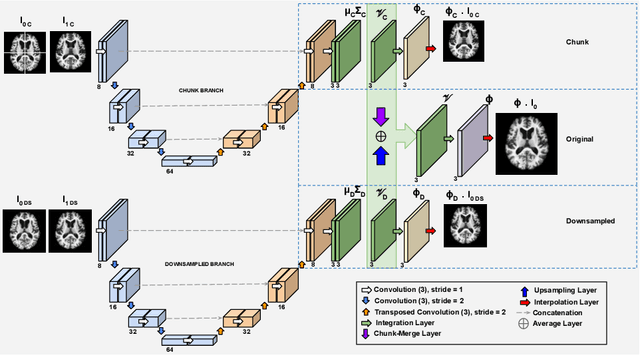
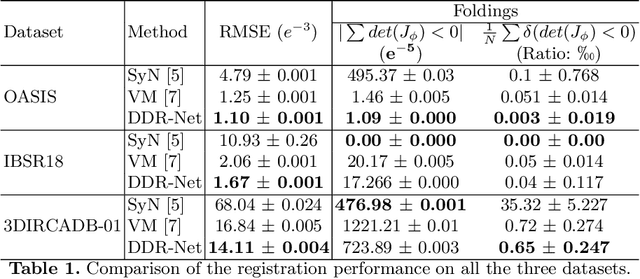
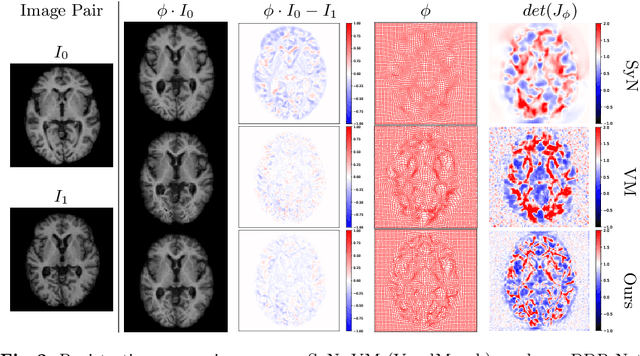
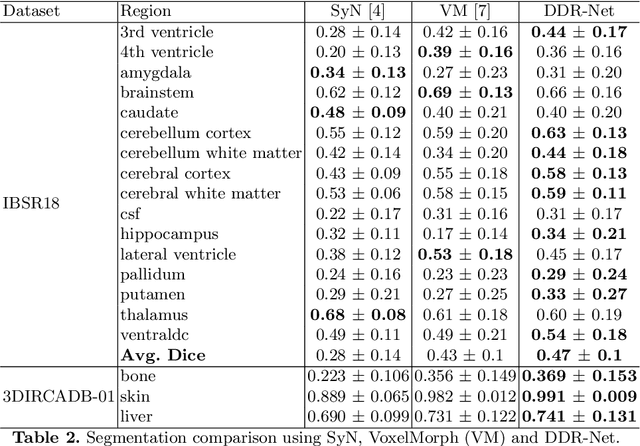
Deep diffeomorphic registration faces significant challenges for high-dimensional images, especially in terms of memory limits. Existing approaches either downsample original images, or approximate underlying transformations, or reduce model size. The information loss during the approximation or insufficient model capacity is a hindrance to the registration accuracy for high-dimensional images, e.g., 3D medical volumes. In this paper, we propose a Dividing and Downsampling mixed Registration network (DDR-Net), a general architecture that preserves most of the image information at multiple scales. DDR-Net leverages the global context via downsampling the input and utilizes the local details from divided chunks of the input images. This design reduces the network input size and its memory cost; meanwhile, by fusing global and local information, DDR-Net obtains both coarse-level and fine-level alignments in the final deformation fields. We evaluate DDR-Net on three public datasets, i.e., OASIS, IBSR18, and 3DIRCADB-01, and the experimental results demonstrate our approach outperforms existing approaches.
Improving One-Shot Learning through Fusing Side Information
Jan 23, 2018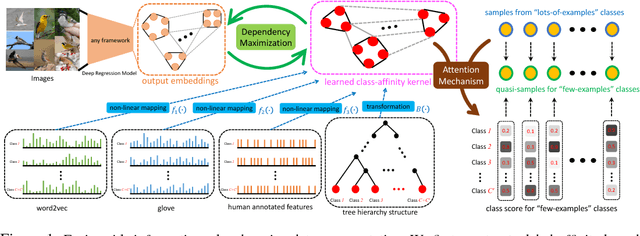

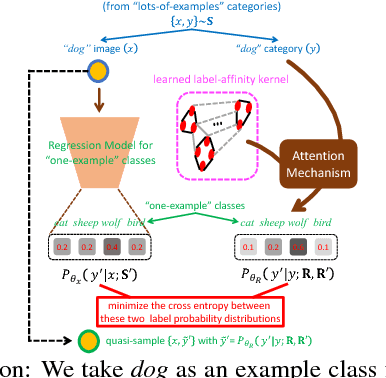
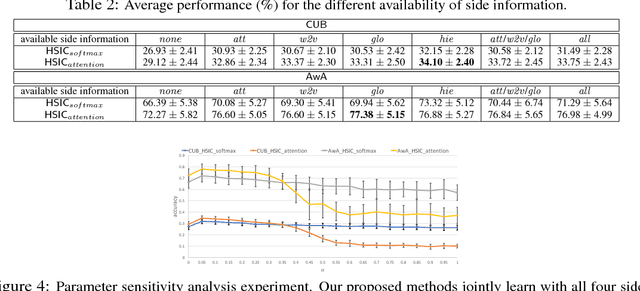
Deep Neural Networks (DNNs) often struggle with one-shot learning where we have only one or a few labeled training examples per category. In this paper, we argue that by using side information, we may compensate the missing information across classes. We introduce two statistical approaches for fusing side information into data representation learning to improve one-shot learning. First, we propose to enforce the statistical dependency between data representations and multiple types of side information. Second, we introduce an attention mechanism to efficiently treat examples belonging to the 'lots-of-examples' classes as quasi-samples (additional training samples) for 'one-example' classes. We empirically show that our learning architecture improves over traditional softmax regression networks as well as state-of-the-art attentional regression networks on one-shot recognition tasks.
Robust High-Resolution Video Matting with Temporal Guidance
Aug 25, 2021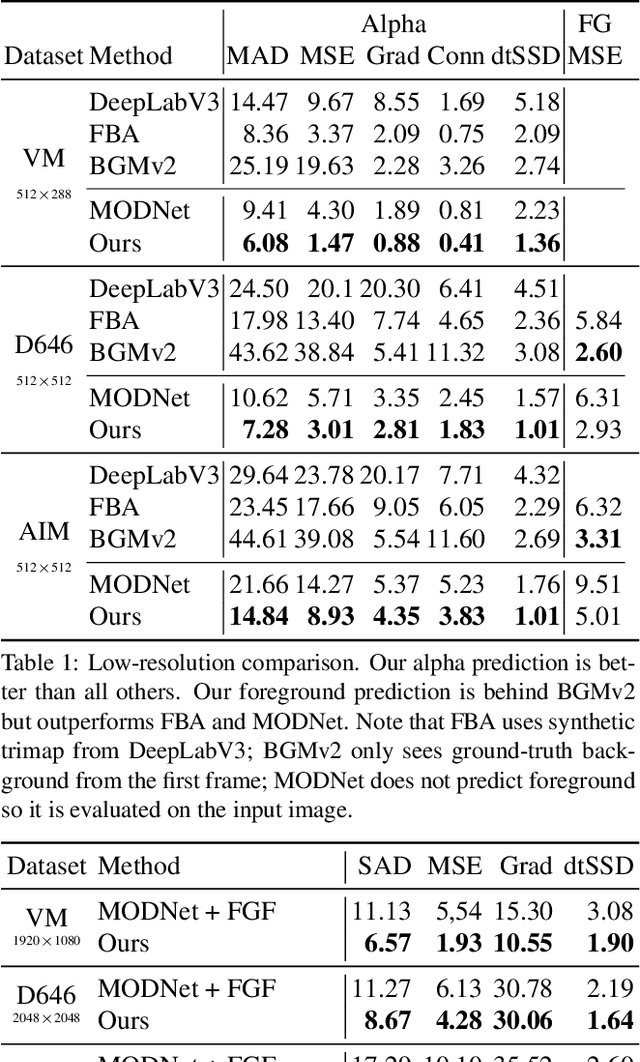
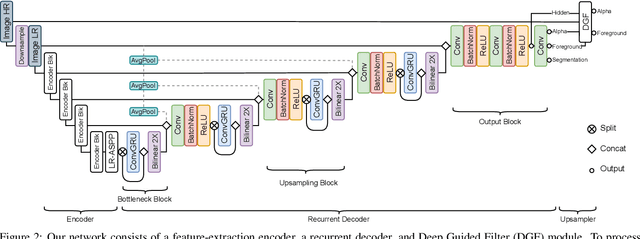
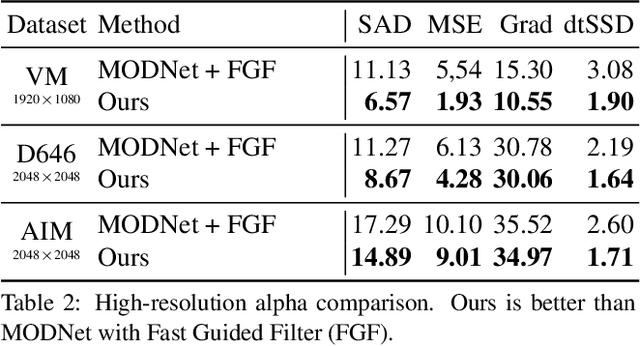
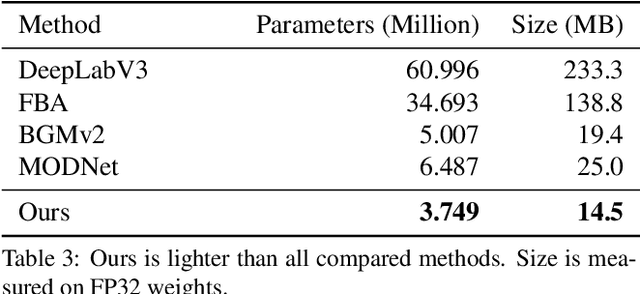
We introduce a robust, real-time, high-resolution human video matting method that achieves new state-of-the-art performance. Our method is much lighter than previous approaches and can process 4K at 76 FPS and HD at 104 FPS on an Nvidia GTX 1080Ti GPU. Unlike most existing methods that perform video matting frame-by-frame as independent images, our method uses a recurrent architecture to exploit temporal information in videos and achieves significant improvements in temporal coherence and matting quality. Furthermore, we propose a novel training strategy that enforces our network on both matting and segmentation objectives. This significantly improves our model's robustness. Our method does not require any auxiliary inputs such as a trimap or a pre-captured background image, so it can be widely applied to existing human matting applications.
UniMS: A Unified Framework for Multimodal Summarization with Knowledge Distillation
Sep 13, 2021
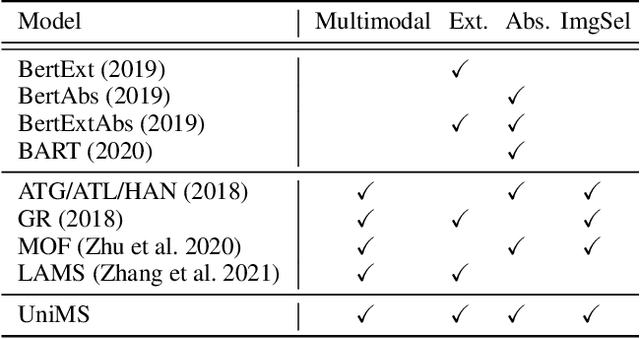
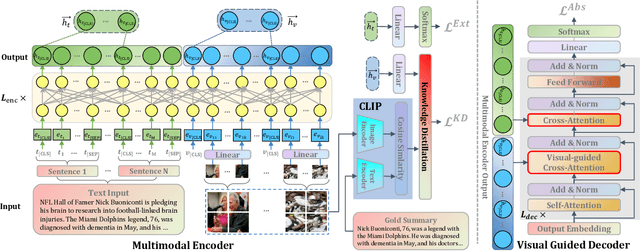
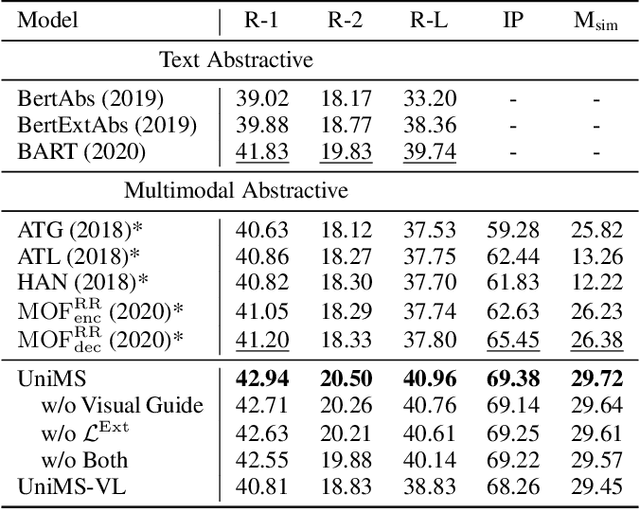
With the rapid increase of multimedia data, a large body of literature has emerged to work on multimodal summarization, the majority of which target at refining salient information from textual and visual modalities to output a pictorial summary with the most relevant images. Existing methods mostly focus on either extractive or abstractive summarization and rely on qualified image captions to build image references. We are the first to propose a Unified framework for Multimodal Summarization grounding on BART, UniMS, that integrates extractive and abstractive objectives, as well as selecting the image output. Specially, we adopt knowledge distillation from a vision-language pretrained model to improve image selection, which avoids any requirement on the existence and quality of image captions. Besides, we introduce a visual guided decoder to better integrate textual and visual modalities in guiding abstractive text generation. Results show that our best model achieves a new state-of-the-art result on a large-scale benchmark dataset. The newly involved extractive objective as well as the knowledge distillation technique are proven to bring a noticeable improvement to the multimodal summarization task.
Predicting survival of glioblastoma from automatic whole-brain and tumor segmentation of MR images
Sep 25, 2021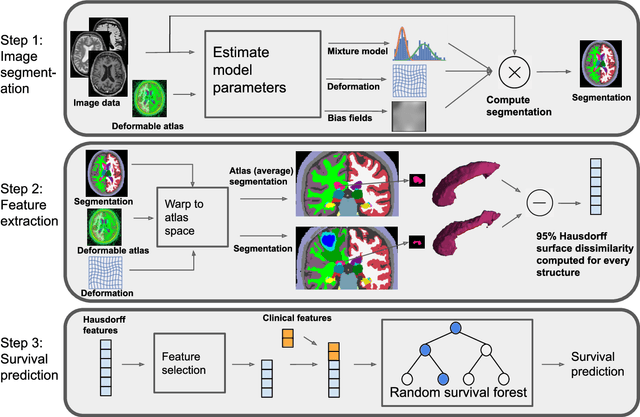

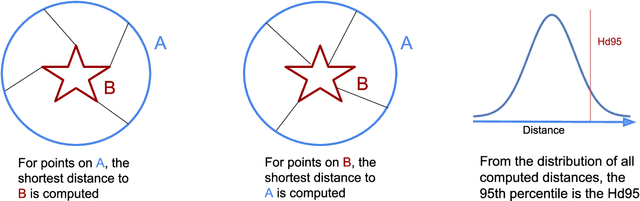
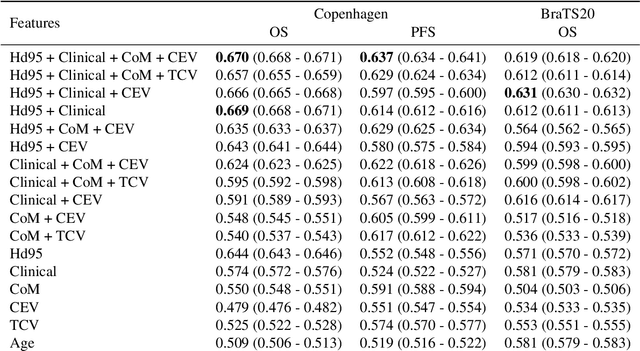
Survival prediction models can potentially be used to guide treatment of glioblastoma patients. However, currently available MR imaging biomarkers holding prognostic information are often challenging to interpret, have difficulties generalizing across data acquisitions, or are only applicable to pre-operative MR data. In this paper we aim to address these issues by introducing novel imaging features that can be automatically computed from MR images and fed into machine learning models to predict patient survival. The features we propose have a direct biological interpretation: They measure the deformation caused by the tumor on the surrounding brain structures, comparing the shape of various structures in the patient's brain to their expected shape in healthy individuals. To obtain the required segmentations, we use an automatic method that is contrast-adaptive and robust to missing modalities, making the features generalizable across scanners and imaging protocols. Since the features we propose do not depend on characteristics of the tumor region itself, they are also applicable to post-operative images, which have been much less studied in the context of survival prediction. Using experiments involving both pre- and post-operative data, we show that the proposed features carry prognostic value in terms of overall- and progression-free survival, over and above that of conventional non-imaging features.
Deep Microlocal Reconstruction for Limited-Angle Tomography
Aug 12, 2021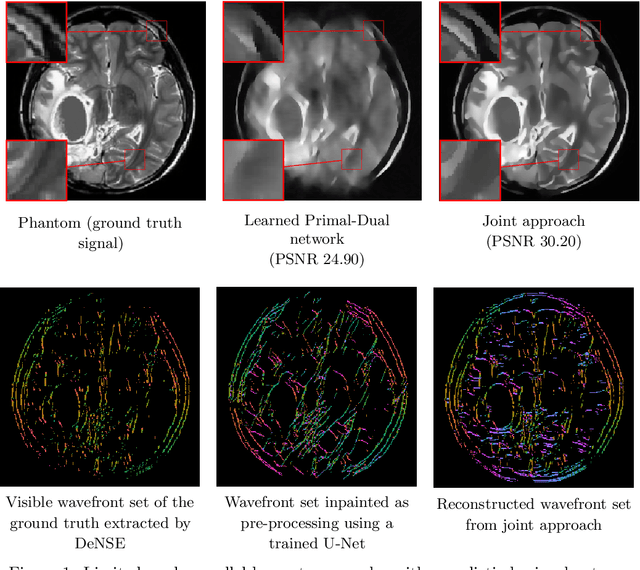
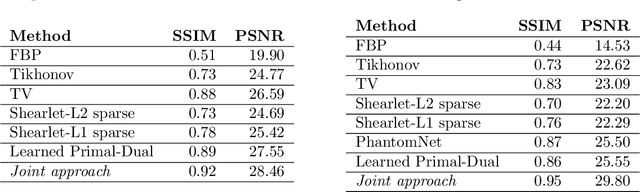

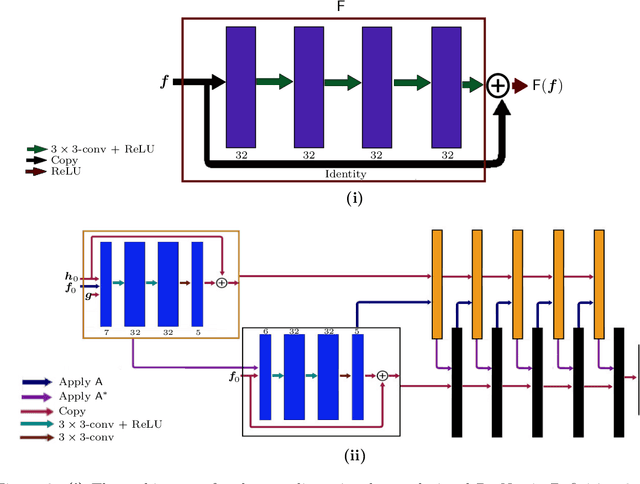
We present a deep learning-based algorithm to jointly solve a reconstruction problem and a wavefront set extraction problem in tomographic imaging. The algorithm is based on a recently developed digital wavefront set extractor as well as the well-known microlocal canonical relation for the Radon transform. We use the wavefront set information about x-ray data to improve the reconstruction by requiring that the underlying neural networks simultaneously extract the correct ground truth wavefront set and ground truth image. As a necessary theoretical step, we identify the digital microlocal canonical relations for deep convolutional residual neural networks. We find strong numerical evidence for the effectiveness of this approach.
Contour location via entropy reduction leveraging multiple information sources
Oct 24, 2018
We introduce an algorithm to locate contours of functions that are expensive to evaluate. The problem of locating contours arises in many applications, including classification, constrained optimization, and performance analysis of mechanical and dynamical systems (reliability, probability of failure, stability, etc.). Our algorithm locates contours using information from multiple sources, which are available in the form of relatively inexpensive, biased, and possibly noisy approximations to the original function. Considering multiple information sources can lead to significant cost savings. We also introduce the concept of contour entropy, a formal measure of uncertainty about the location of the zero contour of a function approximated by a statistical surrogate model. Our algorithm locates contours efficiently by maximizing the reduction of contour entropy per unit cost.
Assessing Algorithmic Biases for Musical Version Identification
Sep 30, 2021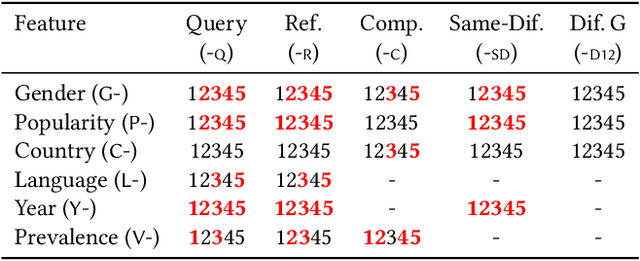
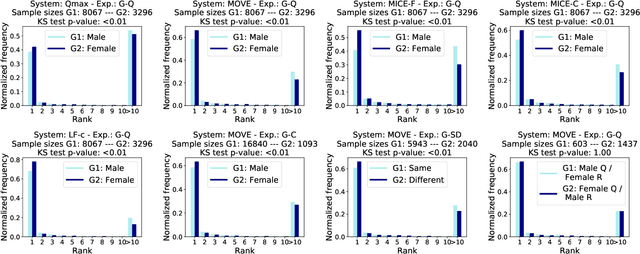
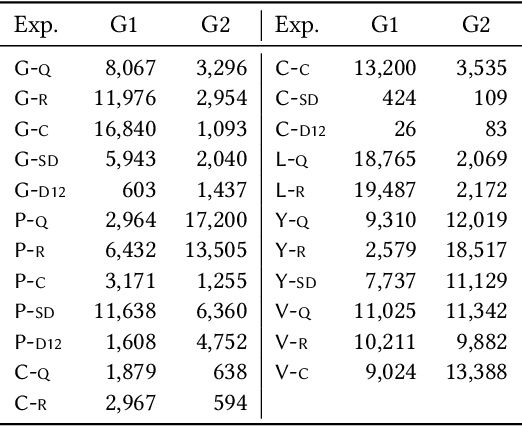
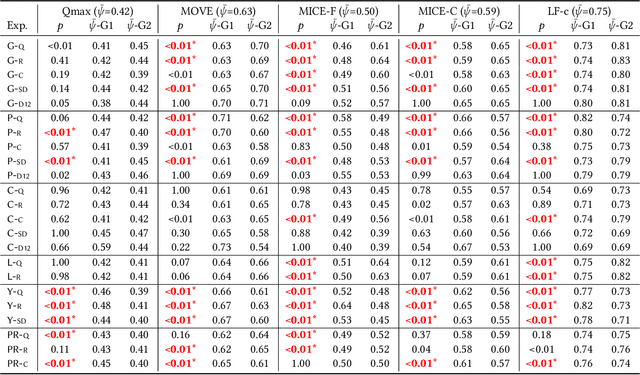
Version identification (VI) systems now offer accurate and scalable solutions for detecting different renditions of a musical composition, allowing the use of these systems in industrial applications and throughout the wider music ecosystem. Such use can have an important impact on various stakeholders regarding recognition and financial benefits, including how royalties are circulated for digital rights management. In this work, we take a step toward acknowledging this impact and consider VI systems as socio-technical systems rather than isolated technologies. We propose a framework for quantifying performance disparities across 5 systems and 6 relevant side attributes: gender, popularity, country, language, year, and prevalence. We also consider 3 main stakeholders for this particular information retrieval use case: the performing artists of query tracks, those of reference (original) tracks, and the composers. By categorizing the recordings in our dataset using such attributes and stakeholders, we analyze whether the considered VI systems show any implicit biases. We find signs of disparities in identification performance for most of the groups we include in our analyses. Moreover, we also find that learning- and rule-based systems behave differently for some attributes, which suggests an additional dimension to consider along with accuracy and scalability when evaluating VI systems. Lastly, we share our dataset with attribute annotations to encourage VI researchers to take these aspects into account while building new systems.
Robust Opponent Modeling via Adversarial Ensemble Reinforcement Learning in Asymmetric Imperfect-Information Games
Sep 18, 2019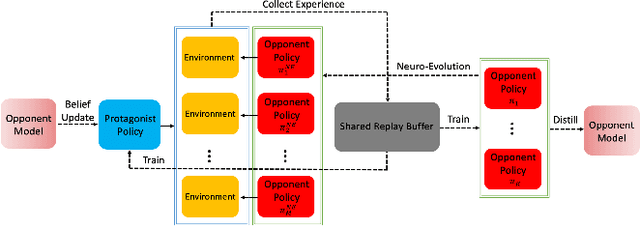
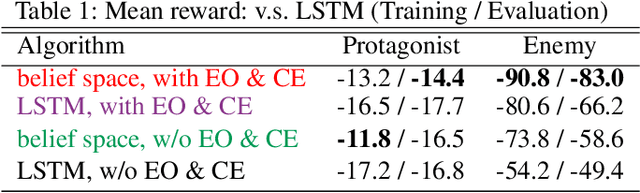

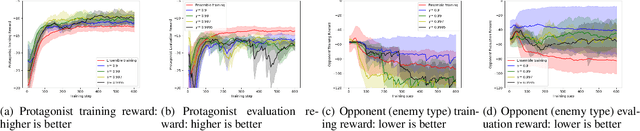
This paper presents an algorithmic framework for learning robust policies in asymmetric imperfect-information games, where the joint reward could depend on the uncertain opponent type (a private information known only to the opponent itself and its ally). In order to maximize the reward, the protagonist agent has to infer the opponent type through agent modeling. We use multiagent reinforcement learning (MARL) to learn opponent models through self-play, which captures the full strategy interaction and reasoning between agents. However, agent policies learned from self-play can suffer from mutual overfitting. Ensemble training methods can be used to improve the robustness of agent policy against different opponents, but it also significantly increases the computational overhead. In order to achieve a good trade-off between the robustness of the learned policy and the computation complexity, we propose to train a separate opponent policy against the protagonist agent for evaluation purposes. The reward achieved by this opponent is a noisy measure of the robustness of the protagonist agent policy due to the intrinsic stochastic nature of a reinforcement learner. To handle this stochasticity, we apply a stochastic optimization scheme to dynamically update the opponent ensemble to optimize an objective function that strikes a balance between robustness and computation complexity. We empirically show that, under the same limited computational budget, the proposed method results in more robust policy learning than standard ensemble training.
Attention Bottlenecks for Multimodal Fusion
Jun 30, 2021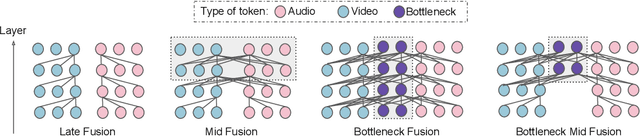
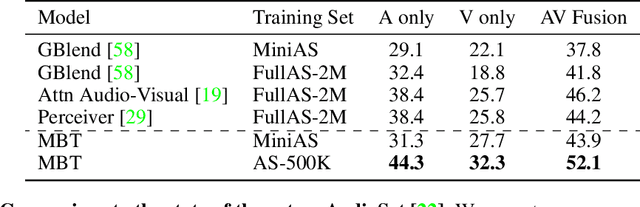
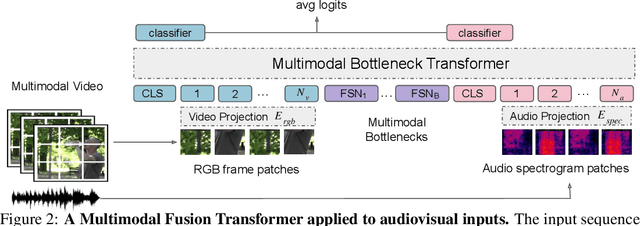
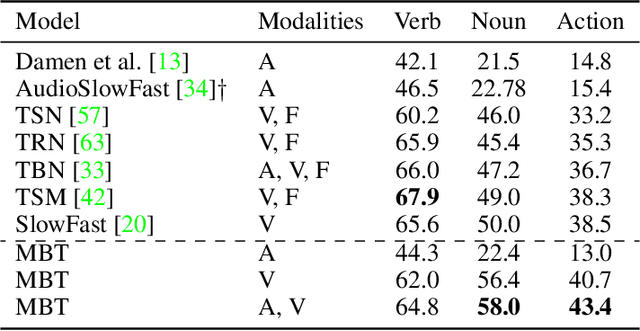
Humans perceive the world by concurrently processing and fusing high-dimensional inputs from multiple modalities such as vision and audio. Machine perception models, in stark contrast, are typically modality-specific and optimised for unimodal benchmarks, and hence late-stage fusion of final representations or predictions from each modality (`late-fusion') is still a dominant paradigm for multimodal video classification. Instead, we introduce a novel transformer based architecture that uses `fusion bottlenecks' for modality fusion at multiple layers. Compared to traditional pairwise self-attention, our model forces information between different modalities to pass through a small number of bottleneck latents, requiring the model to collate and condense the most relevant information in each modality and only share what is necessary. We find that such a strategy improves fusion performance, at the same time reducing computational cost. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple audio-visual classification benchmarks including Audioset, Epic-Kitchens and VGGSound. All code and models will be released.