 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TSM: Temporal Shift Module for Efficient and Scalable Video Understanding on Edge Device
Sep 27, 2021
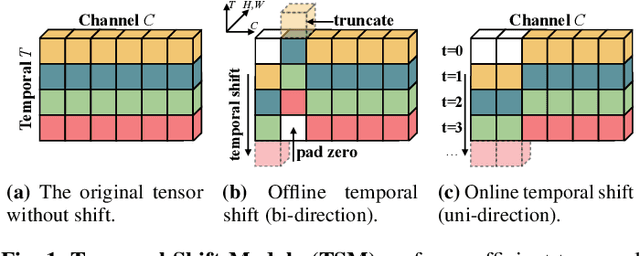
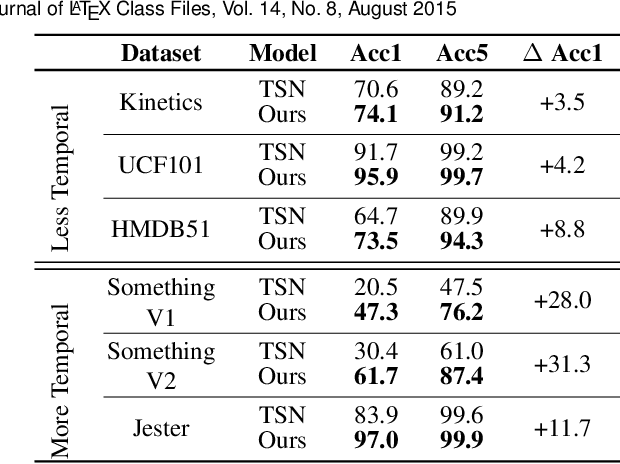

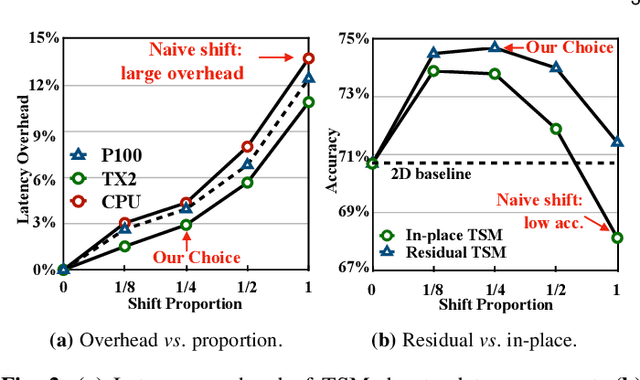
The explosive growth in video streaming requires video understanding at high accuracy and low computation cost. Conventional 2D CNNs are computationally cheap but cannot capture temporal relationships; 3D CNN-based methods can achieve good performance but are computationally intensive. In this paper, we propose a generic and effective Temporal Shift Module (TSM) that enjoys both high efficiency and high performance. The key idea of TSM is to shift part of the channels along the temporal dimension, thus facilitate information exchanged among neighboring frames. It can be inserted into 2D CNNs to achieve temporal modeling at zero computation and zero parameters. TSM offers several unique advantages. Firstly, TSM has high performance; it ranks the first on the Something-Something leaderboard upon submission. Secondly, TSM has high efficiency; it achieves a high frame rate of 74fps and 29fps for online video recognition on Jetson Nano and Galaxy Note8. Thirdly, TSM has higher scalability compared to 3D networks, enabling large-scale Kinetics training on 1,536 GPUs in 15 minutes. Lastly, TSM enables action concepts learning, which 2D networks cannot model; we visualize the category attention map and find that spatial-temporal action detector emerges during the training of classification tasks. The code is publicly available at https://github.com/mit-han-lab/temporal-shift-module.
A Hierarchical Network-Oriented Analysis of User Participation in Misinformation Spread on WhatsApp
Sep 22, 2021



WhatsApp emerged as a major communication platform in many countries in the recent years. Despite offering only one-to-one and small group conversations, WhatsApp has been shown to enable the formation of a rich underlying network, crossing the boundaries of existing groups, and with structural properties that favor information dissemination at large. Indeed, WhatsApp has reportedly been used as a forum of misinformation campaigns with significant social, political and economic consequences in several countries. In this article, we aim at complementing recent studies on misinformation spread on WhatsApp, mostly focused on content properties and propagation dynamics, by looking into the network that connects users sharing the same piece of content. Specifically, we present a hierarchical network-oriented characterization of the users engaged in misinformation spread by focusing on three perspectives: individuals, WhatsApp groups and user communities, i.e., groupings of users who, intentionally or not, share the same content disproportionately often. By analyzing sharing and network topological properties, our study offers valuable insights into how WhatsApp users leverage the underlying network connecting different groups to gain large reach in the spread of misinformation on the platform.
Evaluating Groundedness in Dialogue Systems: The BEGIN Benchmark
Apr 30, 2021
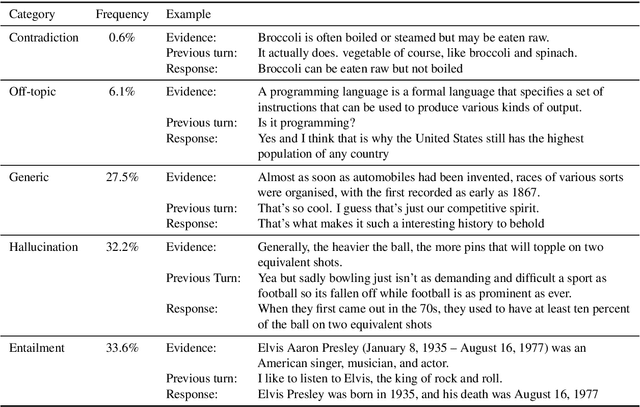

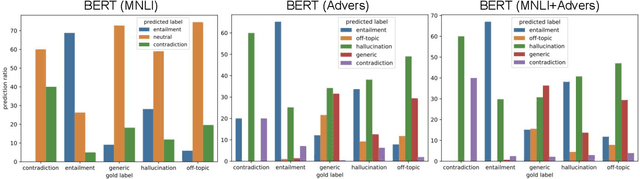
Knowledge-grounded dialogue agents are systems designed to conduct a conversation based on externally provided background information, such as a Wikipedia page. Such dialogue agents, especially those based on neural network language models, often produce responses that sound fluent but are not justified by the background information. Progress towards addressing this problem requires developing automatic evaluation metrics that can quantify the extent to which responses are grounded in background information. To facilitate evaluation of such metrics, we introduce the Benchmark for Evaluation of Grounded INteraction (BEGIN). BEGIN consists of 8113 dialogue turns generated by language-model-based dialogue systems, accompanied by humans annotations specifying the relationship between the system's response and the background information. These annotations are based on an extension of the natural language inference paradigm. We use the benchmark to demonstrate the effectiveness of adversarially generated data for improving an evaluation metric based on existing natural language inference datasets.
Validation of Information Fusion
Jul 22, 2016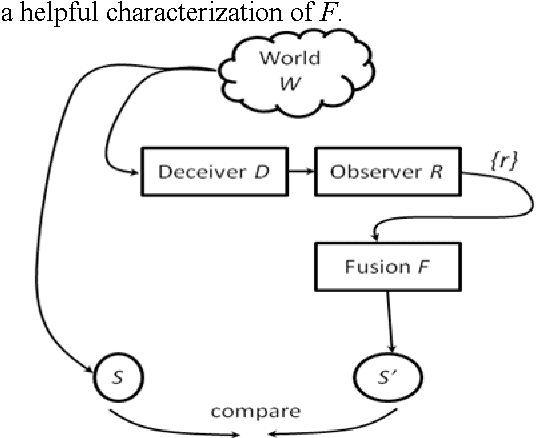
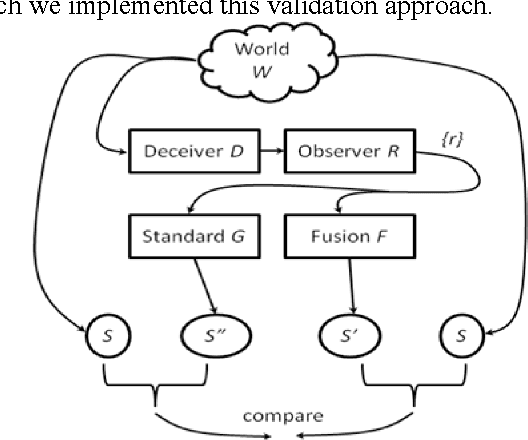
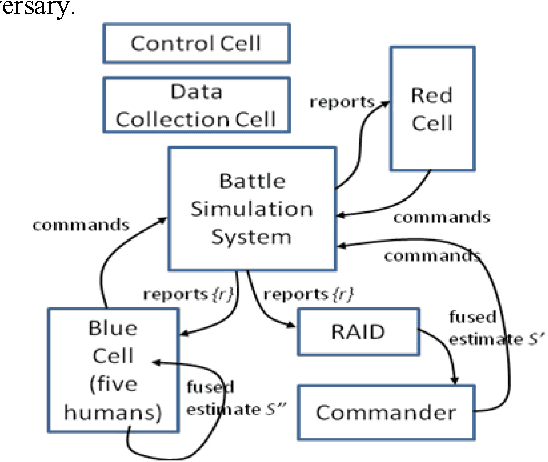
We motivate and offer a formal definition of validation as it applies to information fusion systems. Common definitions of validation compare the actual state of the world with that derived by the fusion process. This definition conflates properties of the fusion system with properties of systems that intervene between the world and the fusion system. We propose an alternative definition where validation of an information fusion system references a standard fusion device, such as recognized human experts. We illustrate the approach by describing the validation process implemented in RAID, a program conducted by DARPA and focused on information fusion in adversarial, deceptive environments.
Unsupervised Landmark Detection Based Spatiotemporal Motion Estimation for 4D Dynamic Medical Images
Oct 12, 2021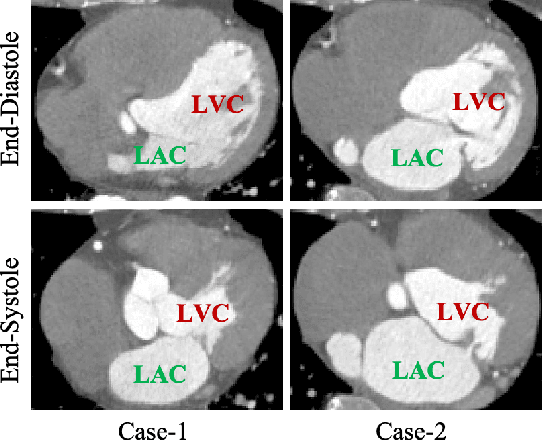

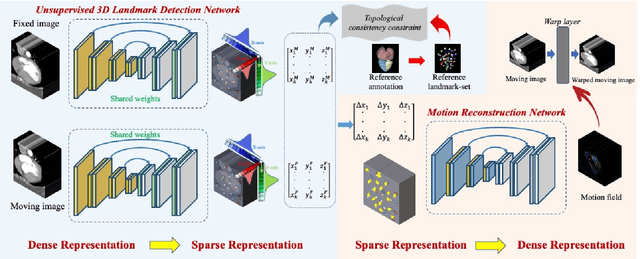
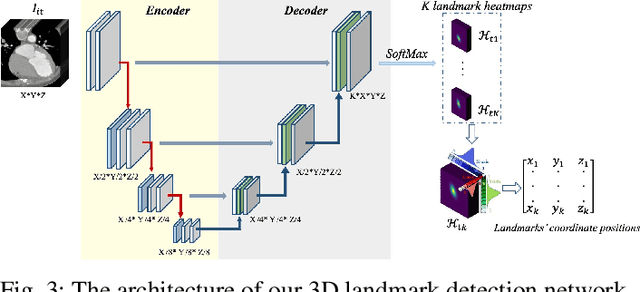
Motion estimation is a fundamental step in dynamic medical image processing for the assessment of target organ anatomy and function. However, existing image-based motion estimation methods, which optimize the motion field by evaluating the local image similarity, are prone to produce implausible estimation, especially in the presence of large motion. In this study, we provide a novel motion estimation framework of Dense-Sparse-Dense (DSD), which comprises two stages. In the first stage, we process the raw dense image to extract sparse landmarks to represent the target organ anatomical topology and discard the redundant information that is unnecessary for motion estimation. For this purpose, we introduce an unsupervised 3D landmark detection network to extract spatially sparse but representative landmarks for the target organ motion estimation. In the second stage, we derive the sparse motion displacement from the extracted sparse landmarks of two images of different time points. Then, we present a motion reconstruction network to construct the motion field by projecting the sparse landmarks displacement back into the dense image domain. Furthermore, we employ the estimated motion field from our two-stage DSD framework as initialization and boost the motion estimation quality in light-weight yet effective iterative optimization. We evaluate our method on two dynamic medical imaging tasks to model cardiac motion and lung respiratory motion, respectively. Our method has produced superior motion estimation accuracy compared to existing comparative methods. Besides, the extensive experimental results demonstrate that our solution can extract well representative anatomical landmarks without any requirement of manual annotation. Our code is publicly available online.
A scalable and fast artificial neural network syndrome decoder for surface codes
Oct 12, 2021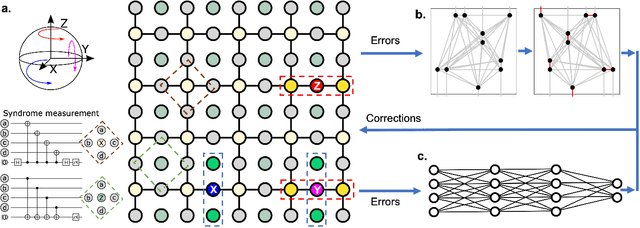
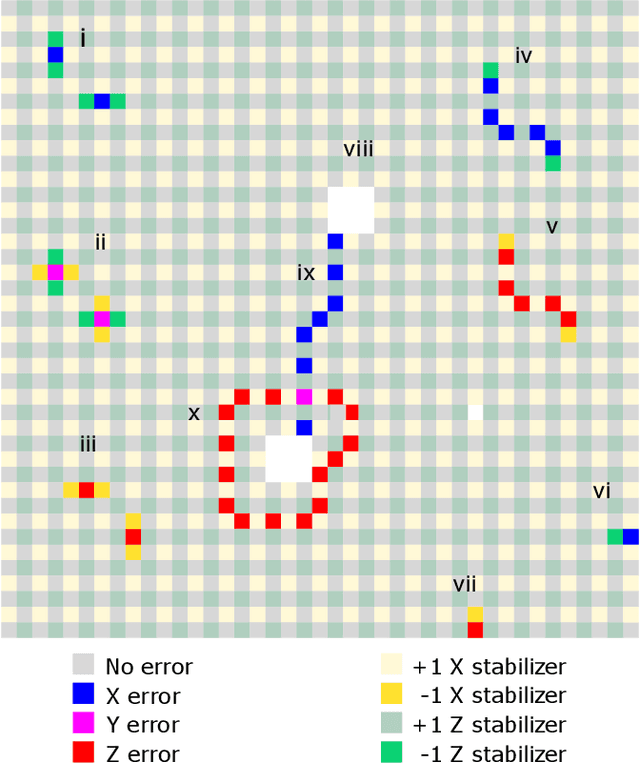
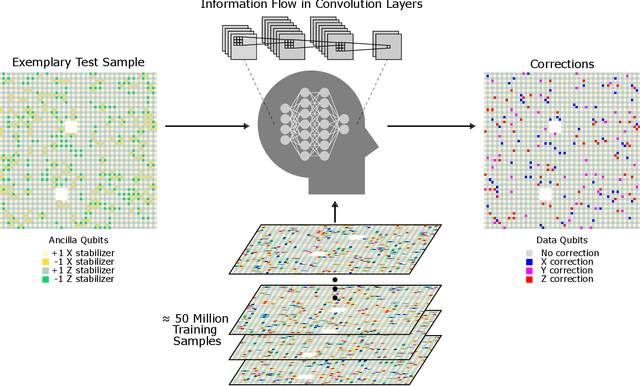
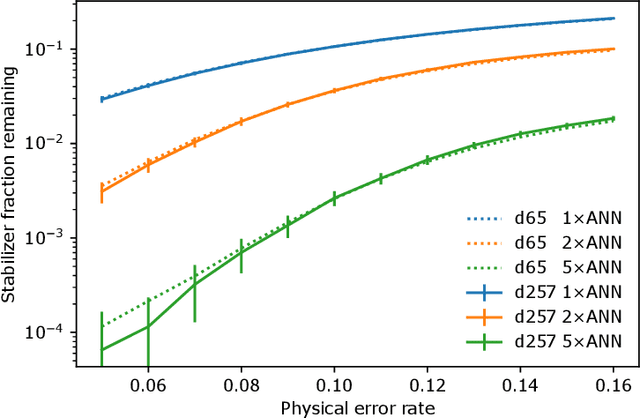
Surface code error correction offers a highly promising pathway to achieve scalable fault-tolerant quantum computing. When operated as stabilizer codes, surface code computations consist of a syndrome decoding step where measured stabilizer operators are used to determine appropriate corrections for errors in physical qubits. Decoding algorithms have undergone substantial development, with recent work incorporating machine learning (ML) techniques. Despite promising initial results, the ML-based syndrome decoders are still limited to small scale demonstrations with low latency and are incapable of handling surface codes with boundary conditions and various shapes needed for lattice surgery and braiding. Here, we report the development of an artificial neural network (ANN) based scalable and fast syndrome decoder capable of decoding surface codes of arbitrary shape and size with data qubits suffering from the depolarizing error model. Based on rigorous training over 50 million random quantum error instances, our ANN decoder is shown to work with code distances exceeding 1000 (more than 4 million physical qubits), which is the largest ML-based decoder demonstration to-date. The established ANN decoder demonstrates an execution time in principle independent of code distance, implying that its implementation on dedicated hardware could potentially offer surface code decoding times of O($\mu$sec), commensurate with the experimentally realisable qubit coherence times. With the anticipated scale-up of quantum processors within the next decade, their augmentation with a fast and scalable syndrome decoder such as developed in our work is expected to play a decisive role towards experimental implementation of fault-tolerant quantum information processing.
Sleep Staging Based on Multi Scale Dual Attention Network
Aug 14, 2021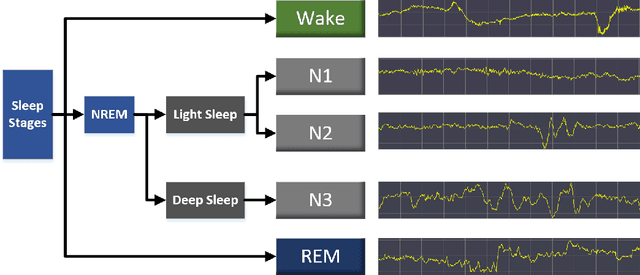

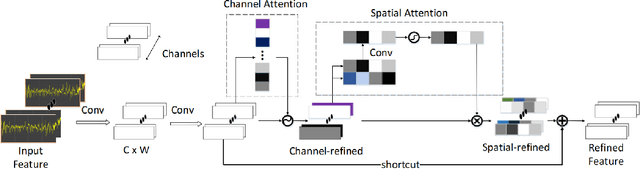

Sleep staging plays an important role on the diagnosis of sleep disorders. In general, experts classify sleep stages manually based on polysomnography (PSG), which is quite time-consuming. Meanwhile, the acquisition process of multiple signals is much complex, which can affect the subject's sleep. Therefore, the use of single-channel electroencephalogram (EEG) for automatic sleep staging has become a popular research topic. In the literature, a large number of sleep staging methods based on single-channel EEG have been proposed with promising results and achieve the preliminary automation of sleep staging. However, the performance for most of these methods in the N1 stage do not satisfy the needs of the diagnosis. In this paper, we propose a deep learning model multi scale dual attention network(MSDAN) based on raw EEG, which utilizes multi-scale convolution to extract features in different waveforms contained in the EEG signal, connects channel attention and spatial attention mechanisms in series to filter and highlight key information, and uses soft thresholding to remove redundant information. Experiments were conducted using two datasets with 5-fold cross-validation and hold-out validation method. The final average accuracy, overall accuracy, macro F1 score and Cohen's Kappa coefficient of the model reach 96.70%, 91.74%, 0.8231 and 0.8723 on the Sleep-EDF dataset, 96.14%, 90.35%, 0.7945 and 0.8284 on the Sleep-EDFx dataset. Significantly, our model performed superiorly in the N1 stage, with F1 scores of 54.41% and 52.79% on the two datasets respectively. The results show the superiority of our network over the existing methods, reaching a new state-of-the-art. In particular, the proposed method achieves excellent results in the N1 sleep stage compared to other methods.
Machine Learning Advances aiding Recognition and Classification of Indian Monuments and Landmarks
Jul 29, 2021



Tourism in India plays a quintessential role in the country's economy with an estimated 9.2% GDP share for the year 2018. With a yearly growth rate of 6.2%, the industry holds a huge potential for being the primary driver of the economy as observed in the nations of the Middle East like the United Arab Emirates. The historical and cultural diversity exhibited throughout the geography of the nation is a unique spectacle for people around the world and therefore serves to attract tourists in tens of millions in number every year. Traditionally, tour guides or academic professionals who study these heritage monuments were responsible for providing information to the visitors regarding their architectural and historical significance. However, unfortunately this system has several caveats when considered on a large scale such as unavailability of sufficient trained people, lack of accurate information, failure to convey the richness of details in an attractive format etc. Recently, machine learning approaches revolving around the usage of monument pictures have been shown to be useful for rudimentary analysis of heritage sights. This paper serves as a survey of the research endeavors undertaken in this direction which would eventually provide insights for building an automated decision system that could be utilized to make the experience of tourism in India more modernized for visitors.
Two algorithms for vehicular obstacle detection in sparse pointcloud
Sep 15, 2021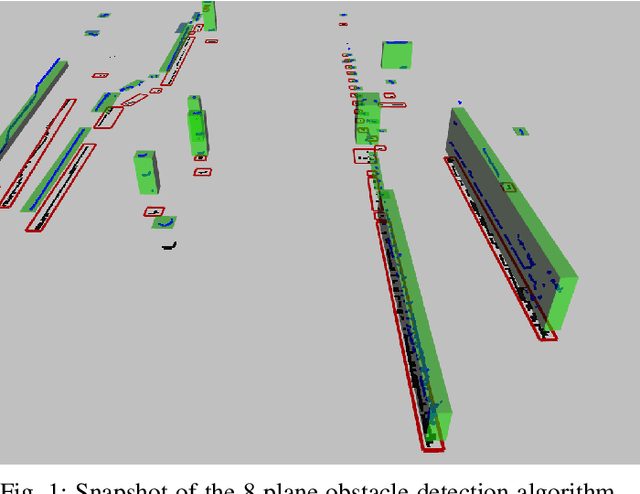


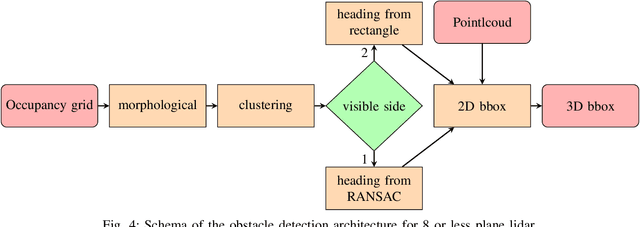
One of the main components of an autonomous vehicle is the obstacle detection pipeline. Most prototypes, both from research and industry, rely on lidars for this task. Pointcloud information from lidar is usually combined with data from cameras and radars, but the backbone of the architecture is mainly based on 3D bounding boxes computed from lidar data. To retrieve an accurate representation, sensors with many planes, e.g., greater than 32 planes, are usually employed. The returned pointcloud is indeed dense and well defined, but high-resolution sensors are still expensive and often require powerful GPUs to be processed. Lidars with fewer planes are cheaper, but the returned data are not dense enough to be processed with state of the art deep learning approaches to retrieve 3D bounding boxes. In this paper, we propose two solutions based on occupancy grid and geometric refinement to retrieve a list of 3D bounding boxes employing lidar with a low number of planes (i.e., 16 and 8 planes). Our solutions have been validated on a custom acquired dataset with accurate ground truth to prove its feasibility and accuracy.
The combination of context information to enhance simple question answering
Oct 09, 2018
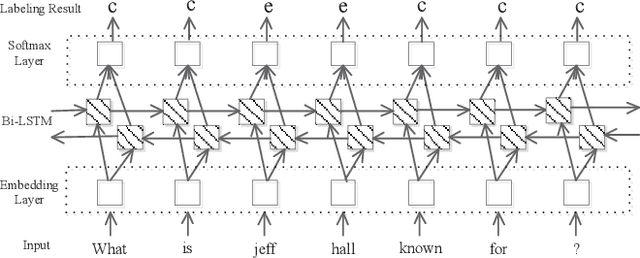
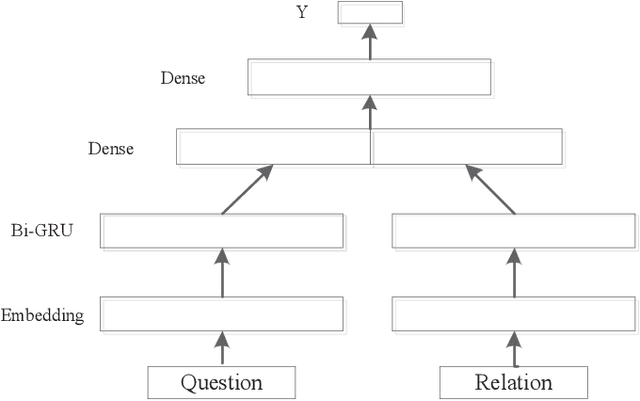
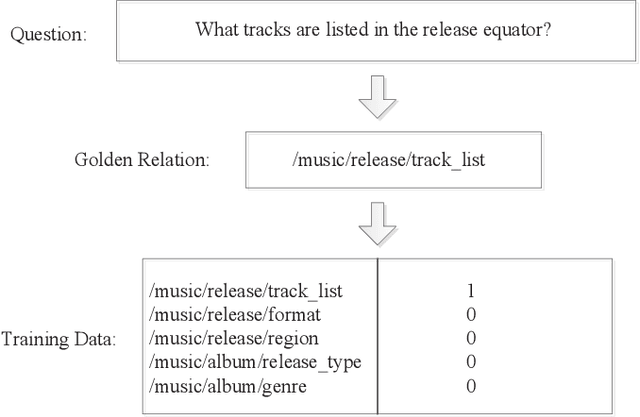
With the rapid development of knowledge base,question answering based on knowledge base has been a hot research issue. In this paper, we focus on answering singlerelation factoid questions based on knowledge base. We build a question answering system and study the effect of context information on fact selection, such as entity's notable type,outdegree. Experimental results show that context information can improve the result of simple question answering.