 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre More Tokens Rational? Inference-Time Scaling in Language Models as Adaptive Resource Rationality
Feb 10, 2026Human reasoning is shaped by resource rationality -- optimizing performance under constraints. Recently, inference-time scaling has emerged as a powerful paradigm to improve the reasoning performance of Large Language Models by expanding test-time computation. Specifically, instruction-tuned (IT) models explicitly generate long reasoning steps during inference, whereas Large Reasoning Models (LRMs) are trained by reinforcement learning to discover reasoning paths that maximize accuracy. However, it remains unclear whether resource-rationality can emerge from such scaling without explicit reward related to computational costs. We introduce a Variable Attribution Task in which models infer which variables determine outcomes given candidate variables, input-output trials, and predefined logical functions. By varying the number of candidate variables and trials, we systematically manipulate task complexity. Both models exhibit a transition from brute-force to analytic strategies as complexity increases. IT models degrade on XOR and XNOR functions, whereas LRMs remain robust. These findings suggest that models can adjust their reasoning behavior in response to task complexity, even without explicit cost-based reward. It provides compelling evidence that resource rationality is an emergent property of inference-time scaling itself.
The Representational Geometry of Number
Feb 06, 2026A central question in cognitive science is whether conceptual representations converge onto a shared manifold to support generalization, or diverge into orthogonal subspaces to minimize task interference. While prior work has discovered evidence for both, a mechanistic account of how these properties coexist and transform across tasks remains elusive. We propose that representational sharing lies not in the concepts themselves, but in the geometric relations between them. Using number concepts as a testbed and language models as high-dimensional computational substrates, we show that number representations preserve a stable relational structure across tasks. Task-specific representations are embedded in distinct subspaces, with low-level features like magnitude and parity encoded along separable linear directions. Crucially, we find that these subspaces are largely transformable into one another via linear mappings, indicating that representations share relational structure despite being located in distinct subspaces. Together, these results provide a mechanistic lens of how language models balance the shared structure of number representation with functional flexibility. It suggests that understanding arises when task-specific transformations are applied to a shared underlying relational structure of conceptual representations.
Sleep Staging Based on Multi Scale Dual Attention Network
Aug 14, 2021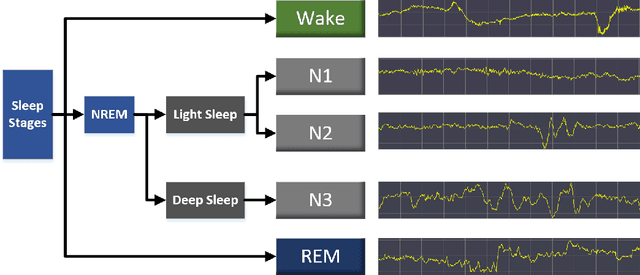

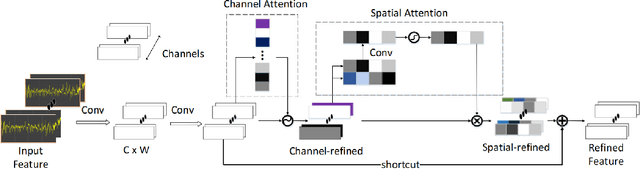

Sleep staging plays an important role on the diagnosis of sleep disorders. In general, experts classify sleep stages manually based on polysomnography (PSG), which is quite time-consuming. Meanwhile, the acquisition process of multiple signals is much complex, which can affect the subject's sleep. Therefore, the use of single-channel electroencephalogram (EEG) for automatic sleep staging has become a popular research topic. In the literature, a large number of sleep staging methods based on single-channel EEG have been proposed with promising results and achieve the preliminary automation of sleep staging. However, the performance for most of these methods in the N1 stage do not satisfy the needs of the diagnosis. In this paper, we propose a deep learning model multi scale dual attention network(MSDAN) based on raw EEG, which utilizes multi-scale convolution to extract features in different waveforms contained in the EEG signal, connects channel attention and spatial attention mechanisms in series to filter and highlight key information, and uses soft thresholding to remove redundant information. Experiments were conducted using two datasets with 5-fold cross-validation and hold-out validation method. The final average accuracy, overall accuracy, macro F1 score and Cohen's Kappa coefficient of the model reach 96.70%, 91.74%, 0.8231 and 0.8723 on the Sleep-EDF dataset, 96.14%, 90.35%, 0.7945 and 0.8284 on the Sleep-EDFx dataset. Significantly, our model performed superiorly in the N1 stage, with F1 scores of 54.41% and 52.79% on the two datasets respectively. The results show the superiority of our network over the existing methods, reaching a new state-of-the-art. In particular, the proposed method achieves excellent results in the N1 sleep stage compared to other methods.