 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Recognizing three-dimensional phase images with deep learning
Jul 22, 2021
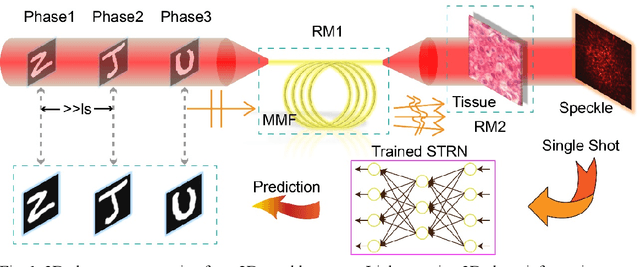
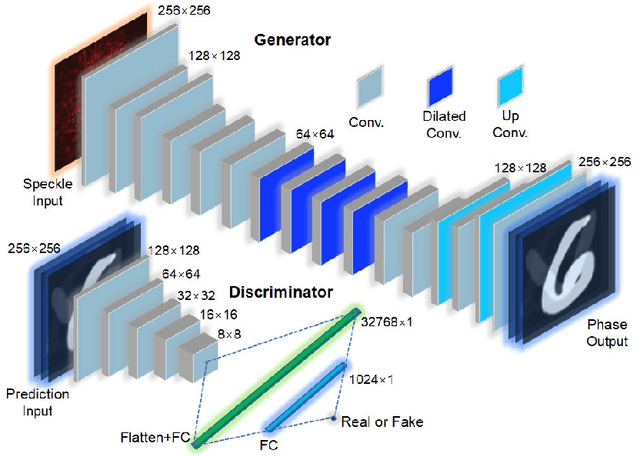
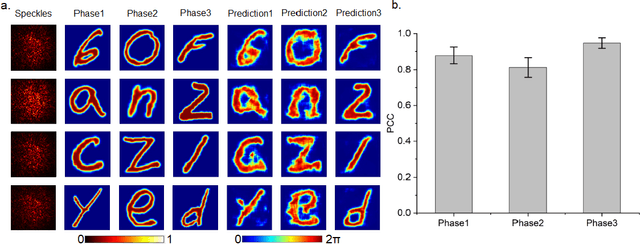
Optical phase contains key information for biomedical and astronomical imaging. However, it is often obscured by layers of heterogeneous and scattering media, which render optical phase imaging at different depths an utmost challenge. Limited by the memory effect, current methods for phase imaging in strong scattering media are inapplicable to retrieving phases at different depths. To address this challenge, we developed a speckle three-dimensional reconstruction network (STRN) to recognize phase objects behind scattering media, which circumvents the limitations of memory effect. From the single-shot, reference-free and scanning-free speckle pattern input, STRN distinguishes depth-resolving quantitative phase information with high fidelity. Our results promise broad applications in biomedical tomography and endoscopy.
Towards Federated Bayesian Network Structure Learning with Continuous Optimization
Oct 18, 2021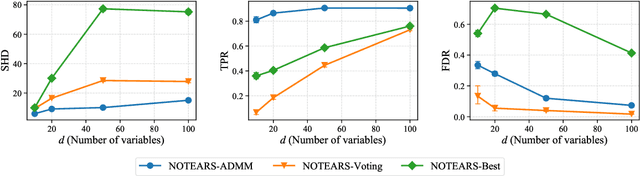
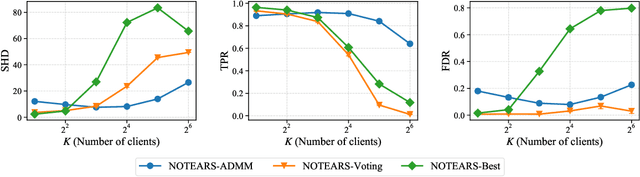
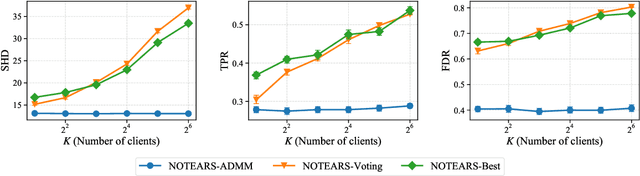
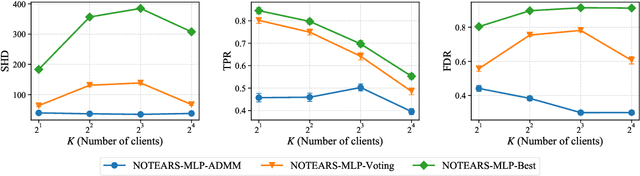
Traditionally, Bayesian network structure learning is often carried out at a central site, in which all data is gathered. However, in practice, data may be distributed across different parties (e.g., companies, devices) who intend to collectively learn a Bayesian network, but are not willing to disclose information related to their data owing to privacy or security concerns. In this work, we present a cross-silo federated learning approach to estimate the structure of Bayesian network from data that is horizontally partitioned across different parties. We develop a distributed structure learning method based on continuous optimization, using the alternating direction method of multipliers (ADMM), such that only the model parameters have to be exchanged during the optimization process. We demonstrate the flexibility of our approach by adopting it for both linear and nonlinear cases. Experimental results on synthetic and real datasets show that it achieves an improved performance over the other methods, especially when there is a relatively large number of clients and each has a limited sample size.
DOD-CNN: Doubly-injecting Object Information for Event Recognition
Nov 07, 2018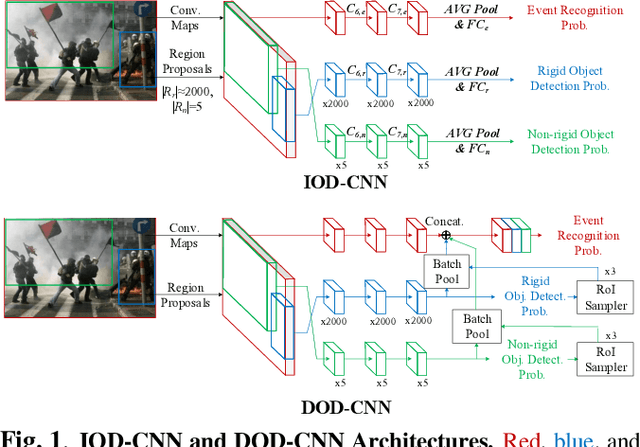

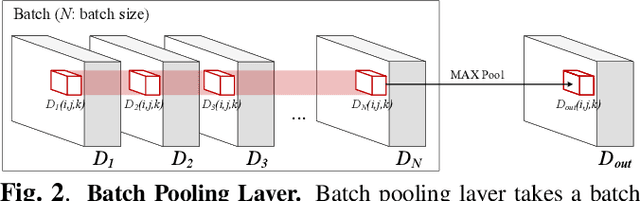
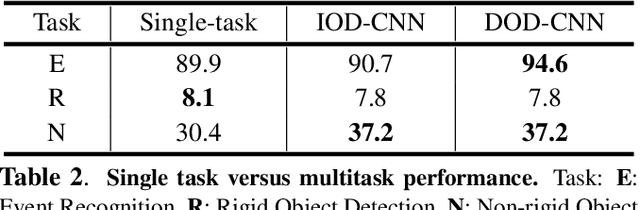
Recognizing an event in an image can be enhanced by detecting relevant objects in two ways: 1) indirectly utilizing object detection information within the unified architecture or 2) directly making use of the object detection output results. We introduce a novel approach, referred to as Doubly-injected Object Detection CNN (DOD-CNN), exploiting the object information in both ways for the task of event recognition. The structure of this network is inspired by the Integrated Object Detection CNN (IOD-CNN) where object information is indirectly exploited by the event recognition module through the shared portion of the network. In the DOD-CNN architecture, the intermediate object detection outputs are directly injected into the event recognition network while keeping the indirect sharing structure inherited from the IOD-CNN, thus being `doubly-injected'. We also introduce a batch pooling layer which constructs one representative feature map from multiple object hypotheses. We have demonstrated the effectiveness of injecting the object detection information in two different ways in the task of malicious event recognition.
MS-LaTTE: A Dataset of Where and When To-do Tasks are Completed
Nov 12, 2021
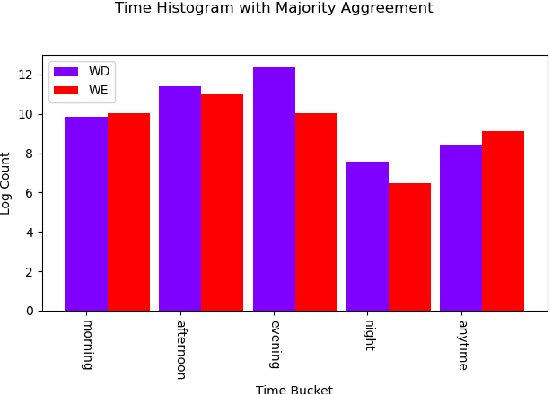
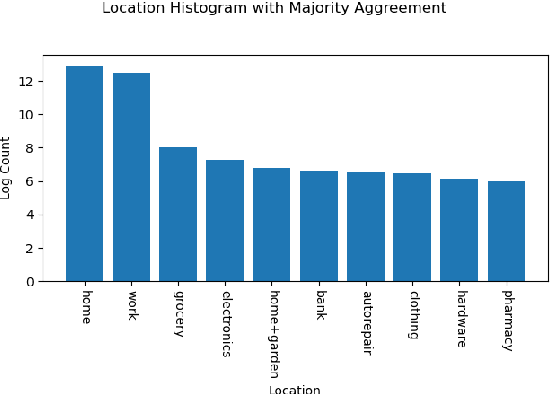
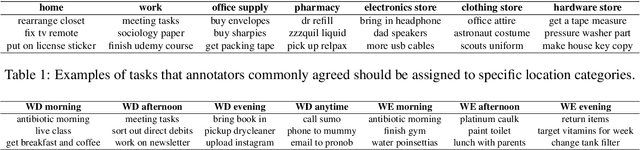
Tasks are a fundamental unit of work in the daily lives of people, who are increasingly using digital means to keep track of, organize, triage and act on them. These digital tools -- such as task management applications -- provide a unique opportunity to study and understand tasks and their connection to the real world, and through intelligent assistance, help people be more productive. By logging signals such as text, timestamp information, and social connectivity graphs, an increasingly rich and detailed picture of how tasks are created and organized, what makes them important, and who acts on them, can be progressively developed. Yet the context around actual task completion remains fuzzy, due to the basic disconnect between actions taken in the real world and telemetry recorded in the digital world. Thus, in this paper we compile and release a novel, real-life, large-scale dataset called MS-LaTTE that captures two core aspects of the context surrounding task completion: location and time. We describe our annotation framework and conduct a number of analyses on the data that were collected, demonstrating that it captures intuitive contextual properties for common tasks. Finally, we test the dataset on the two problems of predicting spatial and temporal task co-occurrence, concluding that predictors for co-location and co-time are both learnable, with a BERT fine-tuned model outperforming several other baselines. The MS-LaTTE dataset provides an opportunity to tackle many new modeling challenges in contextual task understanding and we hope that its release will spur future research in task intelligence more broadly.
Relation-aware Video Reading Comprehension for Temporal Language Grounding
Oct 12, 2021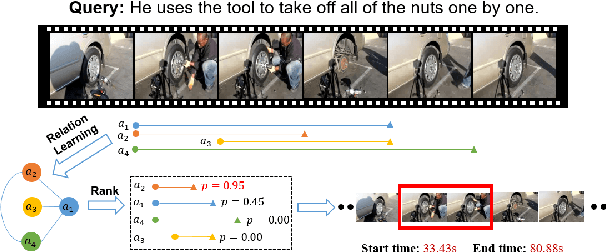
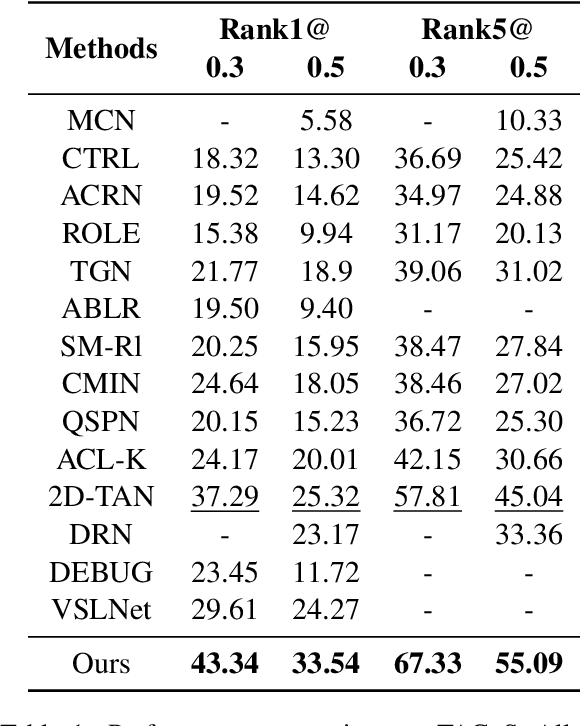
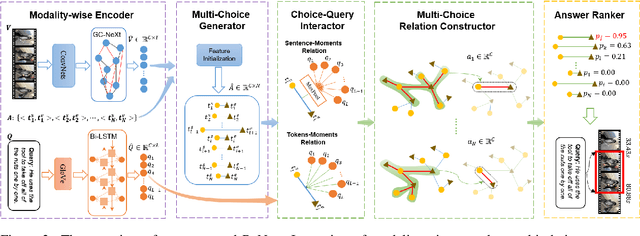
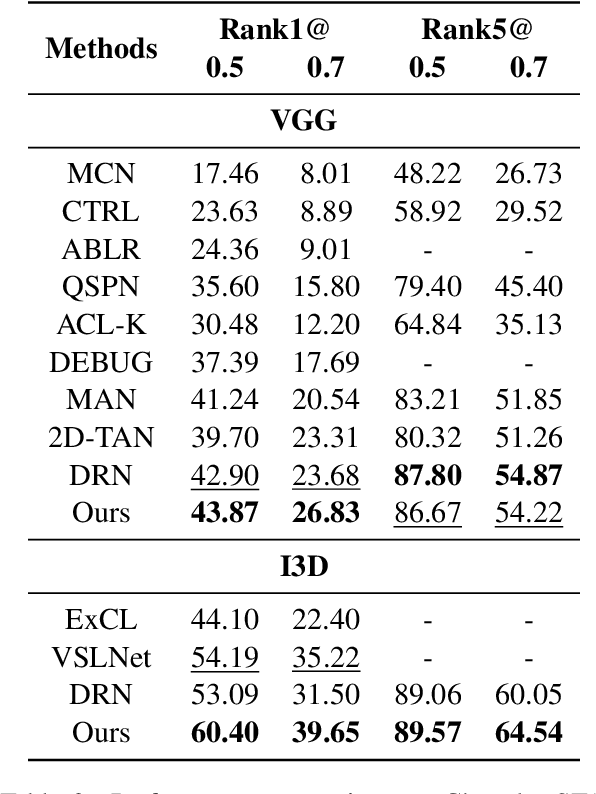
Temporal language grounding in videos aims to localize the temporal span relevant to the given query sentence. Previous methods treat it either as a boundary regression task or a span extraction task. This paper will formulate temporal language grounding into video reading comprehension and propose a Relation-aware Network (RaNet) to address it. This framework aims to select a video moment choice from the predefined answer set with the aid of coarse-and-fine choice-query interaction and choice-choice relation construction. A choice-query interactor is proposed to match the visual and textual information simultaneously in sentence-moment and token-moment levels, leading to a coarse-and-fine cross-modal interaction. Moreover, a novel multi-choice relation constructor is introduced by leveraging graph convolution to capture the dependencies among video moment choices for the best choice selection. Extensive experiments on ActivityNet-Captions, TACoS, and Charades-STA demonstrate the effectiveness of our solution. Codes will be released soon.
Segmentation of turbulent computational fluid dynamics simulations with unsupervised ensemble learning
Sep 03, 2021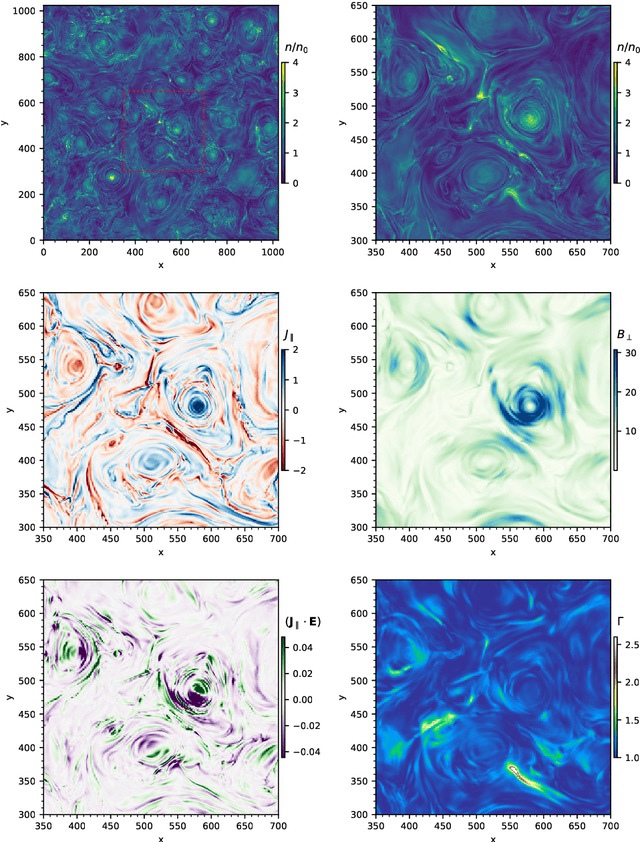
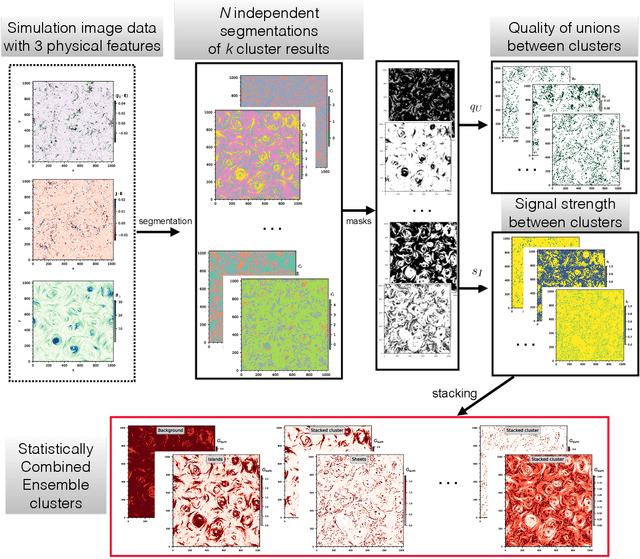
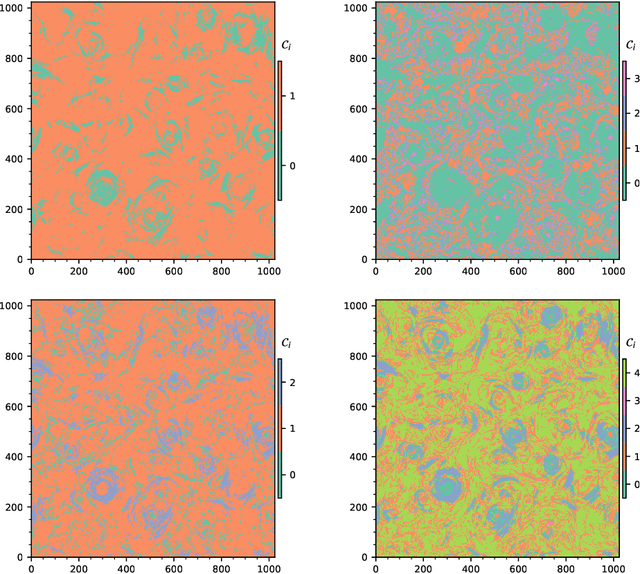
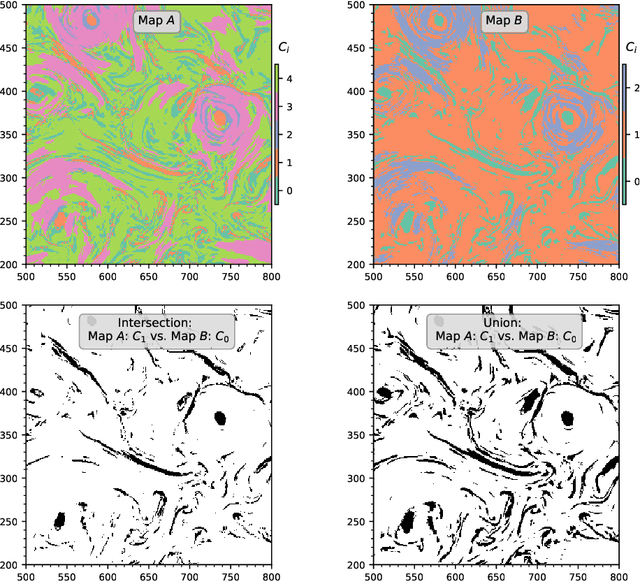
Computer vision and machine learning tools offer an exciting new way for automatically analyzing and categorizing information from complex computer simulations. Here we design an ensemble machine learning framework that can independently and robustly categorize and dissect simulation data output contents of turbulent flow patterns into distinct structure catalogues. The segmentation is performed using an unsupervised clustering algorithm, which segments physical structures by grouping together similar pixels in simulation images. The accuracy and robustness of the resulting segment region boundaries are enhanced by combining information from multiple simultaneously-evaluated clustering operations. The stacking of object segmentation evaluations is performed using image mask combination operations. This statistically-combined ensemble (SCE) of different cluster masks allows us to construct cluster reliability metrics for each pixel and for the associated segments without any prior user input. By comparing the similarity of different cluster occurrences in the ensemble, we can also assess the optimal number of clusters needed to describe the data. Furthermore, by relying on ensemble-averaged spatial segment region boundaries, the SCE method enables reconstruction of more accurate and robust region of interest (ROI) boundaries for the different image data clusters. We apply the SCE algorithm to 2-dimensional simulation data snapshots of magnetically-dominated fully-kinetic turbulent plasma flows where accurate ROI boundaries are needed for geometrical measurements of intermittent flow structures known as current sheets.
Curriculum Pre-Training Heterogeneous Subgraph Transformer for Top-$N$ Recommendation
Jun 12, 2021
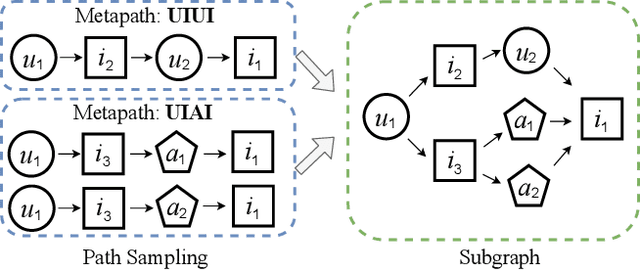
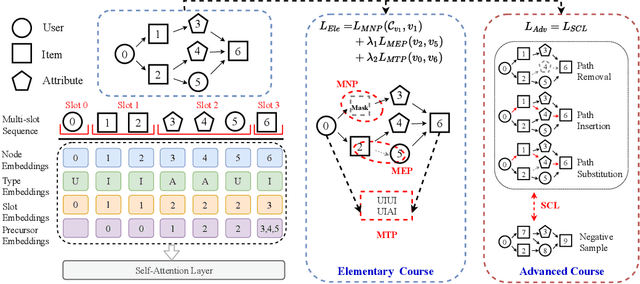
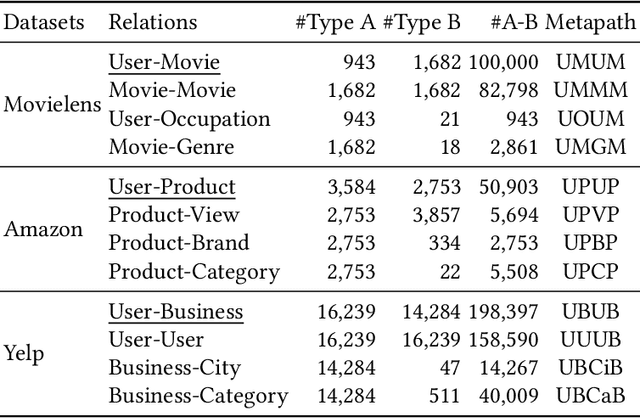
Due to the flexibility in modelling data heterogeneity, heterogeneous information network (HIN) has been adopted to characterize complex and heterogeneous auxiliary data in top-$N$ recommender systems, called \emph{HIN-based recommendation}. HIN characterizes complex, heterogeneous data relations, containing a variety of information that may not be related to the recommendation task. Therefore, it is challenging to effectively leverage useful information from HINs for improving the recommendation performance. To address the above issue, we propose a Curriculum pre-training based HEterogeneous Subgraph Transformer (called \emph{CHEST}) with new \emph{data characterization}, \emph{representation model} and \emph{learning algorithm}. Specifically, we consider extracting useful information from HIN to compose the interaction-specific heterogeneous subgraph, containing both sufficient and relevant context information for recommendation. Then we capture the rich semantics (\eg graph structure and path semantics) within the subgraph via a heterogeneous subgraph Transformer, where we encode the subgraph with multi-slot sequence representations. Besides, we design a curriculum pre-training strategy to provide an elementary-to-advanced learning process, by which we smoothly transfer basic semantics in HIN for modeling user-item interaction relation. Extensive experiments conducted on three real-world datasets demonstrate the superiority of our proposed method over a number of competitive baselines, especially when only limited training data is available.
A deep convolutional neural network for classification of Aedes albopictus mosquitoes
Oct 29, 2021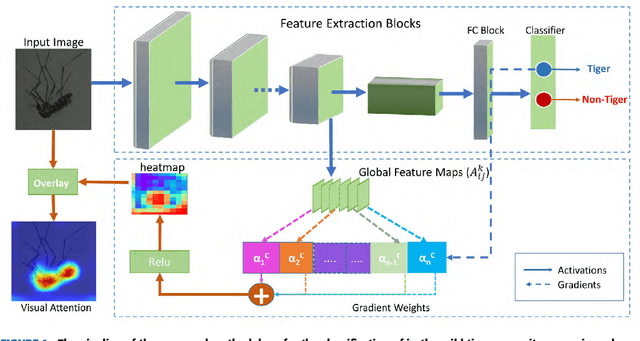
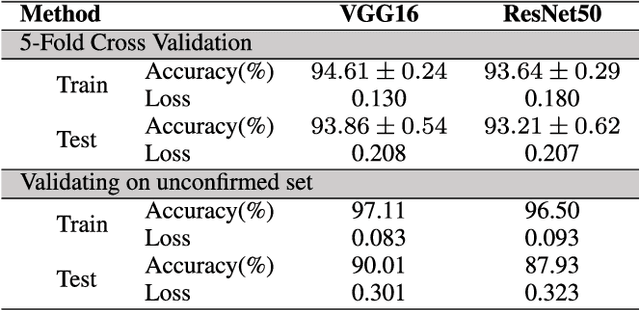

Monitoring the spread of disease-carrying mosquitoes is a first and necessary step to control severe diseases such as dengue, chikungunya, Zika or yellow fever. Previous citizen science projects have been able to obtain large image datasets with linked geo-tracking information. As the number of international collaborators grows, the manual annotation by expert entomologists of the large amount of data gathered by these users becomes too time demanding and unscalable, posing a strong need for automated classification of mosquito species from images. We introduce the application of two Deep Convolutional Neural Networks in a comparative study to automate this classification task. We use the transfer learning principle to train two state-of-the-art architectures on the data provided by the Mosquito Alert project, obtaining testing accuracy of 94%. In addition, we applied explainable models based on the Grad-CAM algorithm to visualise the most discriminant regions of the classified images, which coincide with the white band stripes located at the legs, abdomen, and thorax of mosquitoes of the Aedes albopictus species. The model allows us to further analyse the classification errors. Visual Grad-CAM models show that they are linked to poor acquisition conditions and strong image occlusions.
Exploring Separable Attention for Multi-Contrast MR Image Super-Resolution
Sep 03, 2021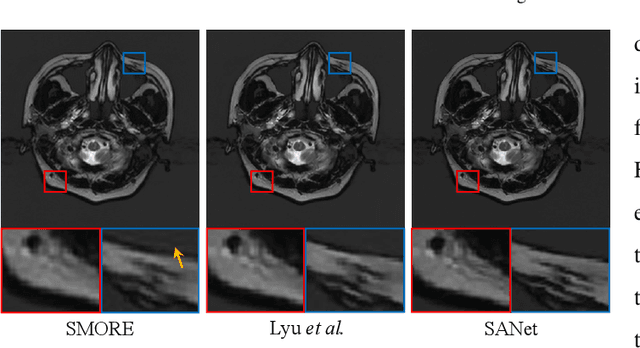
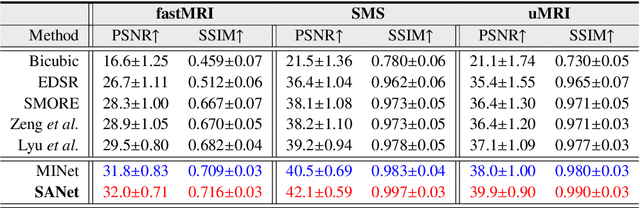
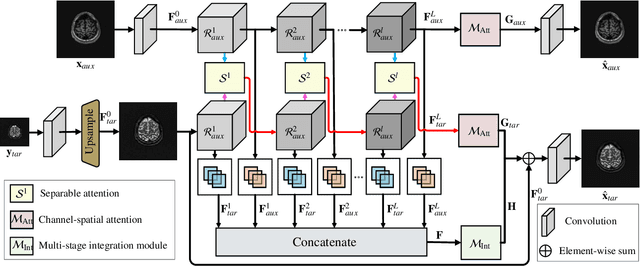
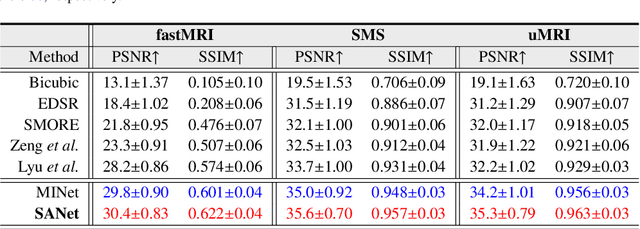
Super-resolving the Magnetic Resonance (MR) image of a target contrast under the guidance of the corresponding auxiliary contrast, which provides additional anatomical information, is a new and effective solution for fast MR imaging. However, current multi-contrast super-resolution (SR) methods tend to concatenate different contrasts directly, ignoring their relationships in different clues, \eg, in the foreground and background. In this paper, we propose a separable attention network (comprising a foreground priority attention and background separation attention), named SANet. Our method can explore the foreground and background areas in the forward and reverse directions with the help of the auxiliary contrast, enabling it to learn clearer anatomical structures and edge information for the SR of a target-contrast MR image. SANet provides three appealing benefits: (1) It is the first model to explore a separable attention mechanism that uses the auxiliary contrast to predict the foreground and background regions, diverting more attention to refining any uncertain details between these regions and correcting the fine areas in the reconstructed results. (2) A multi-stage integration module is proposed to learn the response of multi-contrast fusion at different stages, obtain the dependency between the fused features, and improve their representation ability. (3) Extensive experiments with various state-of-the-art multi-contrast SR methods on fastMRI and clinical \textit{in vivo} datasets demonstrate the superiority of our model.
Non-ground Abductive Logic Programming with Probabilistic Integrity Constraints
Aug 06, 2021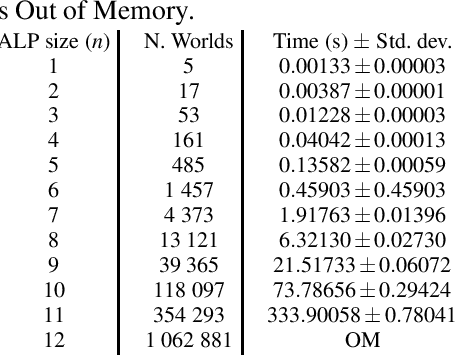

Uncertain information is being taken into account in an increasing number of application fields. In the meantime, abduction has been proved a powerful tool for handling hypothetical reasoning and incomplete knowledge. Probabilistic logical models are a suitable framework to handle uncertain information, and in the last decade many probabilistic logical languages have been proposed, as well as inference and learning systems for them. In the realm of Abductive Logic Programming (ALP), a variety of proof procedures have been defined as well. In this paper, we consider a richer logic language, coping with probabilistic abduction with variables. In particular, we consider an ALP program enriched with integrity constraints `a la IFF, possibly annotated with a probability value. We first present the overall abductive language, and its semantics according to the Distribution Semantics. We then introduce a proof procedure, obtained by extending one previously presented, and prove its soundness and completeness.