 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Hierarchical Alignment for UAV-based Human Detection using Diffusion Models
Dec 15, 2025Training object detectors demands extensive, task-specific annotations, yet this requirement becomes impractical in UAV-based human detection due to constantly shifting target distributions and the scarcity of labeled images. As a remedy, synthetic simulators are adopted to generate annotated data, with a low annotation cost. However, the domain gap between synthetic and real images hinders the model from being effectively applied to the target domain. Accordingly, we introduce Coarse-to-Fine Hierarchical Alignment (CFHA), a three-stage diffusion-based framework designed to transform synthetic data for UAV-based human detection, narrowing the domain gap while preserving the original synthetic labels. CFHA explicitly decouples global style and local content domain discrepancies and bridges those gaps using three modules: (1) Global Style Transfer -- a diffusion model aligns color, illumination, and texture statistics of synthetic images to the realistic style, using only a small real reference set; (2) Local Refinement -- a super-resolution diffusion model is used to facilitate fine-grained and photorealistic details for the small objects, such as human instances, preserving shape and boundary integrity; (3) Hallucination Removal -- a module that filters out human instances whose visual attributes do not align with real-world data to make the human appearance closer to the target distribution. Extensive experiments on public UAV Sim2Real detection benchmarks demonstrate that our methods significantly improve the detection accuracy compared to the non-transformed baselines. Specifically, our method achieves up to $+14.1$ improvement of mAP50 on Semantic-Drone benchmark. Ablation studies confirm the complementary roles of the global and local stages and highlight the importance of hierarchical alignment. The code is released at \href{https://github.com/liwd190019/CFHA}{this url}.
Generative Spatiotemporal Data Augmentation
Dec 14, 2025We explore spatiotemporal data augmentation using video foundation models to diversify both camera viewpoints and scene dynamics. Unlike existing approaches based on simple geometric transforms or appearance perturbations, our method leverages off-the-shelf video diffusion models to generate realistic 3D spatial and temporal variations from a given image dataset. Incorporating these synthesized video clips as supplemental training data yields consistent performance gains in low-data settings, such as UAV-captured imagery where annotations are scarce. Beyond empirical improvements, we provide practical guidelines for (i) choosing an appropriate spatiotemporal generative setup, (ii) transferring annotations to synthetic frames, and (iii) addressing disocclusion - regions newly revealed and unlabeled in generated views. Experiments on COCO subsets and UAV-captured datasets show that, when applied judiciously, spatiotemporal augmentation broadens the data distribution along axes underrepresented by traditional and prior generative methods, offering an effective lever for improving model performance in data-scarce regimes.
MoRe: Monocular Geometry Refinement via Graph Optimization for Cross-View Consistency
Oct 08, 2025



Monocular 3D foundation models offer an extensible solution for perception tasks, making them attractive for broader 3D vision applications. In this paper, we propose MoRe, a training-free Monocular Geometry Refinement method designed to improve cross-view consistency and achieve scale alignment. To induce inter-frame relationships, our method employs feature matching between frames to establish correspondences. Rather than applying simple least squares optimization on these matched points, we formulate a graph-based optimization framework that performs local planar approximation using the estimated 3D points and surface normals estimated by monocular foundation models. This formulation addresses the scale ambiguity inherent in monocular geometric priors while preserving the underlying 3D structure. We further demonstrate that MoRe not only enhances 3D reconstruction but also improves novel view synthesis, particularly in sparse view rendering scenarios.
UAV4D: Dynamic Neural Rendering of Human-Centric UAV Imagery using Gaussian Splatting
Jun 05, 2025Despite significant advancements in dynamic neural rendering, existing methods fail to address the unique challenges posed by UAV-captured scenarios, particularly those involving monocular camera setups, top-down perspective, and multiple small, moving humans, which are not adequately represented in existing datasets. In this work, we introduce UAV4D, a framework for enabling photorealistic rendering for dynamic real-world scenes captured by UAVs. Specifically, we address the challenge of reconstructing dynamic scenes with multiple moving pedestrians from monocular video data without the need for additional sensors. We use a combination of a 3D foundation model and a human mesh reconstruction model to reconstruct both the scene background and humans. We propose a novel approach to resolve the scene scale ambiguity and place both humans and the scene in world coordinates by identifying human-scene contact points. Additionally, we exploit the SMPL model and background mesh to initialize Gaussian splats, enabling holistic scene rendering. We evaluated our method on three complex UAV-captured datasets: VisDrone, Manipal-UAV, and Okutama-Action, each with distinct characteristics and 10~50 humans. Our results demonstrate the benefits of our approach over existing methods in novel view synthesis, achieving a 1.5 dB PSNR improvement and superior visual sharpness.
UAVTwin: Neural Digital Twins for UAVs using Gaussian Splatting
Apr 02, 2025



We present UAVTwin, a method for creating digital twins from real-world environments and facilitating data augmentation for training downstream models embedded in unmanned aerial vehicles (UAVs). Specifically, our approach focuses on synthesizing foreground components, such as various human instances in motion within complex scene backgrounds, from UAV perspectives. This is achieved by integrating 3D Gaussian Splatting (3DGS) for reconstructing backgrounds along with controllable synthetic human models that display diverse appearances and actions in multiple poses. To the best of our knowledge, UAVTwin is the first approach for UAV-based perception that is capable of generating high-fidelity digital twins based on 3DGS. The proposed work significantly enhances downstream models through data augmentation for real-world environments with multiple dynamic objects and significant appearance variations-both of which typically introduce artifacts in 3DGS-based modeling. To tackle these challenges, we propose a novel appearance modeling strategy and a mask refinement module to enhance the training of 3D Gaussian Splatting. We demonstrate the high quality of neural rendering by achieving a 1.23 dB improvement in PSNR compared to recent methods. Furthermore, we validate the effectiveness of data augmentation by showing a 2.5% to 13.7% improvement in mAP for the human detection task.
AutoComPose: Automatic Generation of Pose Transition Descriptions for Composed Pose Retrieval Using Multimodal LLMs
Mar 28, 2025



Composed pose retrieval (CPR) enables users to search for human poses by specifying a reference pose and a transition description, but progress in this field is hindered by the scarcity and inconsistency of annotated pose transitions. Existing CPR datasets rely on costly human annotations or heuristic-based rule generation, both of which limit scalability and diversity. In this work, we introduce AutoComPose, the first framework that leverages multimodal large language models (MLLMs) to automatically generate rich and structured pose transition descriptions. Our method enhances annotation quality by structuring transitions into fine-grained body part movements and introducing mirrored/swapped variations, while a cyclic consistency constraint ensures logical coherence between forward and reverse transitions. To advance CPR research, we construct and release two dedicated benchmarks, AIST-CPR and PoseFixCPR, supplementing prior datasets with enhanced attributes. Extensive experiments demonstrate that training retrieval models with AutoComPose yields superior performance over human-annotated and heuristic-based methods, significantly reducing annotation costs while improving retrieval quality. Our work pioneers the automatic annotation of pose transitions, establishing a scalable foundation for future CPR research.
SynPlay: Importing Real-world Diversity for a Synthetic Human Dataset
Aug 21, 2024



We introduce Synthetic Playground (SynPlay), a new synthetic human dataset that aims to bring out the diversity of human appearance in the real world. We focus on two factors to achieve a level of diversity that has not yet been seen in previous works: i) realistic human motions and poses and ii) multiple camera viewpoints towards human instances. We first use a game engine and its library-provided elementary motions to create games where virtual players can take less-constrained and natural movements while following the game rules (i.e., rule-guided motion design as opposed to detail-guided design). We then augment the elementary motions with real human motions captured with a motion capture device. To render various human appearances in the games from multiple viewpoints, we use seven virtual cameras encompassing the ground and aerial views, capturing abundant aerial-vs-ground and dynamic-vs-static attributes of the scene. Through extensive and carefully-designed experiments, we show that using SynPlay in model training leads to enhanced accuracy over existing synthetic datasets for human detection and segmentation. The benefit of SynPlay becomes even greater for tasks in the data-scarce regime, such as few-shot and cross-domain learning tasks. These results clearly demonstrate that SynPlay can be used as an essential dataset with rich attributes of complex human appearances and poses suitable for model pretraining. SynPlay dataset comprising over 73k images and 6.5M human instances, is available for download at https://synplaydataset.github.io/.
Negative Samples are at Large: Leveraging Hard-distance Elastic Loss for Re-identification
Jul 20, 2022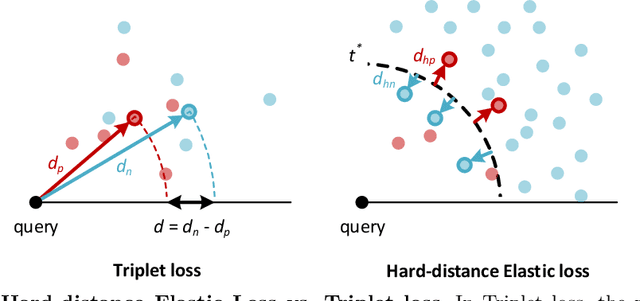
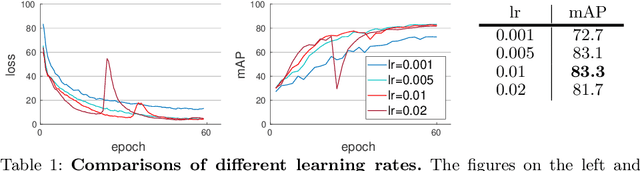
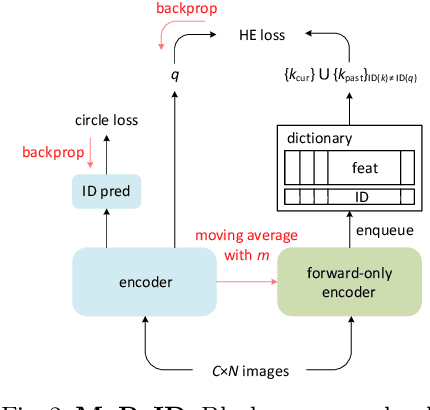
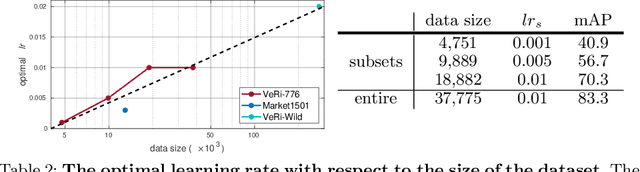
We present a Momentum Re-identification (MoReID) framework that can leverage a very large number of negative samples in training for general re-identification task. The design of this framework is inspired by Momentum Contrast (MoCo), which uses a dictionary to store current and past batches to build a large set of encoded samples. As we find it less effective to use past positive samples which may be highly inconsistent to the encoded feature property formed with the current positive samples, MoReID is designed to use only a large number of negative samples stored in the dictionary. However, if we train the model using the widely used Triplet loss that uses only one sample to represent a set of positive/negative samples, it is hard to effectively leverage the enlarged set of negative samples acquired by the MoReID framework. To maximize the advantage of using the scaled-up negative sample set, we newly introduce Hard-distance Elastic loss (HE loss), which is capable of using more than one hard sample to represent a large number of samples. Our experiments demonstrate that a large number of negative samples provided by MoReID framework can be utilized at full capacity only with the HE loss, achieving the state-of-the-art accuracy on three re-ID benchmarks, VeRi-776, Market-1501, and VeRi-Wild.
Exploring Cross-Domain Pretrained Model for Hyperspectral Image Classification
Apr 07, 2022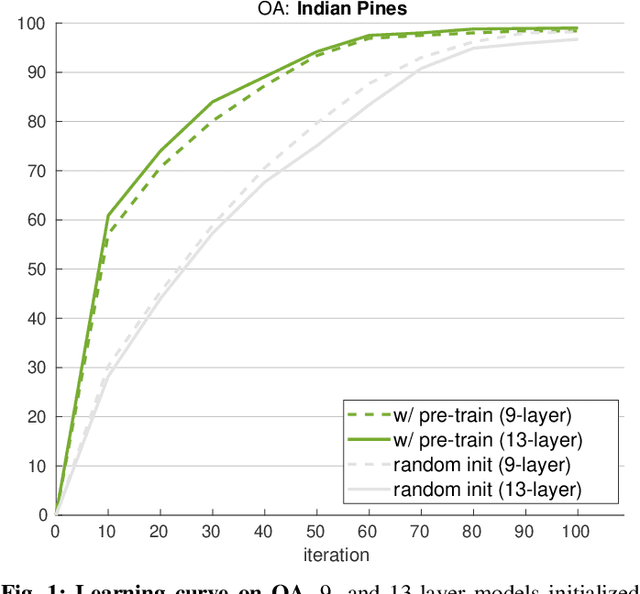
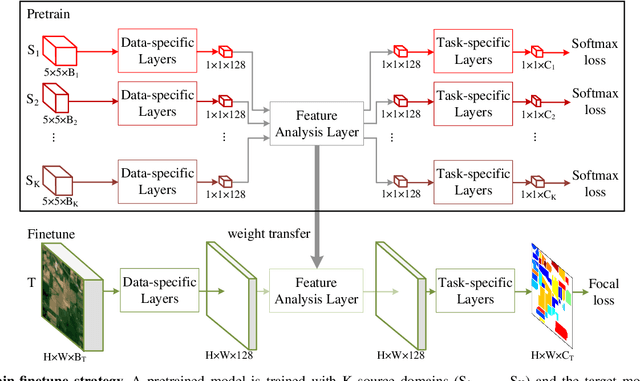
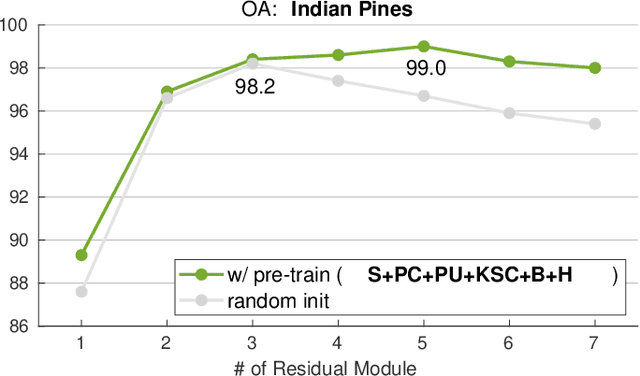
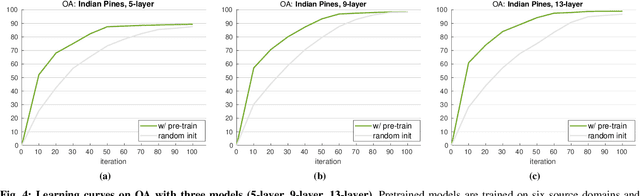
A pretrain-finetune strategy is widely used to reduce the overfitting that can occur when data is insufficient for CNN training. First few layers of a CNN pretrained on a large-scale RGB dataset are capable of acquiring general image characteristics which are remarkably effective in tasks targeted for different RGB datasets. However, when it comes down to hyperspectral domain where each domain has its unique spectral properties, the pretrain-finetune strategy no longer can be deployed in a conventional way while presenting three major issues: 1) inconsistent spectral characteristics among the domains (e.g., frequency range), 2) inconsistent number of data channels among the domains, and 3) absence of large-scale hyperspectral dataset. We seek to train a universal cross-domain model which can later be deployed for various spectral domains. To achieve, we physically furnish multiple inlets to the model while having a universal portion which is designed to handle the inconsistent spectral characteristics among different domains. Note that only the universal portion is used in the finetune process. This approach naturally enables the learning of our model on multiple domains simultaneously which acts as an effective workaround for the issue of the absence of large-scale dataset. We have carried out a study to extensively compare models that were trained using cross-domain approach with ones trained from scratch. Our approach was found to be superior both in accuracy and in training efficiency. In addition, we have verified that our approach effectively reduces the overfitting issue, enabling us to deepen the model up to 13 layers (from 9) without compromising the accuracy.
Semantics to Space(S2S): Embedding semantics into spatial space for zero-shot verb-object query inferencing
Jun 13, 2019
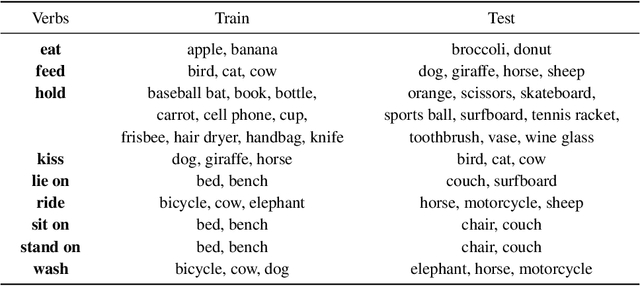
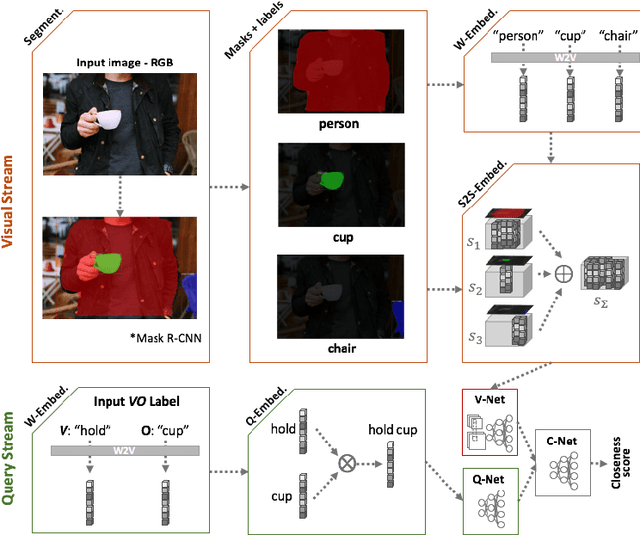

We present a novel deep zero-shot learning (ZSL) model for inferencing human-object-interaction with verb-object (VO) query. While the previous ZSL approaches only use the semantic/textual information to be fed into the query stream, we seek to incorporate and embed the semantics into the visual representation stream as well. Our approach is powered by Semantics-to-Space (S2S) architecture where semantics derived from the residing objects are embedded into a spatial space. This architecture allows the co-capturing of the semantic attributes of the human and the objects along with their location/size/silhouette information. As this is the first attempt to address the zero-shot human-object-interaction inferencing with VO query, we have constructed a new dataset, Verb-Transferability 60 (VT60). VT60 provides 60 different VO pairs with overlapping verbs tailored for testing ZSL approaches with VO query. Experimental evaluations show that our approach not only outperforms the state-of-the-art, but also shows the capability of consistently improving performance regardless of which ZSL baseline architecture is used.