 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Belief Domains into Probabilistic Logic Programs
Jul 23, 2025
Probabilistic Logic Programming (PLP) under the Distribution Semantics is a leading approach to practical reasoning under uncertainty. An advantage of the Distribution Semantics is its suitability for implementation as a Prolog or Python library, available through two well-maintained implementations, namely ProbLog and cplint/PITA. However, current formulations of the Distribution Semantics use point-probabilities, making it difficult to express epistemic uncertainty, such as arises from, for example, hierarchical classifications from computer vision models. Belief functions generalize probability measures as non-additive capacities, and address epistemic uncertainty via interval probabilities. This paper introduces interval-based Capacity Logic Programs based on an extension of the Distribution Semantics to include belief functions, and describes properties of the new framework that make it amenable to practical applications.
Probabilistic Answer Set Programming with Discrete and Continuous Random Variables
Sep 30, 2024Probabilistic Answer Set Programming under the credal semantics (PASP) extends Answer Set Programming with probabilistic facts that represent uncertain information. The probabilistic facts are discrete with Bernoulli distributions. However, several real-world scenarios require a combination of both discrete and continuous random variables. In this paper, we extend the PASP framework to support continuous random variables and propose Hybrid Probabilistic Answer Set Programming (HPASP). Moreover, we discuss, implement, and assess the performance of two exact algorithms based on projected answer set enumeration and knowledge compilation and two approximate algorithms based on sampling. Empirical results, also in line with known theoretical results, show that exact inference is feasible only for small instances, but knowledge compilation has a huge positive impact on the performance. Sampling allows handling larger instances, but sometimes requires an increasing amount of memory. Under consideration in Theory and Practice of Logic Programming (TPLP).
Solving Decision Theory Problems with Probabilistic Answer Set Programming
Aug 21, 2024Solving a decision theory problem usually involves finding the actions, among a set of possible ones, which optimize the expected reward, possibly accounting for the uncertainty of the environment. In this paper, we introduce the possibility to encode decision theory problems with Probabilistic Answer Set Programming under the credal semantics via decision atoms and utility attributes. To solve the task we propose an algorithm based on three layers of Algebraic Model Counting, that we test on several synthetic datasets against an algorithm that adopts answer set enumeration. Empirical results show that our algorithm can manage non trivial instances of programs in a reasonable amount of time. Under consideration in Theory and Practice of Logic Programming (TPLP).
Symbolic Parameter Learning in Probabilistic Answer Set Programming
Aug 16, 2024



Parameter learning is a crucial task in the field of Statistical Relational Artificial Intelligence: given a probabilistic logic program and a set of observations in the form of interpretations, the goal is to learn the probabilities of the facts in the program such that the probabilities of the interpretations are maximized. In this paper, we propose two algorithms to solve such a task within the formalism of Probabilistic Answer Set Programming, both based on the extraction of symbolic equations representing the probabilities of the interpretations. The first solves the task using an off-the-shelf constrained optimization solver while the second is based on an implementation of the Expectation Maximization algorithm. Empirical results show that our proposals often outperform existing approaches based on projected answer set enumeration in terms of quality of the solution and in terms of execution time. The paper has been accepted at the ICLP2024 conference and is under consideration in Theory and Practice of Logic Programming (TPLP).
Fast Inference for Probabilistic Answer Set Programs via the Residual Program
Aug 14, 2024When we want to compute the probability of a query from a Probabilistic Answer Set Program, some parts of a program may not influence the probability of a query, but they impact on the size of the grounding. Identifying and removing them is crucial to speed up the computation. Algorithms for SLG resolution offer the possibility of returning the residual program which can be used for computing answer sets for normal programs that do have a total well-founded model. The residual program does not contain the parts of the program that do not influence the probability. In this paper, we propose to exploit the residual program for performing inference. Empirical results on graph datasets show that the approach leads to significantly faster inference.
A Synergistic Approach In Network Intrusion Detection By Neurosymbolic AI
Jun 03, 2024The prevailing approaches in Network Intrusion Detection Systems (NIDS) are often hampered by issues such as high resource consumption, significant computational demands, and poor interpretability. Furthermore, these systems generally struggle to identify novel, rapidly changing cyber threats. This paper delves into the potential of incorporating Neurosymbolic Artificial Intelligence (NSAI) into NIDS, combining deep learning's data-driven strengths with symbolic AI's logical reasoning to tackle the dynamic challenges in cybersecurity, which also includes detailed NSAI techniques introduction for cyber professionals to explore the potential strengths of NSAI in NIDS. The inclusion of NSAI in NIDS marks potential advancements in both the detection and interpretation of intricate network threats, benefiting from the robust pattern recognition of neural networks and the interpretive prowess of symbolic reasoning. By analyzing network traffic data types and machine learning architectures, we illustrate NSAI's distinctive capability to offer more profound insights into network behavior, thereby improving both detection performance and the adaptability of the system. This merging of technologies not only enhances the functionality of traditional NIDS but also sets the stage for future developments in building more resilient, interpretable, and dynamic defense mechanisms against advanced cyber threats. The continued progress in this area is poised to transform NIDS into a system that is both responsive to known threats and anticipatory of emerging, unseen ones.
Exploiting Uncertainty for Querying Inconsistent Description Logics Knowledge Bases
Jun 15, 2023



The necessity to manage inconsistency in Description Logics Knowledge Bases (KBs) has come to the fore with the increasing importance gained by the Semantic Web, where information comes from different sources that constantly change their content and may contain contradictory descriptions when considered either alone or together. Classical reasoning algorithms do not handle inconsistent KBs, forcing the debugging of the KB in order to remove the inconsistency. In this paper, we exploit an existing probabilistic semantics called DISPONTE to overcome this problem and allow queries also in case of inconsistent KBs. We implemented our approach in the reasoners TRILL and BUNDLE and empirically tested the validity of our proposal. Moreover, we formally compare the presented approach to that of the repair semantics, one of the most established semantics when considering DL reasoning tasks.
Syntactic Requirements for Well-defined Hybrid Probabilistic Logic Programs
Sep 17, 2021Hybrid probabilistic logic programs can represent several scenarios thanks to the expressivity of Logic Programming extended with facts representing discrete and continuous distributions. The semantics for this type of programs is crucial since it ensures that a probability can be assigned to every query. Here, following one recent semantics proposal, we illustrate a concrete syntax, and we analyse the syntactic requirements needed to preserve the well-definedness.
* In Proceedings ICLP 2021, arXiv:2109.07914
Non-ground Abductive Logic Programming with Probabilistic Integrity Constraints
Aug 06, 2021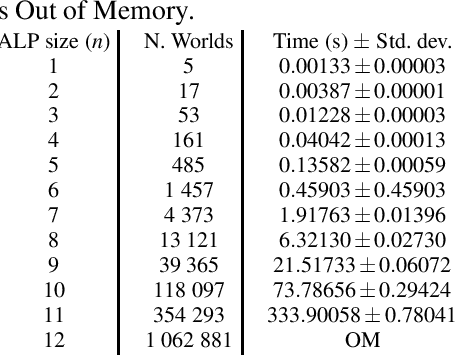

Uncertain information is being taken into account in an increasing number of application fields. In the meantime, abduction has been proved a powerful tool for handling hypothetical reasoning and incomplete knowledge. Probabilistic logical models are a suitable framework to handle uncertain information, and in the last decade many probabilistic logical languages have been proposed, as well as inference and learning systems for them. In the realm of Abductive Logic Programming (ALP), a variety of proof procedures have been defined as well. In this paper, we consider a richer logic language, coping with probabilistic abduction with variables. In particular, we consider an ALP program enriched with integrity constraints `a la IFF, possibly annotated with a probability value. We first present the overall abductive language, and its semantics according to the Distribution Semantics. We then introduce a proof procedure, obtained by extending one previously presented, and prove its soundness and completeness.
A Framework for Reasoning on Probabilistic Description Logics
Oct 02, 2020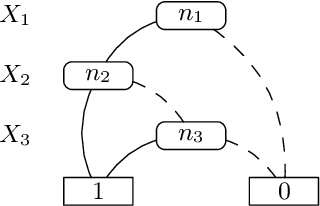

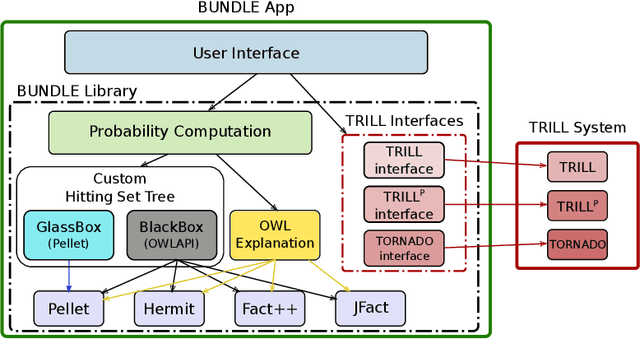
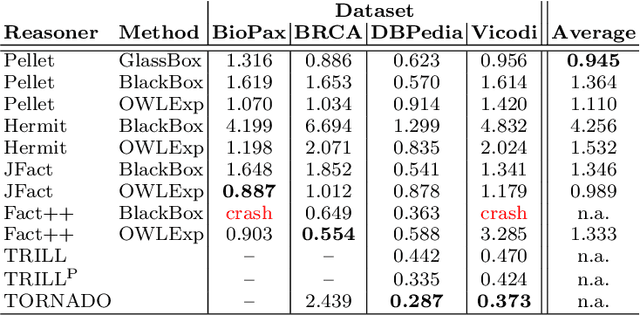
While there exist several reasoners for Description Logics, very few of them can cope with uncertainty. BUNDLE is an inference framework that can exploit several OWL (non-probabilistic) reasoners to perform inference over Probabilistic Description Logics. In this chapter, we report the latest advances implemented in BUNDLE. In particular, BUNDLE can now interface with the reasoners of the TRILL system, thus providing a uniform method to execute probabilistic queries using different settings. BUNDLE can be easily extended and can be used either as a standalone desktop application or as a library in OWL API-based applications that need to reason over Probabilistic Description Logics. The reasoning performance heavily depends on the reasoner and method used to compute the probability. We provide a comparison of the different reasoning settings on several datasets.