 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fast Camouflaged Object Detection via Edge-based Reversible Re-calibration Network
Nov 05, 2021
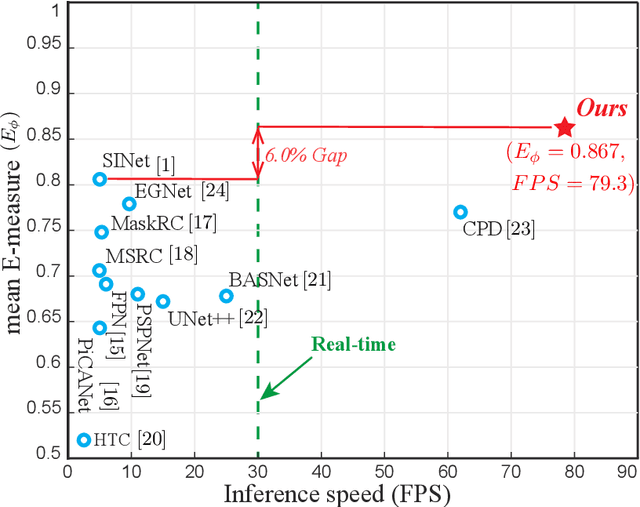
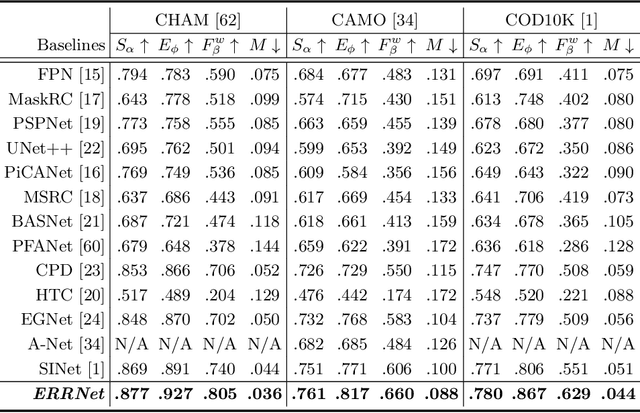
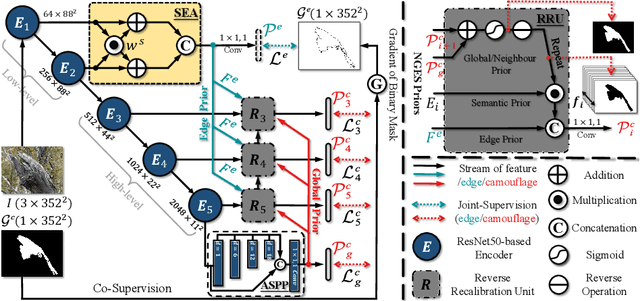
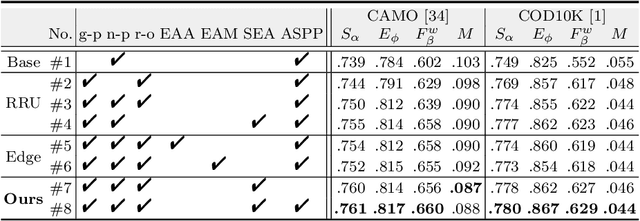
Camouflaged Object Detection (COD) aims to detect objects with similar patterns (e.g., texture, intensity, colour, etc) to their surroundings, and recently has attracted growing research interest. As camouflaged objects often present very ambiguous boundaries, how to determine object locations as well as their weak boundaries is challenging and also the key to this task. Inspired by the biological visual perception process when a human observer discovers camouflaged objects, this paper proposes a novel edge-based reversible re-calibration network called ERRNet. Our model is characterized by two innovative designs, namely Selective Edge Aggregation (SEA) and Reversible Re-calibration Unit (RRU), which aim to model the visual perception behaviour and achieve effective edge prior and cross-comparison between potential camouflaged regions and background. More importantly, RRU incorporates diverse priors with more comprehensive information comparing to existing COD models. Experimental results show that ERRNet outperforms existing cutting-edge baselines on three COD datasets and five medical image segmentation datasets. Especially, compared with the existing top-1 model SINet, ERRNet significantly improves the performance by $\sim$6% (mean E-measure) with notably high speed (79.3 FPS), showing that ERRNet could be a general and robust solution for the COD task.
MobIE: A German Dataset for Named Entity Recognition, Entity Linking and Relation Extraction in the Mobility Domain
Aug 16, 2021
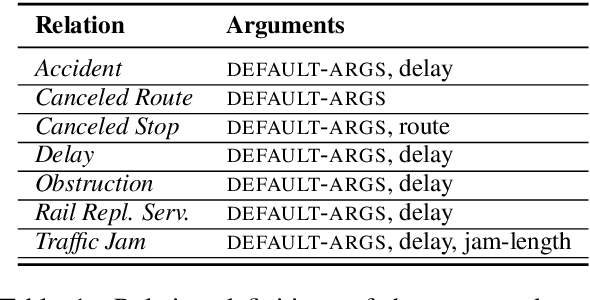
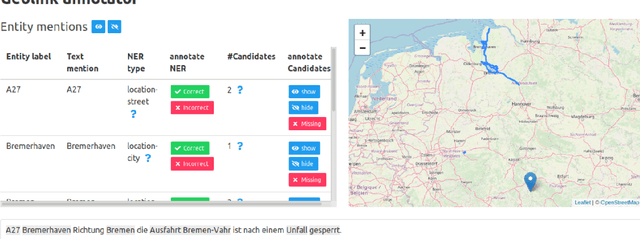
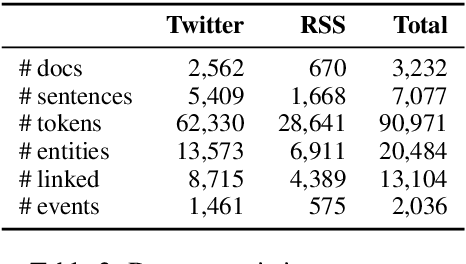
We present MobIE, a German-language dataset, which is human-annotated with 20 coarse- and fine-grained entity types and entity linking information for geographically linkable entities. The dataset consists of 3,232 social media texts and traffic reports with 91K tokens, and contains 20.5K annotated entities, 13.1K of which are linked to a knowledge base. A subset of the dataset is human-annotated with seven mobility-related, n-ary relation types, while the remaining documents are annotated using a weakly-supervised labeling approach implemented with the Snorkel framework. To the best of our knowledge, this is the first German-language dataset that combines annotations for NER, EL and RE, and thus can be used for joint and multi-task learning of these fundamental information extraction tasks. We make MobIE public at https://github.com/dfki-nlp/mobie.
Feature-Rich Named Entity Recognition for Bulgarian Using Conditional Random Fields
Sep 26, 2021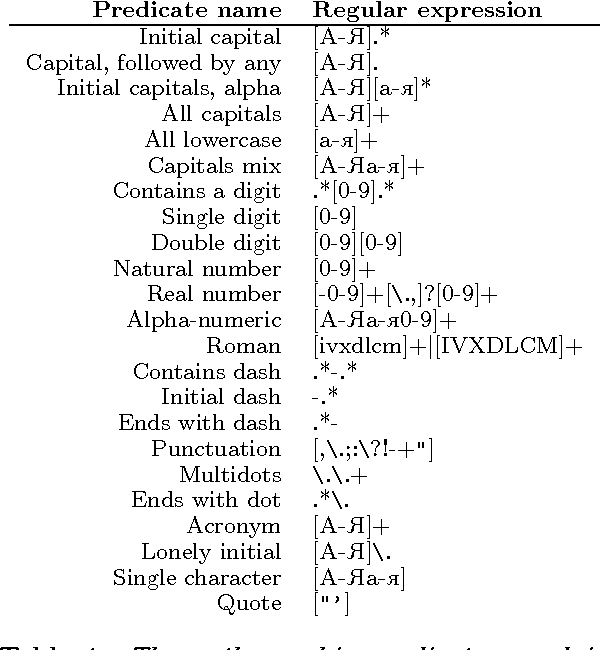

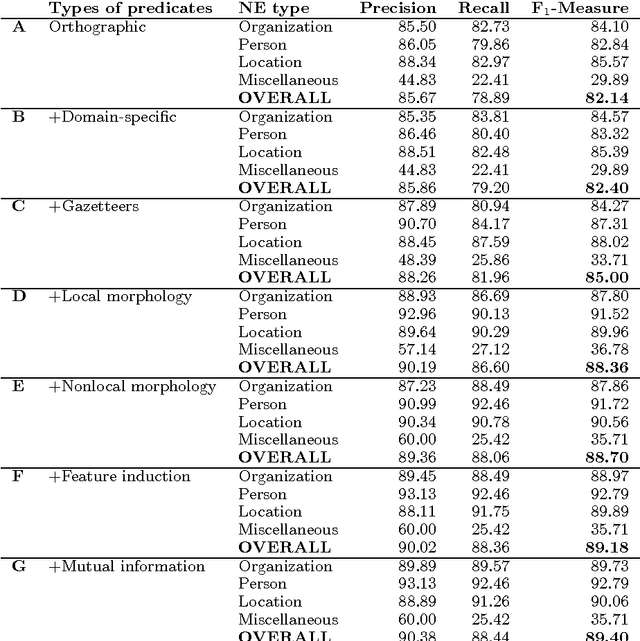
The paper presents a feature-rich approach to the automatic recognition and categorization of named entities (persons, organizations, locations, and miscellaneous) in news text for Bulgarian. We combine well-established features used for other languages with language-specific lexical, syntactic and morphological information. In particular, we make use of the rich tagset annotation of the BulTreeBank (680 morpho-syntactic tags), from which we derive suitable task-specific tagsets (local and nonlocal). We further add domain-specific gazetteers and additional unlabeled data, achieving F1=89.4%, which is comparable to the state-of-the-art results for English.
* named entity recognition, NER, conditional random fields, CRF, Bulgarian, BulTreeBank
Machine learning Hadron Spectral Functions in Lattice QCD
Dec 01, 2021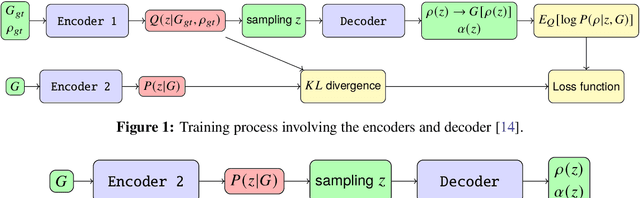
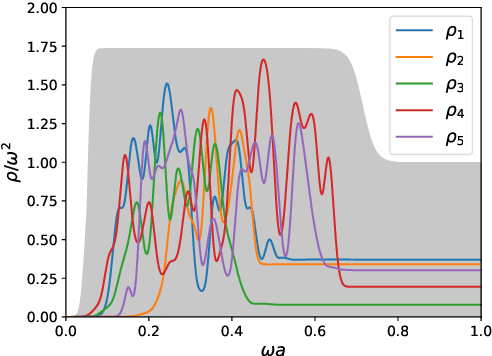
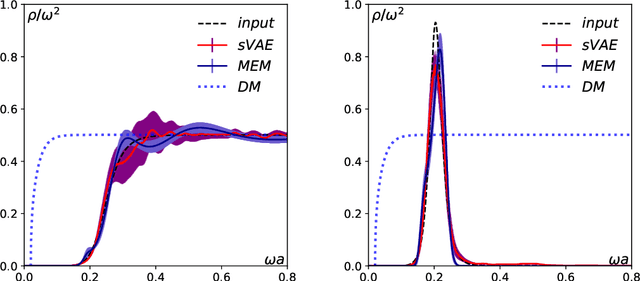
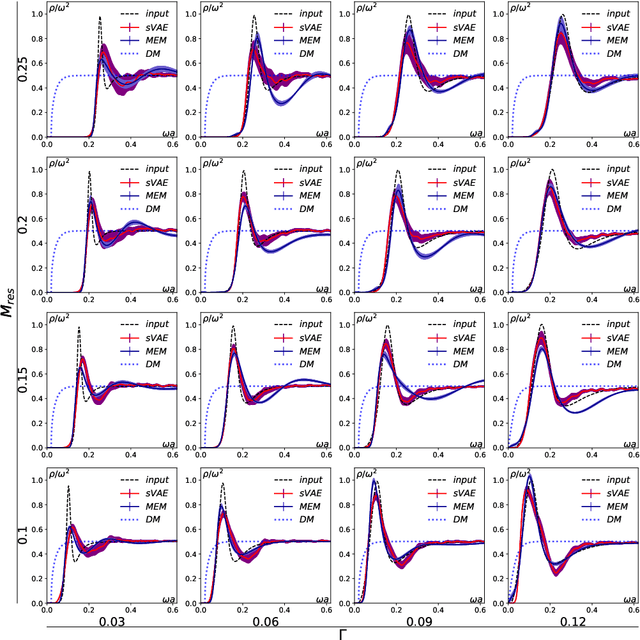
Hadron spectral functions carry all the information of hadrons and are encoded in the Euclidean two-point correlation functions. The extraction of hadron spectral functions from the correlator is a typical ill-posed inverse problem and infinite number of solutions to this problem exists. We propose a novel neural network (sVAE) based on the Variation Auto-Encoder (VAE) and Bayesian theorem. Inspired by the maximum entropy method (MEM) we construct the loss function of the neural work such that it includes a Shannon-Jaynes entropy term and a likelihood term. The sVAE is then trained to provide the most probable spectral functions. For the training samples of spectral function we used general spectral functions produced from the Gaussian Mixture Model. After the training is done we performed the mock data tests with input spectral functions consisting 1) only a free continuum, 2) only a resonance peak, 3) a resonance peak plus a free continuum and 4) a NRQCD motivated spectral function. From the mock data test we find that the sVAE in most cases is comparable to the maximum entropy method in the quality of reconstructing spectral functions and even outperforms the MEM in the case where the spectral function has sharp peaks with insufficient number of data points in the correlator. By applying to temporal correlation functions of charmonium in the pseudoscalar channel obtained in the quenched lattice QCD at 0.75 $T_c$ on $128^3\times96$ lattices and $1.5$ $T_c$ on $128^3\times48$ lattices, we find that the resonance peak of $\eta_c$ extracted from both the sVAE and MEM has a substantial dependence on the number of points in the temporal direction ($N_\tau$) adopted in the lattice simulation and $N_\tau$ larger than 48 is needed to resolve the fate of $\eta_c$ at 1.5 $T_c$.
CANet: A Context-Aware Network for Shadow Removal
Aug 23, 2021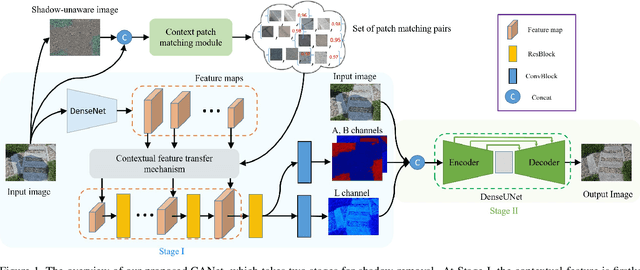
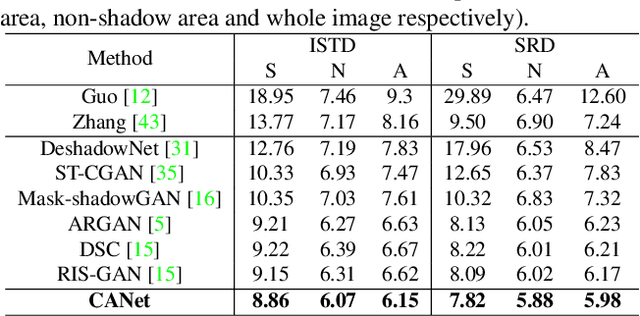
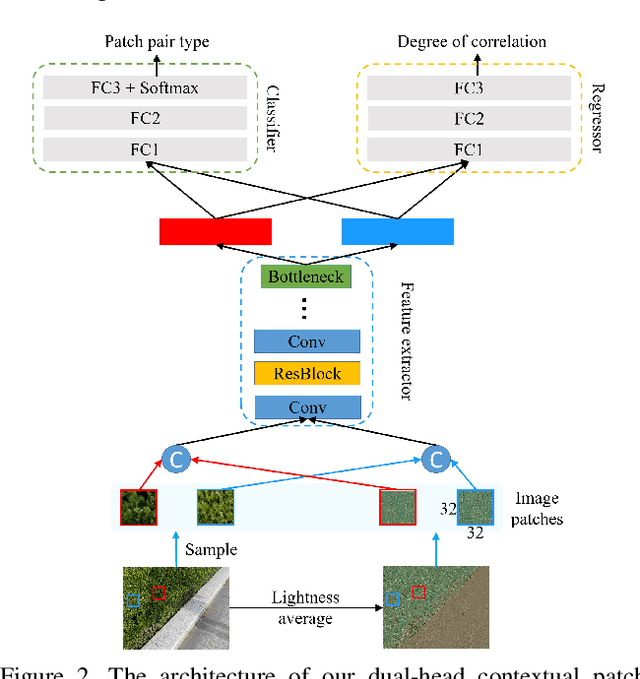
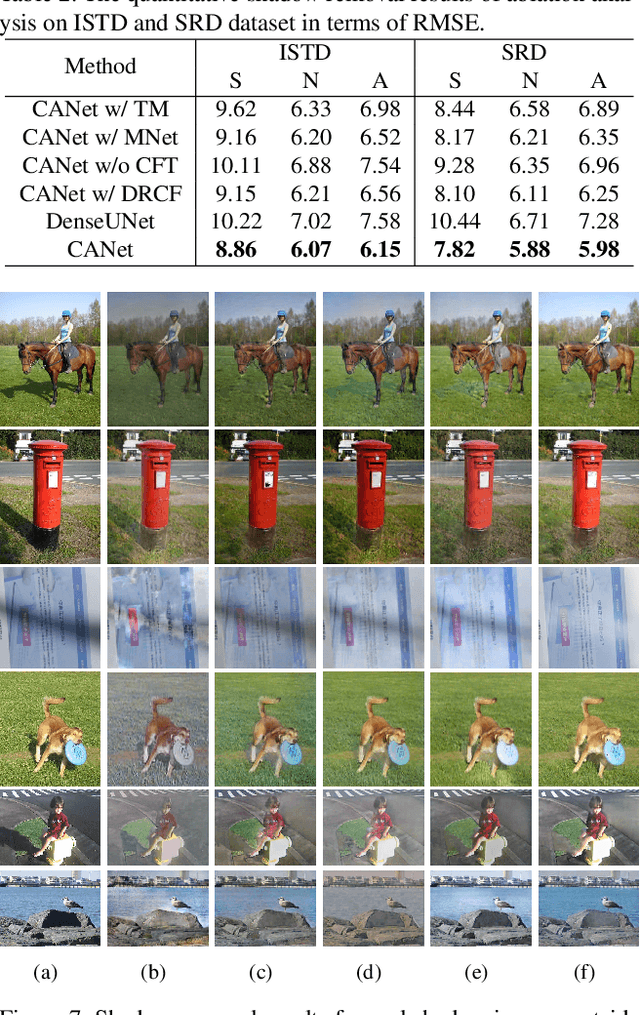
In this paper, we propose a novel two-stage context-aware network named CANet for shadow removal, in which the contextual information from non-shadow regions is transferred to shadow regions at the embedded feature spaces. At Stage-I, we propose a contextual patch matching (CPM) module to generate a set of potential matching pairs of shadow and non-shadow patches. Combined with the potential contextual relationships between shadow and non-shadow regions, our well-designed contextual feature transfer (CFT) mechanism can transfer contextual information from non-shadow to shadow regions at different scales. With the reconstructed feature maps, we remove shadows at L and A/B channels separately. At Stage-II, we use an encoder-decoder to refine current results and generate the final shadow removal results. We evaluate our proposed CANet on two benchmark datasets and some real-world shadow images with complex scenes. Extensive experimental results strongly demonstrate the efficacy of our proposed CANet and exhibit superior performance to state-of-the-arts.
Span Fine-tuning for Pre-trained Language Models
Aug 29, 2021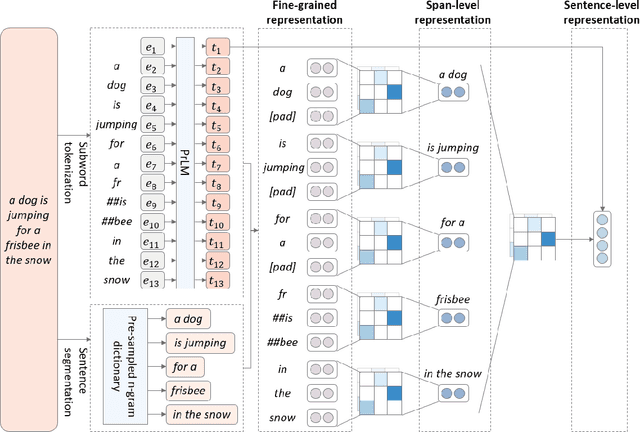
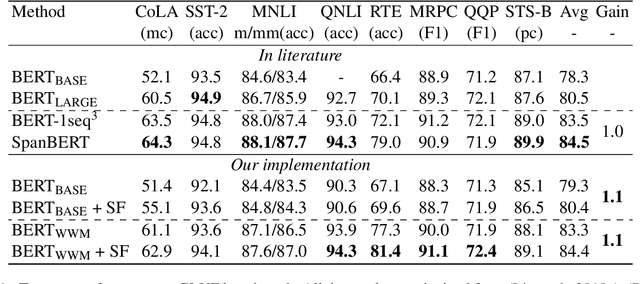

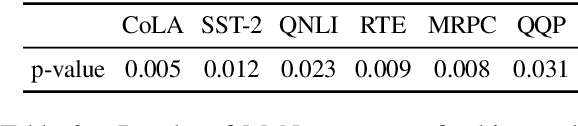
Pre-trained language models (PrLM) have to carefully manage input units when training on a very large text with a vocabulary consisting of millions of words. Previous works have shown that incorporating span-level information over consecutive words in pre-training could further improve the performance of PrLMs. However, given that span-level clues are introduced and fixed in pre-training, previous methods are time-consuming and lack of flexibility. To alleviate the inconvenience, this paper presents a novel span fine-tuning method for PrLMs, which facilitates the span setting to be adaptively determined by specific downstream tasks during the fine-tuning phase. In detail, any sentences processed by the PrLM will be segmented into multiple spans according to a pre-sampled dictionary. Then the segmentation information will be sent through a hierarchical CNN module together with the representation outputs of the PrLM and ultimately generate a span-enhanced representation. Experiments on GLUE benchmark show that the proposed span fine-tuning method significantly enhances the PrLM, and at the same time, offer more flexibility in an efficient way.
Dynamic Assortment Optimization with Changing Contextual Information
Oct 31, 2018
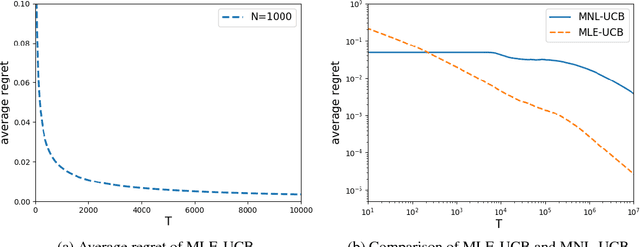
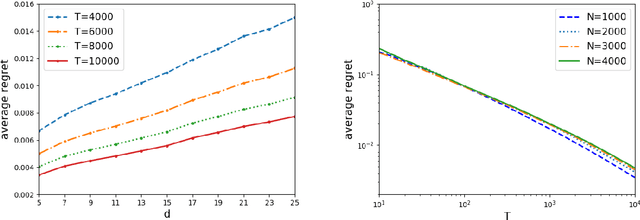
In this paper, we study the dynamic assortment optimization problem under a finite selling season of length $T$. At each time period, the seller offers an arriving customer an assortment of substitutable products under a cardinality constraint, and the customer makes the purchase among offered products according to a discrete choice model. Most existing work associates each product with a real-valued fixed mean utility and assumes a multinomial logit choice (MNL) model. In many practical applications, feature/contexutal information of products is readily available. In this paper, we incorporate the feature information by assuming a linear relationship between the mean utility and the feature. In addition, we allow the feature information of products to change over time so that the underlying choice model can also be non-stationary. To solve the dynamic assortment optimization under this changing contextual MNL model, we need to simultaneously learn the underlying unknown coefficient and makes the decision on the assortment. To this end, we develop an upper confidence bound (UCB) based policy and establish the regret bound on the order of $\widetilde O(d\sqrt{T})$, where $d$ is the dimension of the feature and $\widetilde O$ suppresses logarithmic dependence. We further established the lower bound $\Omega(d\sqrt{T}/K)$ where $K$ is the cardinality constraint of an offered assortment, which is usually small. When $K$ is a constant, our policy is optimal up to logarithmic factors. In the exploitation phase of the UCB algorithm, we need to solve a combinatorial optimization for assortment optimization based on the learned information. We further develop an approximation algorithm and an efficient greedy heuristic. The effectiveness of the proposed policy is further demonstrated by our numerical studies.
Winning the ICCV'2021 VALUE Challenge: Task-aware Ensemble and Transfer Learning with Visual Concepts
Oct 13, 2021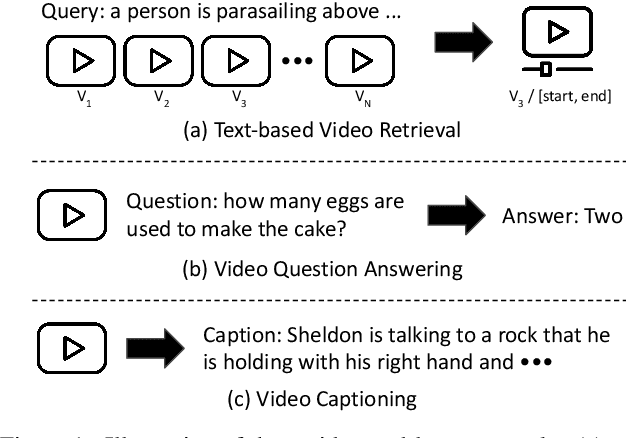

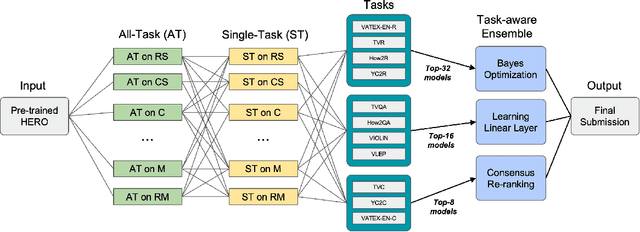
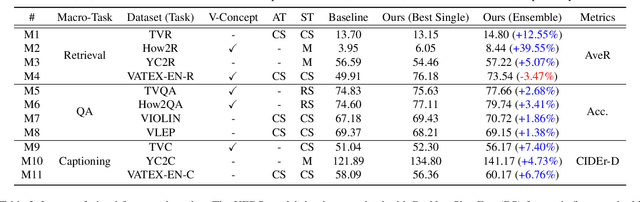
The VALUE (Video-And-Language Understanding Evaluation) benchmark is newly introduced to evaluate and analyze multi-modal representation learning algorithms on three video-and-language tasks: Retrieval, QA, and Captioning. The main objective of the VALUE challenge is to train a task-agnostic model that is simultaneously applicable for various tasks with different characteristics. This technical report describes our winning strategies for the VALUE challenge: 1) single model optimization, 2) transfer learning with visual concepts, and 3) task-aware ensemble. The first and third strategies are designed to address heterogeneous characteristics of each task, and the second one is to leverage rich and fine-grained visual information. We provide a detailed and comprehensive analysis with extensive experimental results. Based on our approach, we ranked first place on the VALUE and QA phases for the competition.
Training Generative Adversarial Networks with Adaptive Composite Gradient
Nov 10, 2021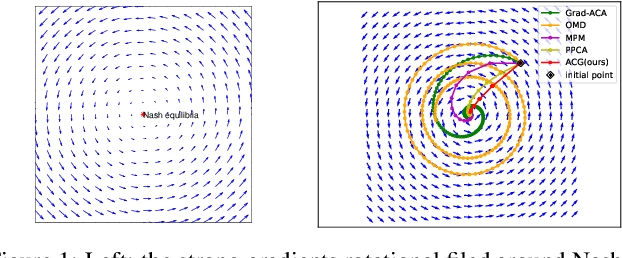
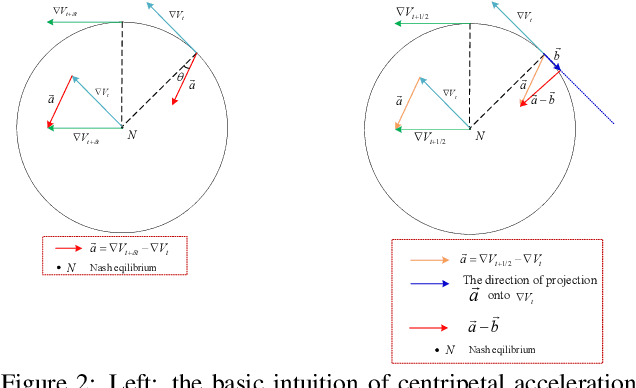
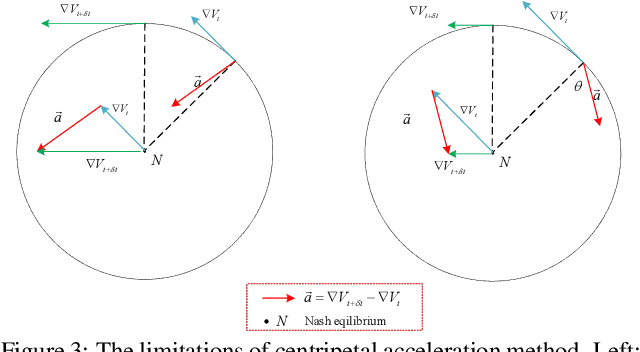
The wide applications of Generative adversarial networks benefit from the successful training methods, guaranteeing that an object function converges to the local minima. Nevertheless, designing an efficient and competitive training method is still a challenging task due to the cyclic behaviors of some gradient-based ways and the expensive computational cost of these methods based on the Hessian matrix. This paper proposed the adaptive Composite Gradients (ACG) method, linearly convergent in bilinear games under suitable settings. Theory and toy-function experiments suggest that our approach can alleviate the cyclic behaviors and converge faster than recently proposed algorithms. Significantly, the ACG method is not only used to find stable fixed points in bilinear games as well as in general games. The ACG method is a novel semi-gradient-free algorithm since it does not need to calculate the gradient of each step, reducing the computational cost of gradient and Hessian by utilizing the predictive information in future iterations. We conducted two mixture of Gaussians experiments by integrating ACG to existing algorithms with Linear GANs. Results show ACG is competitive with the previous algorithms. Realistic experiments on four prevalent data sets (MNIST, Fashion-MNIST, CIFAR-10, and CelebA) with DCGANs show that our ACG method outperforms several baselines, which illustrates the superiority and efficacy of our method.
Action Anticipation for Collaborative Environments: The Impact of Contextual Information and Uncertainty-Based Prediction
Oct 01, 2019
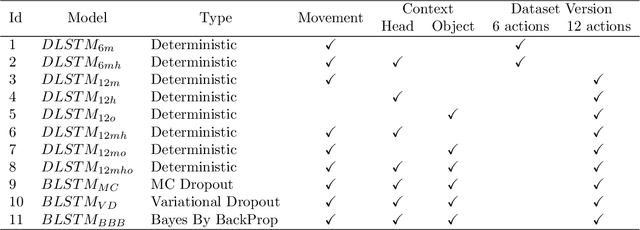

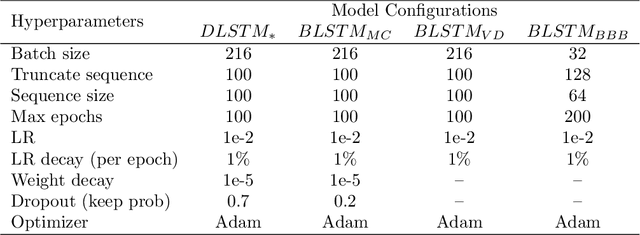
For effectively interacting with humans in collaborative environments, machines need to be able anticipate future events, in order to execute actions in a timely manner. However, the observation of the human limbs movements may not be sufficient to anticipate their actions in an unambiguous manner. In this work we consider two additional sources of information (i.e. context) over time, gaze movements and object information, and study how these additional contextual cues improve the action anticipation performance. We address action anticipation as a classification task, where the model takes the available information as the input, and predicts the most likely action. We propose to use the uncertainty about each prediction as an online decision-making criterion for action anticipation. Uncertainty is modeled as a stochastic process applied to a time-based neural network architecture, which improves the conventional class-likelihood (i.e. deterministic) criterion. The main contributions of this paper are three-fold: (i) we propose a deep architecture that outperforms previous results in the action anticipation task; (ii) we show that contextual information is important do disambiguate the interpretation of similar actions; (iii) we propose the minimization of uncertainty as a more effective criterion for action anticipation, when compared with the maximization of class probability. Our results on the Acticipate dataset showed the importance of contextual information and the uncertainty criterion for action anticipation. We achieve an average accuracy of 98.75% in the anticipation task using only an average of 25% of observations. In addition, considering that a good anticipation model should also perform well in the action recognition task, we achieve an average accuracy of 100% in action recognition on the Acticipate dataset, when the entire observation set is used.