 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactuality Detection using Machine Translation -- a Use Case for German Clinical Text
Aug 17, 2023



Factuality can play an important role when automatically processing clinical text, as it makes a difference if particular symptoms are explicitly not present, possibly present, not mentioned, or affirmed. In most cases, a sufficient number of examples is necessary to handle such phenomena in a supervised machine learning setting. However, as clinical text might contain sensitive information, data cannot be easily shared. In the context of factuality detection, this work presents a simple solution using machine translation to translate English data to German to train a transformer-based factuality detection model.
MobIE: A German Dataset for Named Entity Recognition, Entity Linking and Relation Extraction in the Mobility Domain
Aug 16, 2021
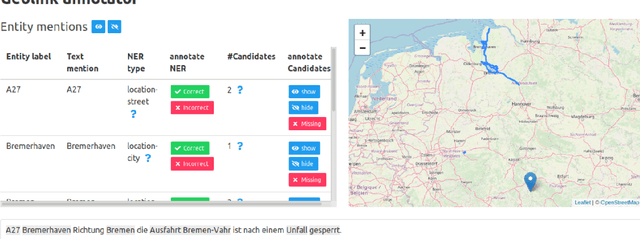
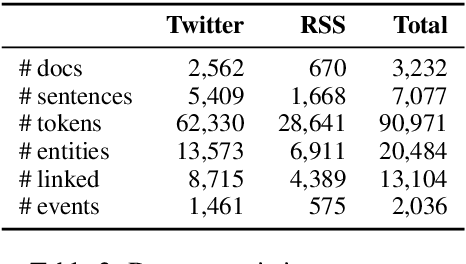
We present MobIE, a German-language dataset, which is human-annotated with 20 coarse- and fine-grained entity types and entity linking information for geographically linkable entities. The dataset consists of 3,232 social media texts and traffic reports with 91K tokens, and contains 20.5K annotated entities, 13.1K of which are linked to a knowledge base. A subset of the dataset is human-annotated with seven mobility-related, n-ary relation types, while the remaining documents are annotated using a weakly-supervised labeling approach implemented with the Snorkel framework. To the best of our knowledge, this is the first German-language dataset that combines annotations for NER, EL and RE, and thus can be used for joint and multi-task learning of these fundamental information extraction tasks. We make MobIE public at https://github.com/dfki-nlp/mobie.
Evaluating German Transformer Language Models with Syntactic Agreement Tests
Jul 07, 2020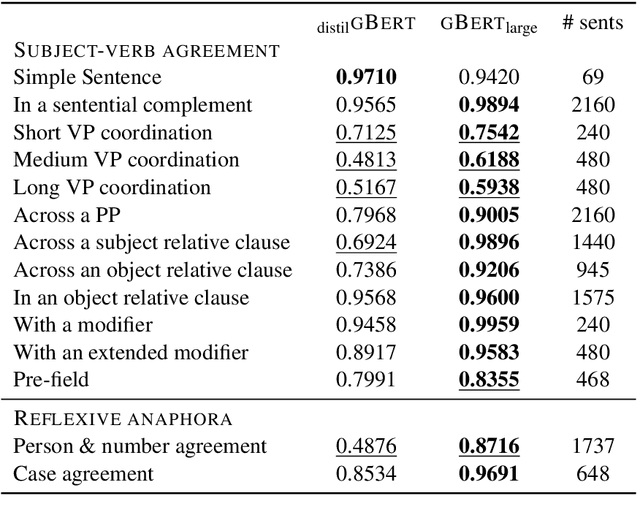
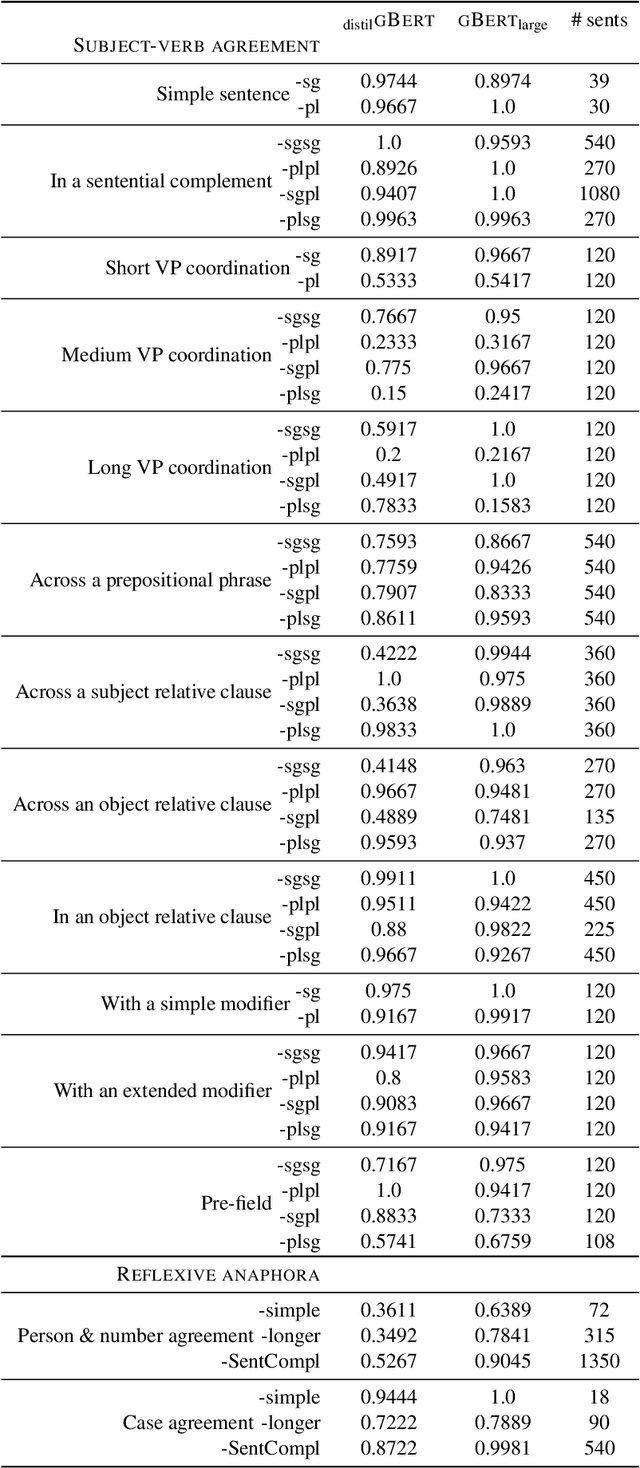
Pre-trained transformer language models (TLMs) have recently refashioned natural language processing (NLP): Most state-of-the-art NLP models now operate on top of TLMs to benefit from contextualization and knowledge induction. To explain their success, the scientific community conducted numerous analyses. Besides other methods, syntactic agreement tests were utilized to analyse TLMs. Most of the studies were conducted for the English language, however. In this work, we analyse German TLMs. To this end, we design numerous agreement tasks, some of which consider peculiarities of the German language. Our experimental results show that state-of-the-art German TLMs generally perform well on agreement tasks, but we also identify and discuss syntactic structures that push them to their limits.
* SwissText + KONVENS 2020
TACRED Revisited: A Thorough Evaluation of the TACRED Relation Extraction Task
Apr 30, 2020
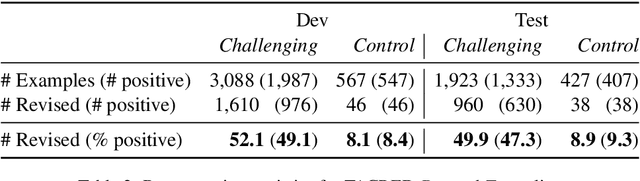
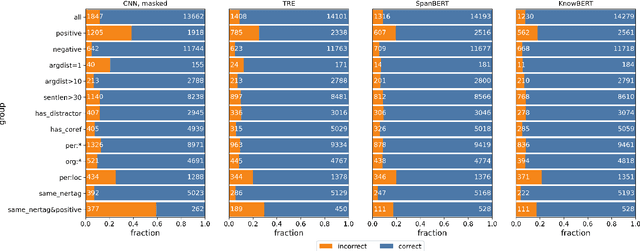
TACRED (Zhang et al., 2017) is one of the largest, most widely used crowdsourced datasets in Relation Extraction (RE). But, even with recent advances in unsupervised pre-training and knowledge enhanced neural RE, models still show a high error rate. In this paper, we investigate the questions: Have we reached a performance ceiling or is there still room for improvement? And how do crowd annotations, dataset, and models contribute to this error rate? To answer these questions, we first validate the most challenging 5K examples in the development and test sets using trained annotators. We find that label errors account for 8% absolute F1 test error, and that more than 50% of the examples need to be relabeled. On the relabeled test set the average F1 score of a large baseline model set improves from 62.1 to 70.1. After validation, we analyze misclassifications on the challenging instances, categorize them into linguistically motivated error groups, and verify the resulting error hypotheses on three state-of-the-art RE models. We show that two groups of ambiguous relations are responsible for most of the remaining errors and that models may adopt shallow heuristics on the dataset when entities are not masked.
Probing Linguistic Features of Sentence-Level Representations in Neural Relation Extraction
Apr 17, 2020
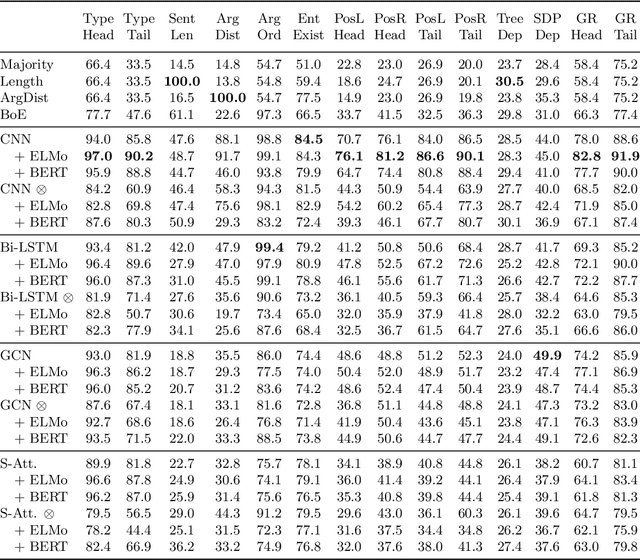
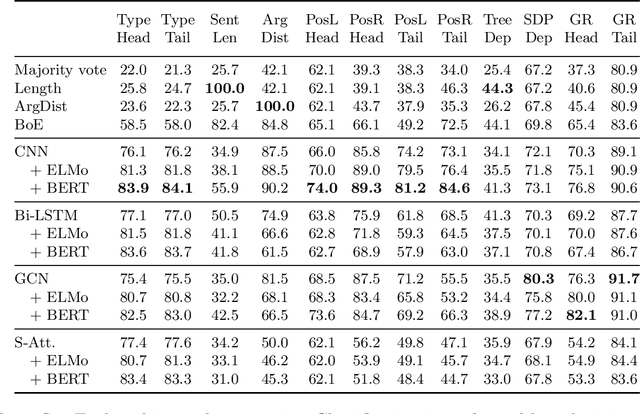
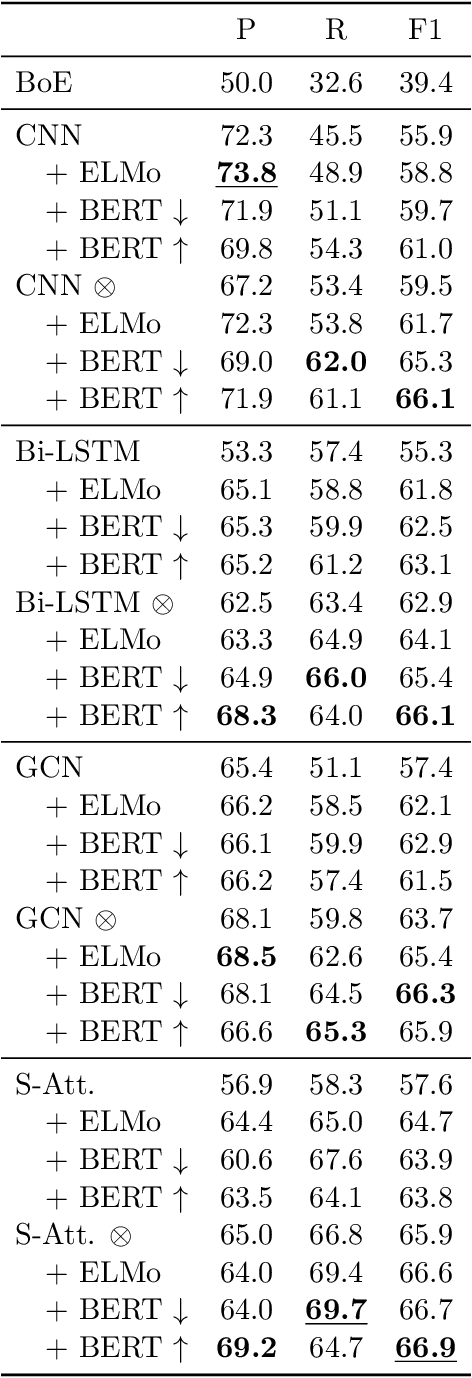
Despite the recent progress, little is known about the features captured by state-of-the-art neural relation extraction (RE) models. Common methods encode the source sentence, conditioned on the entity mentions, before classifying the relation. However, the complexity of the task makes it difficult to understand how encoder architecture and supporting linguistic knowledge affect the features learned by the encoder. We introduce 14 probing tasks targeting linguistic properties relevant to RE, and we use them to study representations learned by more than 40 different encoder architecture and linguistic feature combinations trained on two datasets, TACRED and SemEval 2010 Task 8. We find that the bias induced by the architecture and the inclusion of linguistic features are clearly expressed in the probing task performance. For example, adding contextualized word representations greatly increases performance on probing tasks with a focus on named entity and part-of-speech information, and yields better results in RE. In contrast, entity masking improves RE, but considerably lowers performance on entity type related probing tasks.
A Corpus Study and Annotation Schema for Named Entity Recognition and Relation Extraction of Business Products
Apr 07, 2020
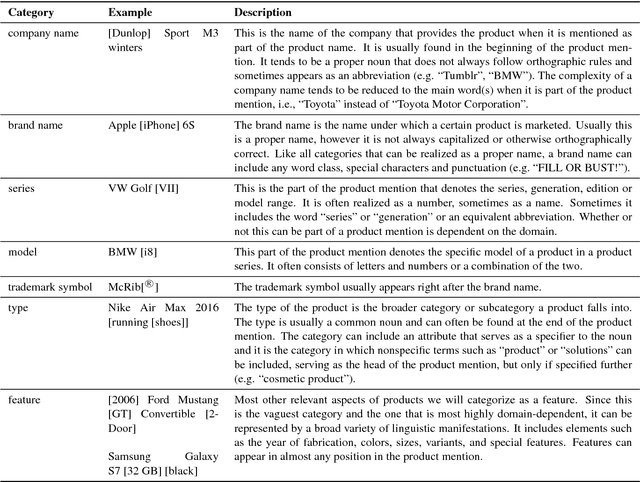
Recognizing non-standard entity types and relations, such as B2B products, product classes and their producers, in news and forum texts is important in application areas such as supply chain monitoring and market research. However, there is a decided lack of annotated corpora and annotation guidelines in this domain. In this work, we present a corpus study, an annotation schema and associated guidelines, for the annotation of product entity and company-product relation mentions. We find that although product mentions are often realized as noun phrases, defining their exact extent is difficult due to high boundary ambiguity and the broad syntactic and semantic variety of their surface realizations. We also describe our ongoing annotation effort, and present a preliminary corpus of English web and social media documents annotated according to the proposed guidelines.
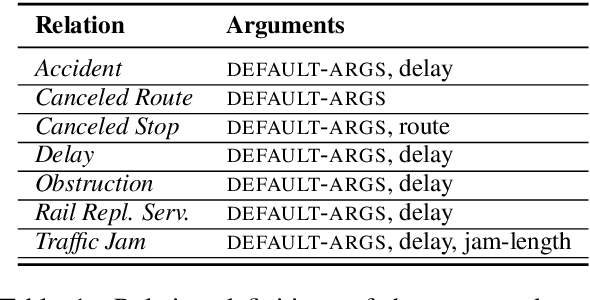
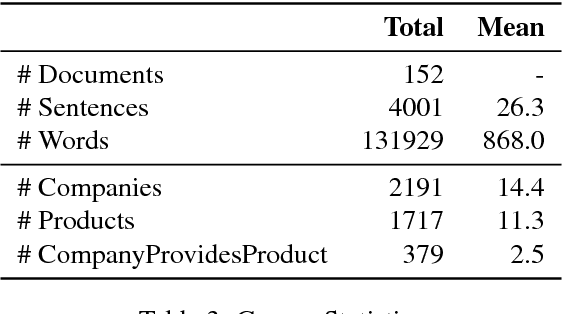
A German Corpus for Fine-Grained Named Entity Recognition and Relation Extraction of Traffic and Industry Events
Apr 07, 2020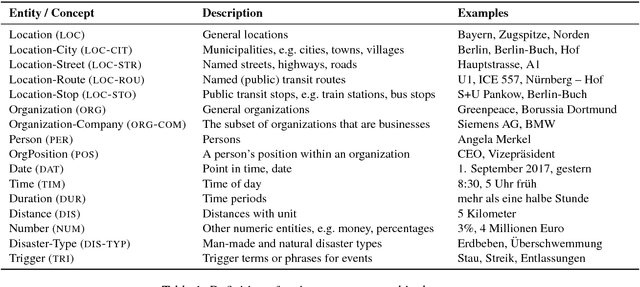


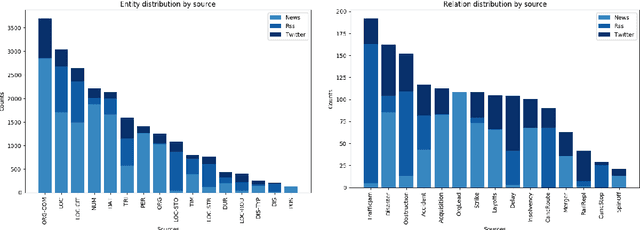
Monitoring mobility- and industry-relevant events is important in areas such as personal travel planning and supply chain management, but extracting events pertaining to specific companies, transit routes and locations from heterogeneous, high-volume text streams remains a significant challenge. This work describes a corpus of German-language documents which has been annotated with fine-grained geo-entities, such as streets, stops and routes, as well as standard named entity types. It has also been annotated with a set of 15 traffic- and industry-related n-ary relations and events, such as accidents, traffic jams, acquisitions, and strikes. The corpus consists of newswire texts, Twitter messages, and traffic reports from radio stations, police and railway companies. It allows for training and evaluating both named entity recognition algorithms that aim for fine-grained typing of geo-entities, as well as n-ary relation extraction systems.