 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Synergistic Learning with Vision-Language Adaption for Low-Resource Biomedical Image Classification
Apr 27, 2026Accurate biomedical image classification under low-resource conditions remains challenging due to limited annotations, subtle inter-class visual differences, and complex disease semantics. While vision--language models offer a promising foundation for mitigating data scarcity, their effective adaptation in biomedical settings is constrained by the need for parameter-efficient tuning alongside fine-grained and semantically consistent representation learning. In this work, we propose Multi-View Synergistic Learning (MVSL), a unified framework that addresses these challenges by jointly considering adaptation paradigms, representation granularity, and disease semantic relationships. MVSL decouples the adaptation of visual and textual encoders to respect their distinct representational characteristics, enabling more stable and effective parameter-efficient fine-tuning. It further introduces multi-granularity contrastive learning to explicitly model both global image semantics and localized lesion-level evidence, improving fine-grained discrimination for visually similar disease categories. In addition, MVSL preserves disease-level semantic structure by incorporating structured supervision derived from large language models, which constrains textual representations at the class level and indirectly regularizes visual embeddings through cross-modal alignment. Together, these components enable more stable cross-modal alignment and improved discrimination under limited supervision. Extensive experiments on $11$ public biomedical datasets spanning $9$ imaging modalities and $10$ anatomical regions demonstrate that MVSL consistently outperforms state-of-the-art methods in few-shot and zero-shot classification settings.
Training Generative Adversarial Networks with Adaptive Composite Gradient
Nov 10, 2021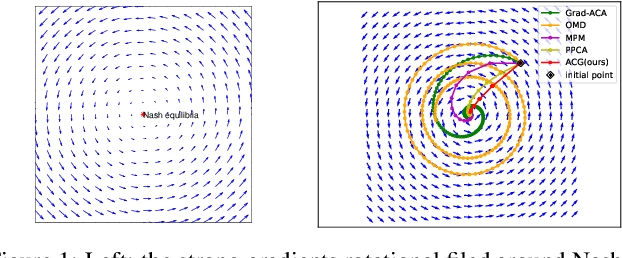
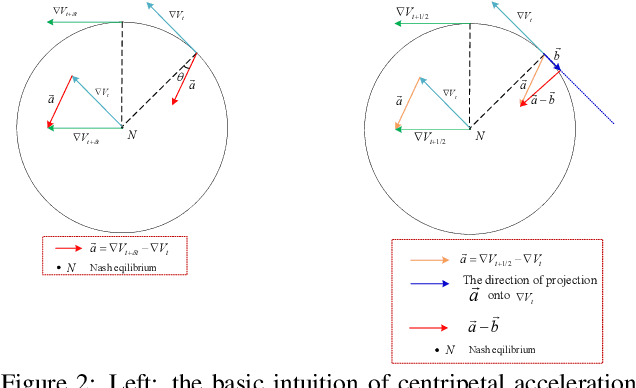
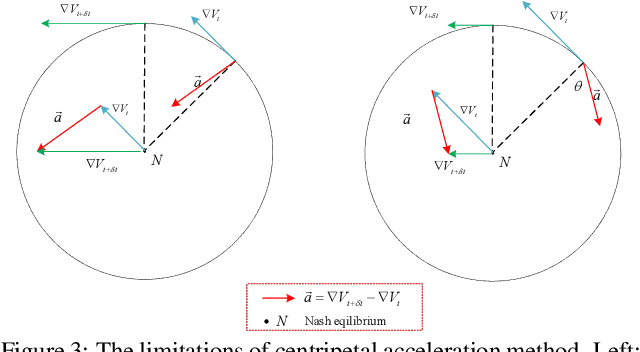
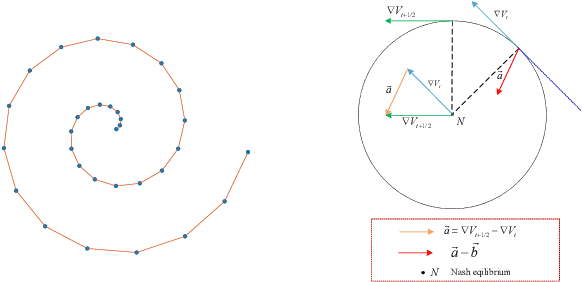
The wide applications of Generative adversarial networks benefit from the successful training methods, guaranteeing that an object function converges to the local minima. Nevertheless, designing an efficient and competitive training method is still a challenging task due to the cyclic behaviors of some gradient-based ways and the expensive computational cost of these methods based on the Hessian matrix. This paper proposed the adaptive Composite Gradients (ACG) method, linearly convergent in bilinear games under suitable settings. Theory and toy-function experiments suggest that our approach can alleviate the cyclic behaviors and converge faster than recently proposed algorithms. Significantly, the ACG method is not only used to find stable fixed points in bilinear games as well as in general games. The ACG method is a novel semi-gradient-free algorithm since it does not need to calculate the gradient of each step, reducing the computational cost of gradient and Hessian by utilizing the predictive information in future iterations. We conducted two mixture of Gaussians experiments by integrating ACG to existing algorithms with Linear GANs. Results show ACG is competitive with the previous algorithms. Realistic experiments on four prevalent data sets (MNIST, Fashion-MNIST, CIFAR-10, and CelebA) with DCGANs show that our ACG method outperforms several baselines, which illustrates the superiority and efficacy of our method.