 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKorean Canonical Legal Benchmark: Toward Knowledge-Independent Evaluation of LLMs' Legal Reasoning Capabilities
Dec 31, 2025We introduce the Korean Canonical Legal Benchmark (KCL), a benchmark designed to assess language models' legal reasoning capabilities independently of domain-specific knowledge. KCL provides question-level supporting precedents, enabling a more faithful disentanglement of reasoning ability from parameterized knowledge. KCL consists of two components: (1) KCL-MCQA, multiple-choice problems of 283 questions with 1,103 aligned precedents, and (2) KCL-Essay, open-ended generation problems of 169 questions with 550 aligned precedents and 2,739 instance-level rubrics for automated evaluation. Our systematic evaluation of 30+ models shows large remaining gaps, particularly in KCL-Essay, and that reasoning-specialized models consistently outperform their general-purpose counterparts. We release all resources, including the benchmark dataset and evaluation code, at https://github.com/lbox-kr/kcl.
Kanana: Compute-efficient Bilingual Language Models
Feb 26, 2025



We introduce Kanana, a series of bilingual language models that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, retrieval augmented generation, and function calling. The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding) publicly released to promote research on Korean language models.
TLCR: Token-Level Continuous Reward for Fine-grained Reinforcement Learning from Human Feedback
Jul 23, 2024



Reinforcement Learning from Human Feedback (RLHF) leverages human preference data to train language models to align more closely with human essence. These human preference data, however, are labeled at the sequence level, creating a mismatch between sequence-level preference labels and tokens, which are autoregressively generated from the language model. Although several recent approaches have tried to provide token-level (i.e., dense) rewards for each individual token, these typically rely on predefined discrete reward values (e.g., positive: +1, negative: -1, neutral: 0), failing to account for varying degrees of preference inherent to each token. To address this limitation, we introduce TLCR (Token-Level Continuous Reward) for RLHF, which incorporates a discriminator trained to distinguish positive and negative tokens, and the confidence of the discriminator is used to assign continuous rewards to each token considering the context. Extensive experiments show that our proposed TLCR leads to consistent performance improvements over previous sequence-level or token-level discrete rewards on open-ended generation benchmarks.
General Item Representation Learning for Cold-start Content Recommendations
Apr 22, 2024



Cold-start item recommendation is a long-standing challenge in recommendation systems. A common remedy is to use a content-based approach, but rich information from raw contents in various forms has not been fully utilized. In this paper, we propose a domain/data-agnostic item representation learning framework for cold-start recommendations, naturally equipped with multimodal alignment among various features by adopting a Transformer-based architecture. Our proposed model is end-to-end trainable completely free from classification labels, not just costly to collect but suboptimal for recommendation-purpose representation learning. From extensive experiments on real-world movie and news recommendation benchmarks, we verify that our approach better preserves fine-grained user taste than state-of-the-art baselines, universally applicable to multiple domains at large scale.
Binary Classifier Optimization for Large Language Model Alignment
Apr 06, 2024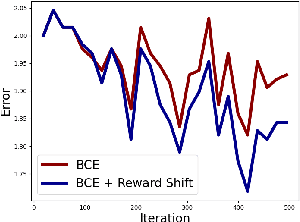


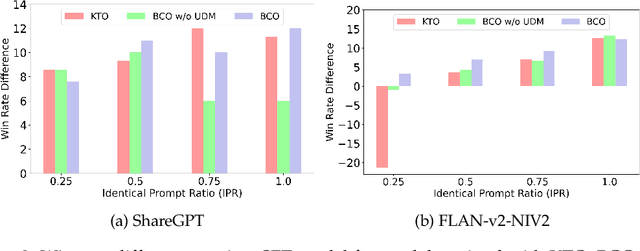
Aligning Large Language Models (LLMs) to human preferences through preference optimization has been crucial but labor-intensive, necessitating for each prompt a comparison of both a chosen and a rejected text completion by evaluators. Recently, Kahneman-Tversky Optimization (KTO) has demonstrated that LLMs can be aligned using merely binary "thumbs-up" or "thumbs-down" signals on each prompt-completion pair. In this paper, we present theoretical foundations to explain the successful alignment achieved through these binary signals. Our analysis uncovers a new perspective: optimizing a binary classifier, whose logit is a reward, implicitly induces minimizing the Direct Preference Optimization (DPO) loss. In the process of this discovery, we identified two techniques for effective alignment: reward shift and underlying distribution matching. Consequently, we propose a new algorithm, \textit{Binary Classifier Optimization}, that integrates the techniques. We validate our methodology in two settings: first, on a paired preference dataset, where our method performs on par with DPO and KTO; and second, on binary signal datasets simulating real-world conditions with divergent underlying distributions between thumbs-up and thumbs-down data. Our model consistently demonstrates effective and robust alignment across two base LLMs and three different binary signal datasets, showcasing the strength of our approach to learning from binary feedback.
Semiparametric Token-Sequence Co-Supervision
Mar 14, 2024



In this work, we introduce a semiparametric token-sequence co-supervision training method. It trains a language model by simultaneously leveraging supervision from the traditional next token prediction loss which is calculated over the parametric token embedding space and the next sequence prediction loss which is calculated over the nonparametric sequence embedding space. The nonparametric sequence embedding space is constructed by a separate language model tasked to condense an input text into a single representative embedding. Our experiments demonstrate that a model trained via both supervisions consistently surpasses models trained via each supervision independently. Analysis suggests that this co-supervision encourages a broader generalization capability across the model. Especially, the robustness of parametric token space which is established during the pretraining step tends to effectively enhance the stability of nonparametric sequence embedding space, a new space established by another language model.
How Well Do Large Language Models Truly Ground?
Nov 15, 2023



Reliance on the inherent knowledge of Large Language Models (LLMs) can cause issues such as hallucinations, lack of control, and difficulties in integrating variable knowledge. To mitigate this, LLMs can be probed to generate responses by grounding on external context, often given as input (knowledge-augmented models). Yet, previous research is often confined to a narrow view of the term "grounding", often only focusing on whether the response contains the correct answer or not, which does not ensure the reliability of the entire response. To address this limitation, we introduce a strict definition of grounding: a model is considered truly grounded when its responses (1) fully utilize necessary knowledge from the provided context, and (2) don't exceed the knowledge within the contexts. We introduce a new dataset and a grounding metric to assess this new definition and perform experiments across 13 LLMs of different sizes and training methods to provide insights into the factors that influence grounding performance. Our findings contribute to a better understanding of how to improve grounding capabilities and suggest an area of improvement toward more reliable and controllable LLM applications.
Hexa: Self-Improving for Knowledge-Grounded Dialogue System
Oct 22, 2023



A common practice in knowledge-grounded dialogue generation is to explicitly utilize intermediate steps (e.g., web-search, memory retrieval) with modular approaches. However, data for such steps are often inaccessible compared to those of dialogue responses as they are unobservable in an ordinary dialogue. To fill in the absence of these data, we develop a self-improving method to improve the generative performances of intermediate steps without the ground truth data. In particular, we propose a novel bootstrapping scheme with a guided prompt and a modified loss function to enhance the diversity of appropriate self-generated responses. Through experiments on various benchmark datasets, we empirically demonstrate that our method successfully leverages a self-improving mechanism in generating intermediate and final responses and improves the performances on the task of knowledge-grounded dialogue generation.
Exploiting the Potential of Seq2Seq Models as Robust Few-Shot Learners
Jul 27, 2023



In-context learning, which offers substantial advantages over fine-tuning, is predominantly observed in decoder-only models, while encoder-decoder (i.e., seq2seq) models excel in methods that rely on weight updates. Recently, a few studies have demonstrated the feasibility of few-shot learning with seq2seq models; however, this has been limited to tasks that align well with the seq2seq architecture, such as summarization and translation. Inspired by these initial studies, we provide a first-ever extensive experiment comparing the in-context few-shot learning capabilities of decoder-only and encoder-decoder models on a broad range of tasks. Furthermore, we propose two methods to more effectively elicit in-context learning ability in seq2seq models: objective-aligned prompting and a fusion-based approach. Remarkably, our approach outperforms a decoder-only model that is six times larger and exhibits significant performance improvements compared to conventional seq2seq models across a variety of settings. We posit that, with the right configuration and prompt design, seq2seq models can be highly effective few-shot learners for a wide spectrum of applications.
Effortless Integration of Memory Management into Open-Domain Conversation Systems
May 23, 2023


Open-domain conversation systems integrate multiple conversation skills into a single system through a modular approach. One of the limitations of the system, however, is the absence of management capability for external memory. In this paper, we propose a simple method to improve BlenderBot3 by integrating memory management ability into it. Since no training data exists for this purpose, we propose an automating dataset creation for memory management. Our method 1) requires little cost for data construction, 2) does not affect performance in other tasks, and 3) reduces external memory. We show that our proposed model BlenderBot3-M^3, which is multi-task trained with memory management, outperforms BlenderBot3 with a relative 4% performance gain in terms of F1 score.