 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinguishing Non-natural from Natural Adversarial Samples for More Robust Pre-trained Language Model
Mar 19, 2022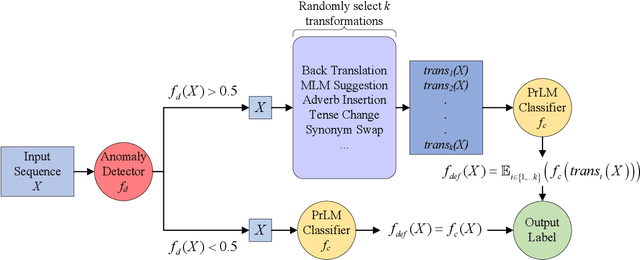

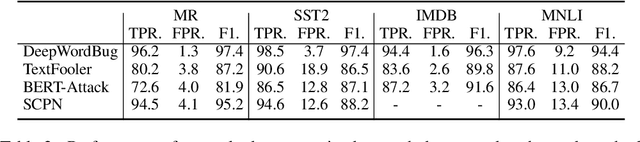
Recently, the problem of robustness of pre-trained language models (PrLMs) has received increasing research interest. Latest studies on adversarial attacks achieve high attack success rates against PrLMs, claiming that PrLMs are not robust. However, we find that the adversarial samples that PrLMs fail are mostly non-natural and do not appear in reality. We question the validity of current evaluation of robustness of PrLMs based on these non-natural adversarial samples and propose an anomaly detector to evaluate the robustness of PrLMs with more natural adversarial samples. We also investigate two applications of the anomaly detector: (1) In data augmentation, we employ the anomaly detector to force generating augmented data that are distinguished as non-natural, which brings larger gains to the accuracy of PrLMs. (2) We apply the anomaly detector to a defense framework to enhance the robustness of PrLMs. It can be used to defend all types of attacks and achieves higher accuracy on both adversarial samples and compliant samples than other defense frameworks.
Span Fine-tuning for Pre-trained Language Models
Aug 29, 2021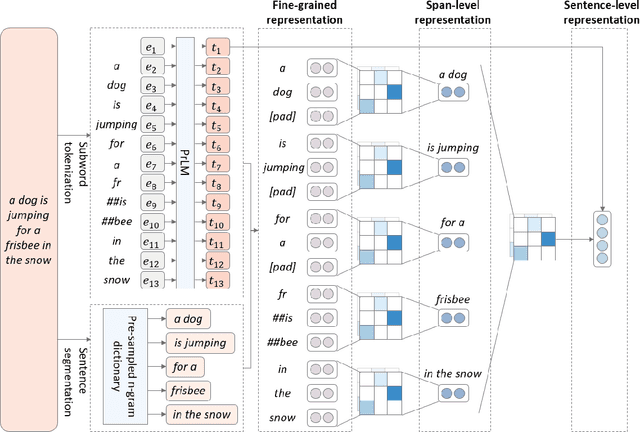
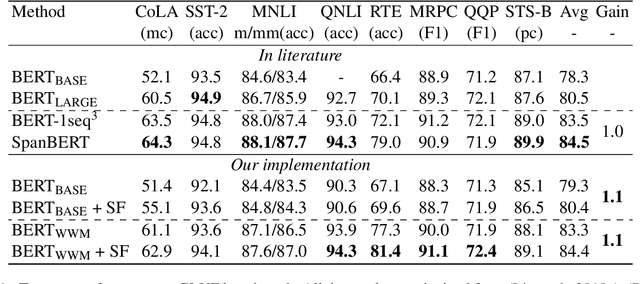

Pre-trained language models (PrLM) have to carefully manage input units when training on a very large text with a vocabulary consisting of millions of words. Previous works have shown that incorporating span-level information over consecutive words in pre-training could further improve the performance of PrLMs. However, given that span-level clues are introduced and fixed in pre-training, previous methods are time-consuming and lack of flexibility. To alleviate the inconvenience, this paper presents a novel span fine-tuning method for PrLMs, which facilitates the span setting to be adaptively determined by specific downstream tasks during the fine-tuning phase. In detail, any sentences processed by the PrLM will be segmented into multiple spans according to a pre-sampled dictionary. Then the segmentation information will be sent through a hierarchical CNN module together with the representation outputs of the PrLM and ultimately generate a span-enhanced representation. Experiments on GLUE benchmark show that the proposed span fine-tuning method significantly enhances the PrLM, and at the same time, offer more flexibility in an efficient way.
Defending Pre-trained Language Models from Adversarial Word Substitutions Without Performance Sacrifice
May 30, 2021
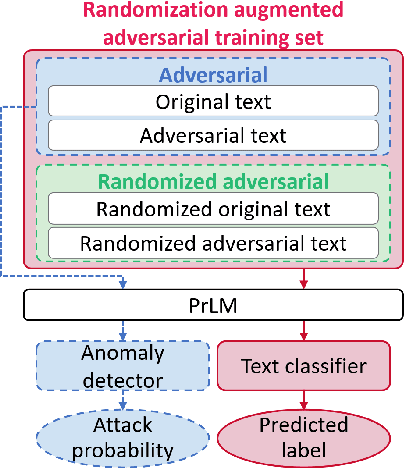
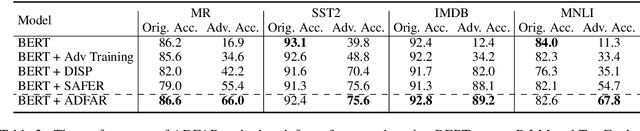
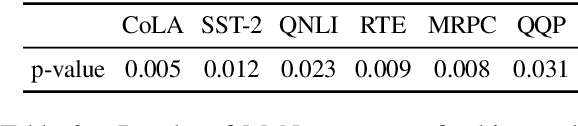
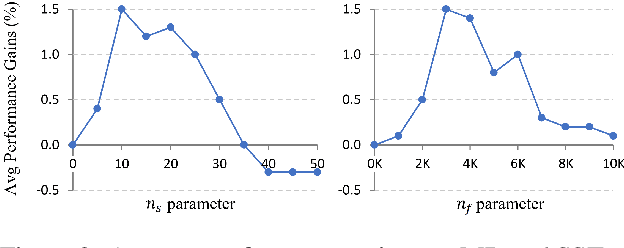
Pre-trained contextualized language models (PrLMs) have led to strong performance gains in downstream natural language understanding tasks. However, PrLMs can still be easily fooled by adversarial word substitution, which is one of the most challenging textual adversarial attack methods. Existing defence approaches suffer from notable performance loss and complexities. Thus, this paper presents a compact and performance-preserved framework, Anomaly Detection with Frequency-Aware Randomization (ADFAR). In detail, we design an auxiliary anomaly detection classifier and adopt a multi-task learning procedure, by which PrLMs are able to distinguish adversarial input samples. Then, in order to defend adversarial word substitution, a frequency-aware randomization process is applied to those recognized adversarial input samples. Empirical results show that ADFAR significantly outperforms those newly proposed defense methods over various tasks with much higher inference speed. Remarkably, ADFAR does not impair the overall performance of PrLMs. The code is available at https://github.com/LilyNLP/ADFAR
Enhancing Pre-trained Language Model with Lexical Simplification
Dec 30, 2020

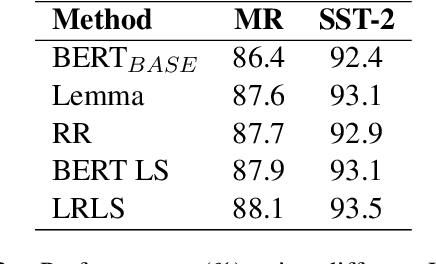
For both human readers and pre-trained language models (PrLMs), lexical diversity may lead to confusion and inaccuracy when understanding the underlying semantic meanings of given sentences. By substituting complex words with simple alternatives, lexical simplification (LS) is a recognized method to reduce such lexical diversity, and therefore to improve the understandability of sentences. In this paper, we leverage LS and propose a novel approach which can effectively improve the performance of PrLMs in text classification. A rule-based simplification process is applied to a given sentence. PrLMs are encouraged to predict the real label of the given sentence with auxiliary inputs from the simplified version. Using strong PrLMs (BERT and ELECTRA) as baselines, our approach can still further improve the performance in various text classification tasks.