 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Over-the-Air Aggregation for Federated Learning: Waveform Superposition and Prototype Validation
Oct 27, 2021
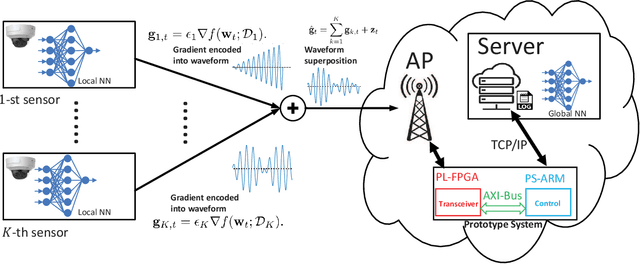
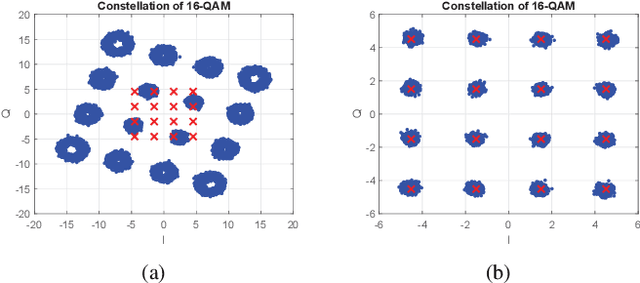
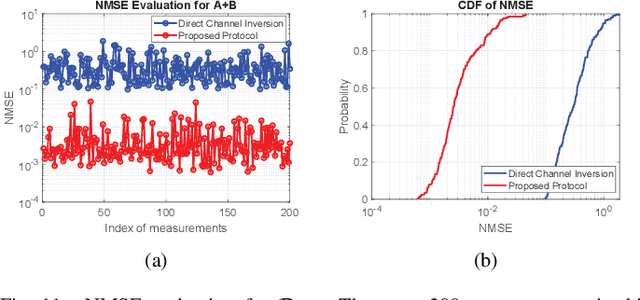

In this paper, we develop an orthogonal-frequency-division-multiplexing (OFDM)-based over-the-air (OTA) aggregation solution for wireless federated learning (FL). In particular, the local gradients in massive IoT devices are modulated by an analog waveform and are then transmitted using the same wireless resources. To this end, achieving perfect waveform superposition is the key challenge, which is difficult due to the existence of frame timing offset (TO) and carrier frequency offset (CFO). In order to address these issues, we propose a two-stage waveform pre-equalization technique with a customized multiple access protocol that can estimate and then mitigate the TO and CFO for the OTA aggregation. Based on the proposed solution, we develop a hardware transceiver and application software to train a real-world FL task, which learns a deep neural network to predict the received signal strength with global positioning system information. Experiments verify that the proposed OTA aggregation solution can achieve comparable performance to offline learning procedures with high prediction accuracy.
Variational Information Bottleneck for Unsupervised Clustering: Deep Gaussian Mixture Embedding
May 28, 2019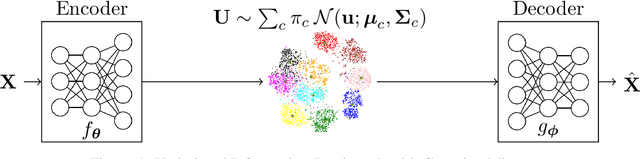
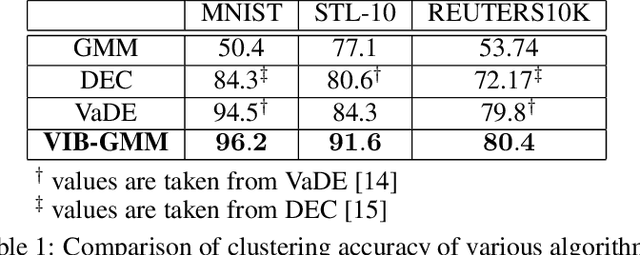
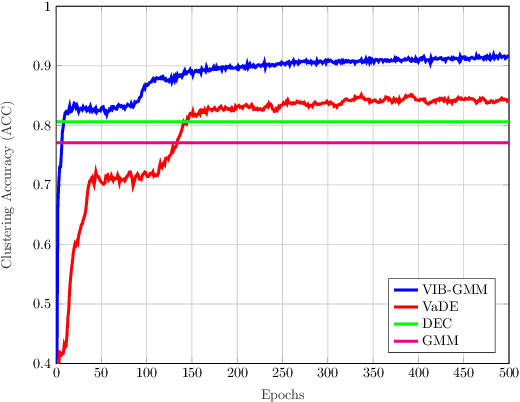
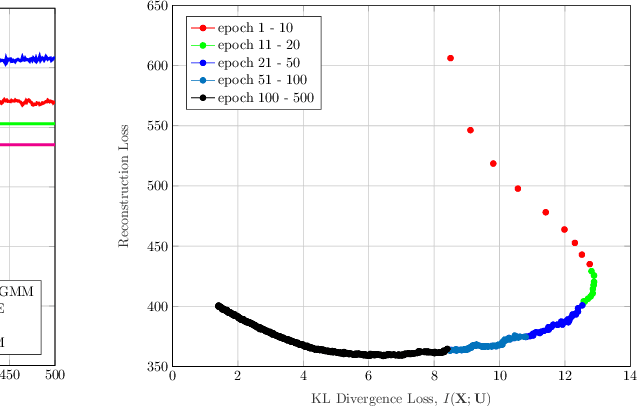
In this paper, we develop an unsupervised generative clustering framework that combines variational information bottleneck and the Gaussian Mixture Model. Specifically, in our approach we use the variational information bottleneck method and model the latent space as a mixture of Gaussians. We derive a bound on the cost function of our model that generalizes the evidence lower bound (ELBO); and provide a variational inference type algorithm that allows to compute it. In the algorithm, the coders' mappings are parametrized using neural networks and the bound is approximated by Markov sampling and optimized with stochastic gradient descent. Numerical results on real datasets are provided to support the efficiency of our method.
RRNet: Relational Reasoning Network with Parallel Multi-scale Attention for Salient Object Detection in Optical Remote Sensing Images
Oct 27, 2021
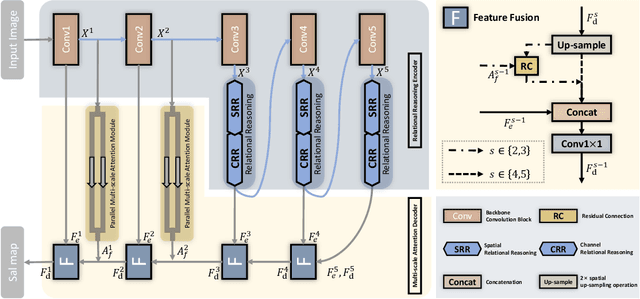

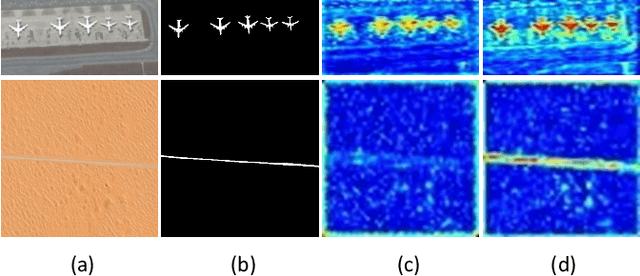
Salient object detection (SOD) for optical remote sensing images (RSIs) aims at locating and extracting visually distinctive objects/regions from the optical RSIs. Despite some saliency models were proposed to solve the intrinsic problem of optical RSIs (such as complex background and scale-variant objects), the accuracy and completeness are still unsatisfactory. To this end, we propose a relational reasoning network with parallel multi-scale attention for SOD in optical RSIs in this paper. The relational reasoning module that integrates the spatial and the channel dimensions is designed to infer the semantic relationship by utilizing high-level encoder features, thereby promoting the generation of more complete detection results. The parallel multi-scale attention module is proposed to effectively restore the detail information and address the scale variation of salient objects by using the low-level features refined by multi-scale attention. Extensive experiments on two datasets demonstrate that our proposed RRNet outperforms the existing state-of-the-art SOD competitors both qualitatively and quantitatively.
AgreementLearning: An End-to-End Framework for Learning with Multiple Annotators without Groundtruth
Sep 08, 2021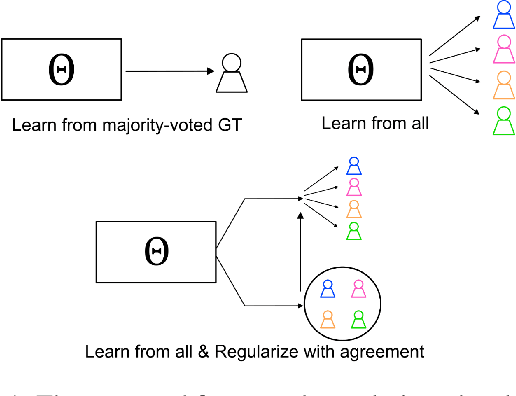
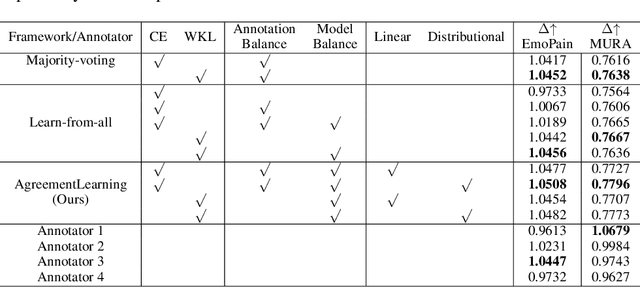
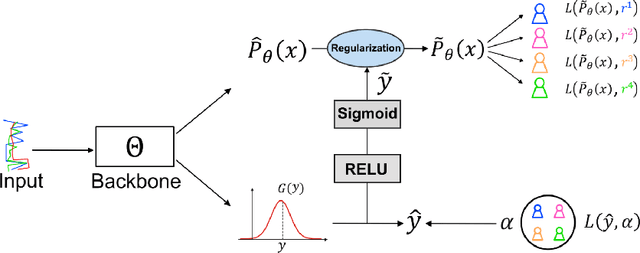
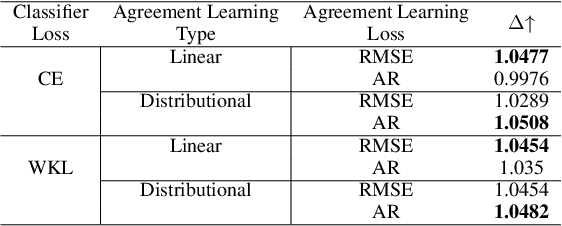
The annotation of domain experts is important for some medical applications where the objective groundtruth is ambiguous to define, e.g., the rehabilitation for some chronic diseases, and the prescreening of some musculoskeletal abnormalities without further medical examinations. However, improper uses of the annotations may hinder developing reliable models. On one hand, forcing the use of a single groundtruth generated from multiple annotations is less informative for the modeling. On the other hand, feeding the model with all the annotations without proper regularization is noisy given existing disagreements. For such issues, we propose a novel agreement learning framework to tackle the challenge of learning from multiple annotators without objective groundtruth. The framework has two streams, with one stream fitting with the multiple annotators and the other stream learning agreement information between the annotators. In particular, the agreement learning stream produces regularization information to the classifier stream, tuning its decision to be better in line with the agreement between the annotators. The proposed method can be easily plugged to existing backbones developed with majority-voted groundtruth or multiple annotations. Thereon, experiments on two medical datasets demonstrate improved agreement levels with annotators.
Scalable pragmatic communication via self-supervision
Aug 12, 2021

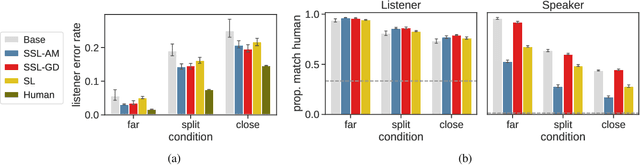
Models of context-sensitive communication often use the Rational Speech Act framework (RSA; Frank & Goodman, 2012), which formulates listeners and speakers in a cooperative reasoning process. However, the standard RSA formulation can only be applied to small domains, and large-scale applications have relied on imitating human behavior. Here, we propose a new approach to scalable pragmatics, building upon recent theoretical results (Zaslavsky et al., 2020) that characterize pragmatic reasoning in terms of general information-theoretic principles. Specifically, we propose an architecture and learning process in which agents acquire pragmatic policies via self-supervision instead of imitating human data. This work suggests a new principled approach for equipping artificial agents with pragmatic skills via self-supervision, which is grounded both in pragmatic theory and in information theory.
Does the Data Induce Capacity Control in Deep Learning?
Oct 27, 2021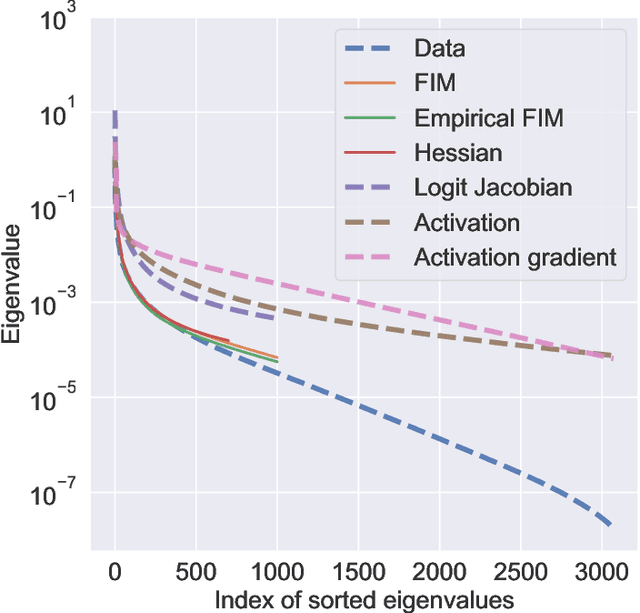
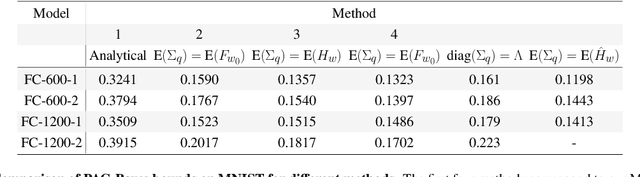
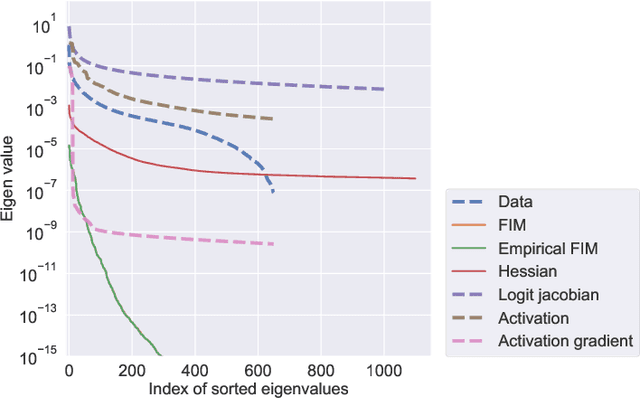
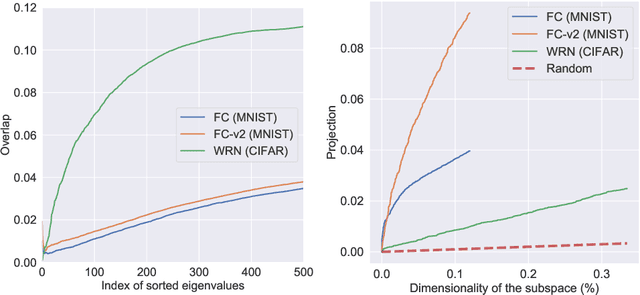
This paper studies how the dataset may be the cause of the anomalous generalization performance of deep networks. We show that the data correlation matrix of typical classification datasets has an eigenspectrum where, after a sharp initial drop, a large number of small eigenvalues are distributed uniformly over an exponentially large range. This structure is mirrored in a network trained on this data: we show that the Hessian and the Fisher Information Matrix (FIM) have eigenvalues that are spread uniformly over exponentially large ranges. We call such eigenspectra "sloppy" because sets of weights corresponding to small eigenvalues can be changed by large magnitudes without affecting the loss. Networks trained on atypical, non-sloppy synthetic data do not share these traits. We show how this structure in the data can give to non-vacuous PAC-Bayes generalization bounds analytically; we also construct data-distribution dependent priors that lead to accurate bounds using numerical optimization.
LAnoBERT : System Log Anomaly Detection based on BERT Masked Language Model
Nov 18, 2021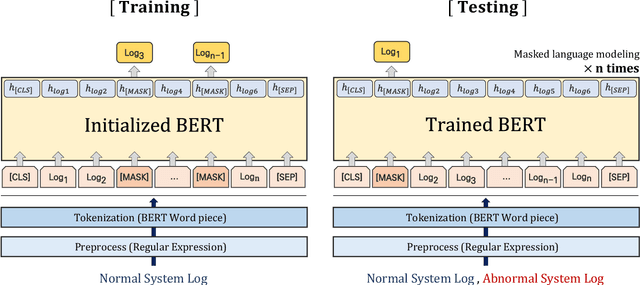
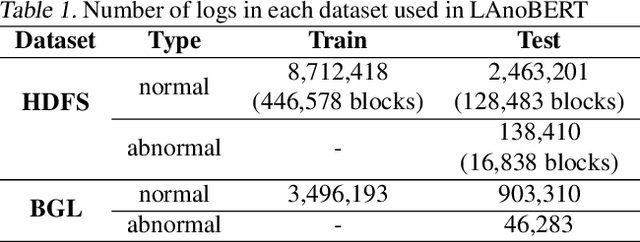


The system log generated in a computer system refers to large-scale data that are collected simultaneously and used as the basic data for determining simple errors and detecting external adversarial intrusion or the abnormal behaviors of insiders. The aim of system log anomaly detection is to promptly identify anomalies while minimizing human intervention, which is a critical problem in the industry. Previous studies performed anomaly detection through algorithms after converting various forms of log data into a standardized template using a parser. These methods involved generating a template for refining the log key. Particularly, a template corresponding to a specific event should be defined in advance for all the log data using which the information within the log key may get lost.In this study, we propose LAnoBERT, a parser free system log anomaly detection method that uses the BERT model, exhibiting excellent natural language processing performance. The proposed method, LAnoBERT, learns the model through masked language modeling, which is a BERT-based pre-training method, and proceeds with unsupervised learning-based anomaly detection using the masked language modeling loss function per log key word during the inference process. LAnoBERT achieved better performance compared to previous methodology in an experiment conducted using benchmark log datasets, HDFS, and BGL, and also compared to certain supervised learning-based models.
Gated Linear Model induced U-net for surrogate modeling and uncertainty quantification
Nov 08, 2021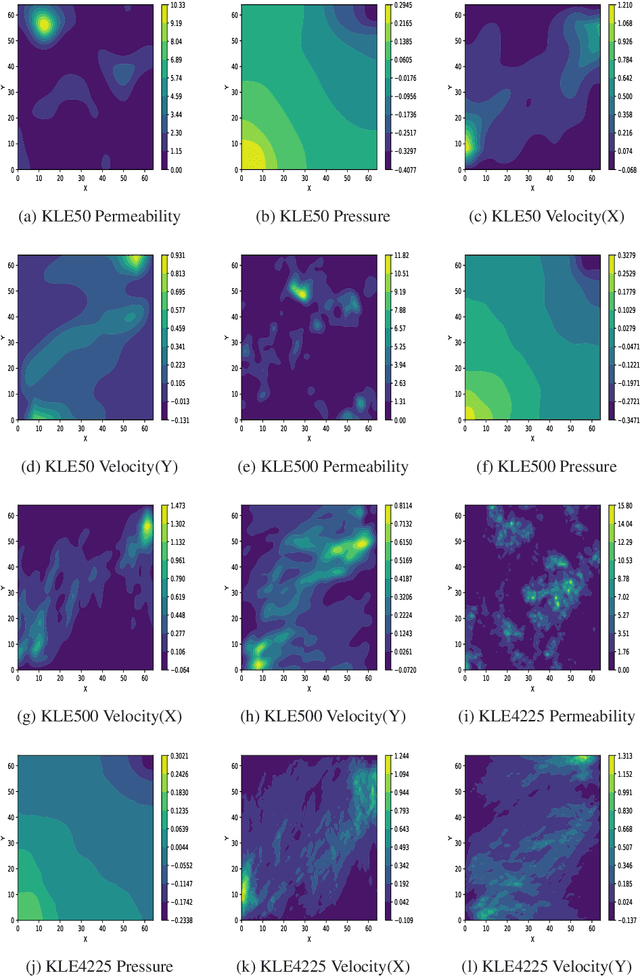
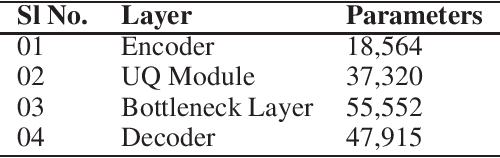
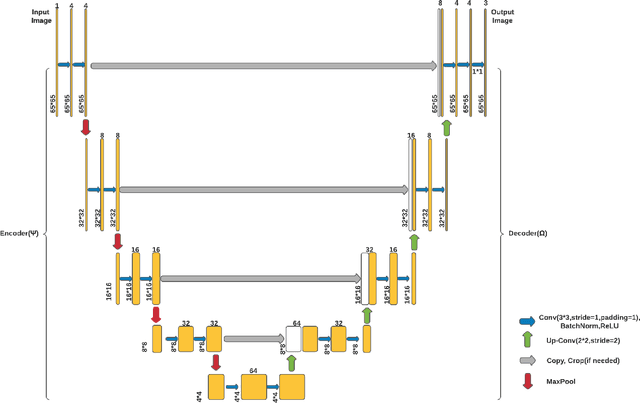

We propose a novel deep learning based surrogate model for solving high-dimensional uncertainty quantification and uncertainty propagation problems. The proposed deep learning architecture is developed by integrating the well-known U-net architecture with the Gaussian Gated Linear Network (GGLN) and referred to as the Gated Linear Network induced U-net or GLU-net. The proposed GLU-net treats the uncertainty propagation problem as an image to image regression and hence, is extremely data efficient. Additionally, it also provides estimates of the predictive uncertainty. The network architecture of GLU-net is less complex with 44\% fewer parameters than the contemporary works. We illustrate the performance of the proposed GLU-net in solving the Darcy flow problem under uncertainty under the sparse data scenario. We consider the stochastic input dimensionality to be up to 4225. Benchmark results are generated using the vanilla Monte Carlo simulation. We observe the proposed GLU-net to be accurate and extremely efficient even when no information about the structure of the inputs is provided to the network. Case studies are performed by varying the training sample size and stochastic input dimensionality to illustrate the robustness of the proposed approach.
HHP-Net: A light Heteroscedastic neural network for Head Pose estimation with uncertainty
Nov 02, 2021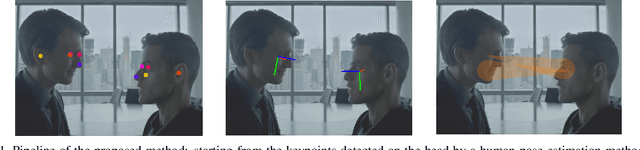
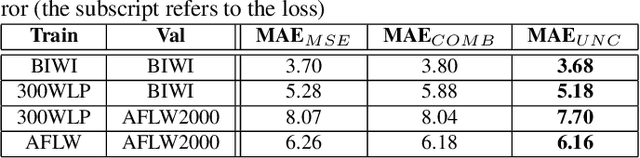
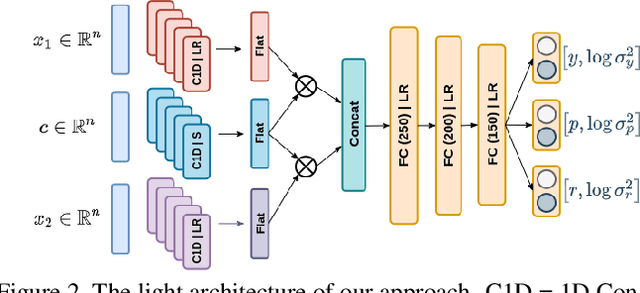
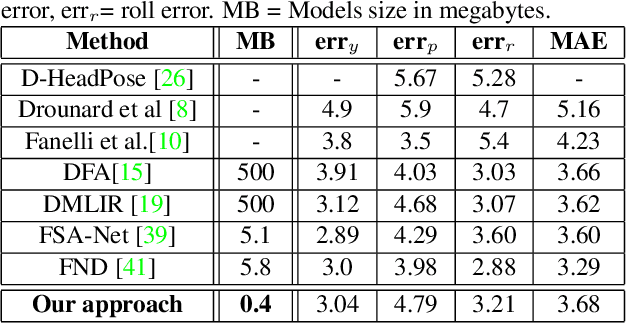
In this paper we introduce a novel method to estimate the head pose of people in single images starting from a small set of head keypoints. To this purpose, we propose a regression model that exploits keypoints computed automatically by 2D pose estimation algorithms and outputs the head pose represented by yaw, pitch, and roll. Our model is simple to implement and more efficient with respect to the state of the art -- faster in inference and smaller in terms of memory occupancy -- with comparable accuracy. Our method also provides a measure of the heteroscedastic uncertainties associated with the three angles, through an appropriately designed loss function; we show there is a correlation between error and uncertainty values, thus this extra source of information may be used in subsequent computational steps. As an example application, we address social interaction analysis in images: we propose an algorithm for a quantitative estimation of the level of interaction between people, starting from their head poses and reasoning on their mutual positions. The code is available at https://github.com/cantarinigiorgio/HHP-Net.
Template NeRF: Towards Modeling Dense Shape Correspondences from Category-Specific Object Images
Nov 08, 2021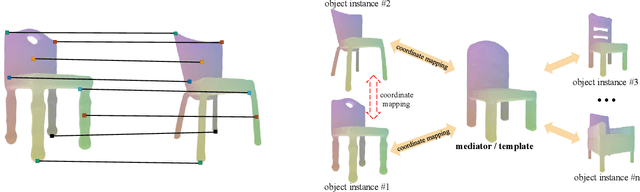
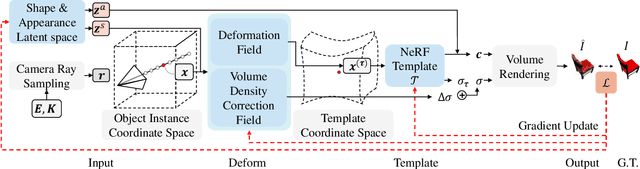
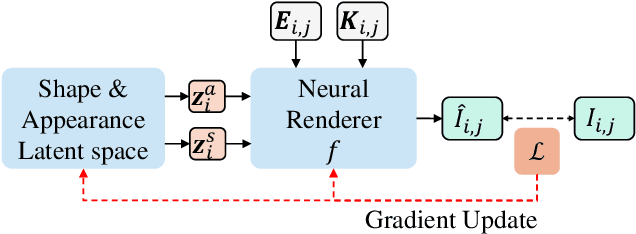
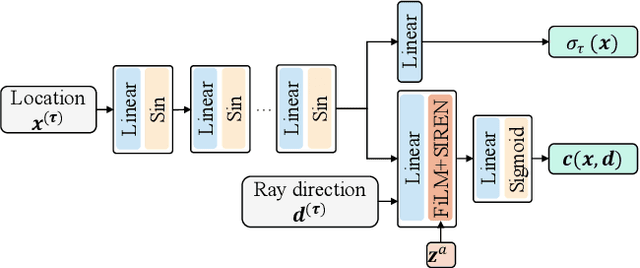
We present neural radiance fields (NeRF) with templates, dubbed Template-NeRF, for modeling appearance and geometry and generating dense shape correspondences simultaneously among objects of the same category from only multi-view posed images, without the need of either 3D supervision or ground-truth correspondence knowledge. The learned dense correspondences can be readily used for various image-based tasks such as keypoint detection, part segmentation, and texture transfer that previously require specific model designs. Our method can also accommodate annotation transfer in a one or few-shot manner, given only one or a few instances of the category. Using periodic activation and feature-wise linear modulation (FiLM) conditioning, we introduce deep implicit templates on 3D data into the 3D-aware image synthesis pipeline NeRF. By representing object instances within the same category as shape and appearance variation of a shared NeRF template, our proposed method can achieve dense shape correspondences reasoning on images for a wide range of object classes. We demonstrate the results and applications on both synthetic and real-world data with competitive results compared with other methods based on 3D information.