 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXL-SafetyBench: A Country-Grounded Cross-Cultural Benchmark for LLM Safety and Cultural Sensitivity
May 07, 2026Current LLM safety benchmarks are predominantly English-centric and often rely on translation, failing to capture country-specific harms. Moreover, they rarely evaluate a model's ability to detect culturally embedded sensitivities as distinct from universal harms. We introduce XL-SafetyBench. a suite of 5,500 test cases across 10 country-language pairs, comprising a Jailbreak Benchmark of country-grounded adversarial prompts and a Cultural Benchmark where local sensitivities are embedded within innocuous requests. Each item is constructed via a multi-stage pipeline that combines LLM-assisted discovery, automated validation gates, and dual independent native-speaker annotators per country. To distinguish principled refusal from comprehension failure, we evaluate Attack Success Rate (ASR) alongside two complementary metrics we introduce: Neutral-Safe Rate (NSR) and Cultural Sensitivity Rate (CSR). Evaluating 10 frontier and 27 local LLMs reveals two key findings. First, jailbreak robustness and cultural awareness do not show a coupled relationship among frontier models, so a composite safety score obscures per-axis variation. Second, local models exhibit a near-linear ASR-NSR trade-off (r = -0.81), indicating that their apparent safety reflects generation failure rather than genuine alignment. XL-SafetyBench enables more nuanced, cross-cultural safety evaluation in the multilingual era.
Towards Safer Pretraining: Analyzing and Filtering Harmful Content in Webscale datasets for Responsible LLMs
May 04, 2025Large language models (LLMs) have become integral to various real-world applications, leveraging massive, web-sourced datasets like Common Crawl, C4, and FineWeb for pretraining. While these datasets provide linguistic data essential for high-quality natural language generation, they often contain harmful content, such as hate speech, misinformation, and biased narratives. Training LLMs on such unfiltered data risks perpetuating toxic behaviors, spreading misinformation, and amplifying societal biases which can undermine trust in LLM-driven applications and raise ethical concerns about their use. This paper presents a large-scale analysis of inappropriate content across these datasets, offering a comprehensive taxonomy that categorizes harmful webpages into Topical and Toxic based on their intent. We also introduce a prompt evaluation dataset, a high-accuracy Topical and Toxic Prompt (TTP), and a transformer-based model (HarmFormer) for content filtering. Additionally, we create a new multi-harm open-ended toxicity benchmark (HAVOC) and provide crucial insights into how models respond to adversarial toxic inputs. Upon publishing, we will also opensource our model signal on the entire C4 dataset. Our work offers insights into ensuring safer LLM pretraining and serves as a resource for Responsible AI (RAI) compliance.
Gated Linear Model induced U-net for surrogate modeling and uncertainty quantification
Nov 08, 2021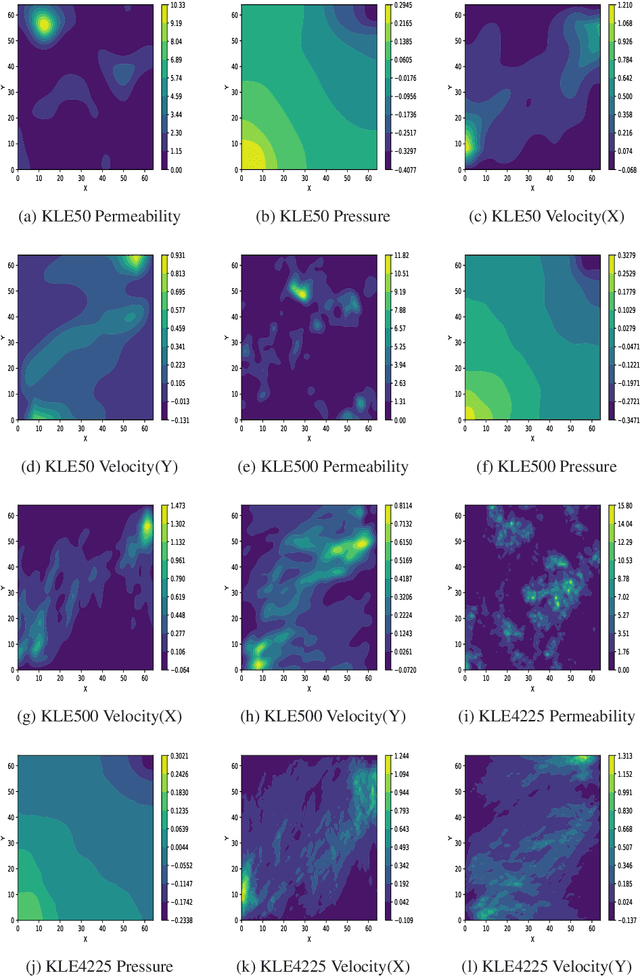
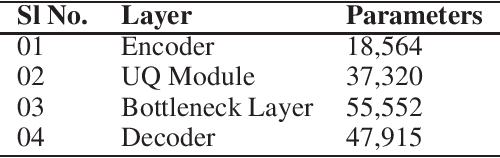
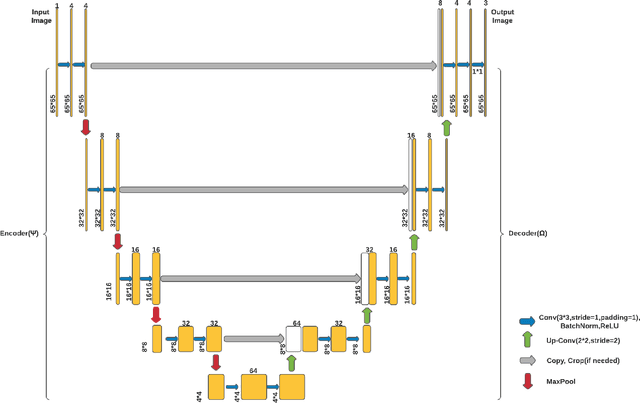

We propose a novel deep learning based surrogate model for solving high-dimensional uncertainty quantification and uncertainty propagation problems. The proposed deep learning architecture is developed by integrating the well-known U-net architecture with the Gaussian Gated Linear Network (GGLN) and referred to as the Gated Linear Network induced U-net or GLU-net. The proposed GLU-net treats the uncertainty propagation problem as an image to image regression and hence, is extremely data efficient. Additionally, it also provides estimates of the predictive uncertainty. The network architecture of GLU-net is less complex with 44\% fewer parameters than the contemporary works. We illustrate the performance of the proposed GLU-net in solving the Darcy flow problem under uncertainty under the sparse data scenario. We consider the stochastic input dimensionality to be up to 4225. Benchmark results are generated using the vanilla Monte Carlo simulation. We observe the proposed GLU-net to be accurate and extremely efficient even when no information about the structure of the inputs is provided to the network. Case studies are performed by varying the training sample size and stochastic input dimensionality to illustrate the robustness of the proposed approach.