 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled representations of microscopy images
Jun 25, 2025Microscopy image analysis is fundamental for different applications, from diagnosis to synthetic engineering and environmental monitoring. Modern acquisition systems have granted the possibility to acquire an escalating amount of images, requiring a consequent development of a large collection of deep learning-based automatic image analysis methods. Although deep neural networks have demonstrated great performance in this field, interpretability, an essential requirement for microscopy image analysis, remains an open challenge. This work proposes a Disentangled Representation Learning (DRL) methodology to enhance model interpretability for microscopy image classification. Exploiting benchmark datasets from three different microscopic image domains (plankton, yeast vacuoles, and human cells), we show how a DRL framework, based on transferring a representation learnt from synthetic data, can provide a good trade-off between accuracy and interpretability in this domain.
Transferring disentangled representations: bridging the gap between synthetic and real images
Sep 26, 2024



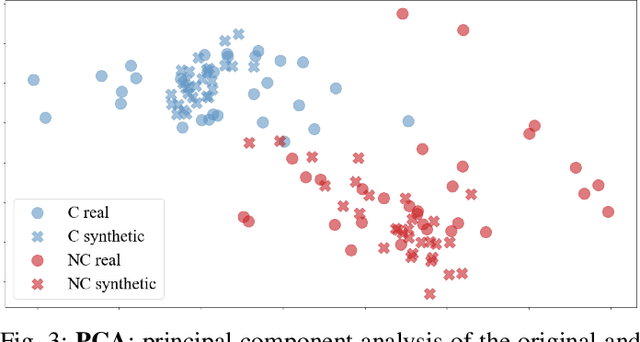
Developing meaningful and efficient representations that separate the fundamental structure of the data generation mechanism is crucial in representation learning. However, Disentangled Representation Learning has not fully shown its potential on real images, because of correlated generative factors, their resolution and limited access to ground truth labels. Specifically on the latter, we investigate the possibility of leveraging synthetic data to learn general-purpose disentangled representations applicable to real data, discussing the effect of fine-tuning and what properties of disentanglement are preserved after the transfer. We provide an extensive empirical study to address these issues. In addition, we propose a new interpretable intervention-based metric, to measure the quality of factors encoding in the representation. Our results indicate that some level of disentanglement, transferring a representation from synthetic to real data, is possible and effective.
Anticipation through Head Pose Estimation: a preliminary study
Aug 10, 2024



The ability to anticipate others' goals and intentions is at the basis of human-human social interaction. Such ability, largely based on non-verbal communication, is also a key to having natural and pleasant interactions with artificial agents, like robots. In this work, we discuss a preliminary experiment on the use of head pose as a visual cue to understand and anticipate action goals, particularly reaching and transporting movements. By reasoning on the spatio-temporal connections between the head, hands and objects in the scene, we will show that short-range anticipation is possible, laying the foundations for future applications to human-robot interaction.
Shortcuts for causal discovery of nonlinear models by score matching
Oct 22, 2023



The use of simulated data in the field of causal discovery is ubiquitous due to the scarcity of annotated real data. Recently, Reisach et al., 2021 highlighted the emergence of patterns in simulated linear data, which displays increasing marginal variance in the casual direction. As an ablation in their experiments, Montagna et al., 2023 found that similar patterns may emerge in nonlinear models for the variance of the score vector $\nabla \log p_{\mathbf{X}}$, and introduced the ScoreSort algorithm. In this work, we formally define and characterize this score-sortability pattern of nonlinear additive noise models. We find that it defines a class of identifiable (bivariate) causal models overlapping with nonlinear additive noise models. We theoretically demonstrate the advantages of ScoreSort in terms of statistical efficiency compared to prior state-of-the-art score matching-based methods and empirically show the score-sortability of the most common synthetic benchmarks in the literature. Our findings remark (1) the lack of diversity in the data as an important limitation in the evaluation of nonlinear causal discovery approaches, (2) the importance of thoroughly testing different settings within a problem class, and (3) the importance of analyzing statistical properties in causal discovery, where research is often limited to defining identifiability conditions of the model.
Assumption violations in causal discovery and the robustness of score matching
Oct 20, 2023



When domain knowledge is limited and experimentation is restricted by ethical, financial, or time constraints, practitioners turn to observational causal discovery methods to recover the causal structure, exploiting the statistical properties of their data. Because causal discovery without further assumptions is an ill-posed problem, each algorithm comes with its own set of usually untestable assumptions, some of which are hard to meet in real datasets. Motivated by these considerations, this paper extensively benchmarks the empirical performance of recent causal discovery methods on observational i.i.d. data generated under different background conditions, allowing for violations of the critical assumptions required by each selected approach. Our experimental findings show that score matching-based methods demonstrate surprising performance in the false positive and false negative rate of the inferred graph in these challenging scenarios, and we provide theoretical insights into their performance. This work is also the first effort to benchmark the stability of causal discovery algorithms with respect to the values of their hyperparameters. Finally, we hope this paper will set a new standard for the evaluation of causal discovery methods and can serve as an accessible entry point for practitioners interested in the field, highlighting the empirical implications of different algorithm choices.
Scalable Causal Discovery with Score Matching
Apr 06, 2023



This paper demonstrates how to discover the whole causal graph from the second derivative of the log-likelihood in observational non-linear additive Gaussian noise models. Leveraging scalable machine learning approaches to approximate the score function $\nabla \log p(\mathbf{X})$, we extend the work of Rolland et al. (2022) that only recovers the topological order from the score and requires an expensive pruning step removing spurious edges among those admitted by the ordering. Our analysis leads to DAS (acronym for Discovery At Scale), a practical algorithm that reduces the complexity of the pruning by a factor proportional to the graph size. In practice, DAS achieves competitive accuracy with current state-of-the-art while being over an order of magnitude faster. Overall, our approach enables principled and scalable causal discovery, significantly lowering the compute bar.
Causal Discovery with Score Matching on Additive Models with Arbitrary Noise
Apr 06, 2023



Causal discovery methods are intrinsically constrained by the set of assumptions needed to ensure structure identifiability. Moreover additional restrictions are often imposed in order to simplify the inference task: this is the case for the Gaussian noise assumption on additive non-linear models, which is common to many causal discovery approaches. In this paper we show the shortcomings of inference under this hypothesis, analyzing the risk of edge inversion under violation of Gaussianity of the noise terms. Then, we propose a novel method for inferring the topological ordering of the variables in the causal graph, from data generated according to an additive non-linear model with a generic noise distribution. This leads to NoGAM (Not only Gaussian Additive noise Models), a causal discovery algorithm with a minimal set of assumptions and state of the art performance, experimentally benchmarked on synthetic data.
Robots with Different Embodiments Can Express and Influence Carefulness in Object Manipulation
Aug 03, 2022

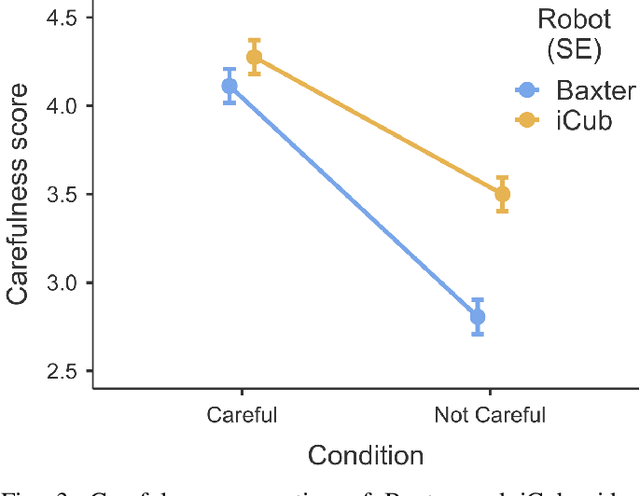
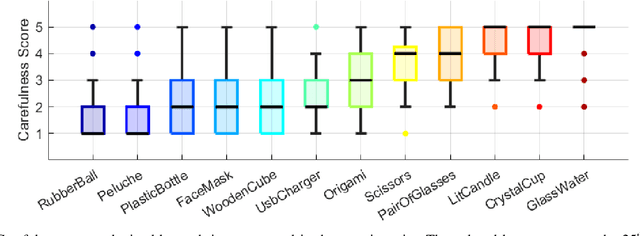
Humans have an extraordinary ability to communicate and read the properties of objects by simply watching them being carried by someone else. This level of communicative skills and interpretation, available to humans, is essential for collaborative robots if they are to interact naturally and effectively. For example, suppose a robot is handing over a fragile object. In that case, the human who receives it should be informed of its fragility in advance, through an immediate and implicit message, i.e., by the direct modulation of the robot's action. This work investigates the perception of object manipulations performed with a communicative intent by two robots with different embodiments (an iCub humanoid robot and a Baxter robot). We designed the robots' movements to communicate carefulness or not during the transportation of objects. We found that not only this feature is correctly perceived by human observers, but it can elicit as well a form of motor adaptation in subsequent human object manipulations. In addition, we get an insight into which motion features may induce to manipulate an object more or less carefully.
Synthesis and Execution of Communicative Robotic Movements with Generative Adversarial Networks
Mar 31, 2022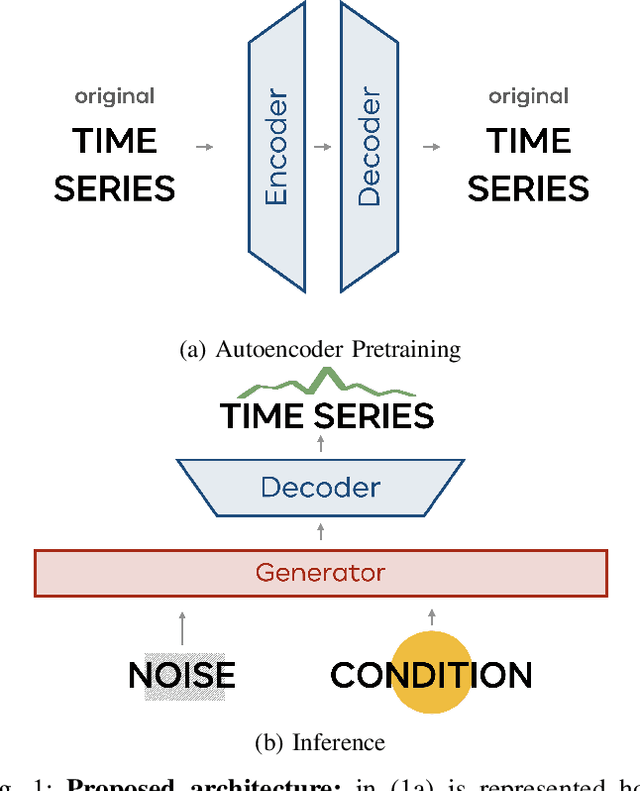
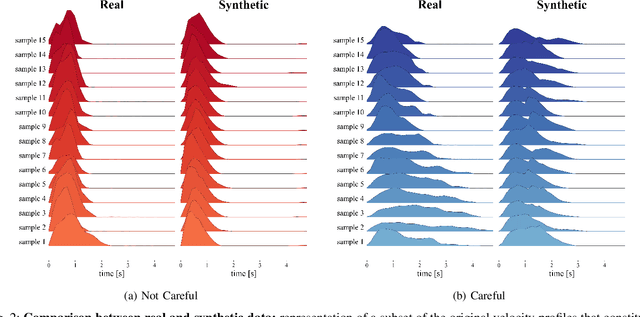
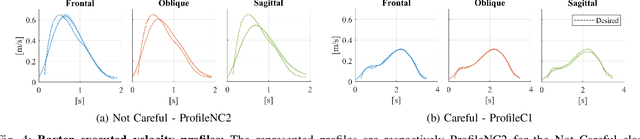
Object manipulation is a natural activity we perform every day. How humans handle objects can communicate not only the willfulness of the acting, or key aspects of the context where we operate, but also the properties of the objects involved, without any need for explicit verbal description. Since human intelligence comprises the ability to read the context, allowing robots to perform actions that intuitively convey this kind of information would greatly facilitate collaboration. In this work, we focus on how to transfer on two different robotic platforms the same kinematics modulation that humans adopt when manipulating delicate objects, aiming to endow robots with the capability to show carefulness in their movements. We choose to modulate the velocity profile adopted by the robots' end-effector, inspired by what humans do when transporting objects with different characteristics. We exploit a novel Generative Adversarial Network architecture, trained with human kinematics examples, to generalize over them and generate new and meaningful velocity profiles, either associated with careful or not careful attitudes. This approach would allow next generation robots to select the most appropriate style of movement, depending on the perceived context, and autonomously generate their motor action execution.
HHP-Net: A light Heteroscedastic neural network for Head Pose estimation with uncertainty
Nov 03, 2021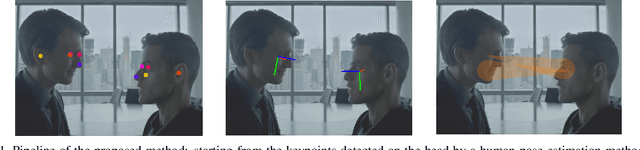
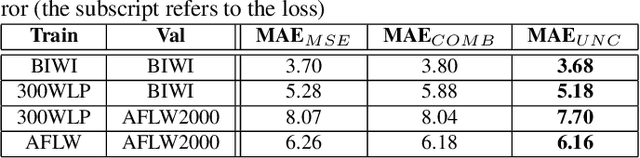
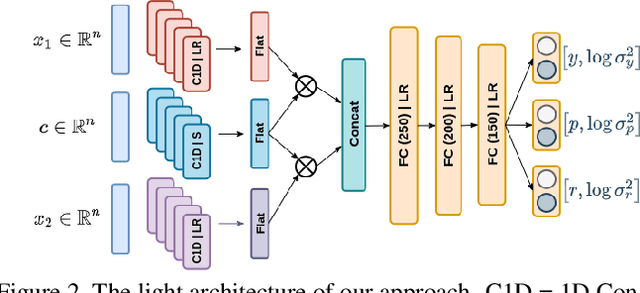
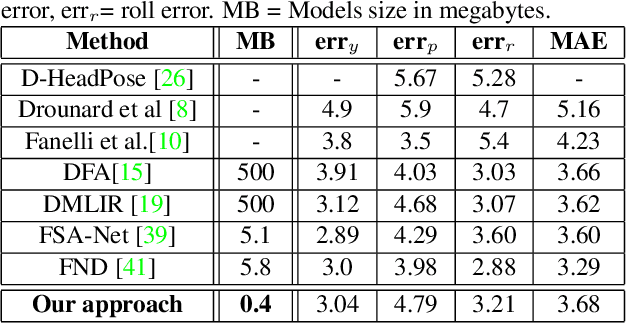
In this paper we introduce a novel method to estimate the head pose of people in single images starting from a small set of head keypoints. To this purpose, we propose a regression model that exploits keypoints computed automatically by 2D pose estimation algorithms and outputs the head pose represented by yaw, pitch, and roll. Our model is simple to implement and more efficient with respect to the state of the art -- faster in inference and smaller in terms of memory occupancy -- with comparable accuracy. Our method also provides a measure of the heteroscedastic uncertainties associated with the three angles, through an appropriately designed loss function; we show there is a correlation between error and uncertainty values, thus this extra source of information may be used in subsequent computational steps. As an example application, we address social interaction analysis in images: we propose an algorithm for a quantitative estimation of the level of interaction between people, starting from their head poses and reasoning on their mutual positions. The code is available at https://github.com/cantarinigiorgio/HHP-Net.