 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-stage Clarification in Conversational AI: The case of Question-Answering Dialogue Systems
Oct 28, 2021

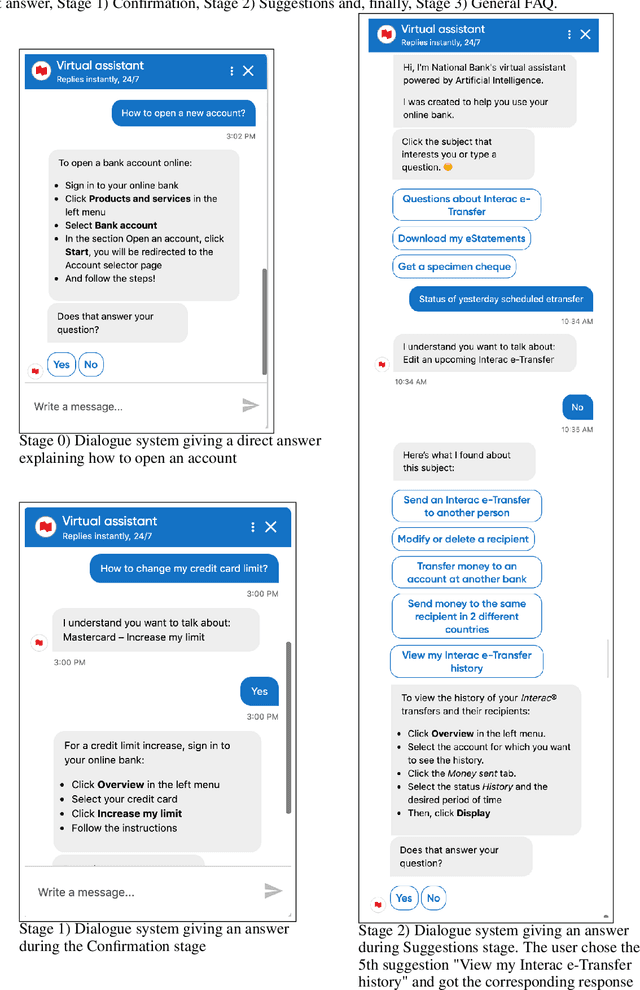

Clarification resolution plays an important role in various information retrieval tasks such as interactive question answering and conversational search. In such context, the user often formulates their information needs as short and ambiguous queries, some popular search interfaces then prompt the user to confirm her intent (e.g. "Did you mean ... ?") or to rephrase if needed. When it comes to dialogue systems, having fluid user-bot exchanges is key to good user experience. In the absence of such clarification mechanism, one of the following responses is given to the user: 1) A direct answer, which can potentially be non-relevant if the intent was not clear, 2) a generic fallback message informing the user that the retrieval tool is incapable of handling the query. Both scenarios might raise frustration and degrade the user experience. To this end, we propose a multi-stage clarification mechanism for prompting clarification and query selection in the context of a question answering dialogue system. We show that our proposed mechanism improves the overall user experience and outperforms competitive baselines with two datasets, namely the public in-scope out-of-scope dataset and a commercial dataset based on real user logs.
Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention
Dec 28, 2021



Recently, Transformers have shown promising performance in various vision tasks. To reduce the quadratic computation complexity caused by the global self-attention, various methods constrain the range of attention within a local region to improve its efficiency. Consequently, their receptive fields in a single attention layer are not large enough, resulting in insufficient context modeling. To address this issue, we propose a Pale-Shaped self-Attention (PS-Attention), which performs self-attention within a pale-shaped region. Compared to the global self-attention, PS-Attention can reduce the computation and memory costs significantly. Meanwhile, it can capture richer contextual information under the similar computation complexity with previous local self-attention mechanisms. Based on the PS-Attention, we develop a general Vision Transformer backbone with a hierarchical architecture, named Pale Transformer, which achieves 83.4%, 84.3%, and 84.9% Top-1 accuracy with the model size of 22M, 48M, and 85M respectively for 224 ImageNet-1K classification, outperforming the previous Vision Transformer backbones. For downstream tasks, our Pale Transformer backbone performs better than the recent state-of-the-art CSWin Transformer by a large margin on ADE20K semantic segmentation and COCO object detection & instance segmentation. The code will be released on https://github.com/BR-IDL/PaddleViT.
AI-Based Secure NOMA and Cognitive Radio enabled Green Communications: Channel State Information and Battery Value Uncertainties
Jun 30, 2021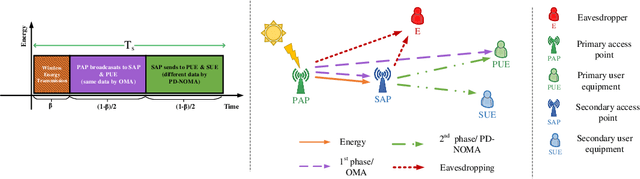
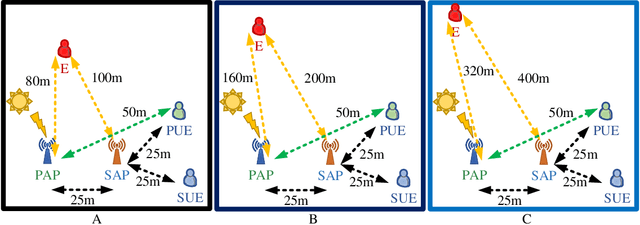
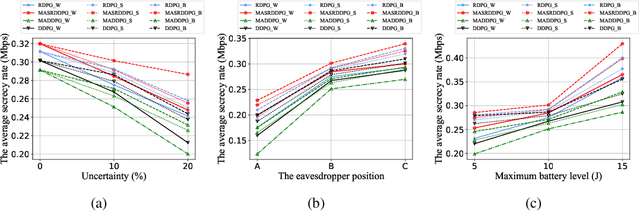
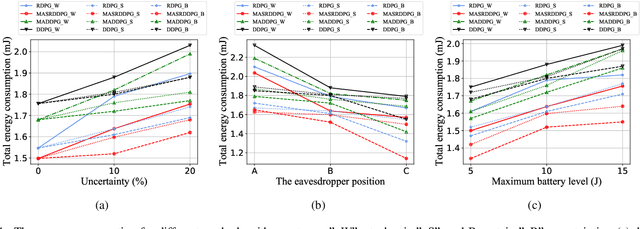
In this paper, the security-aware robust resource allocation in energy harvesting cognitive radio networks is considered with cooperation between two transmitters while there are uncertainties in channel gains and battery energy value. To be specific, the primary access point harvests energy from the green resource and uses time switching protocol to send the energy and data towards the secondary access point (SAP). Using power-domain non-orthogonal multiple access technique, the SAP helps the primary network to improve the security of data transmission by using the frequency band of the primary network. In this regard, we introduce the problem of maximizing the proportional-fair energy efficiency (PFEE) considering uncertainty in the channel gains and battery energy value subject to the practical constraints. Moreover, the channel gain of the eavesdropper is assumed to be unknown. Employing the decentralized partially observable Markov decision process, we investigate the solution of the corresponding resource allocation problem. We exploit multi-agent with single reward deep deterministic policy gradient (MASRDDPG) and recurrent deterministic policy gradient (RDPG) methods. These methods are compared with the state-of-the-art ones like multi-agent and single-agent DDPG. Simulation results show that both MASRDDPG and RDPG methods, outperform the state-of-the-art methods by providing more PFEE to the network.
Siamese Network with Interactive Transformer for Video Object Segmentation
Dec 28, 2021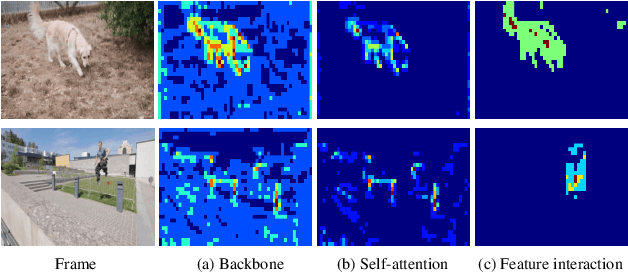
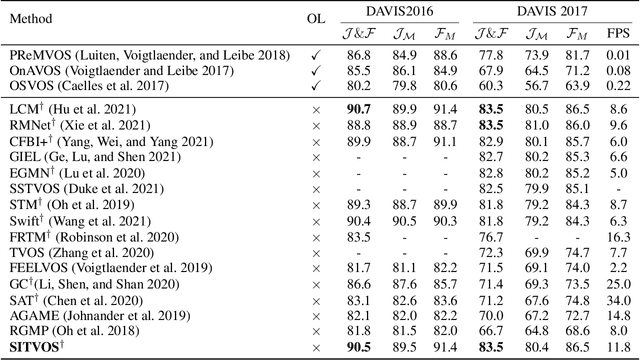
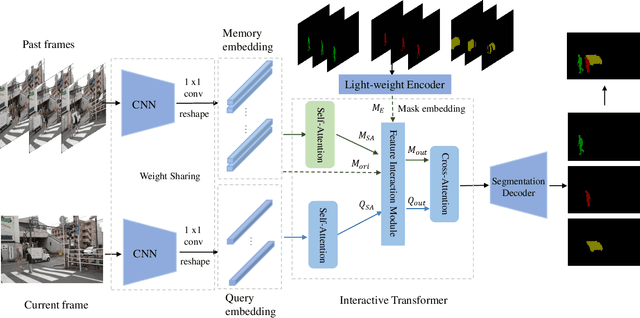
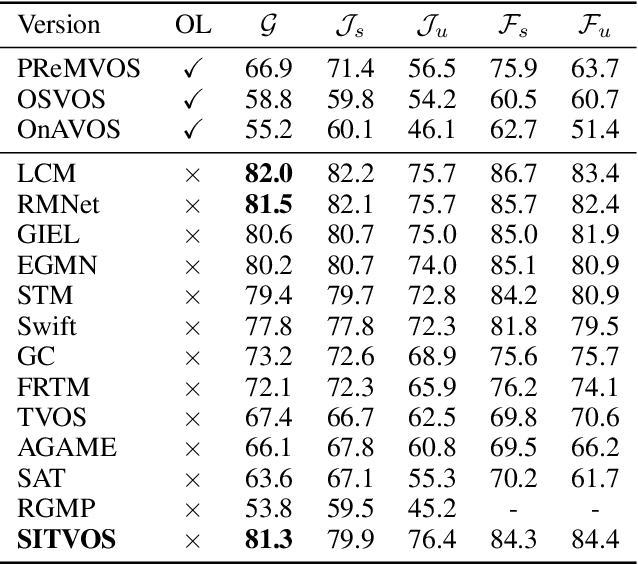
Semi-supervised video object segmentation (VOS) refers to segmenting the target object in remaining frames given its annotation in the first frame, which has been actively studied in recent years. The key challenge lies in finding effective ways to exploit the spatio-temporal context of past frames to help learn discriminative target representation of current frame. In this paper, we propose a novel Siamese network with a specifically designed interactive transformer, called SITVOS, to enable effective context propagation from historical to current frames. Technically, we use the transformer encoder and decoder to handle the past frames and current frame separately, i.e., the encoder encodes robust spatio-temporal context of target object from the past frames, while the decoder takes the feature embedding of current frame as the query to retrieve the target from the encoder output. To further enhance the target representation, a feature interaction module (FIM) is devised to promote the information flow between the encoder and decoder. Moreover, we employ the Siamese architecture to extract backbone features of both past and current frames, which enables feature reuse and is more efficient than existing methods. Experimental results on three challenging benchmarks validate the superiority of SITVOS over state-of-the-art methods.
Advancing Residual Learning towards Powerful Deep Spiking Neural Networks
Dec 23, 2021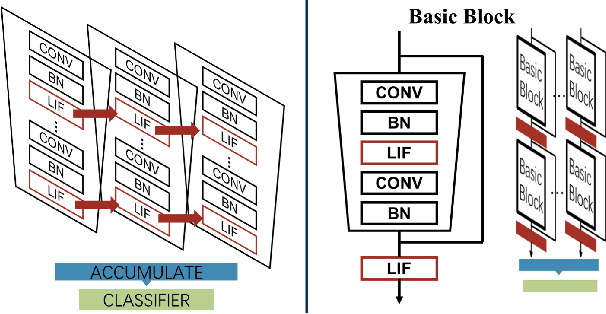

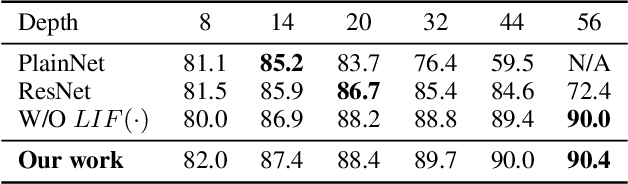
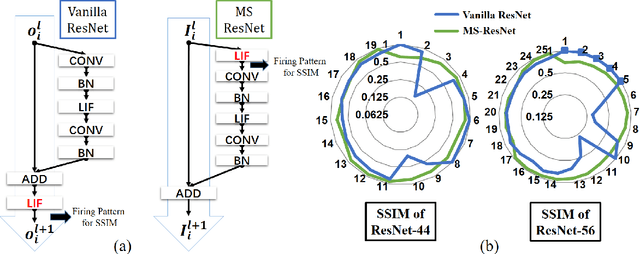
Despite the rapid progress of neuromorphic computing, inadequate capacity and insufficient representation power of spiking neural networks (SNNs) severely restrict their application scope in practice. Residual learning and shortcuts have been evidenced as an important approach for training deep neural networks, but rarely did previous work assess their applicability to the characteristics of spike-based communication and spatiotemporal dynamics. In this paper, we first identify that this negligence leads to impeded information flow and accompanying degradation problem in previous residual SNNs. Then we propose a novel SNN-oriented residual block, MS-ResNet, which is able to significantly extend the depth of directly trained SNNs, e.g. up to 482 layers on CIFAR-10 and 104 layers on ImageNet, without observing any slight degradation problem. We validate the effectiveness of MS-ResNet on both frame-based and neuromorphic datasets, and MS-ResNet104 achieves a superior result of 76.02% accuracy on ImageNet, the first time in the domain of directly trained SNNs. Great energy efficiency is also observed that on average only one spike per neuron is needed to classify an input sample. We believe our powerful and scalable models will provide a strong support for further exploration of SNNs.
A Multi-View Framework for BGP Anomaly Detection via Graph Attention Network
Dec 23, 2021
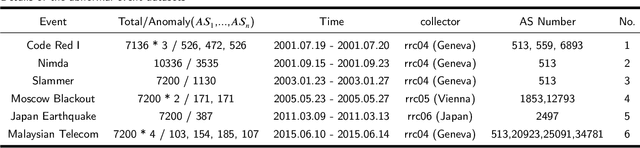
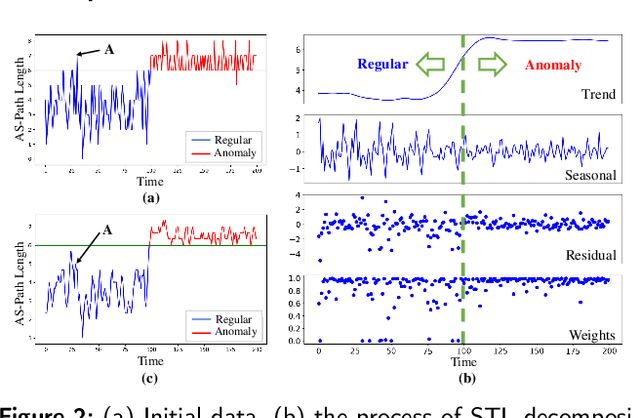

As the default protocol for exchanging routing reachability information on the Internet, the abnormal behavior in traffic of Border Gateway Protocols (BGP) is closely related to Internet anomaly events. The BGP anomalous detection model ensures stable routing services on the Internet through its real-time monitoring and alerting capabilities. Previous studies either focused on the feature selection problem or the memory characteristic in data, while ignoring the relationship between features and the precise time correlation in feature (whether it's long or short term dependence). In this paper, we propose a multi-view model for capturing anomalous behaviors from BGP update traffic, in which Seasonal and Trend decomposition using Loess (STL) method is used to reduce the noise in the original time-series data, and Graph Attention Network (GAT) is used to discover feature relationships and time correlations in feature, respectively. Our results outperform the state-of-the-art methods at the anomaly detection task, with the average F1 score up to 96.3% and 93.2% on the balanced and imbalanced datasets respectively. Meanwhile, our model can be extended to classify multiple anomalous and to detect unknown events.
MAg: a simple learning-based patient-level aggregation method for detecting microsatellite instability from whole-slide images
Jan 13, 2022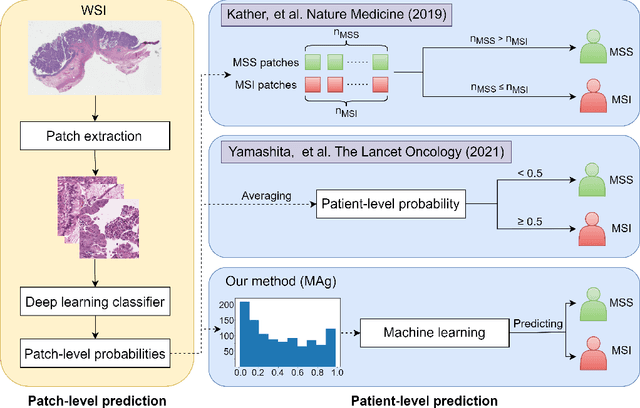
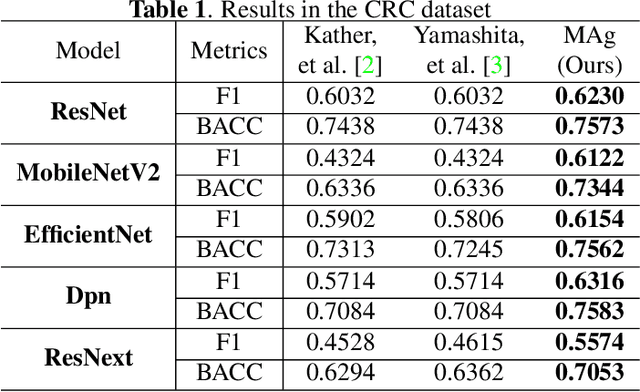
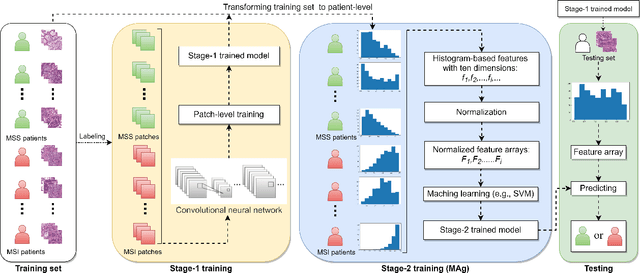
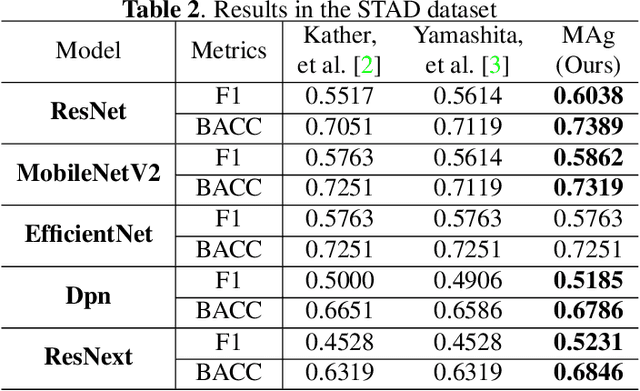
The prediction of microsatellite instability (MSI) and microsatellite stability (MSS) is essential in predicting both the treatment response and prognosis of gastrointestinal cancer. In clinical practice, a universal MSI testing is recommended, but the accessibility of such a test is limited. Thus, a more cost-efficient and broadly accessible tool is desired to cover the traditionally untested patients. In the past few years, deep-learning-based algorithms have been proposed to predict MSI directly from haematoxylin and eosin (H&E)-stained whole-slide images (WSIs). Such algorithms can be summarized as (1) patch-level MSI/MSS prediction, and (2) patient-level aggregation. Compared with the advanced deep learning approaches that have been employed for the first stage, only the na\"ive first-order statistics (e.g., averaging and counting) were employed in the second stage. In this paper, we propose a simple yet broadly generalizable patient-level MSI aggregation (MAg) method to effectively integrate the precious patch-level information. Briefly, the entire probabilistic distribution in the first stage is modeled as histogram-based features to be fused as the final outcome with machine learning (e.g., SVM). The proposed MAg method can be easily used in a plug-and-play manner, which has been evaluated upon five broadly used deep neural networks: ResNet, MobileNetV2, EfficientNet, Dpn and ResNext. From the results, the proposed MAg method consistently improves the accuracy of patient-level aggregation for two publicly available datasets. It is our hope that the proposed method could potentially leverage the low-cost H&E based MSI detection method. The code of our work has been made publicly available at https://github.com/Calvin-Pang/MAg.
AET-SGD: Asynchronous Event-triggered Stochastic Gradient Descent
Dec 27, 2021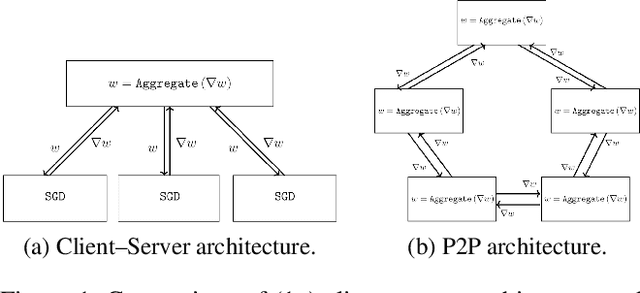
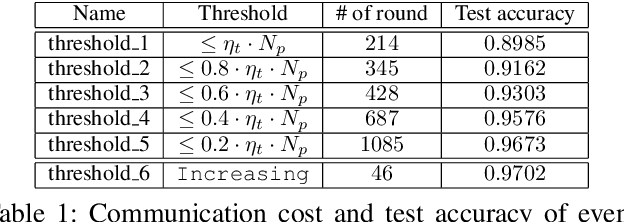
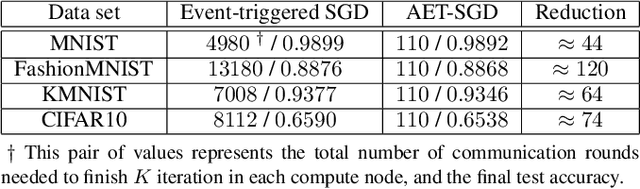
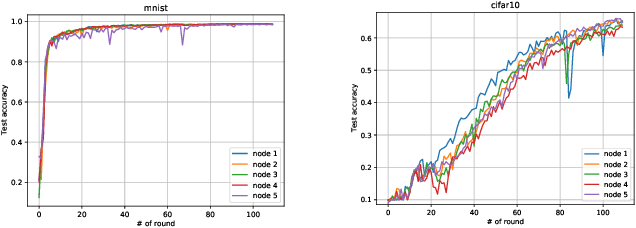
Communication cost is the main bottleneck for the design of effective distributed learning algorithms. Recently, event-triggered techniques have been proposed to reduce the exchanged information among compute nodes and thus alleviate the communication cost. However, most existing event-triggered approaches only consider heuristic event-triggered thresholds. They also ignore the impact of computation and network delay, which play an important role on the training performance. In this paper, we propose an Asynchronous Event-triggered Stochastic Gradient Descent (SGD) framework, called AET-SGD, to i) reduce the communication cost among the compute nodes, and ii) mitigate the impact of the delay. Compared with baseline event-triggered methods, AET-SGD employs a linear increasing sample size event-triggered threshold, and can significantly reduce the communication cost while keeping good convergence performance. We implement AET-SGD and evaluate its performance on multiple representative data sets, including MNIST, FashionMNIST, KMNIST and CIFAR10. The experimental results validate the correctness of the design and show a significant communication cost reduction from 44x to 120x, compared to the state of the art. Our results also show that AET-SGD can resist large delay from the straggler nodes while obtaining a decent performance and a desired speedup ratio.
S-DCCRN: Super Wide Band DCCRN with learnable complex feature for speech enhancement
Nov 16, 2021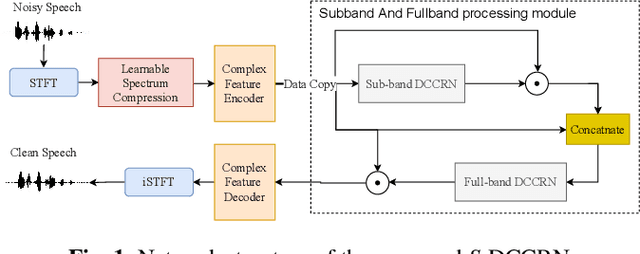
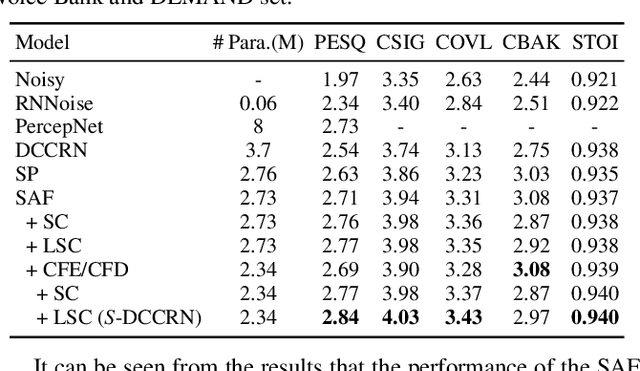
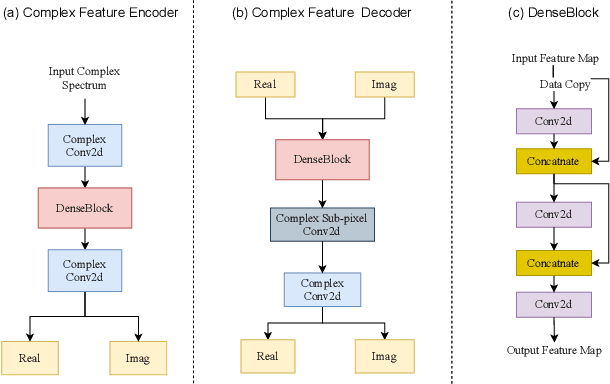
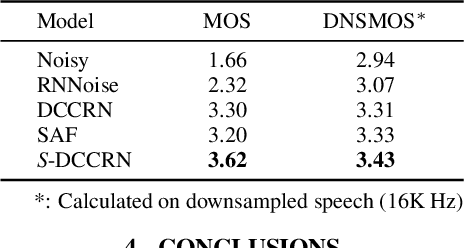
In speech enhancement, complex neural network has shown promising performance due to their effectiveness in processing complex-valued spectrum. Most of the recent speech enhancement approaches mainly focus on wide-band signal with a sampling rate of 16K Hz. However, research on super wide band (e.g., 32K Hz) or even full-band (48K) denoising is still lacked due to the difficulty of modeling more frequency bands and particularly high frequency components. In this paper, we extend our previous deep complex convolution recurrent neural network (DCCRN) substantially to a super wide band version -- S-DCCRN, to perform speech denoising on speech of 32K Hz sampling rate. We first employ a cascaded sub-band and full-band processing module, which consists of two small-footprint DCCRNs -- one operates on sub-band signal and one operates on full-band signal, aiming at benefiting from both local and global frequency information. Moreover, instead of simply adopting the STFT feature as input, we use a complex feature encoder trained in an end-to-end manner to refine the information of different frequency bands. We also use a complex feature decoder to revert the feature to time-frequency domain. Finally, a learnable spectrum compression method is adopted to adjust the energy of different frequency bands, which is beneficial for neural network learning. The proposed model, S-DCCRN, has surpassed PercepNet as well as several competitive models and achieves state-of-the-art performance in terms of speech quality and intelligibility. Ablation studies also demonstrate the effectiveness of different contributions.
Analyzing the Impact of COVID-19 on Economy from the Perspective of Users Reviews
Oct 05, 2021
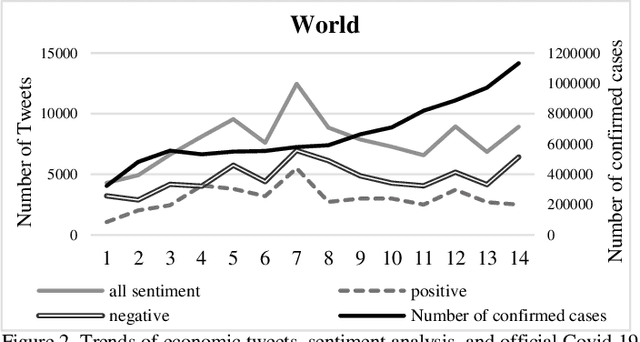

One of the most important incidents in the world in 2020 is the outbreak of the Coronavirus. Users on social networks publish a large number of comments about this event. These comments contain important hidden information of public opinion regarding this pandemic. In this research, a large number of Coronavirus-related tweets are considered and analyzed using natural language processing and information retrieval science. Initially, the location of the tweets is determined using a dictionary prepared through the Geo-Names geographic database, which contains detailed and complete information of places such as city names, streets, and postal codes. Then, using a large dictionary prepared from the terms of economics, related tweets are extracted and sentiments corresponded to tweets are analyzed with the help of the RoBERTa language-based model, which has high accuracy and good performance. Finally, the frequency chart of tweets related to the economy and their sentiment scores (positive and negative tweets) is plotted over time for the entire world and the top 10 economies. From the analysis of the charts, we learn that the reason for publishing economic tweets is not only the increase in the number of people infected with the Coronavirus but also imposed restrictions and lockdowns in countries. The consequences of these restrictions include the loss of millions of jobs and the economic downturn.