 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Performance Analysis of Multi-user NOMA Wireless-Powered mMTC Networks: A Stochastic Geometry Approach
Jan 13, 2022
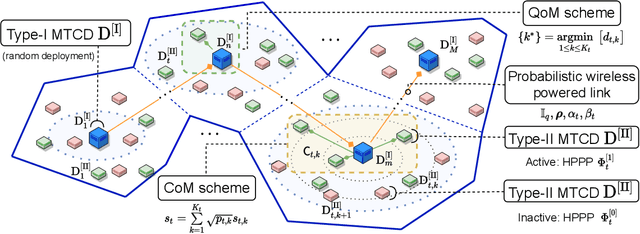
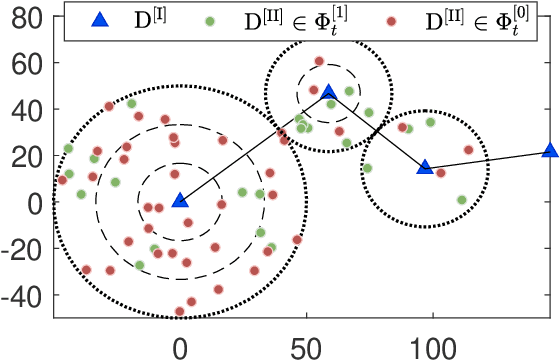
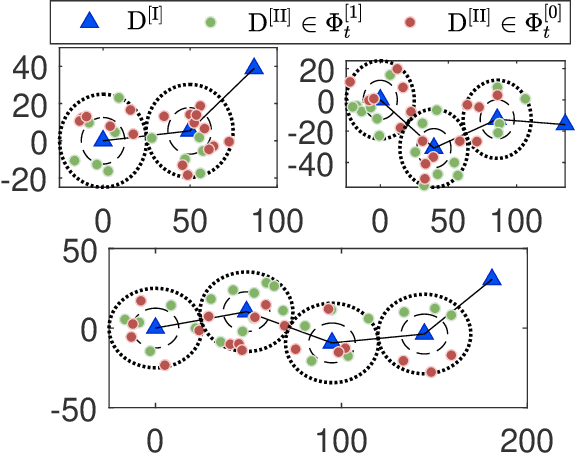
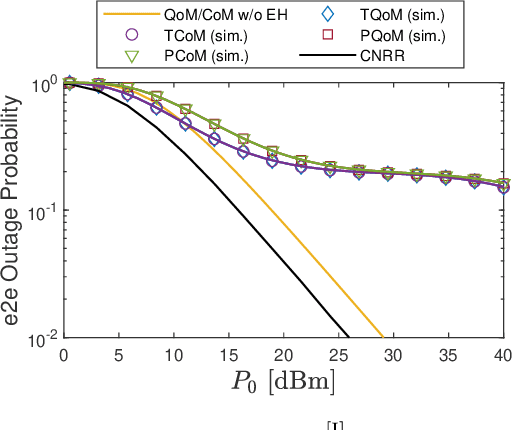
In this paper, we aim to improve the connectivity, scalability, and energy efficiency of machine-type communication (MTC) networks with different types of MTC devices (MTCDs), namely Type-I and Type-II MTCDs, which have different communication purposes. To this end, we propose two transmission schemes called connectivity-oriented machine-type communication (CoM) and quality-oriented machine-type communication (QoM), which take into account the stochastic geometry-based deployment and the random active/inactive status of MTCDs. Specifically, in the proposed schemes, the active Type-I MTCDs operate using a novel Bernoulli random process-based simultaneous wireless information and power transfer (SWIPT) architecture. Next, utilizing multi-user power-domain non-orthogonal multiple access (PD-NOMA), each active Type-I MTCD can simultaneously communicate with another Type-I MTCD and a scalable number of Type-II MTCDs. In the performance analysis of the proposed schemes, we prove that the true distribution of the received power at a Type-II MTCD in the QoM scheme can be approximated by the Singh-Maddala distribution. Exploiting this unique statistical finding, we derive approximate closed-form expressions for the outage probability (OP) and sum-throughput of massive MTC (mMTC) networks. Through numerical results, we show that the proposed schemes provide a considerable sum-throughput gain over conventional mMTC networks.
Privacy-Utility Trades in Crowdsourced Signal Map Obfuscation
Jan 13, 2022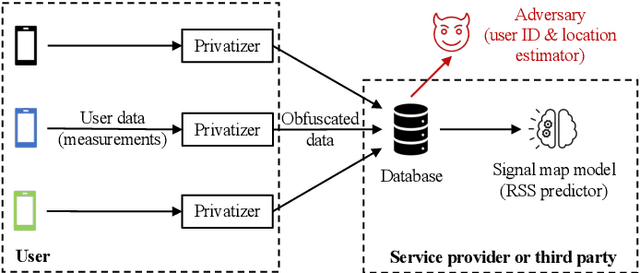

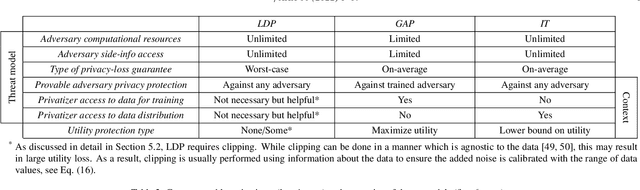
Cellular providers and data aggregating companies crowdsource celluar signal strength measurements from user devices to generate signal maps, which can be used to improve network performance. Recognizing that this data collection may be at odds with growing awareness of privacy concerns, we consider obfuscating such data before the data leaves the mobile device. The goal is to increase privacy such that it is difficult to recover sensitive features from the obfuscated data (e.g. user ids and user whereabouts), while still allowing network providers to use the data for improving network services (i.e. create accurate signal maps). To examine this privacy-utility tradeoff, we identify privacy and utility metrics and threat models suited to signal strength measurements. We then obfuscate the measurements using several preeminent techniques, spanning differential privacy, generative adversarial privacy, and information-theoretic privacy techniques, in order to benchmark a variety of promising obfuscation approaches and provide guidance to real-world engineers who are tasked to build signal maps that protect privacy without hurting utility. Our evaluation results, based on multiple, diverse, real-world signal map datasets, demonstrate the feasibility of concurrently achieving adequate privacy and utility, with obfuscation strategies which use the structure and intended use of datasets in their design, and target average-case, rather than worst-case, guarantees.
Kleister: A novel task for Information Extraction involving Long Documents with Complex Layout
Mar 04, 2020
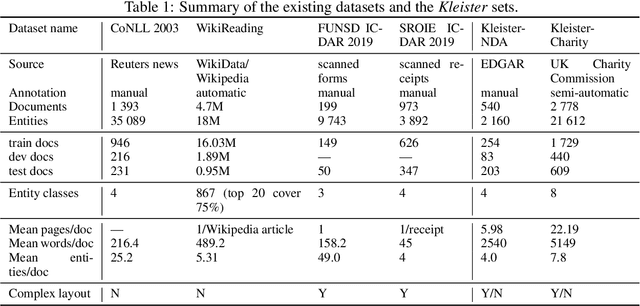

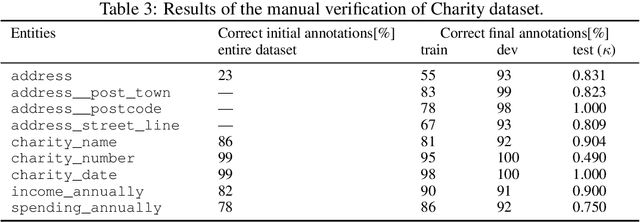
State-of-the-art solutions for Natural Language Processing (NLP) are able to capture a broad range of contexts, like the sentence level context or document level context for short documents. But these solutions are still struggling when it comes to real-world longer documents with information encoded in the spatial structure of the document, in elements like tables, forms, headers, openings or footers, or the complex layout of pages or multiple pages. To encourage progress on deeper and more complex information extraction, we present a new task (named Kleister) with two new datasets. Based on textual and structural layout features, an NLP system must find the most important information, about various types of entities, in formal long documents. These entities are not only classes from standard named entity recognition (NER) systems (e.g. location, date, or amount) but also the roles of the entities in the whole documents (e.g. company town address, report date, income amount).
Transformer-based Multi-task Learning for Disaster Tweet Categorisation
Oct 15, 2021
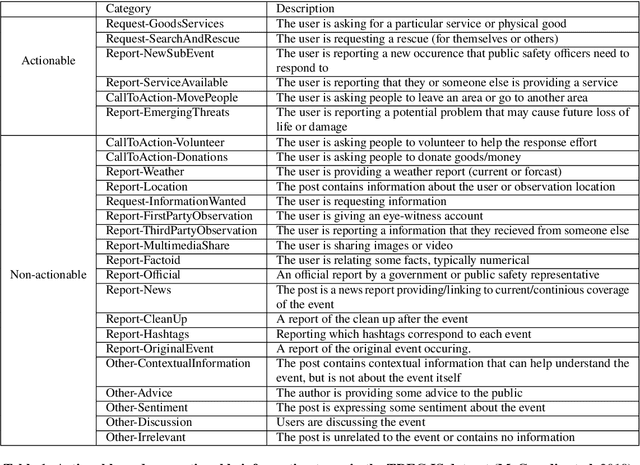
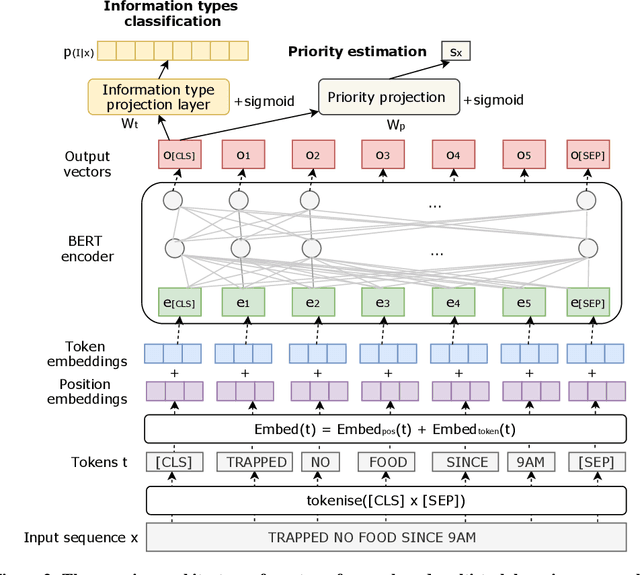
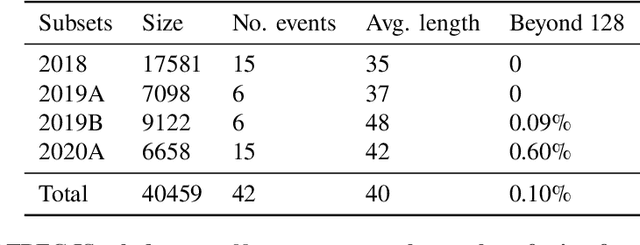
Social media has enabled people to circulate information in a timely fashion, thus motivating people to post messages seeking help during crisis situations. These messages can contribute to the situational awareness of emergency responders, who have a need for them to be categorised according to information types (i.e. the type of aid services the messages are requesting). We introduce a transformer-based multi-task learning (MTL) technique for classifying information types and estimating the priority of these messages. We evaluate the effectiveness of our approach with a variety of metrics by submitting runs to the TREC Incident Streams (IS) track: a research initiative specifically designed for disaster tweet classification and prioritisation. The results demonstrate that our approach achieves competitive performance in most metrics as compared to other participating runs. Subsequently, we find that an ensemble approach combining disparate transformer encoders within our approach helps to improve the overall effectiveness to a significant extent, achieving state-of-the-art performance in almost every metric. We make the code publicly available so that our work can be reproduced and used as a baseline for the community for future work in this domain.
Demographic Biases of Crowd Workers in Key Opinion Leaders Finding
Oct 19, 2021Key Opinion Leaders (KOLs) are people that have a strong influence and their opinions are listened to by people when making important decisions. Crowdsourcing provides an efficient and cost-effective means to gather data for the KOL finding task. However, data collected through crowdsourcing is affected by the inherent demographic biases of crowd workers. To avoid such demographic biases, we need to measure how biased each crowd worker is. In this paper, we propose a simple yet effective approach based on demographic information of candidate KOLs and their counterfactual value. We argue that it is effectiveness because of the extra information that we can consider together with labeled data to curate a less biased dataset.
Locally Invariant Explanations: Towards Stable and Unidirectional Explanations through Local Invariant Learning
Jan 28, 2022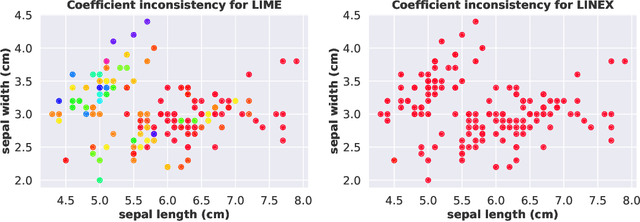



Locally interpretable model agnostic explanations (LIME) method is one of the most popular methods used to explain black-box models at a per example level. Although many variants have been proposed, few provide a simple way to produce high fidelity explanations that are also stable and intuitive. In this work, we provide a novel perspective by proposing a model agnostic local explanation method inspired by the invariant risk minimization (IRM) principle -- originally proposed for (global) out-of-distribution generalization -- to provide such high fidelity explanations that are also stable and unidirectional across nearby examples. Our method is based on a game theoretic formulation where we theoretically show that our approach has a strong tendency to eliminate features where the gradient of the black-box function abruptly changes sign in the locality of the example we want to explain, while in other cases it is more careful and will choose a more conservative (feature) attribution, a behavior which can be highly desirable for recourse. Empirically, we show on tabular, image and text data that the quality of our explanations with neighborhoods formed using random perturbations are much better than LIME and in some cases even comparable to other methods that use realistic neighbors sampled from the data manifold. This is desirable given that learning a manifold to either create realistic neighbors or to project explanations is typically expensive or may even be impossible. Moreover, our algorithm is simple and efficient to train, and can ascertain stable input features for local decisions of a black-box without access to side information such as a (partial) causal graph as has been seen in some recent works.
SLA$^2$P: Self-supervised Anomaly Detection with Adversarial Perturbation
Nov 25, 2021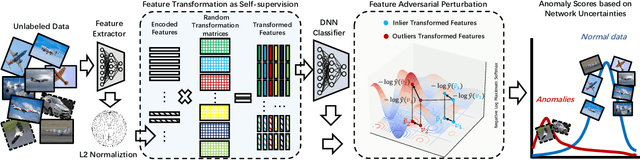
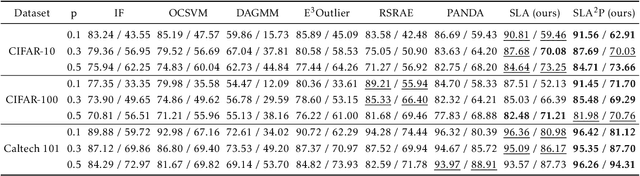
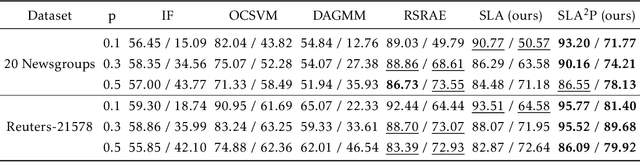
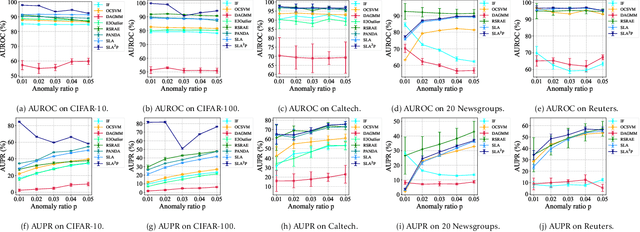
Anomaly detection is a fundamental yet challenging problem in machine learning due to the lack of label information. In this work, we propose a novel and powerful framework, dubbed as SLA$^2$P, for unsupervised anomaly detection. After extracting representative embeddings from raw data, we apply random projections to the features and regard features transformed by different projections as belonging to distinct pseudo classes. We then train a classifier network on these transformed features to perform self-supervised learning. Next we add adversarial perturbation to the transformed features to decrease their softmax scores of the predicted labels and design anomaly scores based on the predictive uncertainties of the classifier on these perturbed features. Our motivation is that because of the relatively small number and the decentralized modes of anomalies, 1) the pseudo label classifier's training concentrates more on learning the semantic information of normal data rather than anomalous data; 2) the transformed features of the normal data are more robust to the perturbations than those of the anomalies. Consequently, the perturbed transformed features of anomalies fail to be classified well and accordingly have lower anomaly scores than those of the normal samples. Extensive experiments on image, text and inherently tabular benchmark datasets back up our findings and indicate that SLA$^2$P achieves state-of-the-art results on unsupervised anomaly detection tasks consistently.
Relieving Long-tailed Instance Segmentation via Pairwise Class Balance
Jan 08, 2022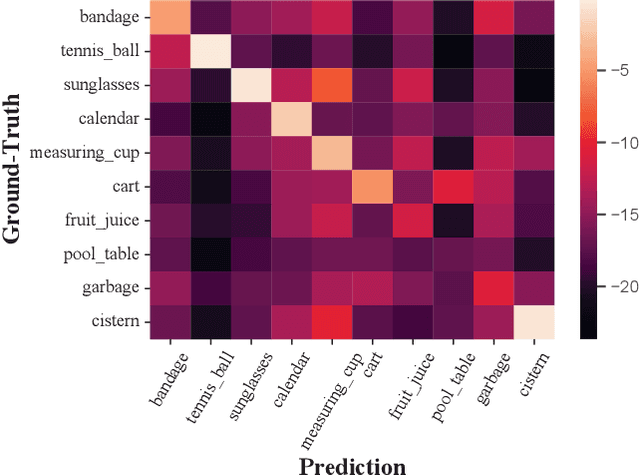
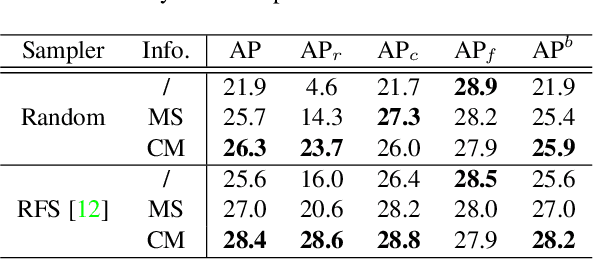
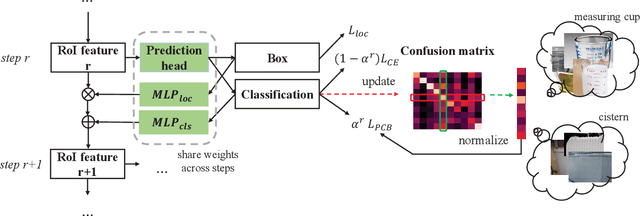
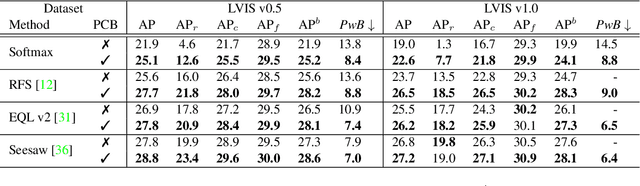
Long-tailed instance segmentation is a challenging task due to the extreme imbalance of training samples among classes. It causes severe biases of the head classes (with majority samples) against the tailed ones. This renders "how to appropriately define and alleviate the bias" one of the most important issues. Prior works mainly use label distribution or mean score information to indicate a coarse-grained bias. In this paper, we explore to excavate the confusion matrix, which carries the fine-grained misclassification details, to relieve the pairwise biases, generalizing the coarse one. To this end, we propose a novel Pairwise Class Balance (PCB) method, built upon a confusion matrix which is updated during training to accumulate the ongoing prediction preferences. PCB generates fightback soft labels for regularization during training. Besides, an iterative learning paradigm is developed to support a progressive and smooth regularization in such debiasing. PCB can be plugged and played to any existing method as a complement. Experimental results on LVIS demonstrate that our method achieves state-of-the-art performance without bells and whistles. Superior results across various architectures show the generalization ability.
Attend to Who You Are: Supervising Self-Attention for Keypoint Detection and Instance-Aware Association
Nov 25, 2021

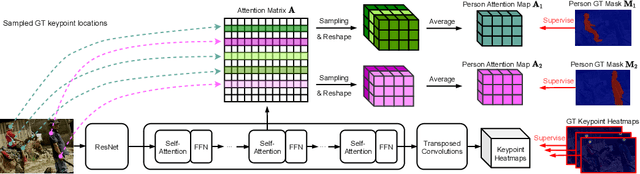
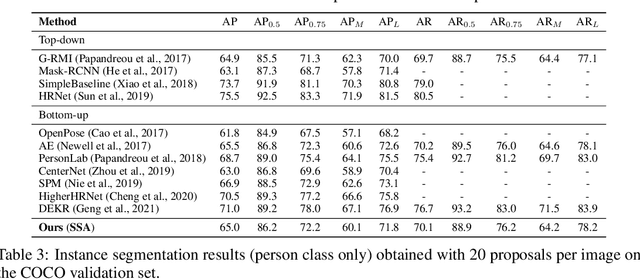
This paper presents a new method to solve keypoint detection and instance association by using Transformer. For bottom-up multi-person pose estimation models, they need to detect keypoints and learn associative information between keypoints. We argue that these problems can be entirely solved by Transformer. Specifically, the self-attention in Transformer measures dependencies between any pair of locations, which can provide association information for keypoints grouping. However, the naive attention patterns are still not subjectively controlled, so there is no guarantee that the keypoints will always attend to the instances to which they belong. To address it we propose a novel approach of supervising self-attention for multi-person keypoint detection and instance association. By using instance masks to supervise self-attention to be instance-aware, we can assign the detected keypoints to their corresponding instances based on the pairwise attention scores, without using pre-defined offset vector fields or embedding like CNN-based bottom-up models. An additional benefit of our method is that the instance segmentation results of any number of people can be directly obtained from the supervised attention matrix, thereby simplifying the pixel assignment pipeline. The experiments on the COCO multi-person keypoint detection challenge and person instance segmentation task demonstrate the effectiveness and simplicity of the proposed method and show a promising way to control self-attention behavior for specific purposes.
Characterization of causal ancestral graphs for time series with latent confounders
Dec 15, 2021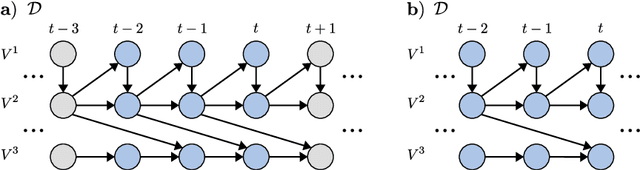
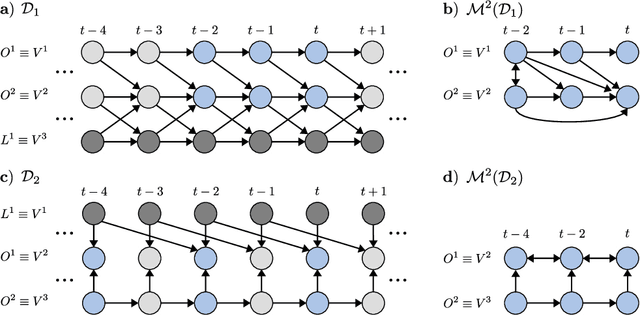


Generalizing directed maximal ancestral graphs, we introduce a class of graphical models for representing time lag specific causal relationships and independencies among finitely many regularly sampled and regularly subsampled time steps of multivariate time series with unobserved variables. We completely characterize these graphs and show that they entail constraints beyond those that have previously been considered in the literature. This allows for stronger causal inferences without having imposed additional assumptions. In generalization of directed partial ancestral graphs we further introduce a graphical representation of Markov equivalence classes of the novel type of graphs and show that these are more informative than what current state-of-the-art causal discovery algorithms learn. We also analyze the additional information gained by increasing the number of observed time steps.