 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Collaborative learning of images and geometrics for predicting isocitrate dehydrogenase status of glioma
Jan 14, 2022
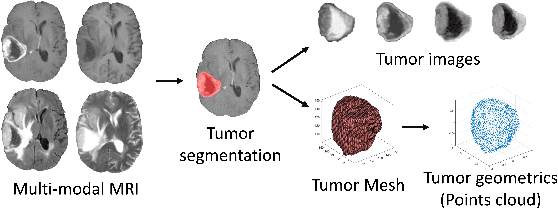
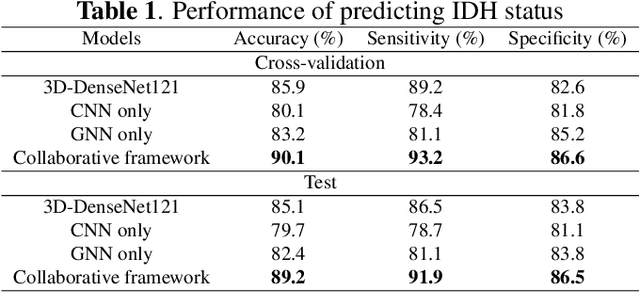
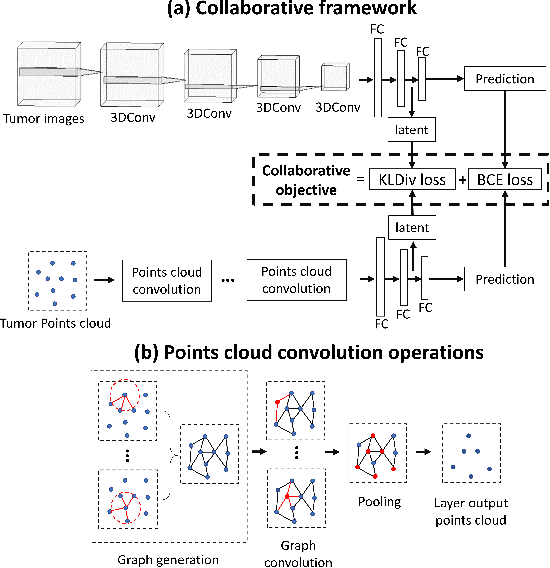

The isocitrate dehydrogenase (IDH) gene mutation status is an important biomarker for glioma patients. The gold standard of IDH mutation detection requires tumour tissue obtained via invasive approaches and is usually expensive. Recent advancement in radiogenomics provides a non-invasive approach for predicting IDH mutation based on MRI. Meanwhile, tumor geometrics encompass crucial information for tumour phenotyping. Here we propose a collaborative learning framework that learns both tumor images and tumor geometrics using convolutional neural networks (CNN) and graph neural networks (GNN), respectively. Our results show that the proposed model outperforms the baseline model of 3D-DenseNet121. Further, the collaborative learning model achieves better performance than either the CNN or the GNN alone. The model interpretation shows that the CNN and GNN could identify common and unique regions of interest for IDH mutation prediction. In conclusion, collaborating image and geometric learners provides a novel approach for predicting genotype and characterising glioma.
Cross-view Self-Supervised Learning on Heterogeneous Graph Neural Network via Bootstrapping
Jan 11, 2022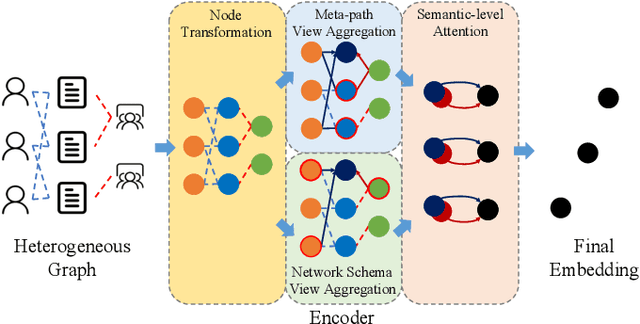
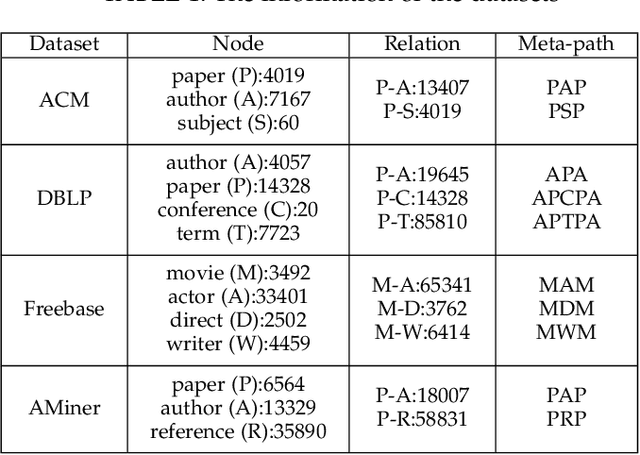
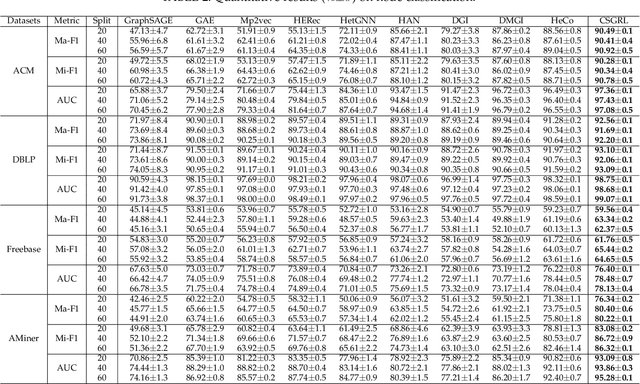
Heterogeneous graph neural networks can represent information of heterogeneous graphs with excellent ability. Recently, self-supervised learning manner is researched which learns the unique expression of a graph through a contrastive learning method. In the absence of labels, this learning methods show great potential. However, contrastive learning relies heavily on positive and negative pairs, and generating high-quality pairs from heterogeneous graphs is difficult. In this paper, in line with recent innovations in self-supervised learning called BYOL or bootstrapping, we introduce a that can generate good representations without generating large number of pairs. In addition, paying attention to the fact that heterogeneous graphs can be viewed from two perspectives, network schema and meta-path views, high-level expressions in the graphs are captured and expressed. The proposed model showed state-of-the-art performance than other methods in various real world datasets.
Reasoning for Complex Data through Ensemble-based Self-Supervised Learning
Feb 12, 2022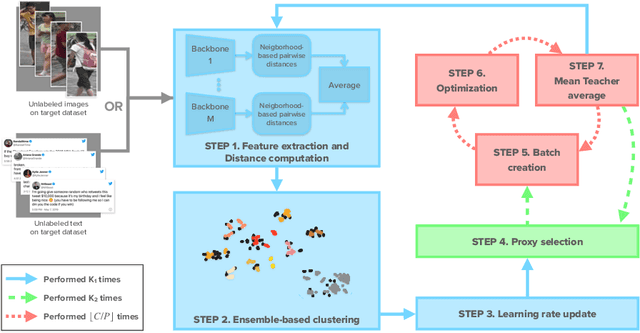
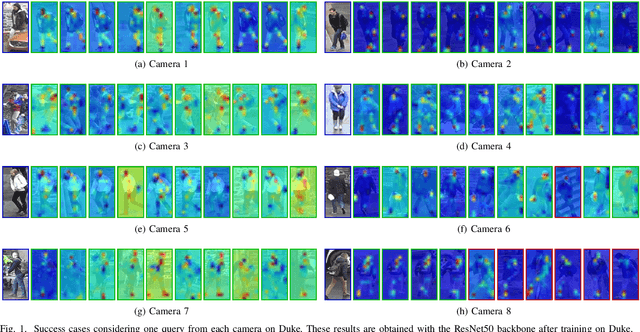
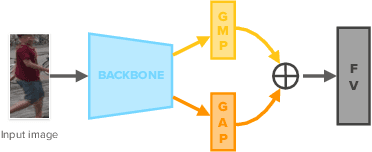
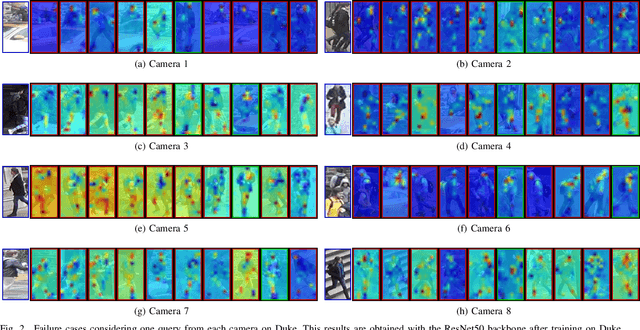
Self-supervised learning deals with problems that have little or no available labeled data. Recent work has shown impressive results when underlying classes have significant semantic differences. One important dataset in which this technique thrives is ImageNet, as intra-class distances are substantially lower than inter-class distances. However, this is not the case for several critical tasks, and general self-supervised learning methods fail to learn discriminative features when classes have closer semantics, thus requiring more robust strategies. We propose a strategy to tackle this problem, and to enable learning from unlabeled data even when samples from different classes are not prominently diverse. We approach the problem by leveraging a novel ensemble-based clustering strategy where clusters derived from different configurations are combined to generate a better grouping for the data samples in a fully-unsupervised way. This strategy allows clusters with different densities and higher variability to emerge, which in turn reduces intra-class discrepancies, without requiring the burden of finding an optimal configuration per dataset. We also consider different Convolutional Neural Networks to compute distances between samples. We refine these distances by performing context analysis and group them to capture complementary information. We consider two applications to validate our pipeline: Person Re-Identification and Text Authorship Verification. These are challenging applications considering that classes are semantically close to each other and that training and test sets have disjoint identities. Our method is robust across different modalities and outperforms state-of-the-art results with a fully-unsupervised solution without any labeling or human intervention.
Deep Video Prior for Video Consistency and Propagation
Jan 27, 2022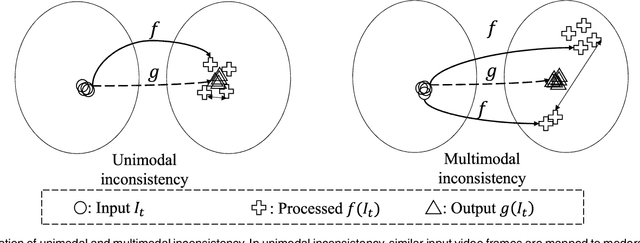
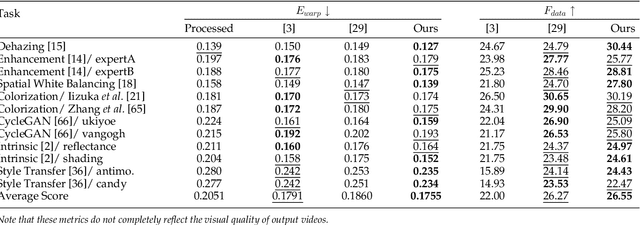
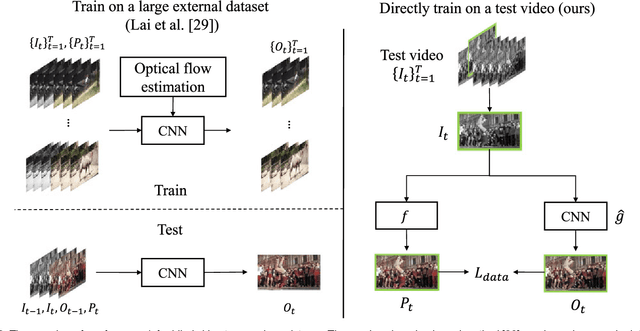
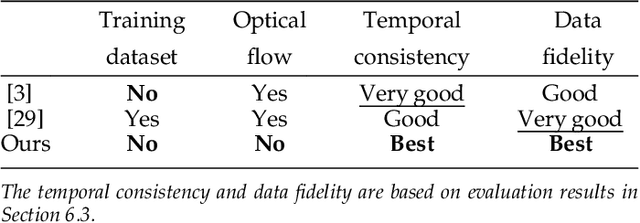
Applying an image processing algorithm independently to each video frame often leads to temporal inconsistency in the resulting video. To address this issue, we present a novel and general approach for blind video temporal consistency. Our method is only trained on a pair of original and processed videos directly instead of a large dataset. Unlike most previous methods that enforce temporal consistency with optical flow, we show that temporal consistency can be achieved by training a convolutional neural network on a video with Deep Video Prior (DVP). Moreover, a carefully designed iteratively reweighted training strategy is proposed to address the challenging multimodal inconsistency problem. We demonstrate the effectiveness of our approach on 7 computer vision tasks on videos. Extensive quantitative and perceptual experiments show that our approach obtains superior performance than state-of-the-art methods on blind video temporal consistency. We further extend DVP to video propagation and demonstrate its effectiveness in propagating three different types of information (color, artistic style, and object segmentation). A progressive propagation strategy with pseudo labels is also proposed to enhance DVP's performance on video propagation. Our source codes are publicly available at https://github.com/ChenyangLEI/deep-video-prior.
A Unified Review of Deep Learning for Automated Medical Coding
Jan 08, 2022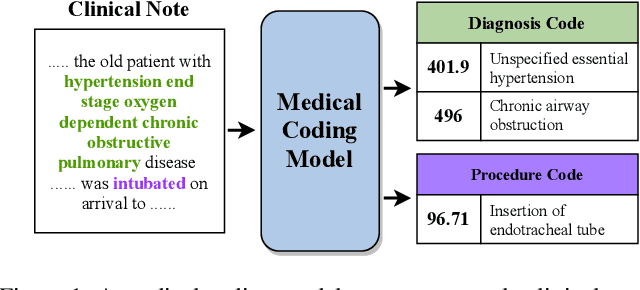
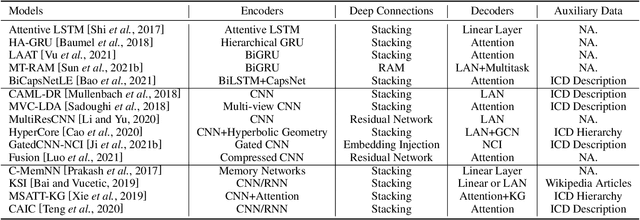
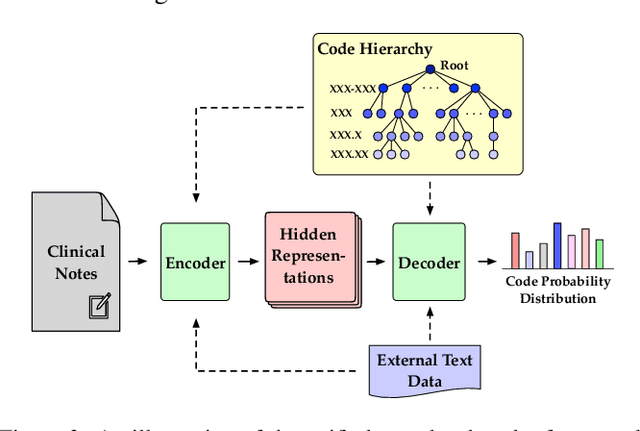
Automated medical coding, an essential task for healthcare operation and delivery, makes unstructured data manageable by predicting medical codes from clinical documents. Recent advances in deep learning models in natural language processing have been widely applied to this task. However, it lacks a unified view of the design of neural network architectures for medical coding. This review proposes a unified framework to provide a general understanding of the building blocks of medical coding models and summarizes recent advanced models under the proposed framework. Our unified framework decomposes medical coding into four main components, i.e., encoder modules for text feature extraction, mechanisms for building deep encoder architectures, decoder modules for transforming hidden representations into medical codes, and the usage of auxiliary information. Finally, we discuss key research challenges and future directions.
Energy Efficiency Optimization for Backscatter Enhanced NOMA Cooperative V2X Communications under Imperfect CSI
Feb 16, 2022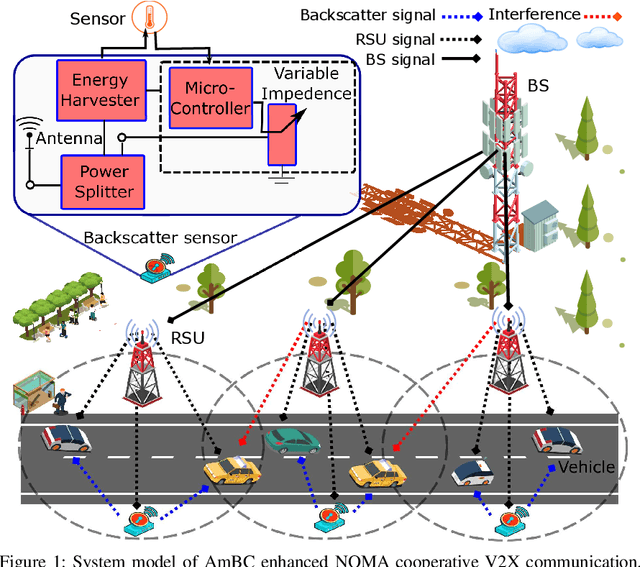
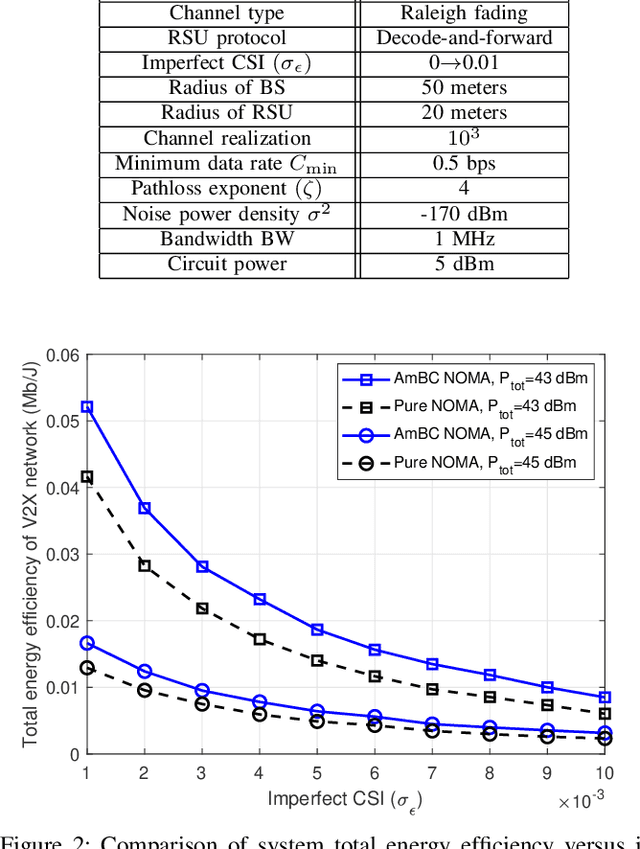
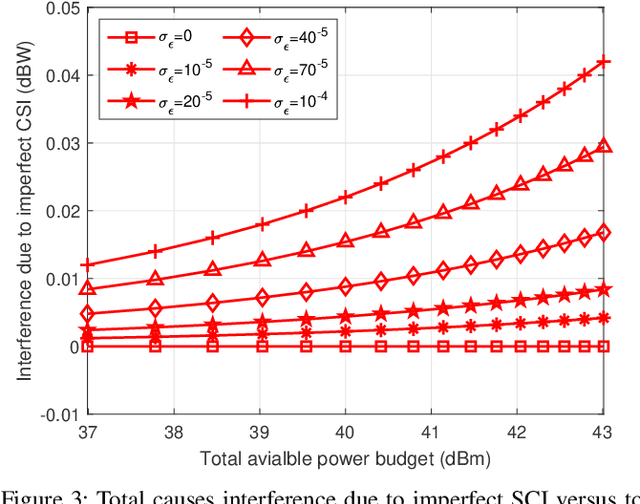
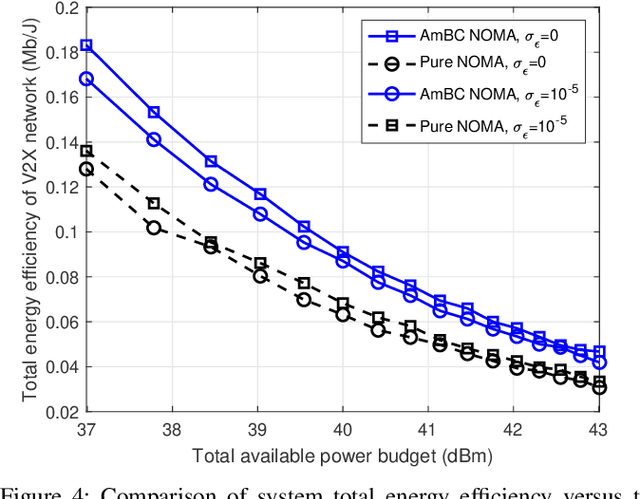
Automotive-Industry 5.0 will use beyond fifth-generation (B5G) technologies to provide robust, computationally intelligent, and energy-efficient data sharing among various onboard sensors, vehicles, and other devices. Recently, ambient backscatter communications (AmBC) have gained significant interest in the research community for providing battery-free communications. AmBC can modulate useful data and reflect it towards near devices using the energy and frequency of existing RF signals. However, obtaining channel state information (CSI) for AmBC systems would be very challenging due to no pilot sequences and limited power. As one of the latest members of multiple access technology, non-orthogonal multiple access (NOMA) has emerged as a promising solution for connecting large-scale devices over the same spectral resources in B5G wireless networks. Under imperfect CSI, this paper provides a new optimization framework for energy-efficient transmission in AmBC enhanced NOMA cooperative vehicle-to-everything (V2X) networks. We simultaneously minimize the total transmit power of the V2X network by optimizing the power allocation at BS and reflection coefficient at backscatter sensors while guaranteeing the individual quality of services. The problem of total power minimization is formulated as non-convex optimization and coupled on multiple variables, making it complex and challenging. Therefore, we first decouple the original problem into two sub-problems and convert the nonlinear rate constraints into linear constraints. Then, we adopt the iterative sub-gradient method to obtain an efficient solution. For comparison, we also present a conventional NOMA cooperative V2X network without AmBC. Simulation results show the benefits of our proposed AmBC enhanced NOMA cooperative V2X network in terms of total achievable energy efficiency.
Learning-based multiplexed transmission of scattered twisted light through a kilometer-scale standard multimode fiber
Jan 17, 2022Multiplexing multiple orbital angular momentum (OAM) modes of light has the potential to increase data capacity in optical communication. However, the distribution of such modes over long distances remains challenging. Free-space transmission is strongly influenced by atmospheric turbulence and light scattering, while the wave distortion induced by the mode dispersion in fibers disables OAM demultiplexing in fiber-optic communications. Here, a deep-learning-based approach is developed to recover the data from scattered OAM channels without measuring any phase information. Over a 1-km-long standard multimode fiber, the method is able to identify different OAM modes with an accuracy of more than 99.9% in parallel demultiplexing of 24 scattered OAM channels. To demonstrate the transmission quality, color images are encoded in multiplexed twisted light and our method achieves decoding the transmitted data with an error rate of 0.13%. Our work shows the artificial intelligence algorithm could benefit the use of OAM multiplexing in commercial fiber networks and high-performance optical communication in turbulent environments.
Deep Reference Priors: What is the best way to pretrain a model?
Feb 01, 2022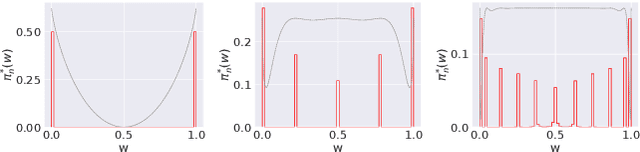
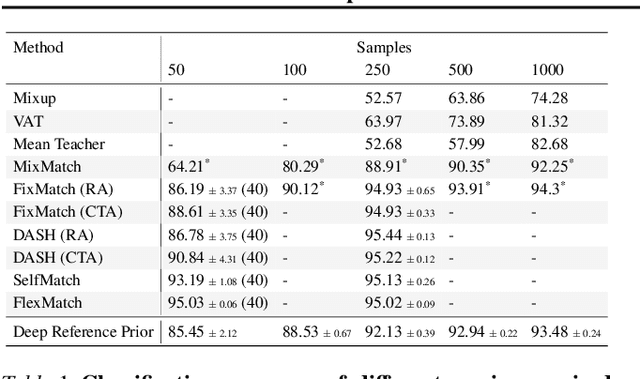
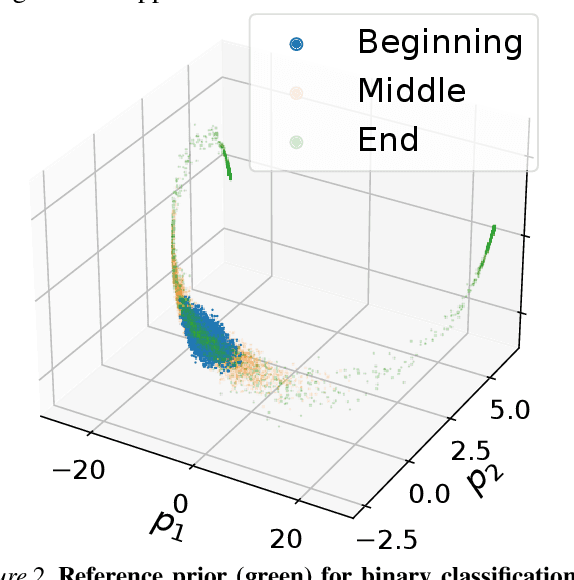
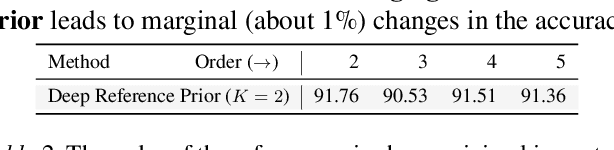
What is the best way to exploit extra data -- be it unlabeled data from the same task, or labeled data from a related task -- to learn a given task? This paper formalizes the question using the theory of reference priors. Reference priors are objective, uninformative Bayesian priors that maximize the mutual information between the task and the weights of the model. Such priors enable the task to maximally affect the Bayesian posterior, e.g., reference priors depend upon the number of samples available for learning the task and for very small sample sizes, the prior puts more probability mass on low-complexity models in the hypothesis space. This paper presents the first demonstration of reference priors for medium-scale deep networks and image-based data. We develop generalizations of reference priors and demonstrate applications to two problems. First, by using unlabeled data to compute the reference prior, we develop new Bayesian semi-supervised learning methods that remain effective even with very few samples per class. Second, by using labeled data from the source task to compute the reference prior, we develop a new pretraining method for transfer learning that allows data from the target task to maximally affect the Bayesian posterior. Empirical validation of these methods is conducted on image classification datasets.
HampDTI: a heterogeneous graph automatic meta-path learning method for drug-target interaction prediction
Dec 16, 2021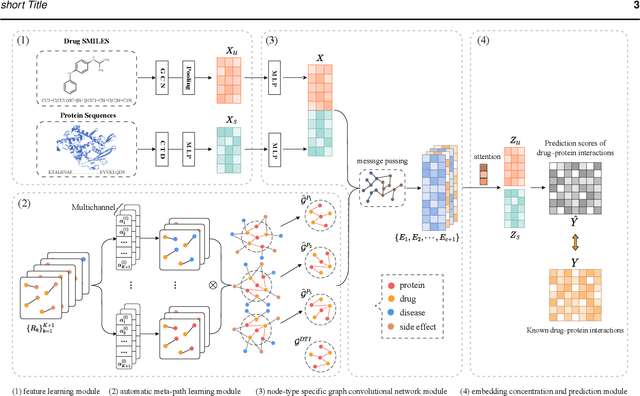

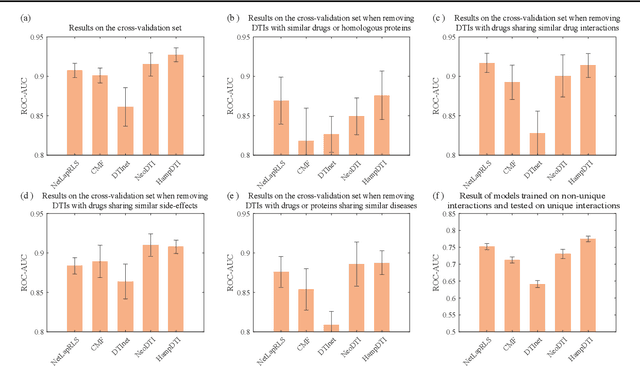
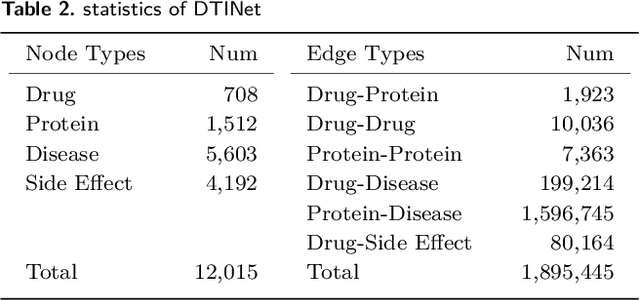
Motivation: Identifying drug-target interactions (DTIs) is a key step in drug repositioning. In recent years, the accumulation of a large number of genomics and pharmacology data has formed mass drug and target related heterogeneous networks (HNs), which provides new opportunities of developing HN-based computational models to accurately predict DTIs. The HN implies lots of useful information about DTIs but also contains irrelevant data, and how to make the best of heterogeneous networks remains a challenge. Results: In this paper, we propose a heterogeneous graph automatic meta-path learning based DTI prediction method (HampDTI). HampDTI automatically learns the important meta-paths between drugs and targets from the HN, and generates meta-path graphs. For each meta-path graph, the features learned from drug molecule graphs and target protein sequences serve as the node attributes, and then a node-type specific graph convolutional network (NSGCN) which efficiently considers node type information (drugs or targets) is designed to learn embeddings of drugs and targets. Finally, the embeddings from multiple meta-path graphs are combined to predict novel DTIs. The experiments on benchmark datasets show that our proposed HampDTI achieves superior performance compared with state-of-the-art DTI prediction methods. More importantly, HampDTI identifies the important meta-paths for DTI prediction, which could explain how drugs connect with targets in HNs.
Compressed Sensing with Probability-based Prior Information
Oct 27, 2019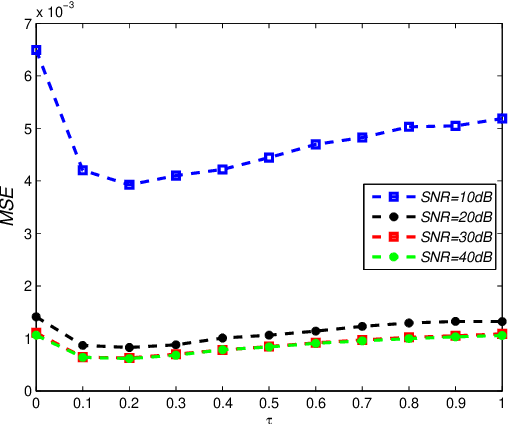
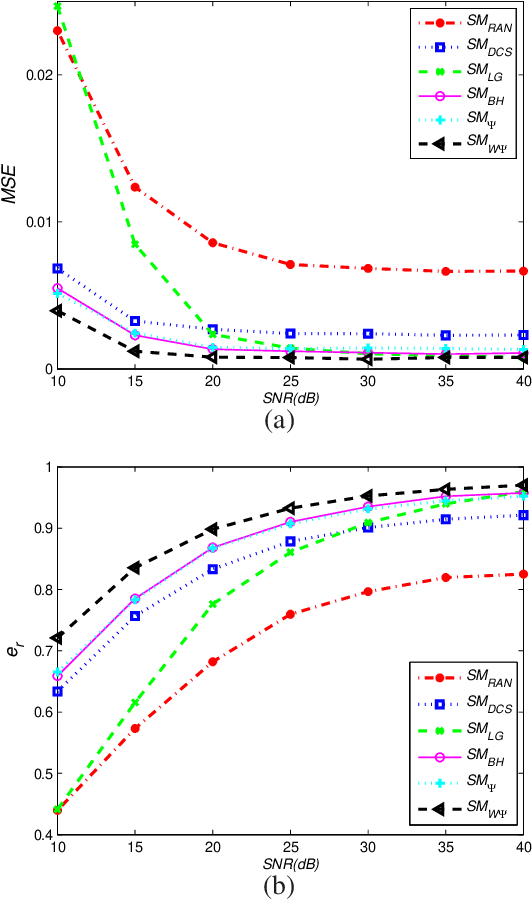
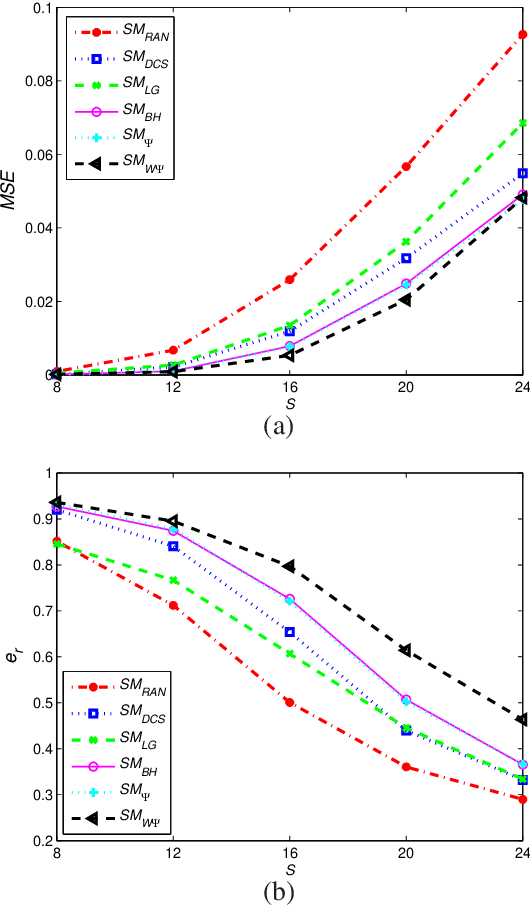
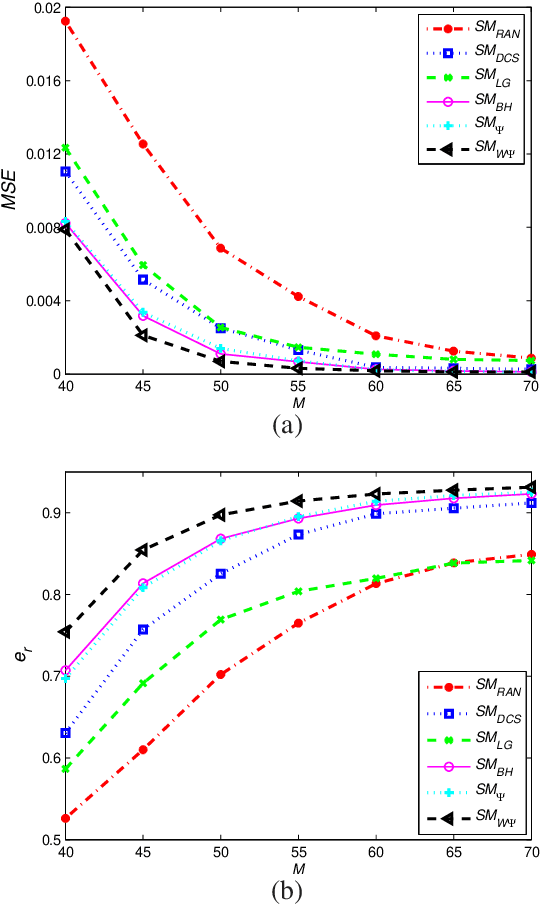
This paper deals with the design of a sensing matrix along with a sparse recovery algorithm by utilizing the probability-based prior information for compressed sensing system. With the knowledge of the probability for each atom of the dictionary being used, a diagonal weighted matrix is obtained and then the sensing matrix is designed by minimizing a weighted function such that the Gram of the equivalent dictionary is as close to the Gram of dictionary as possible. An analytical solution for the corresponding sensing matrix is derived which leads to low computational complexity. We also exploit this prior information through the sparse recovery stage and propose a probability-driven orthogonal matching pursuit algorithm that improves the accuracy of the recovery. Simulations for synthetic data and application scenarios of surveillance video are carried out to compare the performance of the proposed methods with some existing algorithms. The results reveal that the proposed CS system outperforms existing CS systems.