 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mobile APP User Attribute Prediction by Heterogeneous Information Network Modeling
Oct 06, 2019
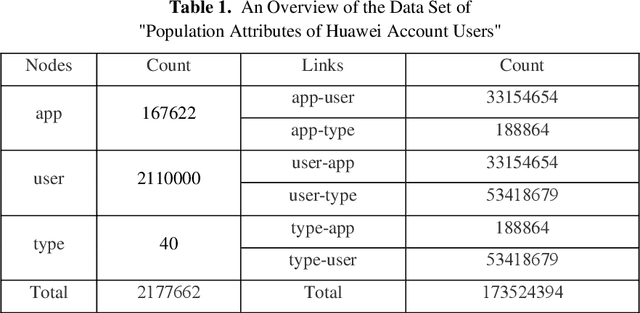
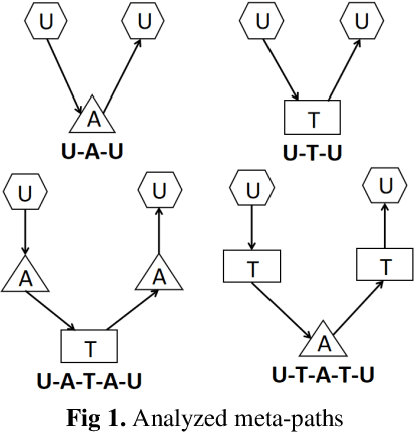
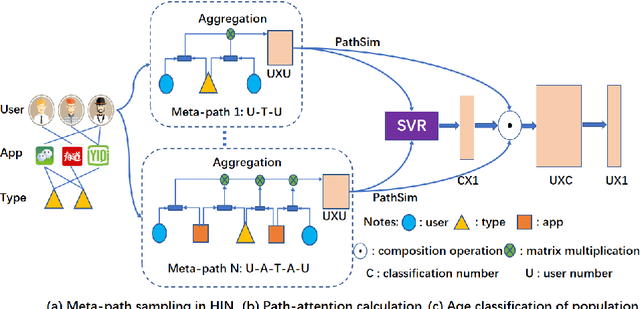
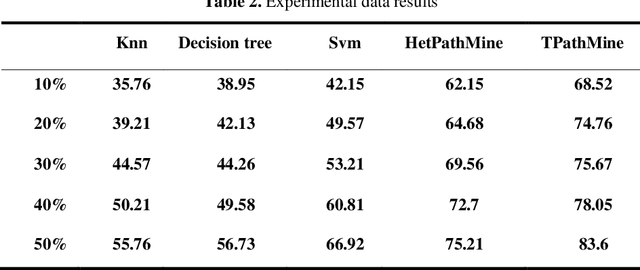
User-based attribute information, such as age and gender, is usually considered as user privacy information. It is difficult for enterprises to obtain user-based privacy attribute information. However, user-based privacy attribute information has a wide range of applications in personalized services, user behavior analysis and other aspects. this paper advances the HetPathMine model and puts forward TPathMine model. With applying the number of clicks of attributes under each node to express the user's emotional preference information, optimizations of the solution of meta-path weight are also presented. Based on meta-path in heterogeneous information networks, the new model integrates all relationships among objects into isomorphic relationships of classified objects. Matrix is used to realize the knowledge dissemination of category knowledge among isomorphic objects. The experimental results show that: (1) the prediction of user attributes based on heterogeneous information networks can achieve higher accuracy than traditional machine learning classification methods; (2) TPathMine model based on the number of clicks is more accurate in classifying users of different age groups, and the weight of each meta-path is consistent with human intuition or the real world situation.
A Mini-Block Natural Gradient Method for Deep Neural Networks
Feb 08, 2022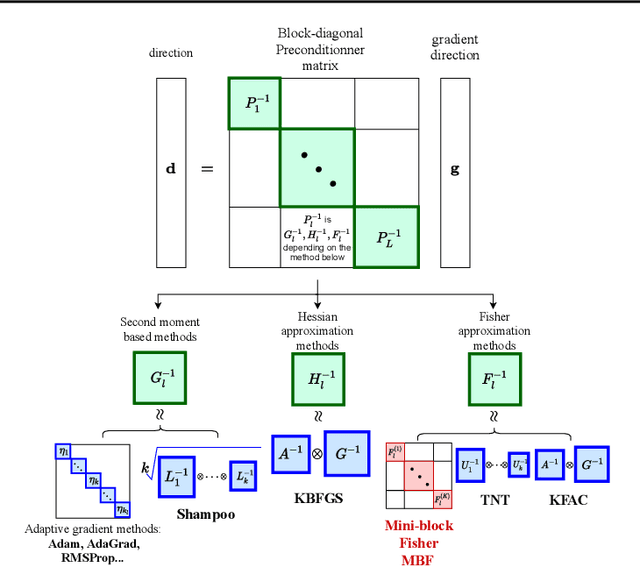
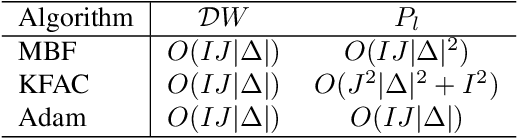
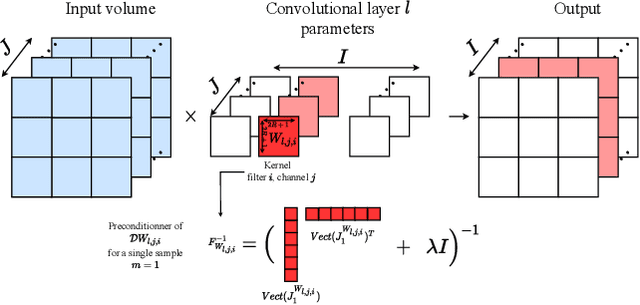

The training of deep neural networks (DNNs) is currently predominantly done using first-order methods. Some of these methods (e.g., Adam, AdaGrad, and RMSprop, and their variants) incorporate a small amount of curvature information by using a diagonal matrix to precondition the stochastic gradient. Recently, effective second-order methods, such as KFAC, K-BFGS, Shampoo, and TNT, have been developed for training DNNs, by preconditioning the stochastic gradient by layer-wise block-diagonal matrices. Here we propose and analyze the convergence of an approximate natural gradient method, mini-block Fisher (MBF), that lies in between these two classes of methods. Specifically, our method uses a block-diagonal approximation to the Fisher matrix, where for each layer in the DNN, whether it is convolutional or feed-forward and fully connected, the associated diagonal block is also block-diagonal and is composed of a large number of mini-blocks of modest size. Our novel approach utilizes the parallelism of GPUs to efficiently perform computations on the large number of matrices in each layer. Consequently, MBF's per-iteration computational cost is only slightly higher than it is for first-order methods. Finally, the performance of our proposed method is compared to that of several baseline methods, on both Auto-encoder and CNN problems, to validate its effectiveness both in terms of time efficiency and generalization power.
Statistical and Spatio-temporal Hand Gesture Features for Sign Language Recognition using the Leap Motion Sensor
Feb 22, 2022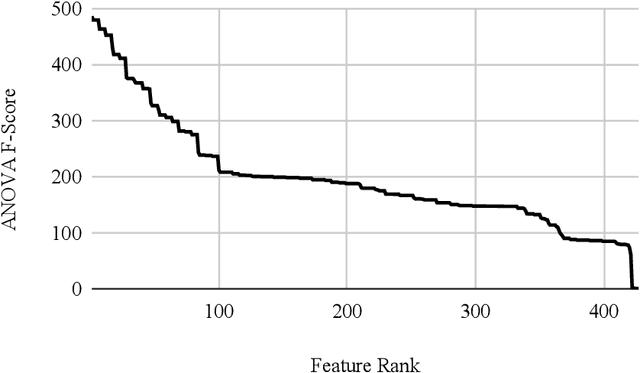
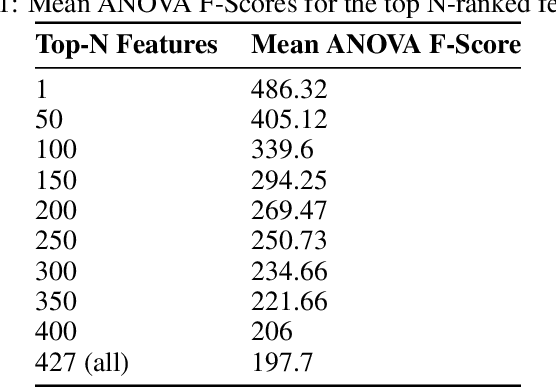
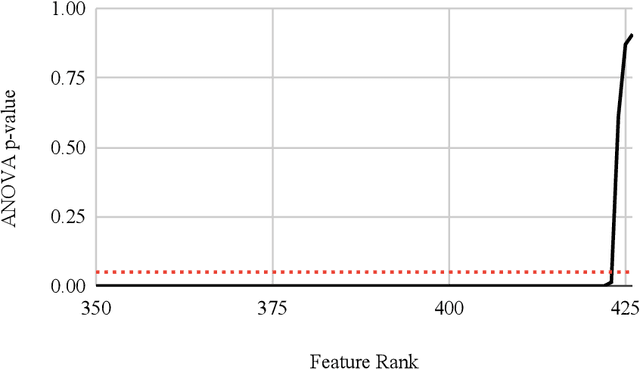
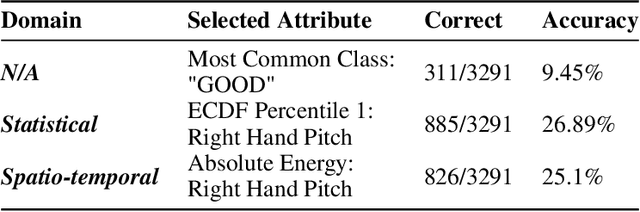
In modern society, people should not be identified based on their disability, rather, it is environments that can disable people with impairments. Improvements to automatic Sign Language Recognition (SLR) will lead to more enabling environments via digital technology. Many state-of-the-art approaches to SLR focus on the classification of static hand gestures, but communication is a temporal activity, which is reflected by many of the dynamic gestures present. Given this, temporal information during the delivery of a gesture is not often considered within SLR. The experiments in this work consider the problem of SL gesture recognition regarding how dynamic gestures change during their delivery, and this study aims to explore how single types of features as well as mixed features affect the classification ability of a machine learning model. 18 common gestures recorded via a Leap Motion Controller sensor provide a complex classification problem. Two sets of features are extracted from a 0.6 second time window, statistical descriptors and spatio-temporal attributes. Features from each set are compared by their ANOVA F-Scores and p-values, arranged into bins grown by 10 features per step to a limit of the 250 highest-ranked features. Results show that the best statistical model selected 240 features and scored 85.96% accuracy, the best spatio-temporal model selected 230 features and scored 80.98%, and the best mixed-feature model selected 240 features from each set leading to a classification accuracy of 86.75%. When all three sets of results are compared (146 individual machine learning models), the overall distribution shows that the minimum results are increased when inputs are any number of mixed features compared to any number of either of the two single sets of features.
Uformer: A Unet based dilated complex & real dual-path conformer network for simultaneous speech enhancement and dereverberation
Nov 11, 2021
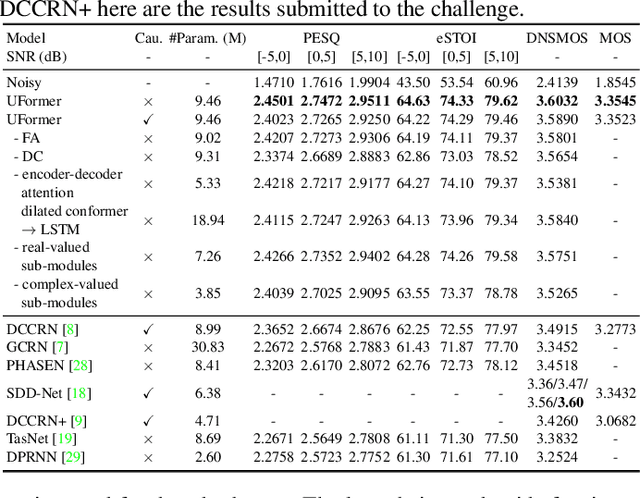
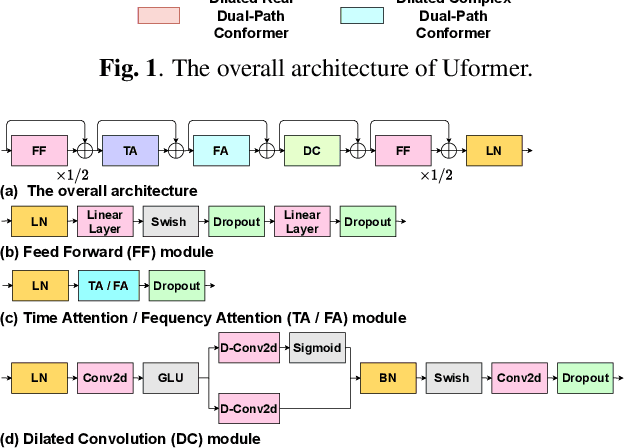
Complex spectrum and magnitude are considered as two major features of speech enhancement and dereverberation. Traditional approaches always treat these two features separately, ignoring their underlying relationship. In this paper, we proposem Uformer, a Unet based dilated complex & real dual-path conformer network in both complex and magnitude domain for simultaneous speech enhancement and dereverberation. We exploit time attention (TA) and dilated convolution (DC) to leverage local and global contextual information and frequency attention (FA) to model dimensional information. These three sub-modules contained in the proposed dilated complex & real dual-path conformer module effectively improve the speech enhancement and dereverberation performance. Furthermore, hybrid encoder and decoder are adopted to simultaneously model the complex spectrum and magnitude and promote the information interaction between two domains. Encoder decoder attention is also applied to enhance the interaction between encoder and decoder. Our experimental results outperform all SOTA time and complex domain models objectively and subjectively. Specifically, Uformer reaches 3.6032 DNSMOS on the blind test set of Interspeech 2021 DNS Challenge, which outperforms all top-performed models. We also carry out ablation experiments to tease apart all proposed sub-modules that are most important.
Contextualize differential privacy in image database: a lightweight image differential privacy approach based on principle component analysis inverse
Feb 19, 2022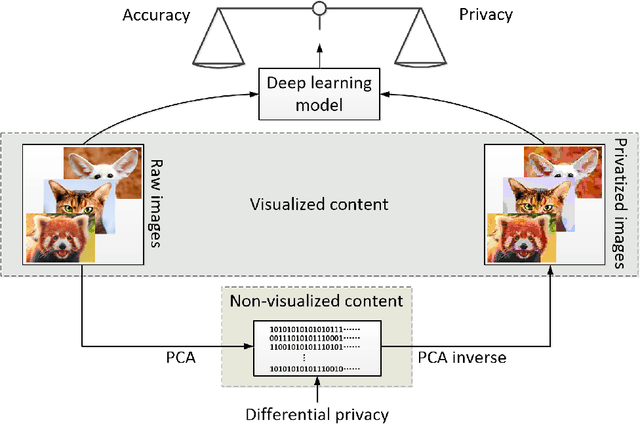


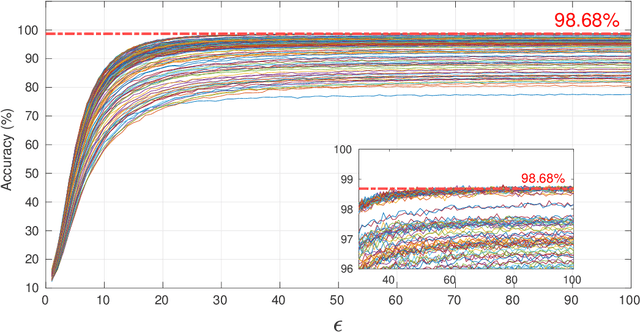
Differential privacy (DP) has been the de-facto standard to preserve privacy-sensitive information in database. Nevertheless, there lacks a clear and convincing contextualization of DP in image database, where individual images' indistinguishable contribution to a certain analysis can be achieved and observed when DP is exerted. As a result, the privacy-accuracy trade-off due to integrating DP is insufficiently demonstrated in the context of differentially-private image database. This work aims at contextualizing DP in image database by an explicit and intuitive demonstration of integrating conceptional differential privacy with images. To this end, we design a lightweight approach dedicating to privatizing image database as a whole and preserving the statistical semantics of the image database to an adjustable level, while making individual images' contribution to such statistics indistinguishable. The designed approach leverages principle component analysis (PCA) to reduce the raw image with large amount of attributes to a lower dimensional space whereby DP is performed, so as to decrease the DP load of calculating sensitivity attribute-by-attribute. The DP-exerted image data, which is not visible in its privatized format, is visualized through PCA inverse such that both a human and machine inspector can evaluate the privatization and quantify the privacy-accuracy trade-off in an analysis on the privatized image database. Using the devised approach, we demonstrate the contextualization of DP in images by two use cases based on deep learning models, where we show the indistinguishability of individual images induced by DP and the privatized images' retention of statistical semantics in deep learning tasks, which is elaborated by quantitative analyses on the privacy-accuracy trade-off under different privatization settings.
Incorporating Effective Global Information via Adaptive Gate Attention for Text Classification
Feb 22, 2020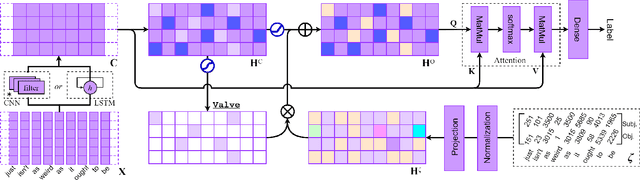
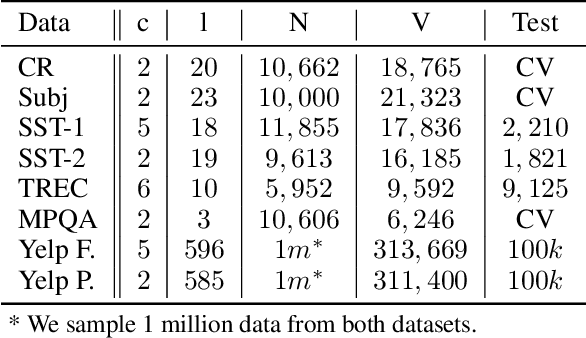
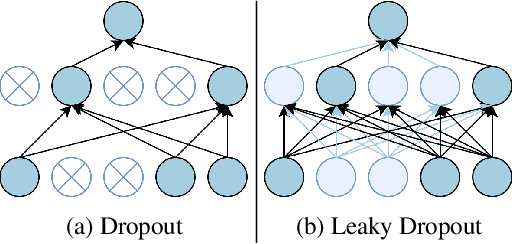
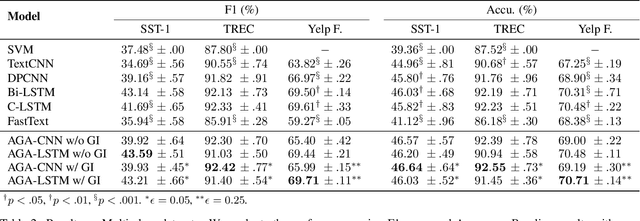
The dominant text classification studies focus on training classifiers using textual instances only or introducing external knowledge (e.g., hand-craft features and domain expert knowledge). In contrast, some corpus-level statistical features, like word frequency and distribution, are not well exploited. Our work shows that such simple statistical information can enhance classification performance both efficiently and significantly compared with several baseline models. In this paper, we propose a classifier with gate mechanism named Adaptive Gate Attention model with Global Information (AGA+GI), in which the adaptive gate mechanism incorporates global statistical features into latent semantic features and the attention layer captures dependency relationship within the sentence. To alleviate the overfitting issue, we propose a novel Leaky Dropout mechanism to improve generalization ability and performance stability. Our experiments show that the proposed method can achieve better accuracy than CNN-based and RNN-based approaches without global information on several benchmarks.
Video-based Facial Micro-Expression Analysis: A Survey of Datasets, Features and Algorithms
Feb 16, 2022
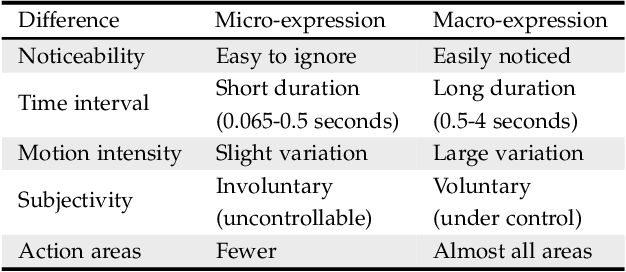
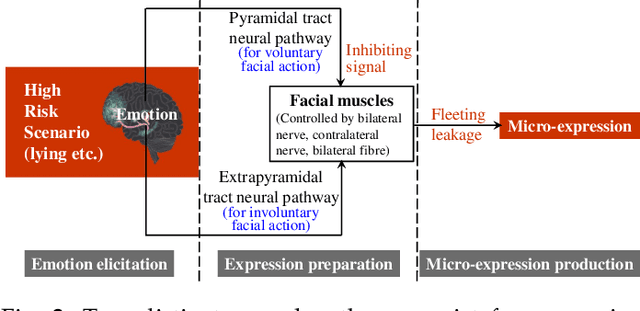
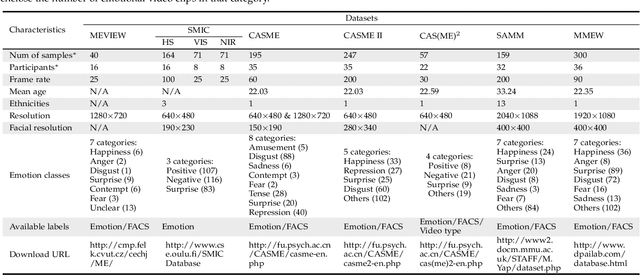
Unlike the conventional facial expressions, micro-expressions are involuntary and transient facial expressions capable of revealing the genuine emotions that people attempt to hide. Therefore, they can provide important information in a broad range of applications such as lie detection, criminal detection, etc. Since micro-expressions are transient and of low intensity, however, their detection and recognition is difficult and relies heavily on expert experiences. Due to its intrinsic particularity and complexity, video-based micro-expression analysis is attractive but challenging, and has recently become an active area of research. Although there have been numerous developments in this area, thus far there has been no comprehensive survey that provides researchers with a systematic overview of these developments with a unified evaluation. Accordingly, in this survey paper, we first highlight the key differences between macro- and micro-expressions, then use these differences to guide our research survey of video-based micro-expression analysis in a cascaded structure, encompassing the neuropsychological basis, datasets, features, spotting algorithms, recognition algorithms, applications and evaluation of state-of-the-art approaches. For each aspect, the basic techniques, advanced developments and major challenges are addressed and discussed. Furthermore, after considering the limitations of existing micro-expression datasets, we present and release a new dataset - called micro-and-macro expression warehouse (MMEW) - containing more video samples and more labeled emotion types. We then perform a unified comparison of representative methods on CAS(ME)2 for spotting, and on MMEW and SAMM for recognition, respectively. Finally, some potential future research directions are explored and outlined.
Phishing Attacks Detection -- A Machine Learning-Based Approach
Jan 26, 2022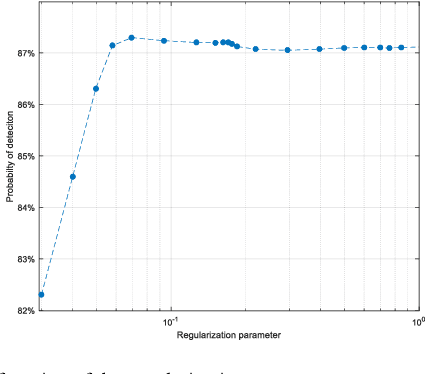
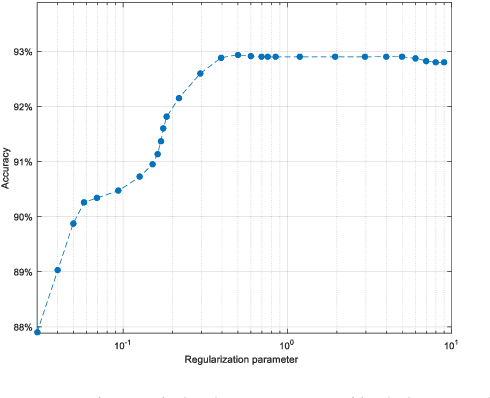

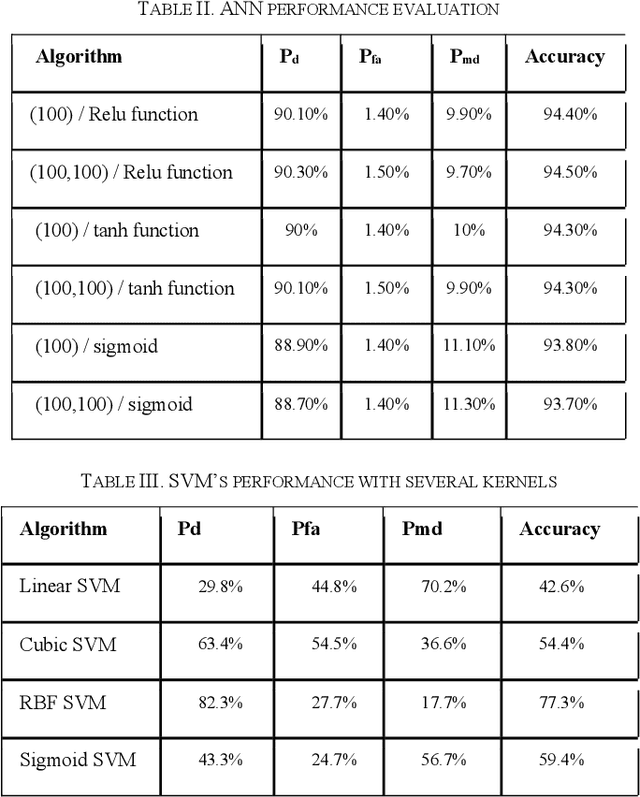
Phishing attacks are one of the most common social engineering attacks targeting users emails to fraudulently steal confidential and sensitive information. They can be used as a part of more massive attacks launched to gain a foothold in corporate or government networks. Over the last decade, a number of anti-phishing techniques have been proposed to detect and mitigate these attacks. However, they are still inefficient and inaccurate. Thus, there is a great need for efficient and accurate detection techniques to cope with these attacks. In this paper, we proposed a phishing attack detection technique based on machine learning. We collected and analyzed more than 4000 phishing emails targeting the email service of the University of North Dakota. We modeled these attacks by selecting 10 relevant features and building a large dataset. This dataset was used to train, validate, and test the machine learning algorithms. For performance evaluation, four metrics have been used, namely probability of detection, probability of miss-detection, probability of false alarm, and accuracy. The experimental results show that better detection can be achieved using an artificial neural network.
Graph Neural Networks with Dynamic and Static Representations for Social Recommendation
Jan 26, 2022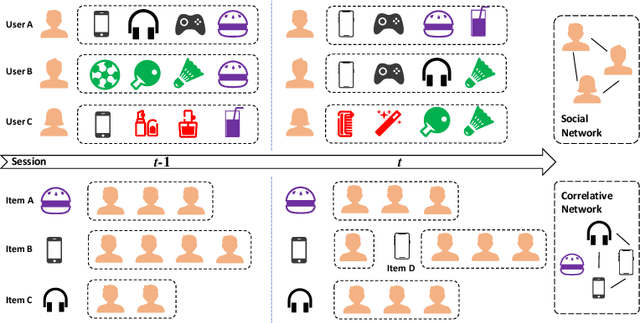
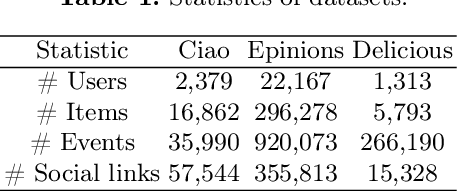
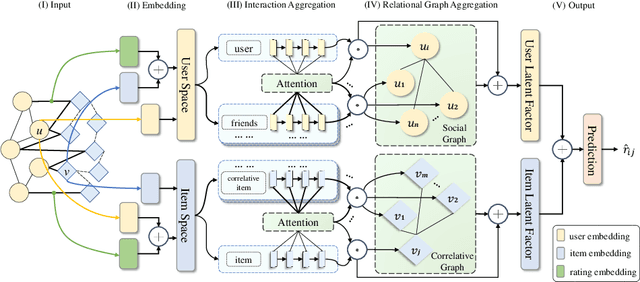
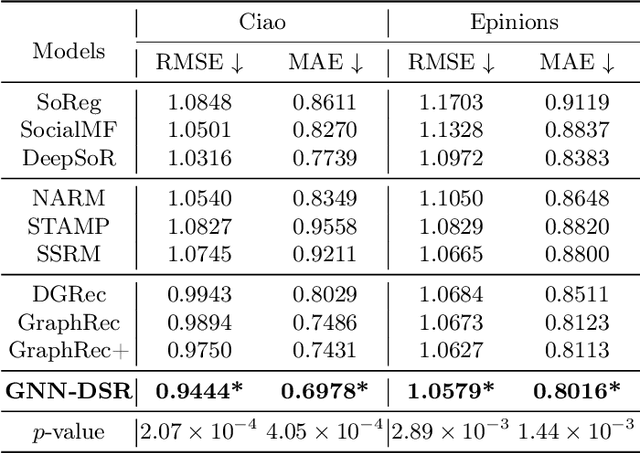
Recommender systems based on graph neural networks receive increasing research interest due to their excellent ability to learn a variety of side information including social networks. However, previous works usually focus on modeling users, not much attention is paid to items. Moreover, the possible changes in the attraction of items over time, which is like the dynamic interest of users are rarely considered, and neither do the correlations among items. To overcome these limitations, this paper proposes graph neural networks with dynamic and static representations for social recommendation (GNN-DSR), which considers both dynamic and static representations of users and items and incorporates their relational influence. GNN-DSR models the short-term dynamic and long-term static interactional representations of the user's interest and the item's attraction, respectively. Furthermore, the attention mechanism is used to aggregate the social influence of users on the target user and the correlative items' influence on a given item. The final latent factors of user and item are combined to make a prediction. Experiments on three real-world recommender system datasets validate the effectiveness of GNN-DSR.
Joint-bone Fusion Graph Convolutional Network for Semi-supervised Skeleton Action Recognition
Feb 08, 2022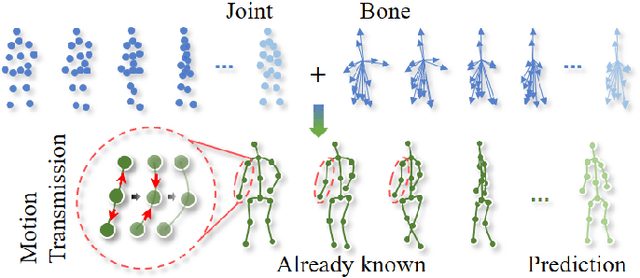
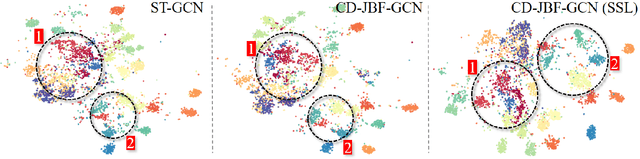
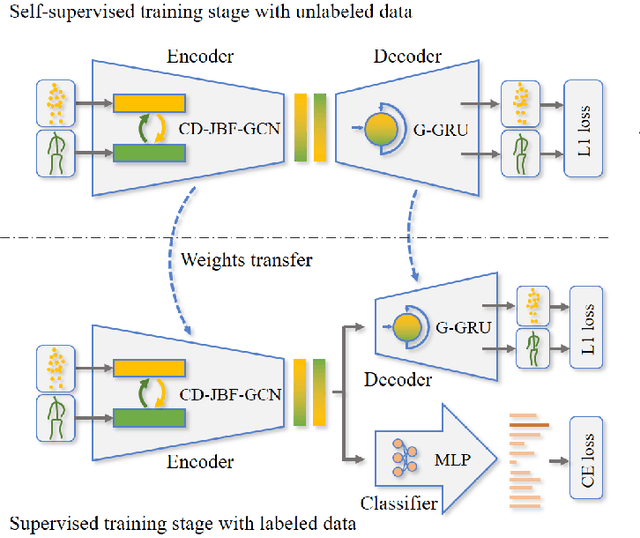
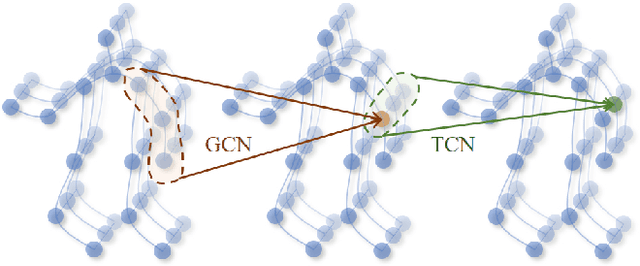
In recent years, graph convolutional networks (GCNs) play an increasingly critical role in skeleton-based human action recognition. However, most GCN-based methods still have two main limitations: 1) They only consider the motion information of the joints or process the joints and bones separately, which are unable to fully explore the latent functional correlation between joints and bones for action recognition. 2) Most of these works are performed in the supervised learning way, which heavily relies on massive labeled training data. To address these issues, we propose a semi-supervised skeleton-based action recognition method which has been rarely exploited before. We design a novel correlation-driven joint-bone fusion graph convolutional network (CD-JBF-GCN) as an encoder and use a pose prediction head as a decoder to achieve semi-supervised learning. Specifically, the CD-JBF-GC can explore the motion transmission between the joint stream and the bone stream, so that promoting both streams to learn more discriminative feature representations. The pose prediction based auto-encoder in the self-supervised training stage allows the network to learn motion representation from unlabeled data, which is essential for action recognition. Extensive experiments on two popular datasets, i.e. NTU-RGB+D and Kinetics-Skeleton, demonstrate that our model achieves the state-of-the-art performance for semi-supervised skeleton-based action recognition and is also useful for fully-supervised methods.