 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGC2026: Micro-Expression Grand Challenge on Visual Question Answering
Mar 09, 2026Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. In recent years, substantial advancements have been made in the areas of ME recognition, spotting, and generation. The emergence of multimodal large language models (MLLMs) and large vision-language models (LVLMs) offers promising new avenues for enhancing ME analysis through their powerful multimodal reasoning capabilities. The ME grand challenge (MEGC) 2026 introduces two tasks that reflect these evolving research directions: (1) ME video question answering (ME-VQA), which explores ME understanding through visual question answering on relatively short video sequences, leveraging MLLMs or LVLMs to address diverse question types related to MEs; and (2) ME long-video question answering (ME-LVQA), which extends VQA to long-duration video sequences in realistic settings, requiring models to handle temporal reasoning and subtle micro-expression detection across extended time periods. All participating algorithms are required to submit their results on a public leaderboard. More details are available at https://megc2026.github.io.
FED-PsyAU: Privacy-Preserving Micro-Expression Recognition via Psychological AU Coordination and Dynamic Facial Motion Modeling
Jul 28, 2025



Micro-expressions (MEs) are brief, low-intensity, often localized facial expressions. They could reveal genuine emotions individuals may attempt to conceal, valuable in contexts like criminal interrogation and psychological counseling. However, ME recognition (MER) faces challenges, such as small sample sizes and subtle features, which hinder efficient modeling. Additionally, real-world applications encounter ME data privacy issues, leaving the task of enhancing recognition across settings under privacy constraints largely unexplored. To address these issues, we propose a FED-PsyAU research framework. We begin with a psychological study on the coordination of upper and lower facial action units (AUs) to provide structured prior knowledge of facial muscle dynamics. We then develop a DPK-GAT network that combines these psychological priors with statistical AU patterns, enabling hierarchical learning of facial motion features from regional to global levels, effectively enhancing MER performance. Additionally, our federated learning framework advances MER capabilities across multiple clients without data sharing, preserving privacy and alleviating the limited-sample issue for each client. Extensive experiments on commonly-used ME databases demonstrate the effectiveness of our approach.
MEGC2025: Micro-Expression Grand Challenge on Spot Then Recognize and Visual Question Answering
Jun 18, 2025
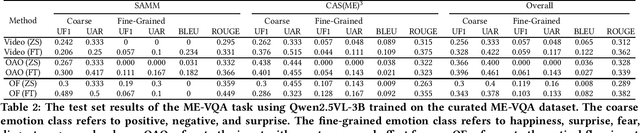
Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. In recent years, substantial advancements have been made in the areas of ME recognition, spotting, and generation. However, conventional approaches that treat spotting and recognition as separate tasks are suboptimal, particularly for analyzing long-duration videos in realistic settings. Concurrently, the emergence of multimodal large language models (MLLMs) and large vision-language models (LVLMs) offers promising new avenues for enhancing ME analysis through their powerful multimodal reasoning capabilities. The ME grand challenge (MEGC) 2025 introduces two tasks that reflect these evolving research directions: (1) ME spot-then-recognize (ME-STR), which integrates ME spotting and subsequent recognition in a unified sequential pipeline; and (2) ME visual question answering (ME-VQA), which explores ME understanding through visual question answering, leveraging MLLMs or LVLMs to address diverse question types related to MEs. All participating algorithms are required to run on this test set and submit their results on a leaderboard. More details are available at https://megc2025.github.io.
CDSD: Chinese Dysarthria Speech Database
Oct 24, 2023



We present the Chinese Dysarthria Speech Database (CDSD) as a valuable resource for dysarthria research. This database comprises speech data from 24 participants with dysarthria. Among these participants, one recorded an additional 10 hours of speech data, while each recorded one hour, resulting in 34 hours of speech material. To accommodate participants with varying cognitive levels, our text pool primarily consists of content from the AISHELL-1 dataset and speeches by primary and secondary school students. When participants read these texts, they must use a mobile device or the ZOOM F8n multi-track field recorder to record their speeches. In this paper, we elucidate the data collection and annotation processes and present an approach for establishing a baseline for dysarthric speech recognition. Furthermore, we conducted a speaker-dependent dysarthric speech recognition experiment using an additional 10 hours of speech data from one of our participants. Our research findings indicate that, through extensive data-driven model training, fine-tuning limited quantities of specific individual data yields commendable results in speaker-dependent dysarthric speech recognition. However, we observe significant variations in recognition results among different dysarthric speakers. These insights provide valuable reference points for speaker-dependent dysarthric speech recognition.
Video-based Facial Micro-Expression Analysis: A Survey of Datasets, Features and Algorithms
Feb 16, 2022
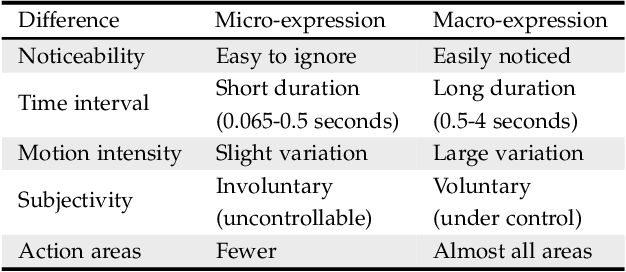
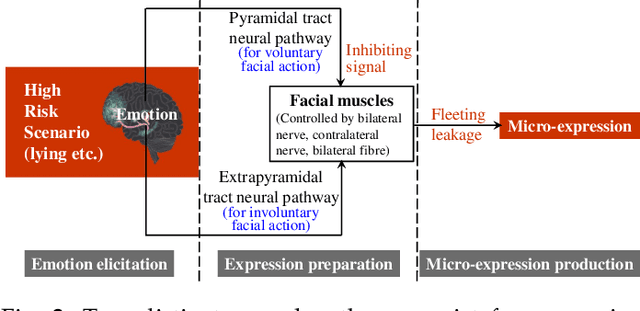
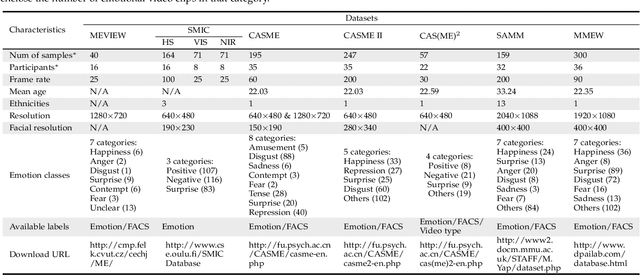
Unlike the conventional facial expressions, micro-expressions are involuntary and transient facial expressions capable of revealing the genuine emotions that people attempt to hide. Therefore, they can provide important information in a broad range of applications such as lie detection, criminal detection, etc. Since micro-expressions are transient and of low intensity, however, their detection and recognition is difficult and relies heavily on expert experiences. Due to its intrinsic particularity and complexity, video-based micro-expression analysis is attractive but challenging, and has recently become an active area of research. Although there have been numerous developments in this area, thus far there has been no comprehensive survey that provides researchers with a systematic overview of these developments with a unified evaluation. Accordingly, in this survey paper, we first highlight the key differences between macro- and micro-expressions, then use these differences to guide our research survey of video-based micro-expression analysis in a cascaded structure, encompassing the neuropsychological basis, datasets, features, spotting algorithms, recognition algorithms, applications and evaluation of state-of-the-art approaches. For each aspect, the basic techniques, advanced developments and major challenges are addressed and discussed. Furthermore, after considering the limitations of existing micro-expression datasets, we present and release a new dataset - called micro-and-macro expression warehouse (MMEW) - containing more video samples and more labeled emotion types. We then perform a unified comparison of representative methods on CAS(ME)2 for spotting, and on MMEW and SAMM for recognition, respectively. Finally, some potential future research directions are explored and outlined.
Spotting Macro- and Micro-expression Intervals in Long Video Sequences
Feb 05, 2020

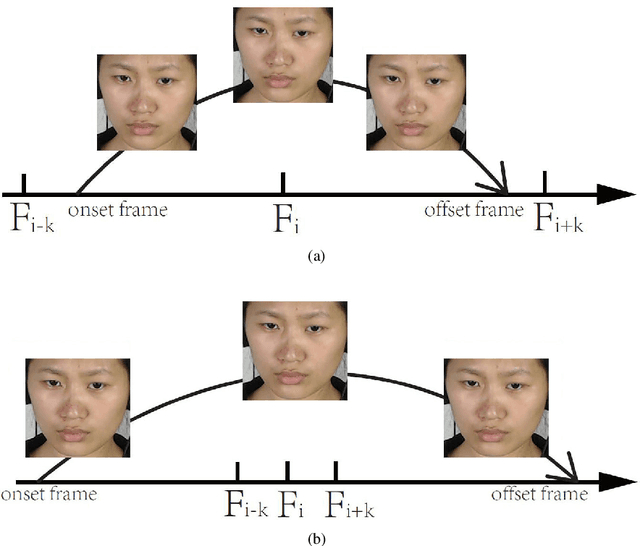
This paper presents baseline results for the Third Facial Micro-Expression Grand Challenge (MEGC 2020). Both macro- and micro-expression intervals in CAS(ME)$^2$ and SAMM Long Videos are spotted by employing the method of Main Directional Maximal Difference Analysis (MDMD). The MDMD method uses the magnitude maximal difference in the main direction of optical flow features to spot facial movements. The single frame prediction results of the original MDMD method are post processed into reasonable video intervals. The metric F1-scores of baseline results are evaluated: for CAS(ME)$^2$, the F1-scores are 0.1196 and 0.0082 for macro- and micro-expressions respectively, and the overall F1-score is 0.0376; for SAMM Long Videos, the F1-scores are 0.0629 and 0.0364 for macro- and micro-expressions respectively, and the overall F1-score is 0.0445. The baseline project codes is publicly available at https://github.com/HeyingGithub/Baseline-project-for-MEGC2020_spotting.