 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Poisoning Attacks and Defenses on Artificial Intelligence: A Survey
Feb 22, 2022
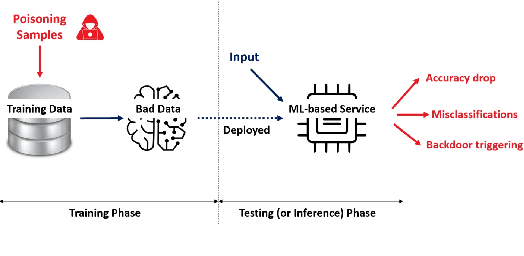
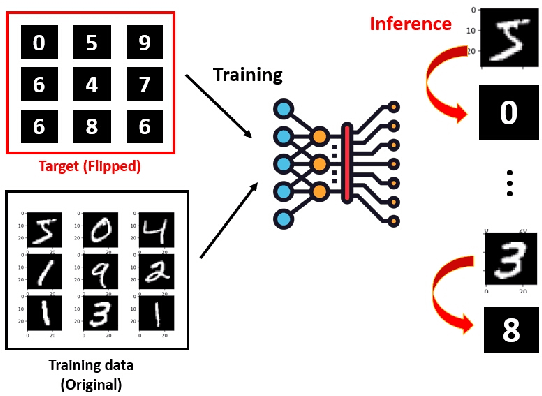
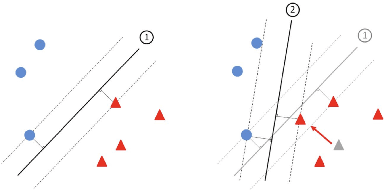
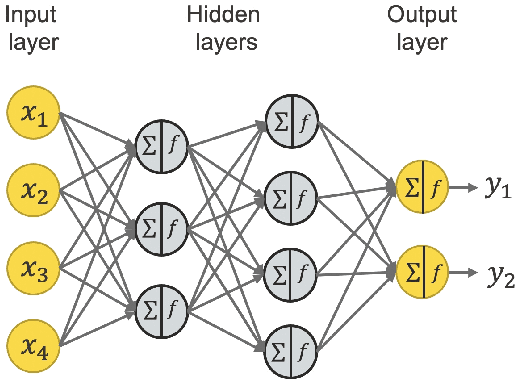
Machine learning models have been widely adopted in several fields. However, most recent studies have shown several vulnerabilities from attacks with a potential to jeopardize the integrity of the model, presenting a new window of research opportunity in terms of cyber-security. This survey is conducted with a main intention of highlighting the most relevant information related to security vulnerabilities in the context of machine learning (ML) classifiers; more specifically, directed towards training procedures against data poisoning attacks, representing a type of attack that consists of tampering the data samples fed to the model during the training phase, leading to a degradation in the models accuracy during the inference phase. This work compiles the most relevant insights and findings found in the latest existing literatures addressing this type of attacks. Moreover, this paper also covers several defense techniques that promise feasible detection and mitigation mechanisms, capable of conferring a certain level of robustness to a target model against an attacker. A thorough assessment is performed on the reviewed works, comparing the effects of data poisoning on a wide range of ML models in real-world conditions, performing quantitative and qualitative analyses. This paper analyzes the main characteristics for each approach including performance success metrics, required hyperparameters, and deployment complexity. Moreover, this paper emphasizes the underlying assumptions and limitations considered by both attackers and defenders along with their intrinsic properties such as: availability, reliability, privacy, accountability, interpretability, etc. Finally, this paper concludes by making references of some of main existing research trends that provide pathways towards future research directions in the field of cyber-security.
A Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022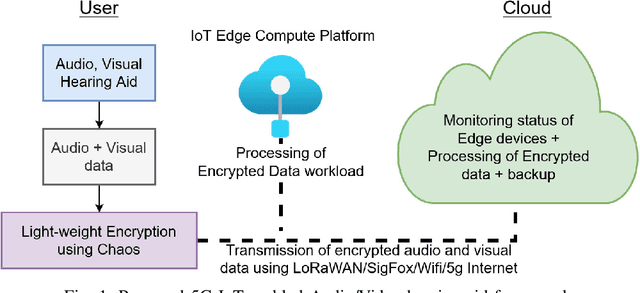

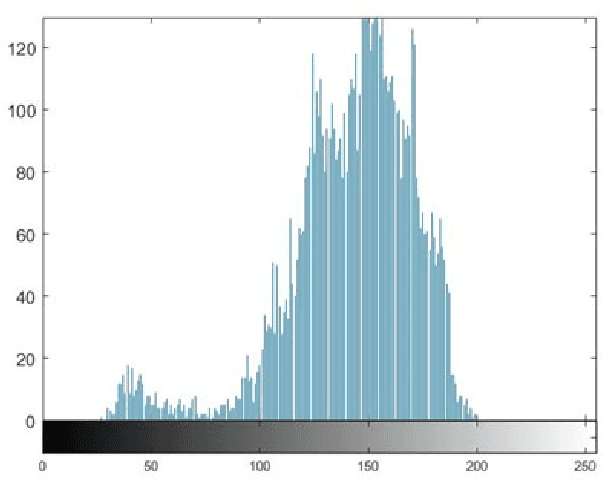
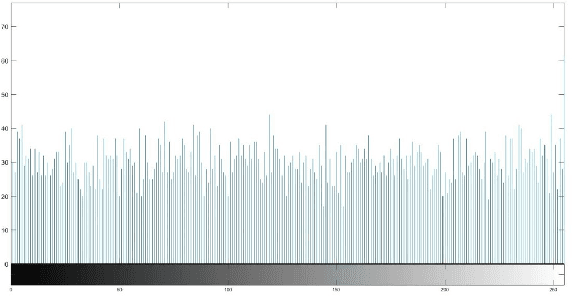
Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.
Everything at Once -- Multi-modal Fusion Transformer for Video Retrieval
Dec 08, 2021

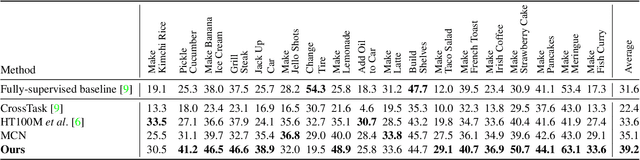
Multi-modal learning from video data has seen increased attention recently as it allows to train semantically meaningful embeddings without human annotation enabling tasks like zero-shot retrieval and classification. In this work, we present a multi-modal, modality agnostic fusion transformer approach that learns to exchange information between multiple modalities, such as video, audio, and text, and integrate them into a joined multi-modal representation to obtain an embedding that aggregates multi-modal temporal information. We propose to train the system with a combinatorial loss on everything at once, single modalities as well as pairs of modalities, explicitly leaving out any add-ons such as position or modality encoding. At test time, the resulting model can process and fuse any number of input modalities. Moreover, the implicit properties of the transformer allow to process inputs of different lengths. To evaluate the proposed approach, we train the model on the large scale HowTo100M dataset and evaluate the resulting embedding space on four challenging benchmark datasets obtaining state-of-the-art results in zero-shot video retrieval and zero-shot video action localization.
Equilibrated Zeroth-Order Unrolled Deep Networks for Accelerated MRI
Dec 23, 2021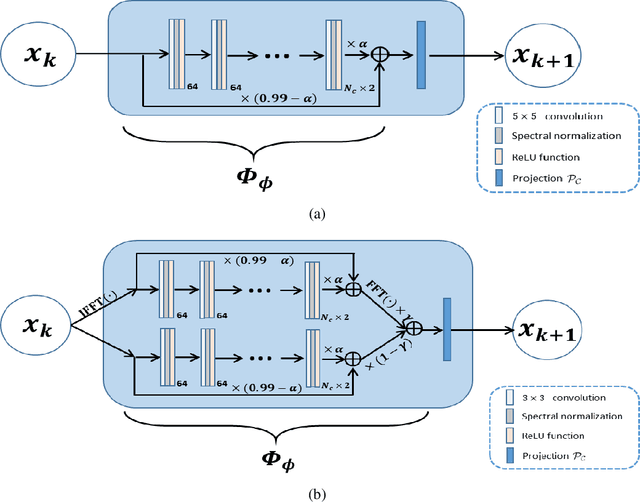
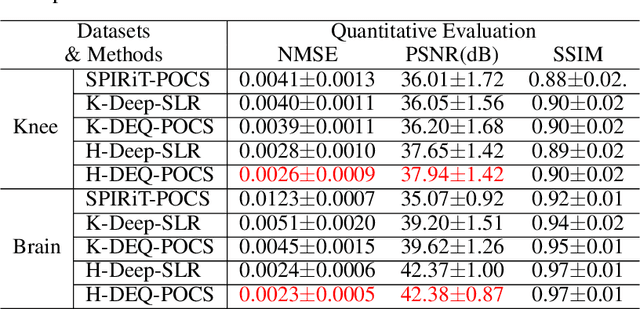

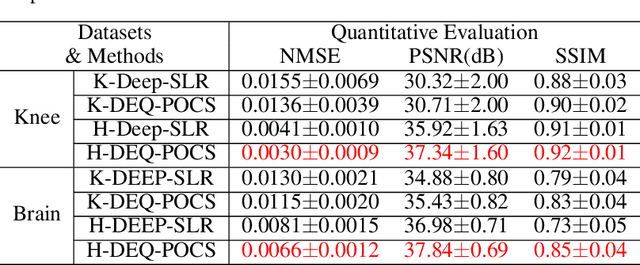
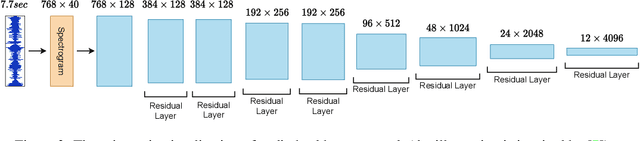
Recently, model-driven deep learning unrolls a certain iterative algorithm of a regularization model into a cascade network by replacing the first-order information (i.e., (sub)gradient or proximal operator) of the regularizer with a network module, which appears more explainable and predictable compared to common data-driven networks. Conversely, in theory, there is not necessarily such a functional regularizer whose first-order information matches the replaced network module, which means the network output may not be covered by the original regularization model. Moreover, up to now, there is also no theory to guarantee the global convergence and robustness (regularity) of unrolled networks under realistic assumptions. To bridge this gap, this paper propose to present a safeguarded methodology on network unrolling. Specifically, focusing on accelerated MRI, we unroll a zeroth-order algorithm, of which the network module represents the regularizer itself, so that the network output can be still covered by the regularization model. Furthermore, inspired by the ideal of deep equilibrium models, before backpropagating, we carry out the unrolled iterative network to converge to a fixed point to ensure the convergence. In case the measurement data contains noise, we prove that the proposed network is robust against noisy interference. Finally, numerical experiments show that the proposed network consistently outperforms the state-of-the-art MRI reconstruction methods including traditional regularization methods and other deep learning methods.
Understanding Knowledge Integration in Language Models with Graph Convolutions
Feb 15, 2022
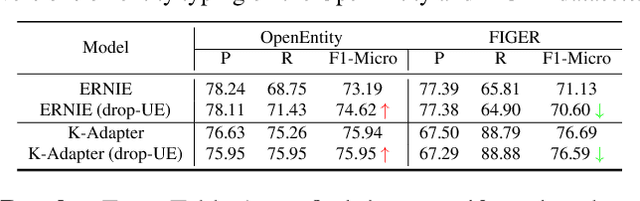
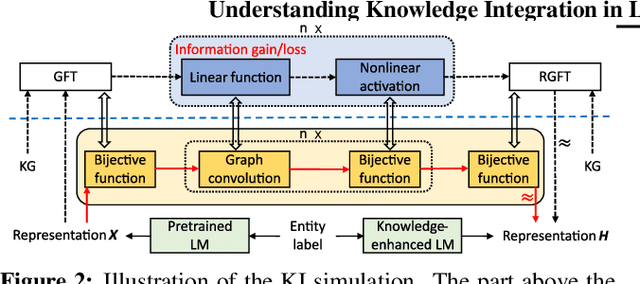
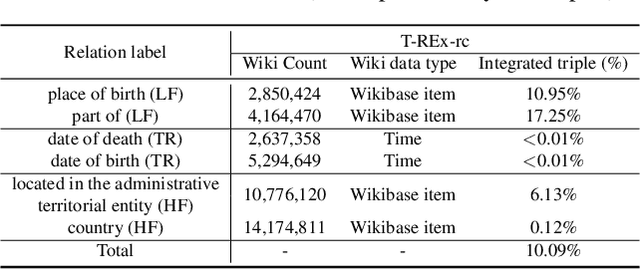
Pretrained language models (LMs) do not capture factual knowledge very well. This has led to the development of a number of knowledge integration (KI) methods which aim to incorporate external knowledge into pretrained LMs. Even though KI methods show some performance gains over vanilla LMs, the inner-workings of these methods are not well-understood. For instance, it is unclear how and what kind of knowledge is effectively integrated into these models and if such integration may lead to catastrophic forgetting of already learned knowledge. This paper revisits the KI process in these models with an information-theoretic view and shows that KI can be interpreted using a graph convolution operation. We propose a probe model called \textit{Graph Convolution Simulator} (GCS) for interpreting knowledge-enhanced LMs and exposing what kind of knowledge is integrated into these models. We conduct experiments to verify that our GCS can indeed be used to correctly interpret the KI process, and we use it to analyze two well-known knowledge-enhanced LMs: ERNIE and K-Adapter, and find that only a small amount of factual knowledge is integrated in them. We stratify knowledge in terms of various relation types and find that ERNIE and K-Adapter integrate different kinds of knowledge to different extent. Our analysis also shows that simply increasing the size of the KI corpus may not lead to better KI; fundamental advances may be needed.
Towards Personalized Answer Generation in E-Commerce via Multi-Perspective Preference Modeling
Dec 27, 2021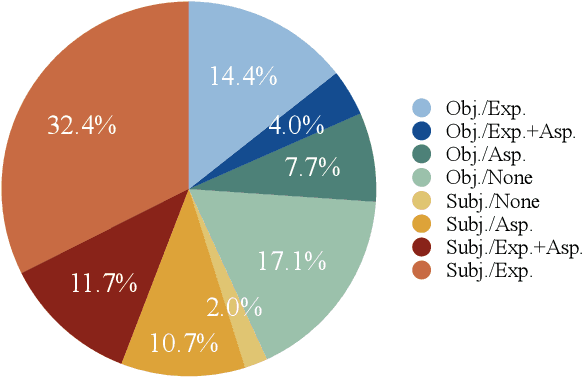


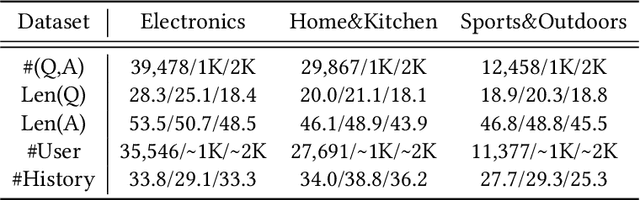
Recently, Product Question Answering (PQA) on E-Commerce platforms has attracted increasing attention as it can act as an intelligent online shopping assistant and improve the customer shopping experience. Its key function, automatic answer generation for product-related questions, has been studied by aiming to generate content-preserving while question-related answers. However, an important characteristic of PQA, i.e., personalization, is neglected by existing methods. It is insufficient to provide the same "completely summarized" answer to all customers, since many customers are more willing to see personalized answers with customized information only for themselves, by taking into consideration their own preferences towards product aspects or information needs. To tackle this challenge, we propose a novel Personalized Answer GEneration method (PAGE) with multi-perspective preference modeling, which explores historical user-generated contents to model user preference for generating personalized answers in PQA. Specifically, we first retrieve question-related user history as external knowledge to model knowledge-level user preference. Then we leverage Gaussian Softmax distribution model to capture latent aspect-level user preference. Finally, we develop a persona-aware pointer network to generate personalized answers in terms of both content and style by utilizing personal user preference and dynamic user vocabulary. Experimental results on real-world E-Commerce QA datasets demonstrate that the proposed method outperforms existing methods by generating informative and customized answers, and show that answer generation in E-Commerce can benefit from personalization.
Improving Federated Learning Face Recognition via Privacy-Agnostic Clusters
Jan 29, 2022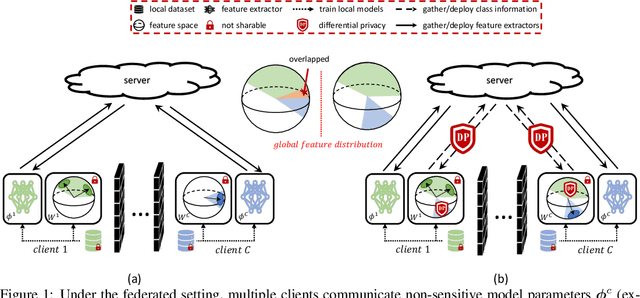
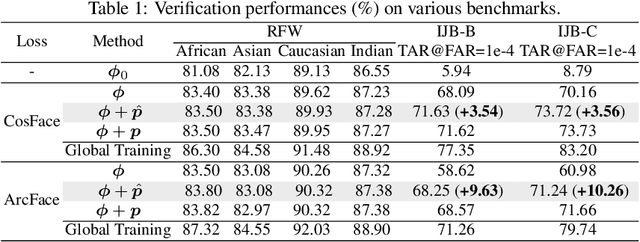
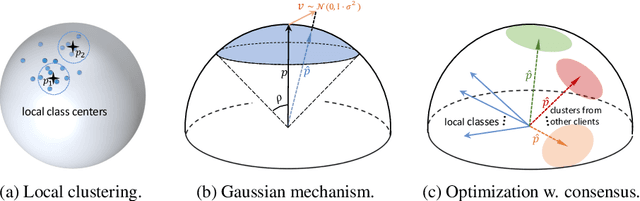
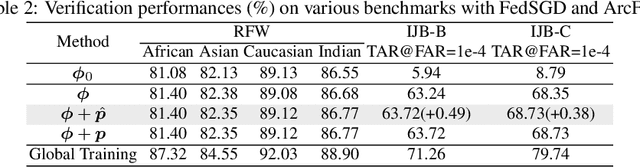
The growing public concerns on data privacy in face recognition can be greatly addressed by the federated learning (FL) paradigm. However, conventional FL methods perform poorly due to the uniqueness of the task: broadcasting class centers among clients is crucial for recognition performances but leads to privacy leakage. To resolve the privacy-utility paradox, this work proposes PrivacyFace, a framework largely improves the federated learning face recognition via communicating auxiliary and privacy-agnostic information among clients. PrivacyFace mainly consists of two components: First, a practical Differentially Private Local Clustering (DPLC) mechanism is proposed to distill sanitized clusters from local class centers. Second, a consensus-aware recognition loss subsequently encourages global consensuses among clients, which ergo results in more discriminative features. The proposed framework is mathematically proved to be differentially private, introducing a lightweight overhead as well as yielding prominent performance boosts (\textit{e.g.}, +9.63\% and +10.26\% for TAR@FAR=1e-4 on IJB-B and IJB-C respectively). Extensive experiments and ablation studies on a large-scale dataset have demonstrated the efficacy and practicability of our method.
Learning with Less Labels in Digital Pathology via Scribble Supervision from Natural Images
Jan 20, 2022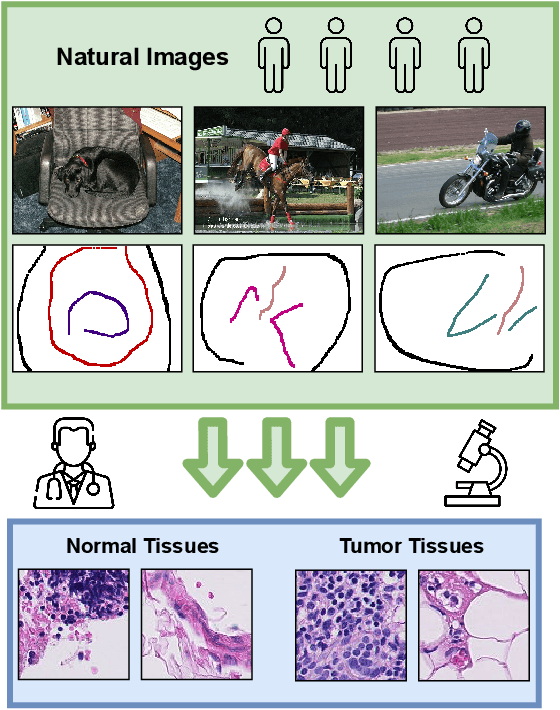
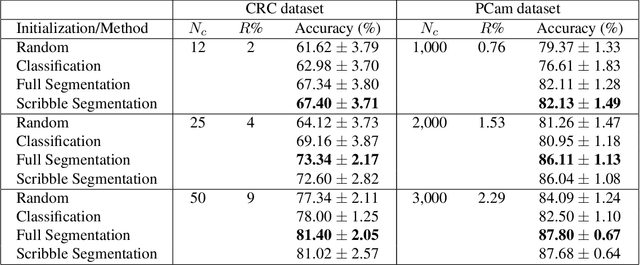

A critical challenge of training deep learning models in the Digital Pathology (DP) domain is the high annotation cost by medical experts. One way to tackle this issue is via transfer learning from the natural image domain (NI), where the annotation cost is considerably cheaper. Cross-domain transfer learning from NI to DP is shown to be successful via class labels. One potential weakness of relying on class labels is the lack of spatial information, which can be obtained from spatial labels such as full pixel-wise segmentation labels and scribble labels. We demonstrate that scribble labels from NI domain can boost the performance of DP models on two cancer classification datasets (Patch Camelyon Breast Cancer and Colorectal Cancer dataset). Furthermore, we show that models trained with scribble labels yield the same performance boost as full pixel-wise segmentation labels despite being significantly easier and faster to collect.
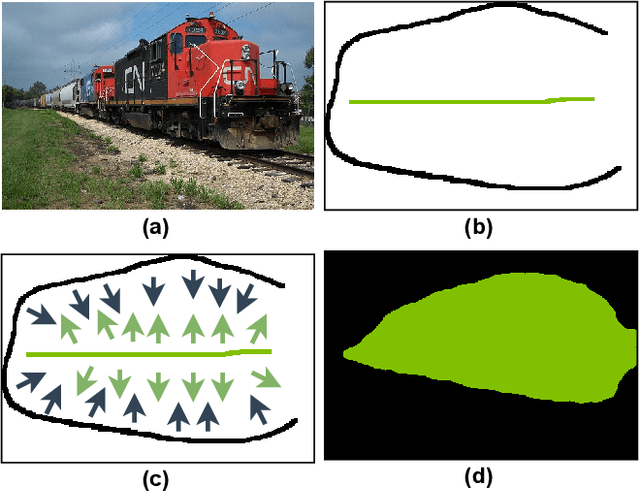
ULSA: Unified Language of Synthesis Actions for Representation of Synthesis Protocols
Jan 23, 2022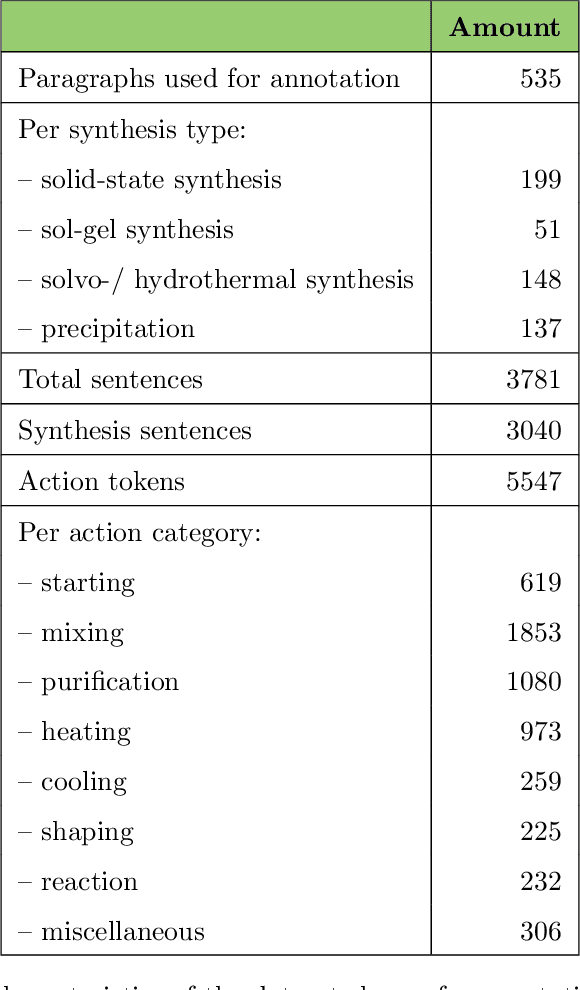
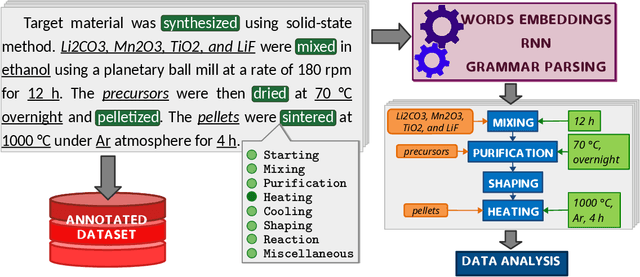
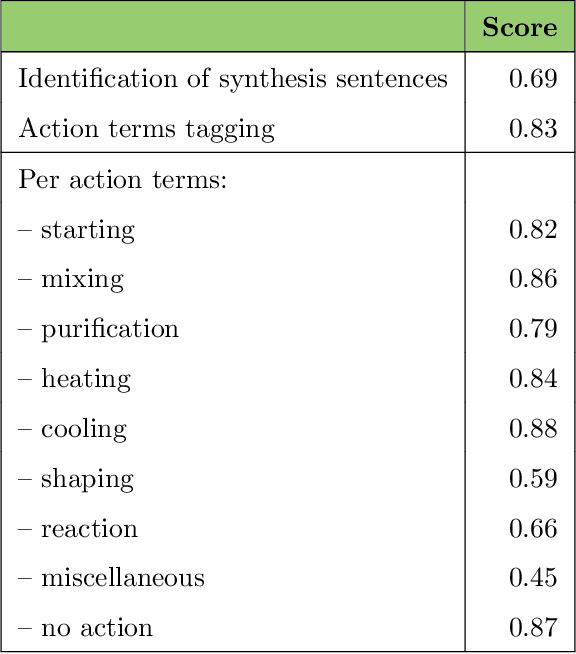
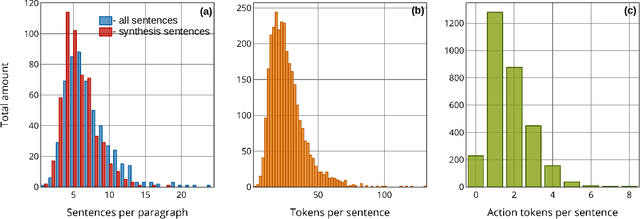
Applying AI power to predict syntheses of novel materials requires high-quality, large-scale datasets. Extraction of synthesis information from scientific publications is still challenging, especially for extracting synthesis actions, because of the lack of a comprehensive labeled dataset using a solid, robust, and well-established ontology for describing synthesis procedures. In this work, we propose the first Unified Language of Synthesis Actions (ULSA) for describing ceramics synthesis procedures. We created a dataset of 3,040 synthesis procedures annotated by domain experts according to the proposed ULSA scheme. To demonstrate the capabilities of ULSA, we built a neural network-based model to map arbitrary ceramics synthesis paragraphs into ULSA and used it to construct synthesis flowcharts for synthesis procedures. Analysis for the flowcharts showed that (a) ULSA covers essential vocabulary used by researchers when describing synthesis procedures and (b) it can capture important features of synthesis protocols. This work is an important step towards creating a synthesis ontology and a solid foundation for autonomous robotic synthesis.
Case law retrieval: problems, methods, challenges and evaluations in the last 20 years
Feb 15, 2022Case law retrieval is the retrieval of judicial decisions relevant to a legal question. Case law retrieval comprises a significant amount of a lawyer's time, and is important to ensure accurate advice and reduce workload. We survey methods for case law retrieval from the past 20 years and outline the problems and challenges facing evaluation of case law retrieval systems going forward. Limited published work has focused on improving ranking in ad-hoc case law retrieval. But there has been significant work in other areas of case law retrieval, and legal information retrieval generally. This is likely due to legal search providers being unwilling to give up the secrets of their success to competitors. Most evaluations of case law retrieval have been undertaken on small collections and focus on related tasks such as question-answer systems or recommender systems. Work has not focused on Cranfield style evaluations and baselines of methods for case law retrieval on publicly available test collections are not present. This presents a major challenge going forward. But there are reasons to question the extent of this problem, at least in a commercial setting. Without test collections to baseline approaches it cannot be known whether methods are promising. Works by commercial legal search providers show the effectiveness of natural language systems as well as query expansion for case law retrieval. Machine learning is being applied to more and more legal search tasks, and undoubtedly this represents the future of case law retrieval.