 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Cholesky Gaussian Processes
Feb 23, 2022
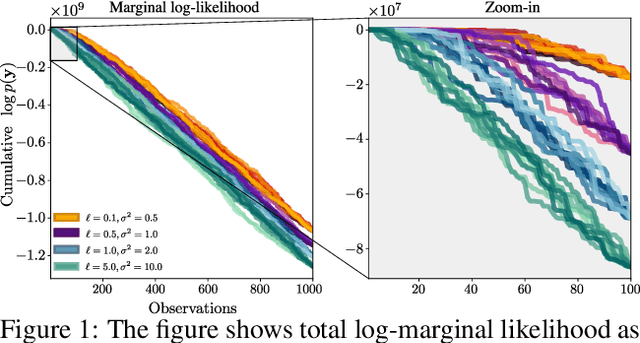
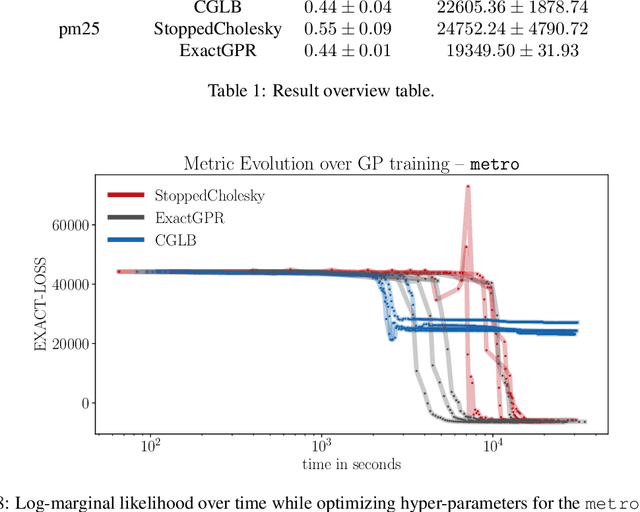
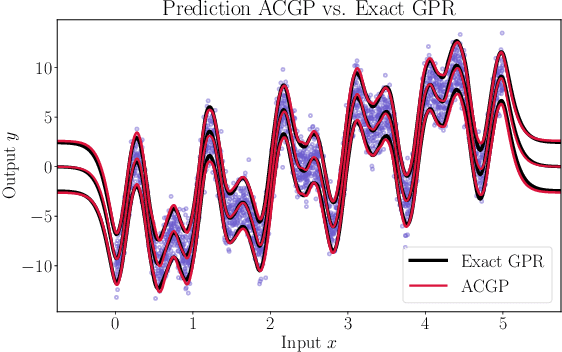
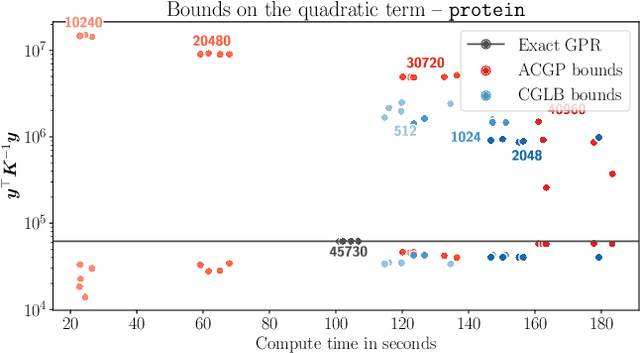
We present a method to fit exact Gaussian process models to large datasets by considering only a subset of the data. Our approach is novel in that the size of the subset is selected on the fly during exact inference with little computational overhead. From an empirical observation that the log-marginal likelihood often exhibits a linear trend once a sufficient subset of a dataset has been observed, we conclude that many large datasets contain redundant information that only slightly affects the posterior. Based on this, we provide probabilistic bounds on the full model evidence that can identify such subsets. Remarkably, these bounds are largely composed of terms that appear in intermediate steps of the standard Cholesky decomposition, allowing us to modify the algorithm to adaptively stop the decomposition once enough data have been observed. Empirically, we show that our method can be directly plugged into well-known inference schemes to fit exact Gaussian process models to large datasets.
Look Closer: Bridging Egocentric and Third-Person Views with Transformers for Robotic Manipulation
Jan 20, 2022
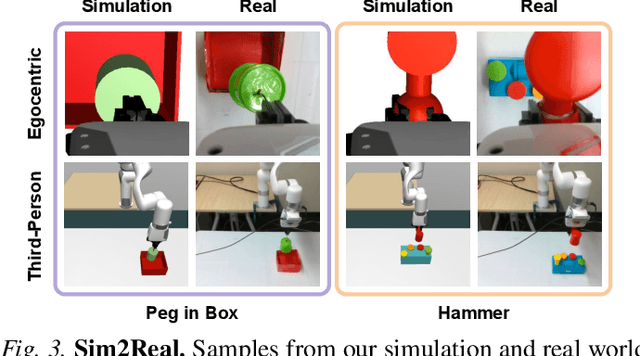
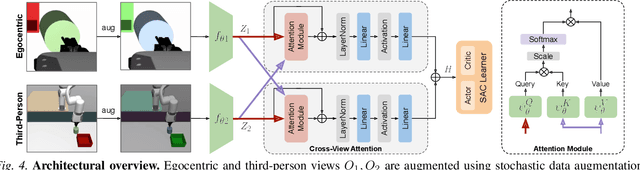

Learning to solve precision-based manipulation tasks from visual feedback using Reinforcement Learning (RL) could drastically reduce the engineering efforts required by traditional robot systems. However, performing fine-grained motor control from visual inputs alone is challenging, especially with a static third-person camera as often used in previous work. We propose a setting for robotic manipulation in which the agent receives visual feedback from both a third-person camera and an egocentric camera mounted on the robot's wrist. While the third-person camera is static, the egocentric camera enables the robot to actively control its vision to aid in precise manipulation. To fuse visual information from both cameras effectively, we additionally propose to use Transformers with a cross-view attention mechanism that models spatial attention from one view to another (and vice-versa), and use the learned features as input to an RL policy. Our method improves learning over strong single-view and multi-view baselines, and successfully transfers to a set of challenging manipulation tasks on a real robot with uncalibrated cameras, no access to state information, and a high degree of task variability. In a hammer manipulation task, our method succeeds in 75% of trials versus 38% and 13% for multi-view and single-view baselines, respectively.
FusionCount: Efficient Crowd Counting via Multiscale Feature Fusion
Feb 28, 2022
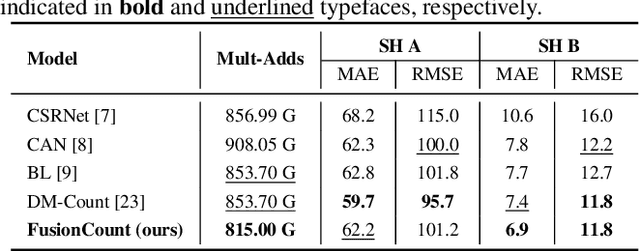
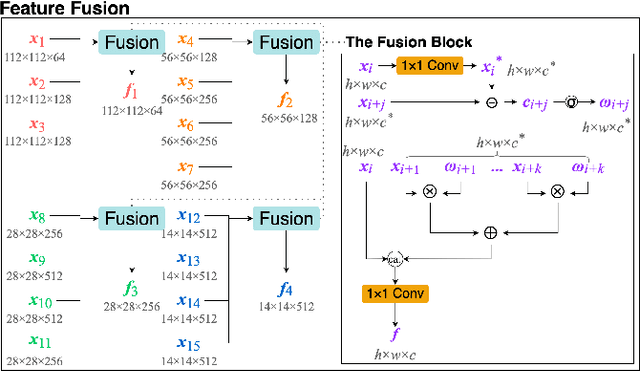

State-of-the-art crowd counting models follow an encoder-decoder approach. Images are first processed by the encoder to extract features. Then, to account for perspective distortion, the highest-level feature map is fed to extra components to extract multiscale features, which are the input to the decoder to generate crowd densities. However, in these methods, features extracted at earlier stages during encoding are underutilised, and the multiscale modules can only capture a limited range of receptive fields, albeit with considerable computational cost. This paper proposes a novel crowd counting architecture (FusionCount), which exploits the adaptive fusion of a large majority of encoded features instead of relying on additional extraction components to obtain multiscale features. Thus, it can cover a more extensive scope of receptive field sizes and lower the computational cost. We also introduce a new channel reduction block, which can extract saliency information during decoding and further enhance the model's performance. Experiments on two benchmark databases demonstrate that our model achieves state-of-the-art results with reduced computational complexity.
Query Suggestion for Click-Absent Queries in Enterprise Search
Dec 28, 2021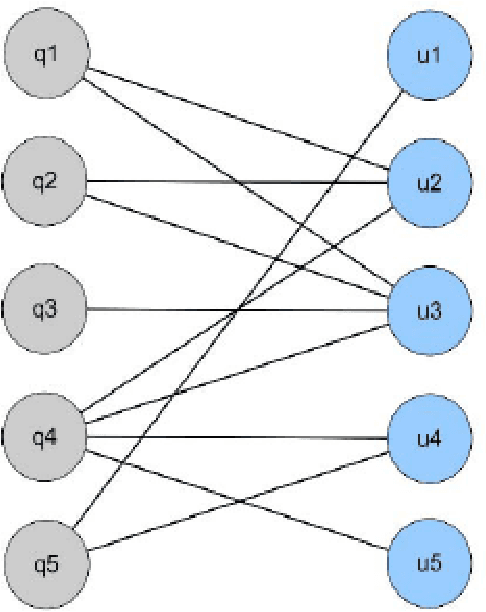
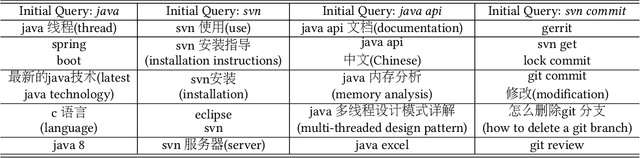
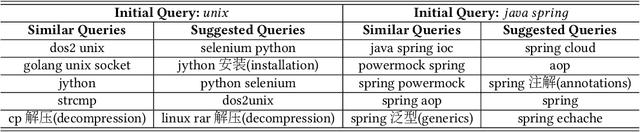
Creating alternative queries, also known as query suggestion, has been proved to be helpful on improving users' search experience. Owing to the suggestions, users could retrieve their information need more quickly and accurately. In many scenarios, these suggestions could be generated from the click-through logs by establishing a bipartite graph of the clicked query-document pairs. Most of the existing methods focused on click-existing queries which possess clicked information in the search logs, to suggest related queries using the co-clicked documents. In this paper, we propose a simple yet effective query suggestion method particularly for click-absent queries by ensuring semantic consistency without utilising any additional resources. Our experimental results show that the proposed technique generates comparatively good suggestions for click-absent queries on a real bilingual enterprise search log.
Graph Collaborative Reasoning
Dec 27, 2021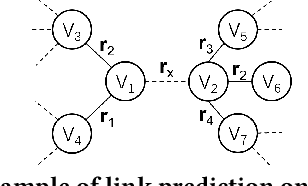


Graphs can represent relational information among entities and graph structures are widely used in many intelligent tasks such as search, recommendation, and question answering. However, most of the graph-structured data in practice suffers from incompleteness, and thus link prediction becomes an important research problem. Though many models are proposed for link prediction, the following two problems are still less explored: (1) Most methods model each link independently without making use of the rich information from relevant links, and (2) existing models are mostly designed based on associative learning and do not take reasoning into consideration. With these concerns, in this paper, we propose Graph Collaborative Reasoning (GCR), which can use the neighbor link information for relational reasoning on graphs from logical reasoning perspectives. We provide a simple approach to translate a graph structure into logical expressions, so that the link prediction task can be converted into a neural logic reasoning problem. We apply logical constrained neural modules to build the network architecture according to the logical expression and use back propagation to efficiently learn the model parameters, which bridges differentiable learning and symbolic reasoning in a unified architecture. To show the effectiveness of our work, we conduct experiments on graph-related tasks such as link prediction and recommendation based on commonly used benchmark datasets, and our graph collaborative reasoning approach achieves state-of-the-art performance.
TSA-Net: Tube Self-Attention Network for Action Quality Assessment
Jan 11, 2022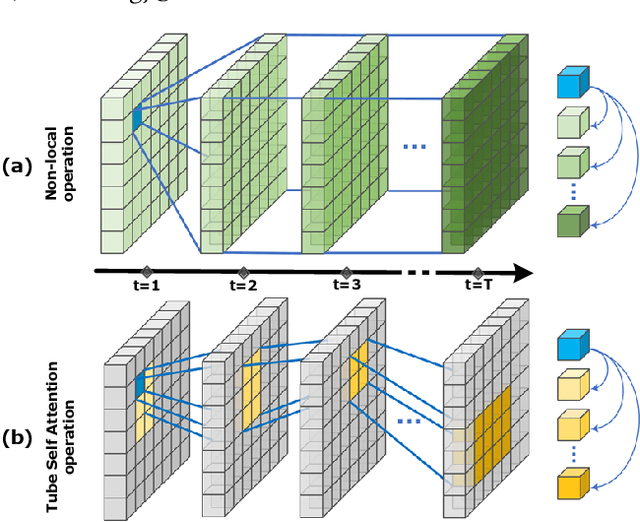
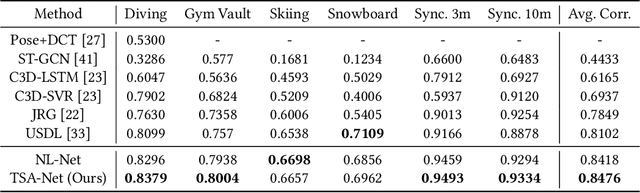
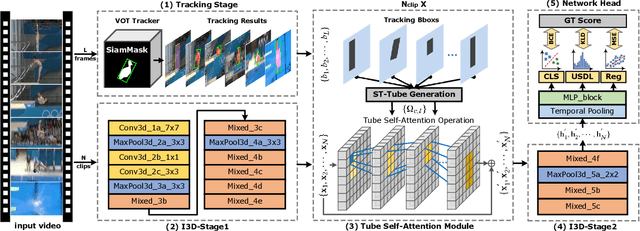

In recent years, assessing action quality from videos has attracted growing attention in computer vision community and human computer interaction. Most existing approaches usually tackle this problem by directly migrating the model from action recognition tasks, which ignores the intrinsic differences within the feature map such as foreground and background information. To address this issue, we propose a Tube Self-Attention Network (TSA-Net) for action quality assessment (AQA). Specifically, we introduce a single object tracker into AQA and propose the Tube Self-Attention Module (TSA), which can efficiently generate rich spatio-temporal contextual information by adopting sparse feature interactions. The TSA module is embedded in existing video networks to form TSA-Net. Overall, our TSA-Net is with the following merits: 1) High computational efficiency, 2) High flexibility, and 3) The state-of-the art performance. Extensive experiments are conducted on popular action quality assessment datasets including AQA-7 and MTL-AQA. Besides, a dataset named Fall Recognition in Figure Skating (FR-FS) is proposed to explore the basic action assessment in the figure skating scene.
FastRPB: a Scalable Relative Positional Encoding for Long Sequence Tasks
Feb 23, 2022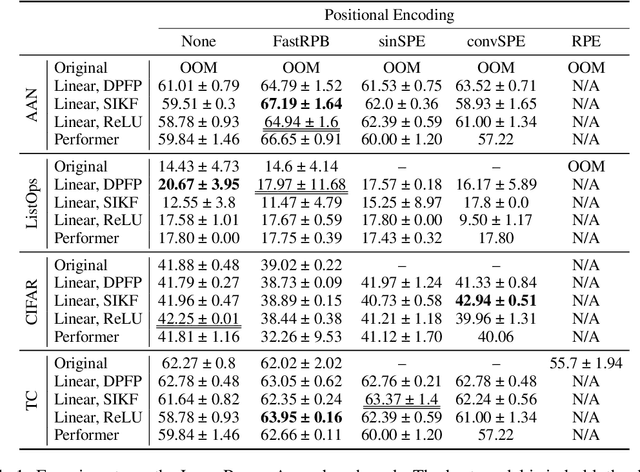
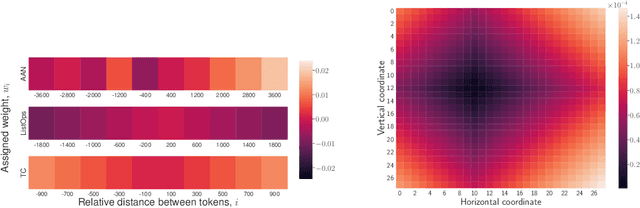
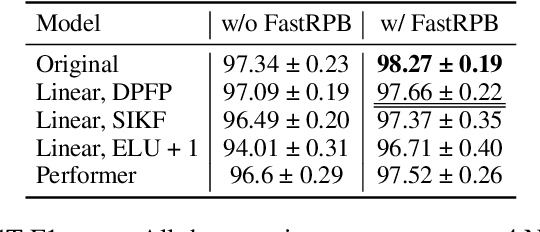
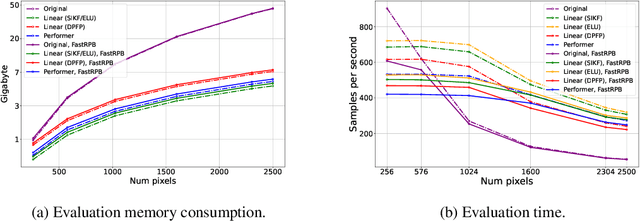
Transformers achieve remarkable performance in various domains, including NLP, CV, audio processing, and graph analysis. However, they do not scale well on long sequence tasks due to their quadratic complexity w.r.t. the inputs length. Linear Transformers were proposed to address this limitation. However, these models have shown weaker performance on the long sequence tasks comparing to the original one. In this paper, we explore Linear Transformer models, rethinking their two core components. Firstly, we improved Linear Transformer with Shift-Invariant Kernel Function SIKF, which achieve higher accuracy without loss in speed. Secondly, we introduce FastRPB which stands for Fast Relative Positional Bias, which efficiently adds positional information to self-attention using Fast Fourier Transformation. FastRPB is independent of the self-attention mechanism and can be combined with an original self-attention and all its efficient variants. FastRPB has O(N log(N)) computational complexity, requiring O(N) memory w.r.t. input sequence length N.
Competing in a Complex Hidden Role Game with Information Set Monte Carlo Tree Search
May 14, 2020

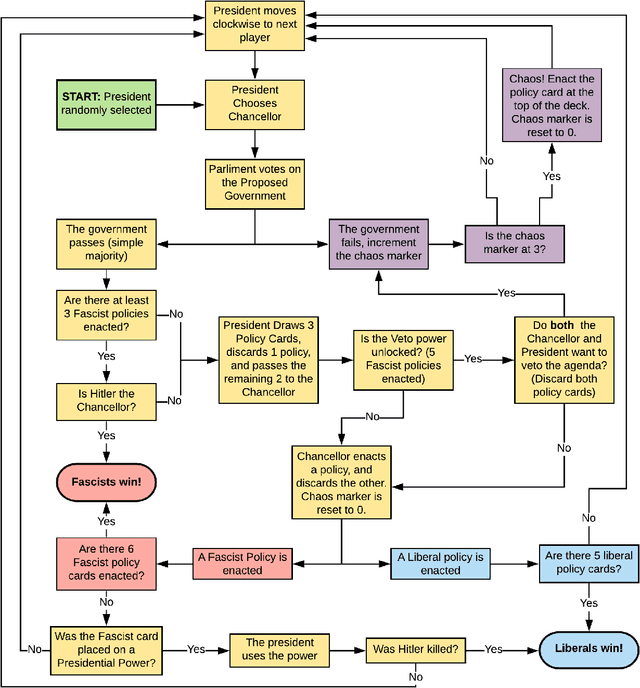

Advances in intelligent game playing agents have led to successes in perfect information games like Go and imperfect information games like Poker. The Information Set Monte Carlo Tree Search (ISMCTS) family of algorithms outperforms previous algorithms using Monte Carlo methods in imperfect information games. In this paper, Single Observer Information Set Monte Carlo Tree Search (SO-ISMCTS) is applied to Secret Hitler, a popular social deduction board game that combines traditional hidden role mechanics with the randomness of a card deck. This combination leads to a more complex information model than the hidden role and card deck mechanics alone. It is shown in 10108 simulated games that SO-ISMCTS plays as well as simpler rule based agents, and demonstrates the potential of ISMCTS algorithms in complicated information set domains.
Protum: A New Method For Prompt Tuning Based on "[MASK]"
Jan 28, 2022![Figure 1 for Protum: A New Method For Prompt Tuning Based on "[MASK]"](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F3c8a620170eed8cc8cb418db429c9e444a20ead6%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Protum: A New Method For Prompt Tuning Based on "[MASK]"](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F3c8a620170eed8cc8cb418db429c9e444a20ead6%2F5-Table1-1.png&w=640&q=75)
![Figure 3 for Protum: A New Method For Prompt Tuning Based on "[MASK]"](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F3c8a620170eed8cc8cb418db429c9e444a20ead6%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for Protum: A New Method For Prompt Tuning Based on "[MASK]"](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F3c8a620170eed8cc8cb418db429c9e444a20ead6%2F6-Table2-1.png&w=640&q=75)
Recently, prompt tuning \cite{lester2021power} has gradually become a new paradigm for NLP, which only depends on the representation of the words by freezing the parameters of pre-trained language models (PLMs) to obtain remarkable performance on downstream tasks. It maintains the consistency of Masked Language Model (MLM) \cite{devlin2018bert} task in the process of pre-training, and avoids some issues that may happened during fine-tuning. Naturally, we consider that the "[MASK]" tokens carry more useful information than other tokens because the model combines with context to predict the masked tokens. Among the current prompt tuning methods, there will be a serious problem of random composition of the answer tokens in prediction when they predict multiple words so that they have to map tokens to labels with the help verbalizer. In response to the above issue, we propose a new \textbf{Pro}mpt \textbf{Tu}ning based on "[\textbf{M}ASK]" (\textbf{Protum}) method in this paper, which constructs a classification task through the information carried by the hidden layer of "[MASK]" tokens and then predicts the labels directly rather than the answer tokens. At the same time, we explore how different hidden layers under "[MASK]" impact on our classification model on many different data sets. Finally, we find that our \textbf{Protum} can achieve much better performance than fine-tuning after continuous pre-training with less time consumption. Our model facilitates the practical application of large models in NLP.
3SD: Self-Supervised Saliency Detection With No Labels
Mar 09, 2022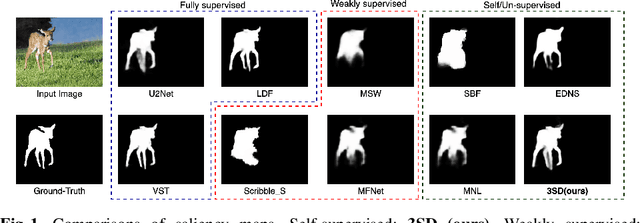
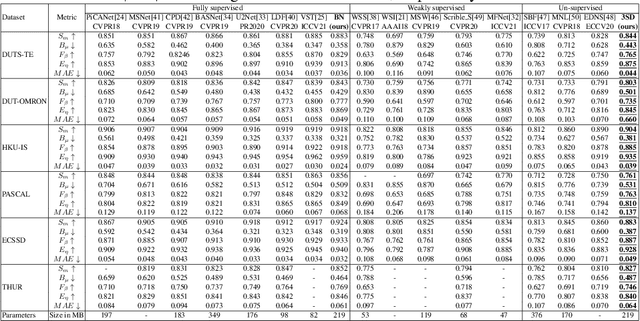

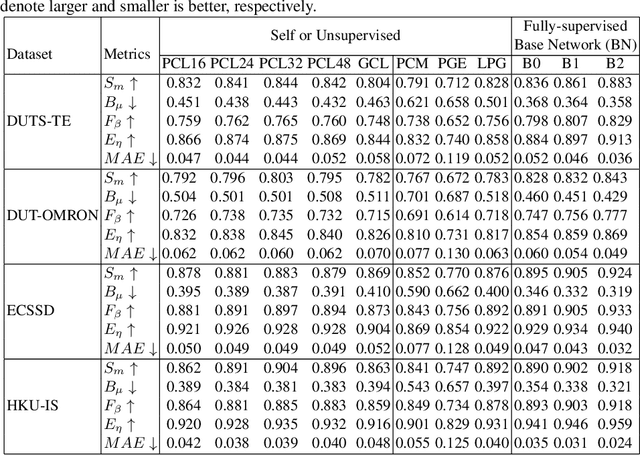
We present a conceptually simple self-supervised method for saliency detection. Our method generates and uses pseudo-ground truth labels for training. The generated pseudo-GT labels don't require any kind of human annotations (e.g., pixel-wise labels or weak labels like scribbles). Recent works show that features extracted from classification tasks provide important saliency cues like structure and semantic information of salient objects in the image. Our method, called 3SD, exploits this idea by adding a branch for a self-supervised classification task in parallel with salient object detection, to obtain class activation maps (CAM maps). These CAM maps along with the edges of the input image are used to generate the pseudo-GT saliency maps to train our 3SD network. Specifically, we propose a contrastive learning-based training on multiple image patches for the classification task. We show the multi-patch classification with contrastive loss improves the quality of the CAM maps compared to naive classification on the entire image. Experiments on six benchmark datasets demonstrate that without any labels, our 3SD method outperforms all existing weakly supervised and unsupervised methods, and its performance is on par with the fully-supervised methods. Code is available at :https://github.com/rajeevyasarla/3SD