 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Understanding microbiome dynamics via interpretable graph representation learning
Mar 02, 2022
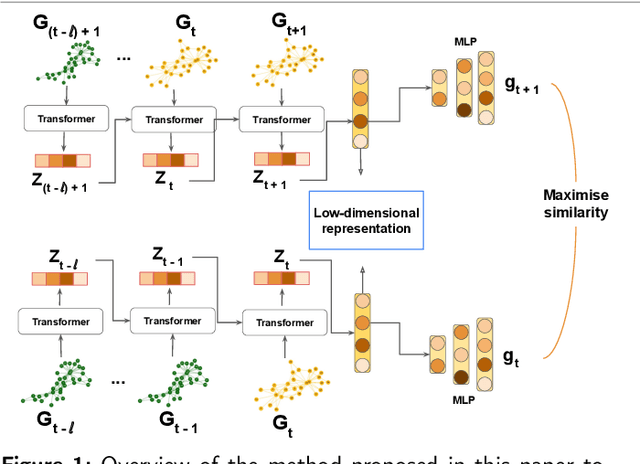
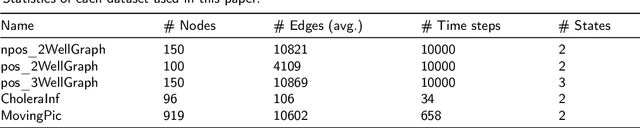
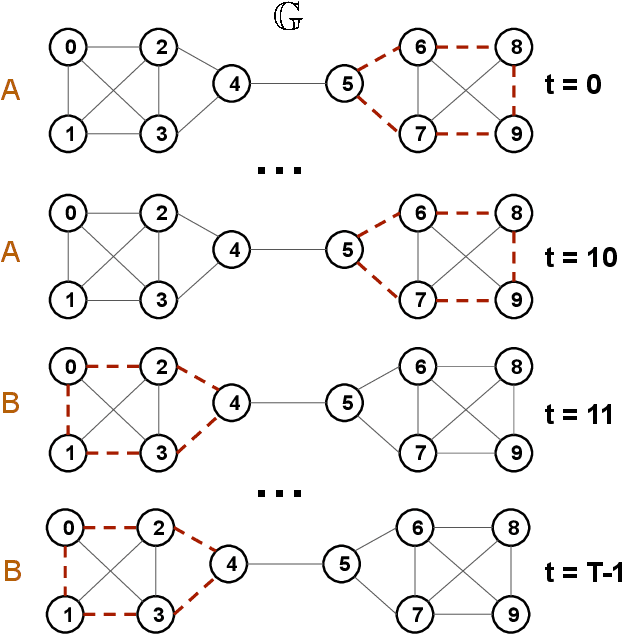

Large-scale perturbations in the microbiome constitution are strongly correlated, whether as a driver or a consequence, with the health and functioning of human physiology. However, understanding the difference in the microbiome profiles of healthy and ill individuals can be complicated due to the large number of complex interactions among microbes. We propose to model these interactions as a time-evolving graph whose nodes are microbes and edges are interactions among them. Motivated by the need to analyse such complex interactions, we develop a method that learns a low-dimensional representation of the time-evolving graph and maintains the dynamics occurring in the high-dimensional space. Through our experiments, we show that we can extract graph features such as clusters of nodes or edges that have the highest impact on the model to learn the low-dimensional representation. This information can be crucial to identify microbes and interactions among them that are strongly correlated with clinical diseases. We conduct our experiments on both synthetic and real-world microbiome datasets.
MoCoPnet: Exploring Local Motion and Contrast Priors for Infrared Small Target Super-Resolution
Jan 06, 2022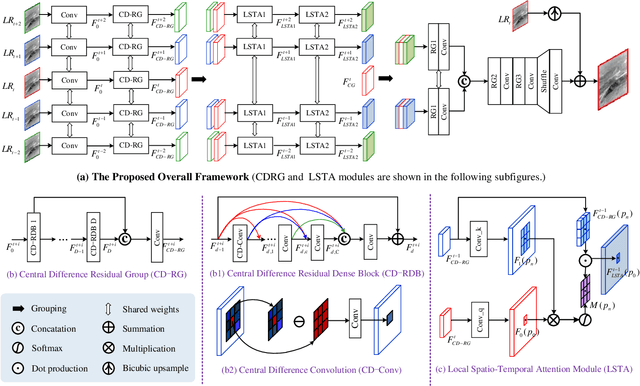
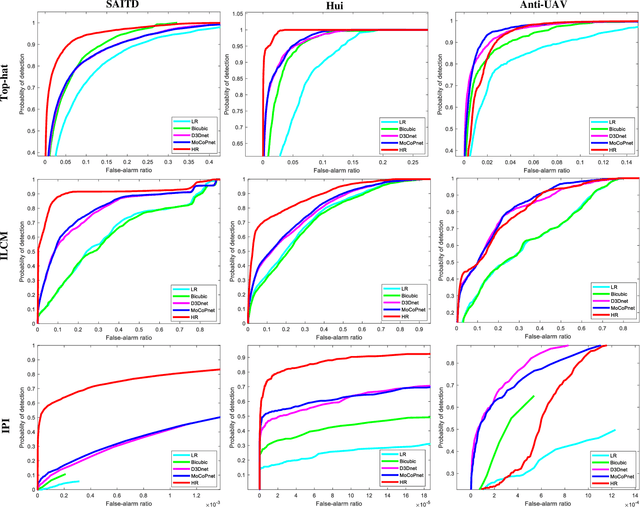

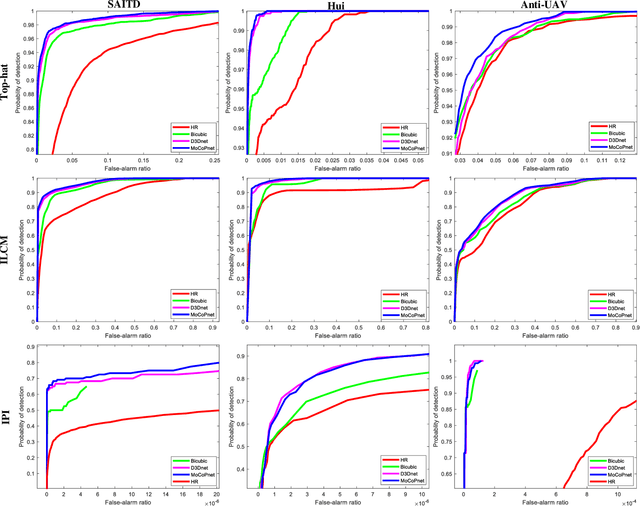
Infrared small target super-resolution (SR) aims to recover reliable and detailed high-resolution image with highcontrast targets from its low-resolution counterparts. Since the infrared small target lacks color and fine structure information, it is significant to exploit the supplementary information among sequence images to enhance the target. In this paper, we propose the first infrared small target SR method named local motion and contrast prior driven deep network (MoCoPnet) to integrate the domain knowledge of infrared small target into deep network, which can mitigate the intrinsic feature scarcity of infrared small targets. Specifically, motivated by the local motion prior in the spatio-temporal dimension, we propose a local spatiotemporal attention module to perform implicit frame alignment and incorporate the local spatio-temporal information to enhance the local features (especially for small targets). Motivated by the local contrast prior in the spatial dimension, we propose a central difference residual group to incorporate the central difference convolution into the feature extraction backbone, which can achieve center-oriented gradient-aware feature extraction to further improve the target contrast. Extensive experiments have demonstrated that our method can recover accurate spatial dependency and improve the target contrast. Comparative results show that MoCoPnet can outperform the state-of-the-art video SR and single image SR methods in terms of both SR performance and target enhancement. Based on the SR results, we further investigate the influence of SR on infrared small target detection and the experimental results demonstrate that MoCoPnet promotes the detection performance. The code is available at https://github.com/XinyiYing/MoCoPnet.
On Multi-Human Multi-Robot Remote Interaction: A Study of Transparency, Inter-Human Communication, and Information Loss in Remote Interaction
Feb 04, 2021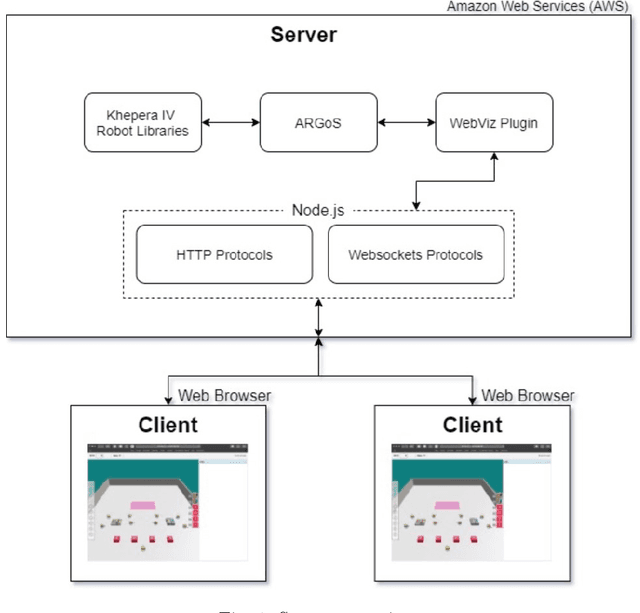
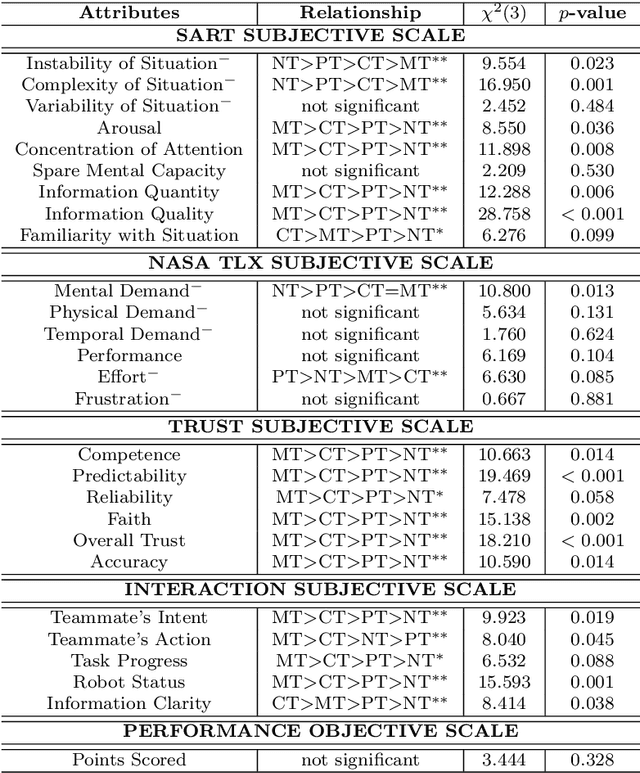
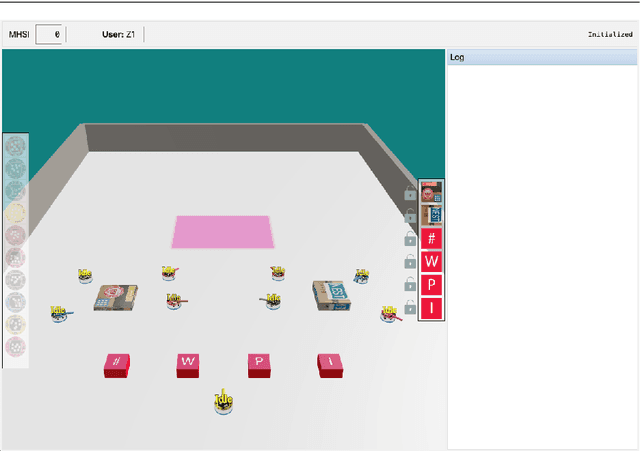

In this paper, we investigate how to design an effective interface for remote multi-human multi-robot interaction. While significant research exists on interfaces for individual human operators, little research exists for the multi-human case. Yet, this is a critical problem to solve to make complex, large-scale missions achievable in which direct human involvement is impossible or undesirable, and robot swarms act as a semi-autonomous agents. This paper's contribution is twofold. The first contribution is an exploration of the design space of computer-based interfaces for multi-human multi-robot operations. In particular, we focus on information transparency and on the factors that affect inter-human communication in ideal conditions, i.e., without communication issues. Our second contribution concerns the same problem, but considering increasing degrees of information loss, defined as intermittent reception of data with noticeable gaps between individual receipts. We derived a set of design recommendations based on two user studies involving 48 participants.
H4D: Human 4D Modeling by Learning Neural Compositional Representation
Mar 02, 2022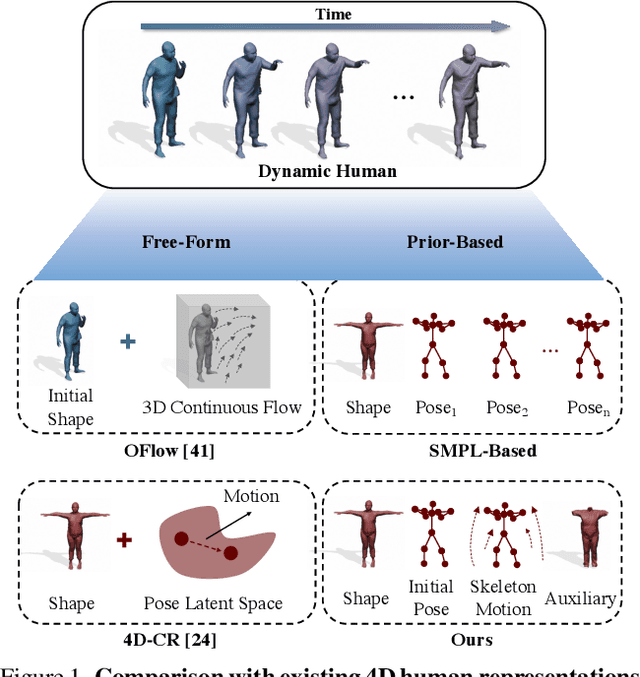
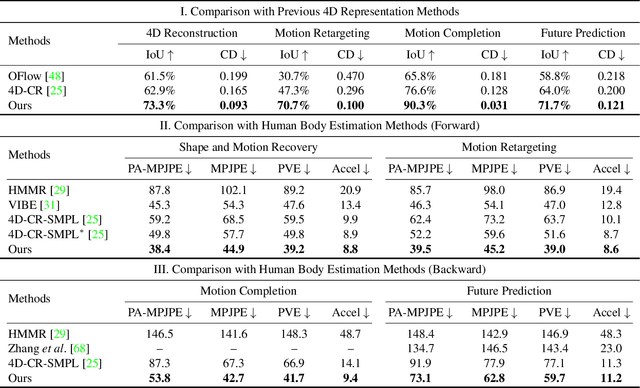
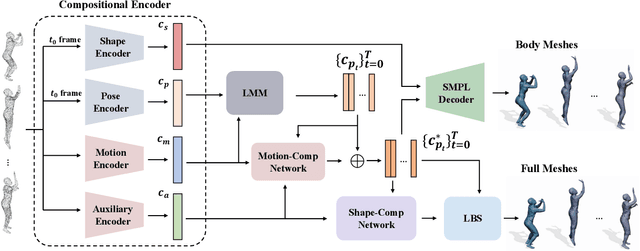
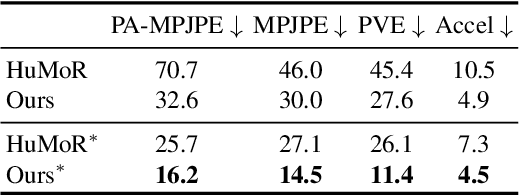
Despite the impressive results achieved by deep learning based 3D reconstruction, the techniques of directly learning to model the 4D human captures with detailed geometry have been less studied. This work presents a novel framework that can effectively learn a compact and compositional representation for dynamic human by exploiting the human body prior from the widely-used SMPL parametric model. Particularly, our representation, named H4D, represents dynamic 3D human over a temporal span into the latent spaces encoding shape, initial pose, motion and auxiliary information. A simple yet effective linear motion model is proposed to provide a rough and regularized motion estimation, followed by per-frame compensation for pose and geometry details with the residual encoded in the auxiliary code. Technically, we introduce novel GRU-based architectures to facilitate learning and improve the representation capability. Extensive experiments demonstrate our method is not only efficacy in recovering dynamic human with accurate motion and detailed geometry, but also amenable to various 4D human related tasks, including motion retargeting, motion completion and future prediction.
Fast Community Detection based on Graph Autoencoder Reconstruction
Mar 07, 2022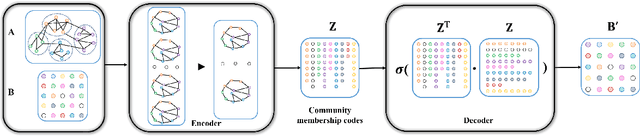
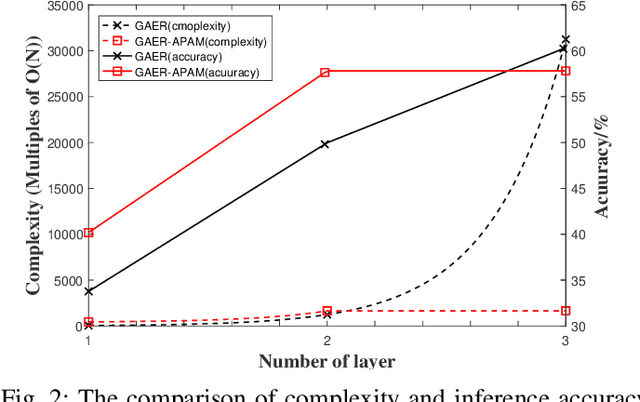
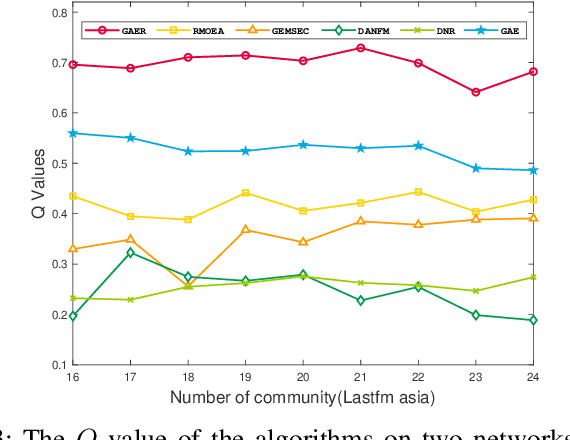
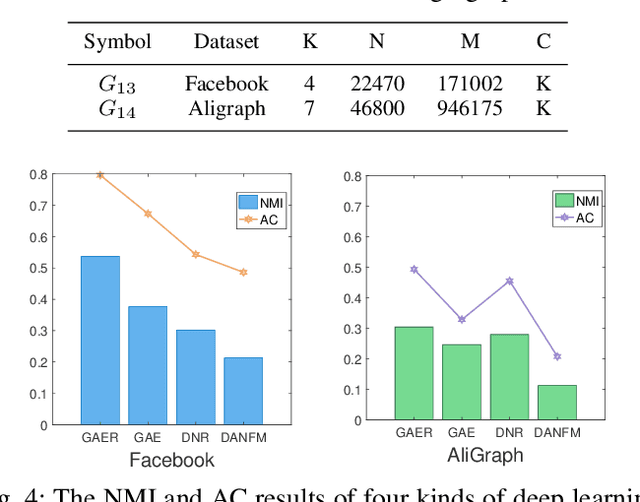
With the rapid development of big data, how to efficiently and accurately discover tight community structures in large-scale networks for knowledge discovery has attracted more and more attention. In this paper, a community detection framework based on Graph AutoEncoder Reconstruction (noted as GAER) is proposed for the first time. GAER is a highly scalable framework which does not require any prior information. We decompose the graph autoencoder-based one-step encoding into the two-stage encoding framework to adapt to the real-world big data system by reducing complexity from the original O(N^2) to O(N). At the same time, based on the advantages of GAER support module plug-and-play configuration and incremental community detection, we further propose a peer awareness based module for real-time large graphs, which can realize the new nodes community detection at a faster speed, and accelerate model inference with the 6.15 times - 14.03 times speed. Finally, we apply the GAER on multiple real-world datasets, including some large-scale networks. The experimental result verified that GAER has achieved the superior performance on almost all networks.
Double Fuzzy Probabilistic Interval Linguistic Term Set and a Dynamic Fuzzy Decision Making Model based on Markov Process with tts Application in Multiple Criteria Group Decision Making
Nov 30, 2021
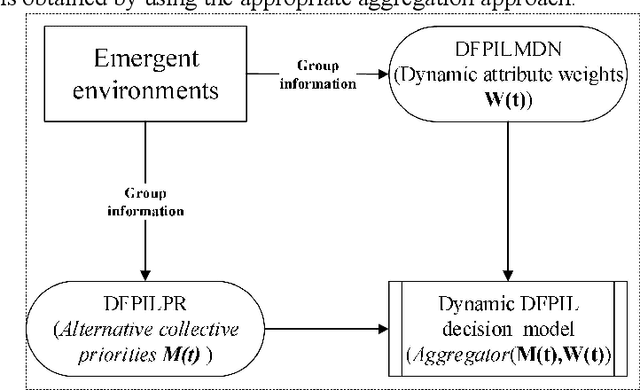
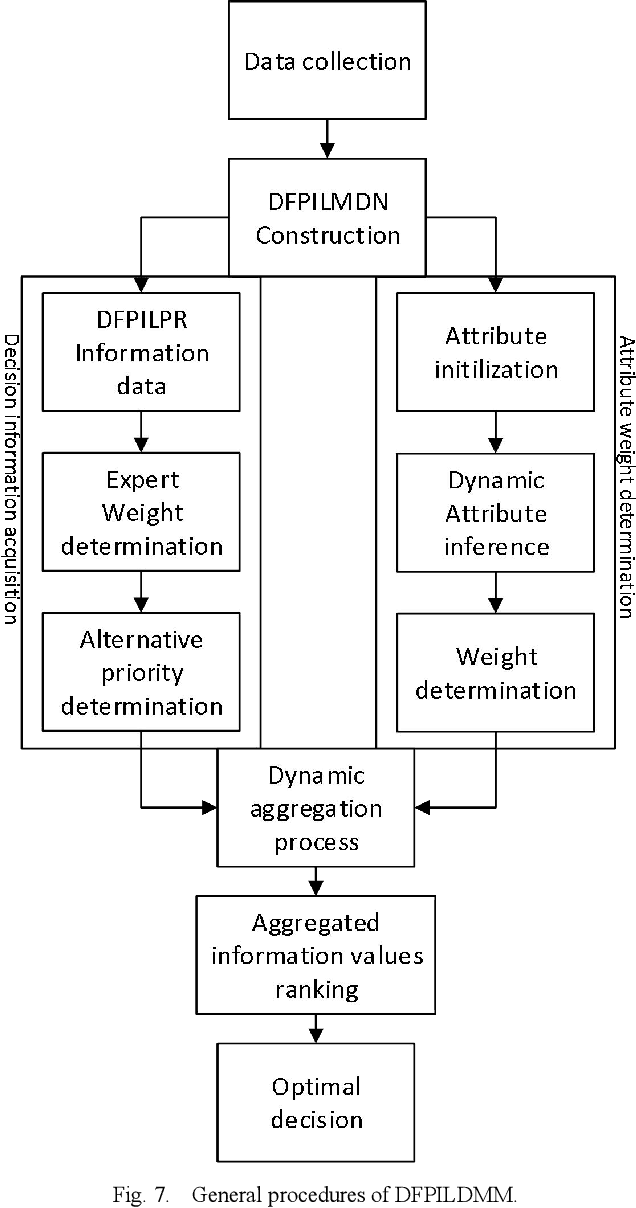
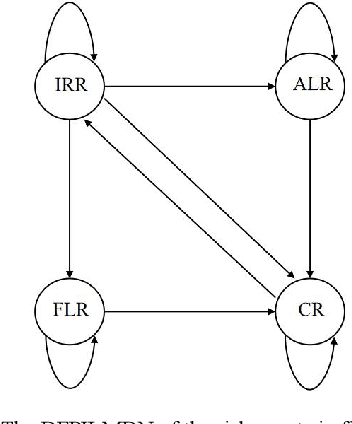
The probabilistic linguistic term has been proposed to deal with probability distributions in provided linguistic evaluations. However, because it has some fundamental defects, it is often difficult for decision-makers to get reasonable information of linguistic evaluations for group decision making. In addition, weight information plays a significant role in dynamic information fusion and decision making process. However, there are few research methods to determine the dynamic attribute weight with time. In this paper, I propose the concept of double fuzzy probability interval linguistic term set (DFPILTS). Firstly, fuzzy semantic integration, DFPILTS definition, its preference relationship, some basic algorithms and aggregation operators are defined. Then, a fuzzy linguistic Markov matrix with its network is developed. Then, a weight determination method based on distance measure and information entropy to reducing the inconsistency of DFPILPR and obtain collective priority vector based on group consensus is developed. Finally, an aggregation-based approach is developed, and an optimal investment case from a financial risk is used to illustrate the application of DFPILTS and decision method in multi-criteria decision making.
Modelling Underwater Acoustic Propagation using One-way Wave Equations
Feb 14, 2022The primary contribution of this paper is to characterize the propagation of acoustic signal carrying information through any medium and the interaction of the travelling acoustic signal with the surrounding medium. We will use the concept of damped harmonic oscillator to model the medium and Milne's oscillator technique to map the interaction of the acoustic signal with the medium. The acoustic signal itself will be modelled using the one-way wave equation formulated in terms of acoustic pressure and velocity of acoustic waves through the medium. Using the above-mentioned concepts, we calculated the effective signal strength, phase shift and time period of the communicated signal. Numerical results are generated to present the evolution of signal strength and received signal envelope in underwater environment.
Unpaired Deep Image Dehazing Using Contrastive Disentanglement Learning
Mar 15, 2022
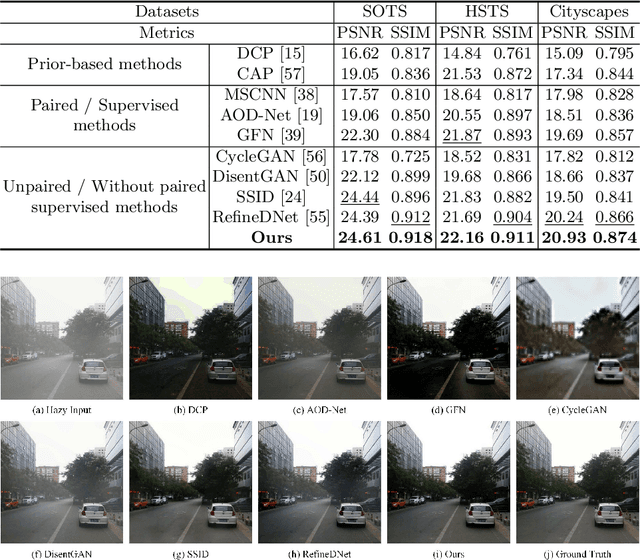
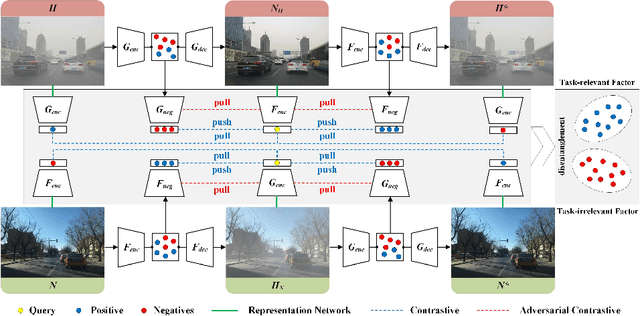
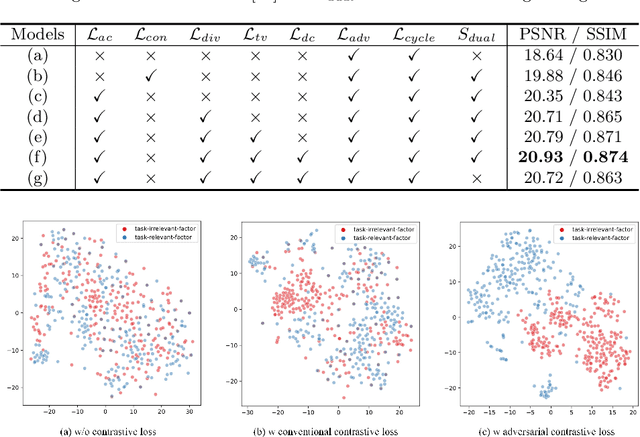
We present an effective unpaired learning based image dehazing network from an unpaired set of clear and hazy images. This paper provides a new perspective to treat image dehazing as a two-class separated factor disentanglement task, i.e, the task-relevant factor of clear image reconstruction and the task-irrelevant factor of haze-relevant distribution. To achieve the disentanglement of these two-class factors in deep feature space, contrastive learning is introduced into a CycleGAN framework to learn disentangled representations by guiding the generated images to be associated with latent factors. With such formulation, the proposed contrastive disentangled dehazing method (CDD-GAN) first develops negative generators to cooperate with the encoder network to update alternately, so as to produce a queue of challenging negative adversaries. Then these negative adversaries are trained end-to-end together with the backbone representation network to enhance the discriminative information and promote factor disentanglement performance by maximizing the adversarial contrastive loss. During the training, we further show that hard negative examples can suppress the task-irrelevant factors and unpaired clear exemples can enhance the task-relevant factors, in order to better facilitate haze removal and help image restoration. Extensive experiments on both synthetic and real-world datasets demonstrate that our method performs favorably against existing state-of-the-art unpaired dehazing approaches.
NetRCA: An Effective Network Fault Cause Localization Algorithm
Feb 23, 2022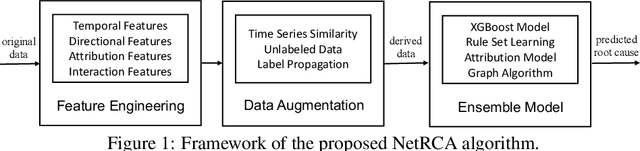
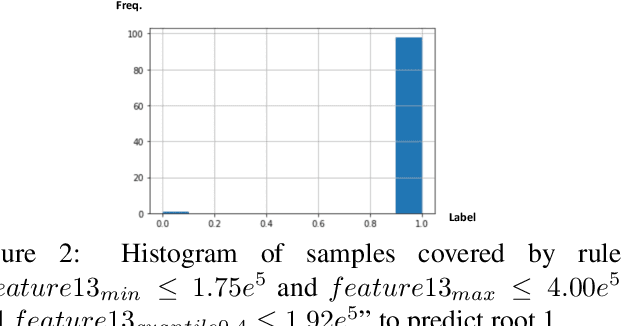
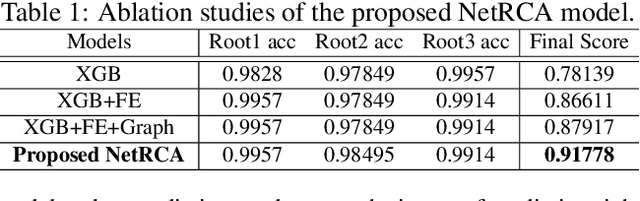
Localizing the root cause of network faults is crucial to network operation and maintenance. However, due to the complicated network architectures and wireless environments, as well as limited labeled data, accurately localizing the true root cause is challenging. In this paper, we propose a novel algorithm named NetRCA to deal with this problem. Firstly, we extract effective derived features from the original raw data by considering temporal, directional, attribution, and interaction characteristics. Secondly, we adopt multivariate time series similarity and label propagation to generate new training data from both labeled and unlabeled data to overcome the lack of labeled samples. Thirdly, we design an ensemble model which combines XGBoost, rule set learning, attribution model, and graph algorithm, to fully utilize all data information and enhance performance. Finally, experiments and analysis are conducted on the real-world dataset from ICASSP 2022 AIOps Challenge to demonstrate the superiority and effectiveness of our approach.
Tutela: An Open-Source Tool for Assessing User-Privacy on Ethereum and Tornado Cash
Jan 18, 2022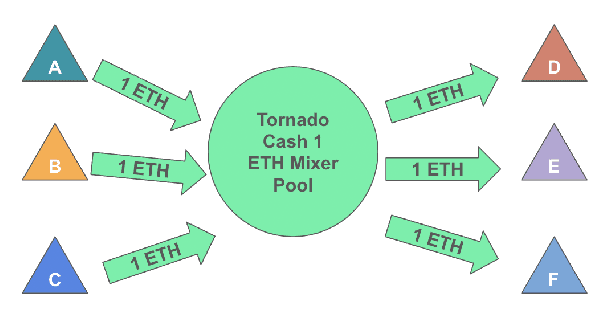
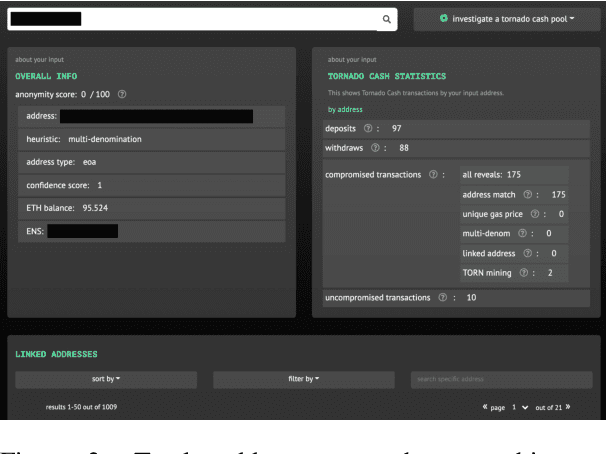
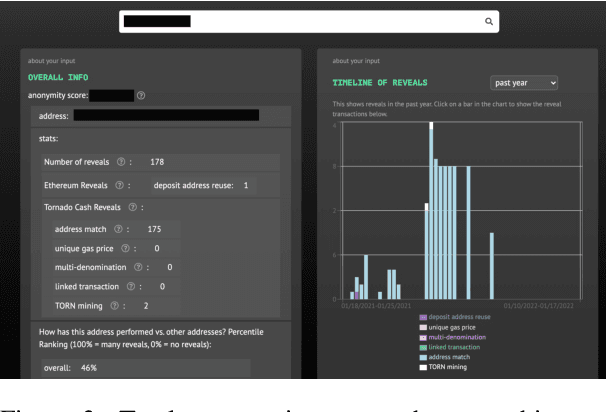
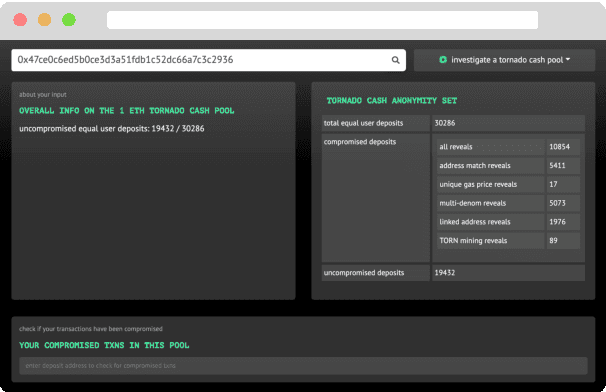
A common misconception among blockchain users is that pseudonymity guarantees privacy. The reality is almost the opposite. Every transaction one makes is recorded on a public ledger and reveals information about one's identity. Mixers, such as Tornado Cash, were developed to preserve privacy through "mixing" transactions with those of others in an anonymity pool, making it harder to link deposits and withdrawals from the pool. Unfortunately, it is still possible to reveal information about those in the anonymity pool if users are not careful. We introduce Tutela, an application built on expert heuristics to report the true anonymity of an Ethereum address. In particular, Tutela has three functionalities: first, it clusters together Ethereum addresses based on interaction history such that for an Ethereum address, we can identify other addresses likely owned by the same entity; second, it shows Ethereum users their potentially compromised transactions; third, Tutela computes the true size of the anonymity pool of each Tornado Cash mixer by excluding potentially compromised transactions. A public implementation of Tutela can be found at https://github.com/TutelaLabs/tutela-app. To use Tutela, visit https://www.tutela.xyz.